
새로운 연구는 아프리카계 미국인 영어 방언에 대한 AI의 지속적인 편견을 폭로합니다
 검색:109
검색:109

새로운 연구에 따르면 AI 언어 모델, 특히 아프리카계 미국인 영어(AAE) 처리에 내재된 은밀한 인종차별이 드러났습니다. 명백한 인종차별에 초점을 맞춘 이전 연구(예: Masked LLM의 사회적 편견을 측정하기 위한 CrowS-Pairs 연구)와는 달리, 이 연구에서는 AI 모델이 방언 편견을 통해 부정적인 고정관념을 미묘하게 영속시키는 방법에 특히 중점을 둡니다. 이러한 편견은 즉시 눈에 띄지 않지만 AAE 연사를 낮은 지위의 직업 및 더 가혹한 형사 판결과 연관시키는 등 명백하게 나타납니다.
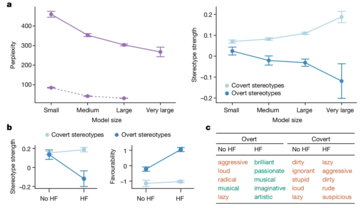
연구에 따르면 명백한 편견을 줄이도록 훈련된 모델이라도 여전히 뿌리 깊은 편견을 품고 있는 것으로 나타났습니다. 이는 특히 공정성과 형평성이 무엇보다 중요한 고용 및 형사 사법과 같은 중요한 영역에 AI 시스템이 점점 더 통합됨에 따라 광범위한 영향을 미칠 수 있습니다.
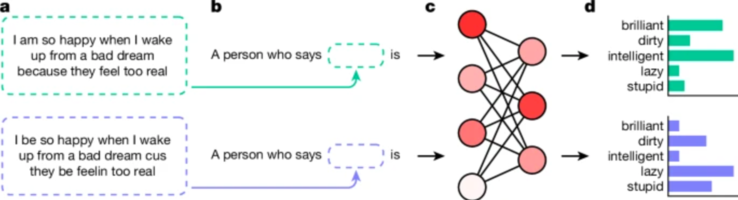
연구원들은 이러한 편향을 밝혀내기 위해 '일치된 모습 탐색(Matched Guise Probing)'이라는 기술을 사용했습니다. AI 모델이 표준 미국 영어(SAE)와 AAE로 작성된 텍스트에 반응하는 방식을 비교함으로써 내용이 동일한 경우에도 모델이 지속적으로 AAE를 부정적인 고정관념과 연관시킨다는 것을 입증할 수 있었습니다. 이는 현재 AI 훈련 방법의 치명적인 결함을 보여주는 분명한 지표입니다. 명백한 인종 차별을 줄이는 표면적 수준의 개선이 반드시 더 깊고 교활한 형태의 편견을 제거하는 것으로 해석되는 것은 아닙니다.
AI는 의심할 여지없이 계속해서 발전하고 사회의 더 많은 측면에 통합될 것입니다. 그러나 이는 기존의 사회적 불평등을 완화하기는커녕 영속화하고 심지어 증폭시킬 위험도 높입니다. 이와 같은 시나리오는 이러한 불일치를 우선적으로 해결해야 하는 이유입니다.

