
기계 학습 분류 모델 평가
 검색:341
검색:341
개요
- 모델 평가의 목표는 무엇인가요?
- 모델 평가의 목적은 무엇이며, 일반적인 평가 절차는 무엇입니까?
- 분류 정확도의 사용법은 무엇이며 그 의미는 무엇입니까? 제한사항이 있나요?
- 혼란 행렬은 성능을 어떻게 설명합니까? 분류자?
- 혼란 행렬에서 어떤 측정항목을 계산할 수 있나요?
T모델 평가의 목표는 질문에 답하는 것입니다.
다른 모델 중에서 어떻게 선택하나요?
기계 학습을 평가하는 프로세스는 모델이 적용에 얼마나 안정적이고 효과적인지 결정하는 데 도움이 됩니다. 여기에는 성능, 지표, 예측 또는 의사 결정의 정확성과 같은 다양한 요소를 평가하는 작업이 포함됩니다.
어떤 모델을 선택하든 다양한 모델 유형, 튜닝 매개변수, 기능 등 모델 중에서 선택할 수 있는 방법이 필요합니다. 또한 모델이 보이지 않는 데이터에 얼마나 잘 일반화되는지 추정하려면 모델 평가 절차가 필요합니다. 마지막으로 모델 성능을 정량화하기 위해 다른 절차와 쌍을 이루는 평가 절차가 필요합니다.
진행하기 전에 다양한 모델 평가 절차와 작동 방식을 검토해 보겠습니다.
모델 평가 절차 및 작동 방식.
-
동일한 데이터에 대한 학습 및 테스트
- 훈련 데이터에 '과적 적합'하고 일반화할 필요가 없는 지나치게 복잡한 모델을 보상합니다.
-
학습/테스트 분할
- 데이터 세트를 두 부분으로 분할하여 모델을 다양한 데이터에 대해 훈련하고 테스트할 수 있습니다.
- 표본 외 성능에 대한 더 나은 추정치이지만 여전히 '높은 분산' 추정치입니다.
- 속도, 단순성, 유연성으로 인해 유용함
-
K-겹 교차 검증
- 체계적으로 "K" 학습/테스트 분할을 생성하고 결과의 평균을 구합니다.
- 샘플 외 성능에 대한 더 나은 예측
- 학습/테스트 분할보다 "K"배 느리게 실행됩니다.
위에서 다음과 같이 추론할 수 있습니다.
동일한 데이터에 대한 교육 및 테스트는 새 데이터에 일반화되지 않고 실제로 유용하지 않은 지나치게 복잡한 모델을 구축하는 과적합의 전형적인 원인입니다.
Train_Test_Split은 샘플 외 성능에 대해 훨씬 더 나은 추정치를 제공합니다.
K-폴드 교차 검증은 K 열차 테스트를 체계적으로 분할하고 결과를 함께 평균화함으로써 더 나은 성능을 발휘합니다.
요약하자면, train_tests_split은 속도와 단순성으로 인해 교차 검증에 여전히 수익성이 있으며, 이것이 바로 이 튜토리얼 가이드에서 사용할 것입니다.
모델 평가 지표:
선택한 절차를 진행하려면 항상 평가 지표가 필요하며, 지표 선택은 해결하려는 문제에 따라 달라집니다. 분류 문제의 경우 분류 정확도를 사용할 수 있습니다. 하지만 이 가이드에서는 다른 중요한 분류 평가 측정항목에 중점을 둘 것입니다.
새로운 평가 지표를 배우기 전에 '분류 정확도를 검토하고 강점과 약점에 대해 이야기해 보겠습니다.
분류 정확도
이 튜토리얼에서는 768명의 환자의 건강 데이터와 당뇨병 상태가 포함된 Pima Indians Diabetes 데이터세트를 선택했습니다.
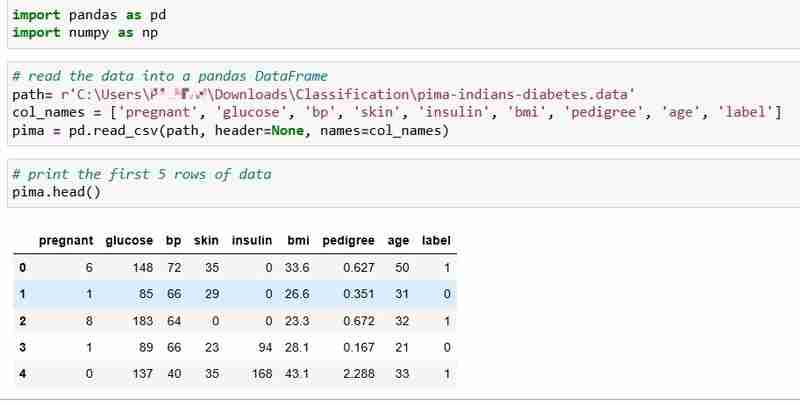
데이터를 읽고 데이터의 처음 5개 행을 인쇄해 보겠습니다. 라벨 열에는 환자에게 당뇨병이 있는 경우 1이 표시되고, 환자에게 당뇨병이 없는 경우 0이 표시되며, 우리는 다음 질문에 대답하려고 합니다.
