
faker 및 pandas Python 라이브러리를 사용하여 테스트용 합성 데이터 생성
 검색:973
검색:973
소개:
데이터 기반 애플리케이션에는 포괄적인 테스트가 필수적이지만 항상 사용 가능하지 않을 수 있는 올바른 데이터 세트가 있어야 하는 경우가 많습니다. 웹 애플리케이션, 기계 학습 모델 또는 백엔드 시스템을 개발하는 경우 현실적이고 구조화된 데이터는 적절한 검증과 강력한 성능 보장에 매우 중요합니다. 실제 데이터 수집은 개인 정보 보호 문제, 라이센스 제한 또는 단순히 관련 데이터를 사용할 수 없는 경우로 인해 제한될 수 있습니다. 합성 데이터가 가치 있는 곳이 바로 여기입니다.
이 블로그에서는 Python을 사용하여 다음을 포함한 다양한 시나리오에 대한 합성 데이터를 생성하는 방법을 살펴보겠습니다.
- 상호관련 테이블: 일대다 관계를 나타냅니다.
- 계층적 데이터: 조직 구조에서 자주 사용됩니다.
- 복잡한 관계: 등록 시스템의 다대다 관계 등.
Faker 및 Pandas 라이브러리를 활용하여 이러한 사용 사례에 대한 현실적인 데이터 세트를 만들 것입니다.
예 1: 고객 및 주문에 대한 종합 데이터 생성(일대다 관계)
많은 애플리케이션에서 데이터는 외래 키 관계를 통해 여러 테이블에 저장됩니다. 고객과 주문에 대한 합성 데이터를 생성해 보겠습니다. 고객은 일대다 관계를 나타내는 여러 주문을 할 수 있습니다.
고객 테이블 생성
고객 테이블에는 고객 ID, 이름, 이메일 주소 등의 기본 정보가 포함되어 있습니다.
import pandas as pd
from faker import Faker
import random
fake = Faker()
def generate_customers(num_customers):
customers = []
for _ in range(num_customers):
customer_id = fake.uuid4()
name = fake.name()
email = fake.email()
customers.append({'CustomerID': customer_id, 'CustomerName': name, 'Email': email})
return pd.DataFrame(customers)
customers_df = generate_customers(10)
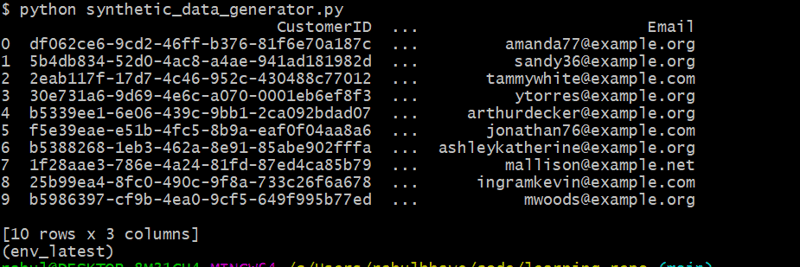
이 코드는 Faker를 사용하여 실제 이름과 이메일 주소를 생성하는 무작위 고객 10명을 생성합니다.
주문 테이블 생성
이제 각 주문이 CustomerID를 통해 고객과 연결되는 Orders 테이블을 생성합니다.
def generate_orders(customers_df, num_orders):
orders = []
for _ in range(num_orders):
order_id = fake.uuid4()
customer_id = random.choice(customers_df['CustomerID'].tolist())
product = fake.random_element(elements=('Laptop', 'Phone', 'Tablet', 'Headphones'))
price = round(random.uniform(100, 2000), 2)
orders.append({'OrderID': order_id, 'CustomerID': customer_id, 'Product': product, 'Price': price})
return pd.DataFrame(orders)
orders_df = generate_orders(customers_df, 30)
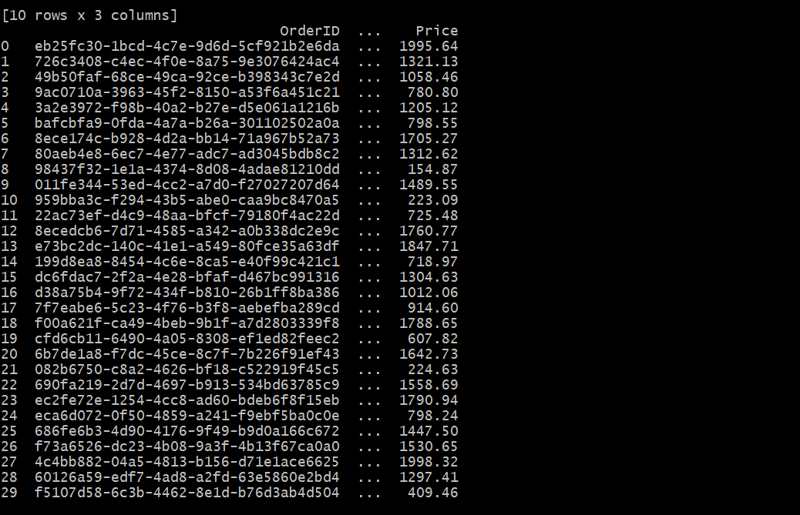
이 경우 Orders 테이블은 CustomerID를 사용하여 각 주문을 고객에 연결합니다. 각 고객은 여러 주문을 하여 일대다 관계를 형성할 수 있습니다.