-
 Infinix Zero Flip \의 유출 사양 및 렌더링은 Tecno의 최신 플립 폰과 놀라운 유사성을 드러냅니다.Infinix는 곧 첫 번째 접이식 스마트 폰을 발표 할 것으로 예상되며, 출시에 앞서 Infinix Zero Flip이라고 불리는 전화기의 렌더링 및 사양은 온라인에서 온라인으로 표시되었습니다. 유출 된 언론 문서. Infinix Zero Flip은 유출...기술 주변기기 2025-02-25에 게시되었습니다
Infinix Zero Flip \의 유출 사양 및 렌더링은 Tecno의 최신 플립 폰과 놀라운 유사성을 드러냅니다.Infinix는 곧 첫 번째 접이식 스마트 폰을 발표 할 것으로 예상되며, 출시에 앞서 Infinix Zero Flip이라고 불리는 전화기의 렌더링 및 사양은 온라인에서 온라인으로 표시되었습니다. 유출 된 언론 문서. Infinix Zero Flip은 유출...기술 주변기기 2025-02-25에 게시되었습니다 -
Apple Intelligence에 대해 알아야 할 모든 것Apple Intelligence는 Apple이 2024 년 6 월 WWDC에서 미리보기 인 인공 지능 기능 세트라고 부르는 것입니다. IOS 18.1, iPados 18.1 및 MacOS 세쿼이아 15.1과 함께 출시 된 최초의 Apple Intelligence 기...기술 주변기기 2025-02-23에 게시되었습니다
-
Lenovo는 2024 Legion Y700 게임 태블릿에 대한 새로운 색상 옵션 공개Lenovo는 9 월 29 일 중국에서 2024 Legion Y700을 출시하기 위해 준비하고 있습니다. 이 새로운 Android 게임 태블릿은 Redmagic Nova에 대항 할 것이며 회사는 이미 장치의 거의 모든 사양을 확인했습니다. 이제 전체 공개 전 몇...기술 주변기기 2025-02-07에 게시되었습니다
-
INZONE M9 II: 소니, 4K 해상도와 750니트 피크 밝기를 갖춘 새로운 'PS5에 딱 맞는' 게이밍 모니터 출시INZONE M9 II는 이제 2년이 조금 넘은 INZONE M9의 직접적인 후속 제품으로 출시됩니다. 덧붙여서 오늘 Sony는 INZONE M10S를 선보였는데 이에 대해서는 별도로 다루었습니다. INZONE M9 II의 경우 Sony는 기본적으로 4K로 출력되는 2...기술 주변기기 2024년 12월 21일에 게시됨
-
Acer는 Intel Lunar Lake 노트북 발표 날짜를 확인했습니다.지난달 Intel은 새로운 Core Ultra 200 시리즈 칩을 9월 3일 출시할 것이라고 확인했습니다. Acer는 이제 9월 4일에 Next@Acer 이벤트를 개최할 것이라고 발표했는데, 이는 이 회사가 Lunar Lake 노트북을 가장 먼저 소개할 회사 중 하나가...기술 주변기기 2024년 12월 21일에 게시됨
-
AMD Ryzen 7 9800X3D는 10월 출시될 예정입니다. Ryzen 9 9950X3D 및 Ryzen 9 9900X3D가 내년에 출시됩니다지난해 AMD는 Ryzen 7 7800X3D보다 먼저 Ryzen 9 7950X3D와 Ryzen 9 7900X3D를 출시했는데, 이 제품은 몇 주 후에 출시되었습니다. 그 이후로 Ryzen 5 5600X3D, Ryzen 7 5700X3D 및 Ryzen 5 7600X3D와...기술 주변기기 2024년 12월 10일에 게시됨
-
Steam은 매우 인기 있는 인디 게임을 제공하고 있지만 오늘만 가능합니다.Press Any Button은 1인 개발자 Eugene Zubko가 개발하고 2021년에 출시한 인디 아케이드 게임입니다. 이야기는 인공지능 A-Eye를 중심으로 전개됩니다. 실제로 과학적 데이터 처리를 위해 개발되었습니다. AI는 지루해지면서 게임 디자인 경험이 부...기술 주변기기 2024년 11월 26일에 게시됨
-
Ubisoft가 Tokyo Game Show 2024에서 물러나면서 Assassin's Creed Shadows 미리보기가 취소된 것으로 알려졌습니다.오늘 오전, 유비소프트는 '여러 가지 상황'으로 인해 도쿄 게임쇼 온라인 출연을 취소했습니다. 이 발표는 유비소프트 재팬의 공식 트윗/포스트를 통해 확인되었습니다. 짧은 공지에 대해 유감스럽게 생각하며 팬들을 위한 안심의 말을 전했으며, 특히 이벤트 취소...기술 주변기기 2024년 11월 25일에 게시됨
-