질문: 환자의 건강 측정치를 토대로 환자의 당뇨병 상태를 예측할 수 있나요?
우리는 기능 메트릭 X와 응답 벡터 Y를 정의합니다. train_test_split을 사용하여 X와 Y를 훈련 및 테스트 세트로 분할합니다.
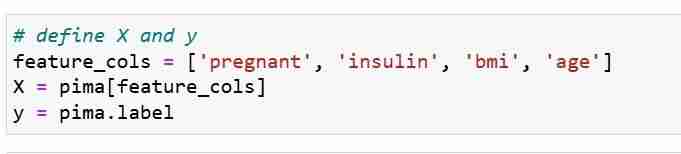
다음으로 훈련 세트에 대한 로지스틱 회귀 모델을 훈련합니다. 그런 다음 맞춤 단계 동안 logreg 모델 개체는 X_train과 Y_train 간의 관계를 학습합니다. 마지막으로 테스트 세트에 대한 클래스 예측을 수행합니다.
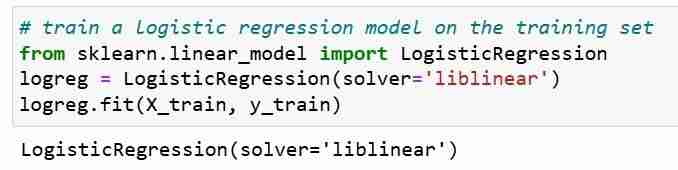

이제 테스트 세트에 대한 예측을 수행했으며 간단히 정확한 예측의 백분율인 분류 정확도를 계산할 수 있습니다.
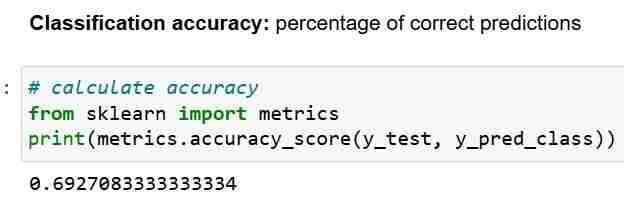
그러나 분류 정확도를 평가 지표로 사용할 때마다 이를 항상 가장 빈번한 클래스를 예측하여 달성할 수 있는 정확도인 Null 정확도와 비교하는 것이 중요합니다.

무 정확도가 질문에 답합니다. 내 모델이 지배적인 클래스를 100% 예측한다면 얼마나 자주 정확할까요? 위 시나리오에서 y_test의 32%는 1입니다. 즉, 환자에게 당뇨병이 있다고 예측하는 멍청한 모델은 시간의 68%(0)가 맞습니다. 이는 로지스틱 회귀를 측정할 수 있는 기준선을 제공합니다. 모델.
Null 정확도 68%와 모델 정확도 69%를 비교해 보면 우리 모델이 그다지 좋아 보이지는 않습니다. 이는 모델 평가 지표로서 분류 정확도의 한 가지 약점을 보여줍니다. 분류 정확도는 테스트 테스트의 기본 분포에 대해 아무 것도 알려주지 않습니다.
요약:
- 분류 정확도는 가장 이해하기 쉬운 분류 측정항목입니다
- 그러나 응답 값의 기본 분포 는 알려주지 않습니다.
- 그리고 분류기가 어떤 오류 '유형'을 알려주지 않습니다.
이제 혼동 행렬을 살펴보겠습니다.
혼란 매트릭스
혼란 행렬은 분류 모델의 성능을 설명하는 테이블입니다.
분류기의 성능을 이해하는 데 유용하지만 모델 평가 지표는 아닙니다. 따라서 scikit이 최고의 혼동 행렬을 사용하여 모델을 선택하도록 지시할 수 없습니다. 그러나 혼동 행렬에서 계산할 수 있는 측정항목이 많으며 모델을 선택하는 데 직접 사용할 수 있습니다.
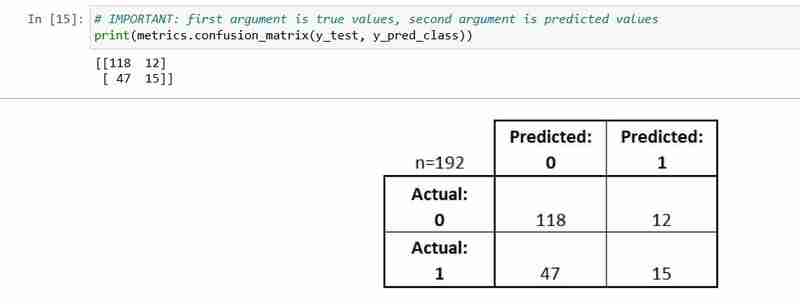
- 테스트 세트의 모든 관찰은 정확히 하나의 상자에 표시됩니다.