예 2: 부서 및 직원에 대한 계층적 데이터 생성
계층적 데이터는 부서에 여러 직원이 있는 조직 설정에서 자주 사용됩니다. 각 부서에 여러 직원이 있는 조직을 시뮬레이션해 보겠습니다.
부서 테이블 생성
부서 테이블에는 각 부서의 고유한 부서 ID, 이름 및 관리자가 포함되어 있습니다.
def generate_departments(num_departments):
departments = []
for _ in range(num_departments):
department_id = fake.uuid4()
department_name = fake.company_suffix()
manager = fake.name()
departments.append({'DepartmentID': department_id, 'DepartmentName': department_name, 'Manager': manager})
return pd.DataFrame(departments)
departments_df = generate_departments(10)
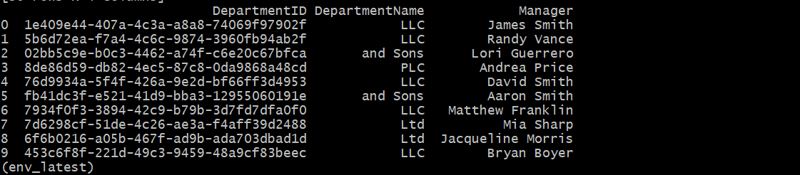
직원 테이블 생성
다음으로 각 직원이 DepartmentID를 통해 부서와 연결되는 Employeestable을 생성합니다.
def generate_employees(departments_df, num_employees):
employees = []
for _ in range(num_employees):
employee_id = fake.uuid4()
employee_name = fake.name()
email = fake.email()
department_id = random.choice(departments_df['DepartmentID'].tolist())
salary = round(random.uniform(40000, 120000), 2)
employees.append({
'EmployeeID': employee_id,
'EmployeeName': employee_name,
'Email': email,
'DepartmentID': department_id,
'Salary': salary
})
return pd.DataFrame(employees)
employees_df = generate_employees(departments_df, 100)
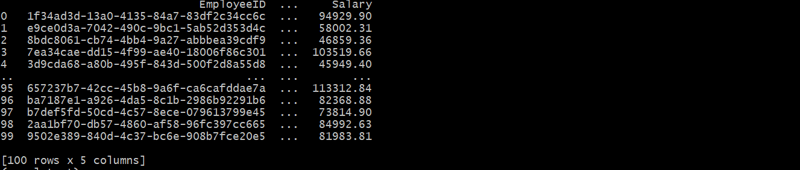
이 계층 구조는 DepartmentID를 통해 각 직원을 부서에 연결하여 상위-하위 관계를 형성합니다.
예 3: 강좌 등록을 위한 다대다 관계 시뮬레이션
특정 시나리오에서는 하나의 엔터티가 다른 엔터티와 관련된 다대다 관계가 존재합니다. 각 코스에는 여러 명의 학생이 있는 여러 코스에 등록하는 학생들을 대상으로 이를 시뮬레이션해 보겠습니다.