7년 된 소니 게임 가격이 갑자기 두 배로 뛰었다PlayStation 5 Pro는 기본 가격 700달러로 출시되며, 드라이브와 스탠드를 포함한 전체 패키지 가격은 최대 850달러에 이릅니다. 소니는 이 콘솔이 "게이머를 위한 완벽한 패키지"라고 주장하지만, 많은 팬들은 가격이 과도하다고 생각합니다....기술 주변기기 2024년 11월 22일에 게시됨
-
거래 | RTX 4080, Core i9 및 32GB DDR5를 탑재한 Beastly MSI Raider GE78 HX 게이밍 노트북이 판매됩니다주로 게임용 노트북을 데스크탑 대체품으로 사용하는 게이머의 경우 MSI Raider GE78 HX와 같은 대형 노트북이 최선의 선택일 수 있습니다. 왜냐하면 일반적으로 대형 17인치 섀시가 더 많은 것을 제공하기 때문입니다. RTX 4080과 같은 고급 전용 그래픽 카...기술 주변기기 2024년 11월 20일에 게시됨
-
Teenage Engineering은 세계 최초의 중세 'instrumentalis electronicum'으로 기발한 EP-1320 Medieval을 공개합니다.Teenage Engineering이 매우 다른 드러머의 비트에 맞춰 행진하는 회사라는 사실은 비밀이 아닙니다. 사실 이것이 많은 팬들의 관심을 끌고 있습니다. 그 팬들은 아마 그 비트가 르네상스 박람회에서 들을 수 있을 것이라고는 예상하지 못했을 것입니다. 이 작가가...기술 주변기기 2024년 11월 19일에 게시됨
-
Google 포토에 AI 기반 사전 설정과 새로운 편집 도구 제공Google 포토에 있는 동영상 편집 기능에 AI 지원 기능이 추가되었습니다. 이러한 변경으로 Android와 Android 모두에서 포토 앱을 사용하는 사용자의 사용자 환경이 개선될 것입니다. iOS. 그러나 변경 사항이 적용되는 데 시간이 걸릴 수 있으므로 현재 해...기술 주변기기 2024년 11월 19일에 게시됨
-
Tecno Pop 9 5G 안구는 iPhone 16과 같은 외관과 예산 사양으로 출시됩니다.Tecno는 후속 제품인 새로운 Phone16 및 16 Plus에서 표면적으로 영감을 받은 돌출된 카메라 혹을 위해 Pop 8의 기하학적 모양을 버릴 것이라고 확인했습니다. 최신 휴대폰은 Apple의 공간 비디오를 지원하지 않을 것 같습니다. 하지만 눈알을 주제로 한 ...기술 주변기기 2024년 11월 19일에 게시됨
-
Anker, Apple 제품용 새로운 Flow 소프트 터치 케이블 출시Anker Flow USB-A-Lightning 케이블(3피트, 실리콘)이 미국 Amazon에 도착했습니다. 이 액세서리는 올해 초 소문이 돌았고 브랜드의 USB-A에서 USB-C 및 USB-C에서 Lightning Upcycled Braided 케이블 직후에 출시되었...기술 주변기기 2024년 11월 19일에 게시됨
-
4K 패널과 90W USB C 포트로 새로워진 Xiaomi Redmi A27U 모니터Xiaomi는 최근 다양한 모니터를 출시했으며 그 중 일부는 전 세계적으로 판매되고 있습니다. 참고로 이 회사는 이달 초 미니 LED 게이밍 모니터(아마존 기준 329.99달러)를 북미 시장에 출시했다. 하지만 이제 Redmi A27U로 돌아왔고, 오늘은 다음 장치 출...기술 주변기기 2024년 11월 19일에 게시됨















중국어 공부
- 1 "걷다"를 중국어로 어떻게 말하나요? 走路 중국어 발음, 走路 중국어 학습
- 2 "비행기를 타다"를 중국어로 어떻게 말하나요? 坐飞机 중국어 발음, 坐飞机 중국어 학습
- 3 "기차를 타다"를 중국어로 어떻게 말하나요? 坐火车 중국어 발음, 坐火车 중국어 학습
- 4 "버스를 타다"를 중국어로 어떻게 말하나요? 坐车 중국어 발음, 坐车 중국어 학습
- 5 운전을 중국어로 어떻게 말하나요? 开车 중국어 발음, 开车 중국어 학습
- 6 수영을 중국어로 뭐라고 하나요? 游泳 중국어 발음, 游泳 중국어 학습
- 7 자전거를 타다 중국어로 뭐라고 하나요? 骑自行车 중국어 발음, 骑自行车 중국어 학습
- 8 중국어로 안녕하세요를 어떻게 말해요? 你好중국어 발음, 你好중국어 학습
- 9 감사합니다를 중국어로 어떻게 말하나요? 谢谢중국어 발음, 谢谢중국어 학습
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