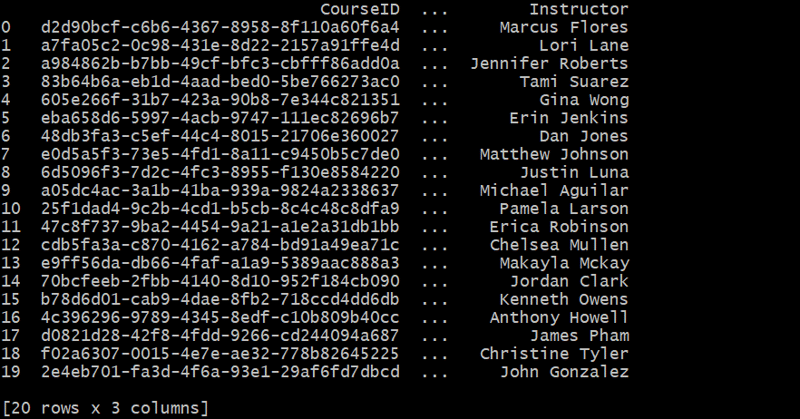
강좌 테이블 생성
def generate_courses(num_courses):
courses = []
for _ in range(num_courses):
course_id = fake.uuid4()
course_name = fake.bs().title()
instructor = fake.name()
courses.append({'CourseID': course_id, 'CourseName': course_name, 'Instructor': instructor})
return pd.DataFrame(courses)
courses_df = generate_courses(20)
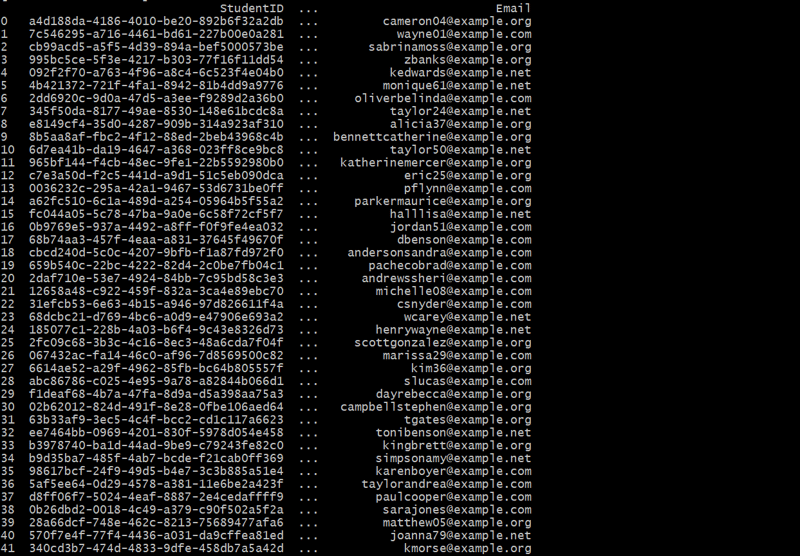
학생 테이블 생성
def generate_students(num_students):
students = []
for _ in range(num_students):
student_id = fake.uuid4()
student_name = fake.name()
email = fake.email()
students.append({'StudentID': student_id, 'StudentName': student_name, 'Email': email})
return pd.DataFrame(students)
students_df = generate_students(50)
print(students_df)
강좌 등록 테이블 생성
CourseEnrollments 테이블은 학생과 코스 간의 다대다 관계를 캡처합니다.
def generate_course_enrollments(students_df, courses_df, num_enrollments):
enrollments = []
for _ in range(num_enrollments):
enrollment_id = fake.uuid4()
student_id = random.choice(students_df['StudentID'].tolist())
course_id = random.choice(courses_df['CourseID'].tolist())
enrollment_date = fake.date_this_year()
enrollments.append({
'EnrollmentID': enrollment_id,
'StudentID': student_id,
'CourseID': course_id,
'EnrollmentDate': enrollment_date
})
return pd.DataFrame(enrollments)
enrollments_df = generate_course_enrollments(students_df, courses_df, 200)
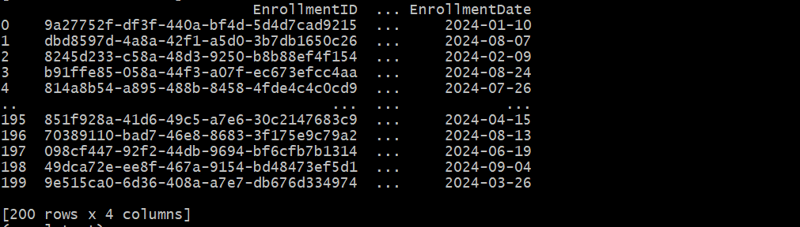
이 예에서는 학생과 강좌 간의 다대다 관계를 나타내는 연결 테이블을 만듭니다.
결론:
Python과 Faker 및 Pandas와 같은 라이브러리를 사용하면 현실적이고 다양한 합성 데이터 세트를 생성하여 다양한 테스트 요구 사항을 충족할 수 있습니다. 이 블로그에서는 다음 내용을 다루었습니다.
- 상호관련 테이블: 고객과 주문 간의 일대다 관계를 보여줍니다.
- 계층적 데이터: 부서와 직원 간의 상위-하위 관계를 보여줍니다.
- 복잡한 관계: 학생과 코스 간의 다대다 관계를 시뮬레이션합니다.
이러한 예는 귀하의 요구에 맞는 합성 데이터를 생성하기 위한 기반을 마련합니다. 더욱 복잡한 관계 생성, 특정 데이터베이스에 대한 데이터 사용자 정의, 성능 테스트를 위한 데이터 세트 확장 등의 추가 개선을 통해 합성 데이터 생성을 한 단계 더 발전시킬 수 있습니다.
이러한 예는 합성 데이터 생성을 위한 견고한 기반을 제공합니다. 그러나 다음과 같이 복잡성과 특이성을 높이기 위해 추가 개선이 이루어질 수 있습니다.
- 데이터베이스별 데이터: 다양한 데이터베이스 시스템에 대한 데이터 생성 사용자 정의(예: SQL 및 NoSQL).
- 더 복잡한 관계: 시간적 관계, 다단계 계층 또는 고유 제약 조건과 같은 추가 상호 종속성을 생성합니다.
- 데이터 확장: 성능 테스트 또는 스트레스 테스트를 위해 더 큰 데이터 세트를 생성하여 시스템이 대규모로 실제 조건을 처리할 수 있도록 보장합니다. 요구 사항에 맞는 합성 데이터를 생성하면 민감하거나 획득하기 어려운 데이터 세트에 의존하지 않고도 애플리케이션 개발, 테스트 및 최적화를 위한 현실적인 조건을 시뮬레이션할 수 있습니다.
-
 PYTZ가 처음에 예상치 못한 시간대 오프셋을 표시하는 이유는 무엇입니까?import pytz pytz.timezone ( 'Asia/Hong_kong') std> discrepancy source 역사 전반에 걸쳐 변동합니다. PYTZ가 제공하는 기본 시간대 이름 및 오프...프로그램 작성 2025-04-08에 게시되었습니다
PYTZ가 처음에 예상치 못한 시간대 오프셋을 표시하는 이유는 무엇입니까?import pytz pytz.timezone ( 'Asia/Hong_kong') std> discrepancy source 역사 전반에 걸쳐 변동합니다. PYTZ가 제공하는 기본 시간대 이름 및 오프...프로그램 작성 2025-04-08에 게시되었습니다 -
`JSON '패키지를 사용하여 이동하는 JSON 어레이를 구문 분석하는 방법은 무엇입니까?JSON 어레이를 Parsing JSON 패키지 문제 : JSON 패키지를 사용하여 어레이를 나타내는 JSON 스트링을 어떻게 구문 분석 할 수 있습니까? 예 : type JsonType struct { Array []string ...프로그램 작성 2025-04-08에 게시되었습니다
-
PostgreSQL의 각 고유 식별자에 대한 마지막 행을 효율적으로 검색하는 방법은 무엇입니까?postgresql : 각각의 고유 식별자에 대한 마지막 행을 추출하는 select distinct on (id) id, date, another_info from the_table order by id, date desc; id ...프로그램 작성 2025-04-08에 게시되었습니다
-
MySQL에서 데이터를 피벗하여 그룹을 어떻게 사용할 수 있습니까?select d.data_timestamp, sum (data_id = 1 that data_value else 0 End), 'input_1'로 0 End), sum (data_id = 2 an Els.] d.data_timestamp ...프로그램 작성 2025-04-08에 게시되었습니다
-
동적 인 크기의 부모 요소 내에서 요소의 스크롤 범위를 제한하는 방법은 무엇입니까?문제 : 고정 된 사이드 바로 조정을 유지하면서 사용자의 수직 스크롤과 함께 이동하는 스크롤 가능한 맵 디브가있는 레이아웃을 고려합니다. 그러나 맵의 스크롤은 뷰포트의 높이를 초과하여 사용자가 페이지 바닥 글에 액세스하는 것을 방지합니다. ...프로그램 작성 2025-04-08에 게시되었습니다
-
PHP를 사용하여 XML 파일에서 속성 값을 효율적으로 검색하려면 어떻게해야합니까?옵션> 1 varnum "varnum"을 복원 할 수 있습니다. stumped. 이 기능은 XML 요소의 속성에 대한 액세스를 연관 배열로 제공합니다. $ xml = simplexml_load_file ($ file);...프로그램 작성 2025-04-08에 게시되었습니다
-
Firefox Back 버튼을 사용할 때 JavaScript 실행이 중단되는 이유는 무엇입니까?원인 및 솔루션 : 이 동작은 브라우저 캐싱 자바 스크립트 리소스에 의해 발생합니다. 이 문제를 해결하고 후속 페이지 방문에서 스크립트가 실행되도록하기 위해 Firefox 사용자는 Window.onload 이벤트에서 호출되도록 빈 기능을 설정해야합니다. ...프로그램 작성 2025-04-08에 게시되었습니다
-
익명의 JavaScript 이벤트 처리기를 깨끗하게 제거하는 방법은 무엇입니까?익명 이벤트 리스너 제거 ELMENTS를 추가하면 유연성과 단순성을 제공하지만 유연성과 단순성을 제공하지만 제거 할 시간이되면 요소 자체를 교체하지 않고 도전 할 수 있습니다. 요소? element.addeventListener (event, fu...프로그램 작성 2025-04-08에 게시되었습니다
-
선형 구배 배경에 줄무늬가있는 이유는 무엇이며 어떻게 고칠 수 있습니까?수직 지향적 구배의 경우, 신체 요소의 마진은 HTML 요소로 전파되어 8px 키가 큰 영역을 초래합니다. 그 후, 선형 등급은이 전체 높이에 걸쳐 확장되어 반복 패턴을 생성합니다. 솔루션 : 이 문제를 해결하기 위해 신체 요소에 충분한 높이가 있는지...프로그램 작성 2025-04-08에 게시되었습니다
-
regex를 사용하여 PHP에서 괄호 안에서 텍스트를 추출하는 방법$ fullstring = "이 (텍스트)을 제외한 모든 것을 무시하는 것"; $ start = strpos ( ', $ fullstring); $ fullString); $ shortstring = substr ($ fulls...프로그램 작성 2025-04-08에 게시되었습니다
-
전체 HTML 문서에서 특정 요소 유형의 첫 번째 인스턴스를 어떻게 스타일링하려면 어떻게해야합니까?javascript 솔루션 < /h2> : 최초의 유형 문서 전체를 달성합니다 유형의 첫 번째 요소와 일치하는 JavaScript 솔루션이 필요합니다. 문서에서 첫 번째 일치 요소를 선택하고 사용자 정의를 적용 할 수 있습니다. 그런 ...프로그램 작성 2025-04-08에 게시되었습니다
-
Visual Studio 2012의 DataSource 대화 상자에 MySQL 데이터베이스를 추가하는 방법은 무엇입니까?MySQL 커넥터 v.6.5.4가 설치되어 있지만 Entity 프레임 워크의 DataSource 대화 상자에 MySQL 데이터베이스를 추가 할 수 없습니다. 이를 해결하기 위해 MySQL 용 공식 Visual Studio 2012 통합은 MySQL 커넥터 v.6....프로그램 작성 2025-04-08에 게시되었습니다
-
교체 지시문을 사용하여 GO MOD에서 모듈 경로 불일치를 해결하는 방법은 무엇입니까?[ github.com/coreos/coreos/client github.com/coreos/etcd/client.test imports github.com/coreos/etcd/integration에 의해 테스트 된 Echoed 메시지에 의해 입증 된 바와...프로그램 작성 2025-04-08에 게시되었습니다
-
\ "일반 오류 : 2006 MySQL Server가 사라졌습니다 \"데이터를 삽입 할 때?를 해결하는 방법 "일반 오류 : 2006 MySQL Server가 사라졌습니다. 이 오류는 일반적으로 MySQL 구성의 두 변수 중 하나로 인해 서버에 대한 연결이 손실 될 때 발생합니다. 솔루션 : 이 오류를 해결하기위한 키는 Wait_Ti...프로그램 작성 2025-04-07에 게시되었습니다
-
유효한 코드에도 불구하고 PHP의 입력을 캡처하는 사후 요청이없는 이유는 무엇입니까?post request 오작동 주소 php action='' action = "프로그램 작성 2025-04-07에 게시되었습니다















중국어 공부
- 1 "걷다"를 중국어로 어떻게 말하나요? 走路 중국어 발음, 走路 중국어 학습
- 2 "비행기를 타다"를 중국어로 어떻게 말하나요? 坐飞机 중국어 발음, 坐飞机 중국어 학습
- 3 "기차를 타다"를 중국어로 어떻게 말하나요? 坐火车 중국어 발음, 坐火车 중국어 학습
- 4 "버스를 타다"를 중국어로 어떻게 말하나요? 坐车 중국어 발음, 坐车 중국어 학습
- 5 운전을 중국어로 어떻게 말하나요? 开车 중국어 발음, 开车 중국어 학습
- 6 수영을 중국어로 뭐라고 하나요? 游泳 중국어 발음, 游泳 중국어 학습
- 7 자전거를 타다 중국어로 뭐라고 하나요? 骑自行车 중국어 발음, 骑自行车 중국어 학습
- 8 중국어로 안녕하세요를 어떻게 말해요? 你好중국어 발음, 你好중국어 학습
- 9 감사합니다를 중국어로 어떻게 말하나요? 谢谢중국어 발음, 谢谢중국어 학습
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