- 2개의 응답 클래스가 있으므로 2x2 행렬입니다.
- 여기에 표시된 형식은 보편적이지 않습니다
기본 용어 몇 가지를 설명하겠습니다.
- 참 긍정(TP): 우리는 정확하게 그들이 당뇨병을 앓고 있다고 예측했습니다
- 진음성(TN): 우리는 올바르게 그 사람들이 당뇨병에 걸리지 않는다고 예측했습니다
- 오탐지(FP): 우리는 당뇨병이 있다고 잘못 예측했습니다('제1종 오류')
- 거짓 부정(FN): 우리는 당뇨병이 없다고 잘못 예측했습니다('제2종 오류')
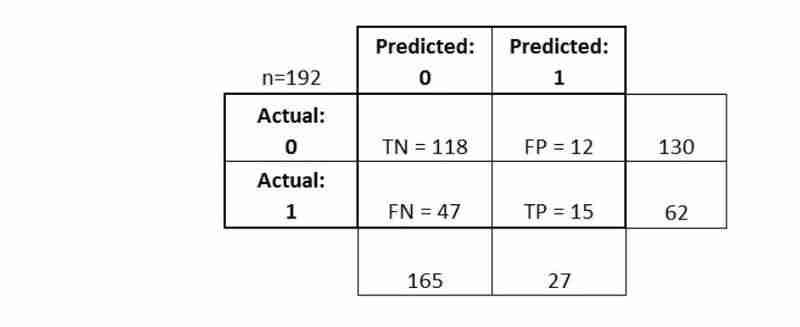


결론적으로:
- 혼동 행렬은 분류기의 성능에 대한
- 보다 완전한 그림을 제공합니다 또한 다양한
- 분류 지표를 계산할 수 있으며 이러한 지표는 모델 선택을 안내할 수 있습니다
-
 두 날짜 사이의 일 수를 계산하는 JavaScript 방법const date1 = 새로운 날짜 ( '7/13/2010'); const date2 = new 날짜 ('12/15/2010 '); const difftime = math.abs (date2 -date1); const diff...프로그램 작성 2025-07-14에 게시되었습니다
두 날짜 사이의 일 수를 계산하는 JavaScript 방법const date1 = 새로운 날짜 ( '7/13/2010'); const date2 = new 날짜 ('12/15/2010 '); const difftime = math.abs (date2 -date1); const diff...프로그램 작성 2025-07-14에 게시되었습니다 -
JavaScript 객체에서 키를 동적으로 설정하는 방법은 무엇입니까?jsobj = 'example'1; jsObj['key' i] = 'example' 1; 배열은 특수한 유형의 객체입니다. 그것들은 숫자 특성 (인치) + 1의 수를 반영하는 길이 속성을 유지합니다. 이 특별한 동작은 표준 객체에...프로그램 작성 2025-07-14에 게시되었습니다
-
파이썬에서 문자열에서 이모티콘을 제거하는 방법 : 일반적인 오류 수정에 대한 초보자 가이드?Codecs 가져 오기. 가져 오기 re text = codecs.decode ( '이 개 \ u0001f602'.encode ('utf-8 '),'utf-8 ') 인쇄 (텍스트) # 이모티콘으로 emoji_patter...프로그램 작성 2025-07-14에 게시되었습니다
-
regex를 사용하여 PHP에서 괄호 안에서 텍스트를 추출하는 방법$ fullstring = "이 (텍스트)을 제외한 모든 것을 무시하는 것"; $ start = strpos ( ', $ fullstring); $ fullString); $ shortstring = substr ($ fulls...프로그램 작성 2025-07-14에 게시되었습니다
-
입력 : "경고 : mysqli_query ()는 왜 매개 변수 1이 mysqli, 주어진 리소스"오류가 발생하고이를 수정하는 방법을 기대 하는가? 출력 : 오류를 해결하는 분석 및 수정 방법 "경고 : MySQLI_QUERY () 매개 변수는 리소스 대신 MySQLI 여야합니다."mysqli_query () mysqli_query ()는 매개 변수 1이 mysqli, 리소스가 주어진 리소스, mysqli_query () 함수를 사용하여 mysql query를 실행하려고 시도 할 때 "경고 : mysqli_query (...프로그램 작성 2025-07-14에 게시되었습니다
-
FormData ()로 여러 파일 업로드를 처리하려면 어떻게해야합니까?); 그러나이 코드는 첫 번째 선택된 파일 만 처리합니다. 파일 : var files = document.getElementById ( 'filetOUpload'). 파일; for (var x = 0; x프로그램 작성 2025-07-14에 게시되었습니다
-
열의 열이 다른 데이터베이스 테이블을 어떻게 통합하려면 어떻게해야합니까?다른 열이있는 결합 테이블 ] 는 데이터베이스 테이블을 다른 열로 병합하려고 할 때 도전에 직면 할 수 있습니다. 간단한 방법은 열이 적은 테이블의 누락 된 열에 null 값을 추가하는 것입니다. 예를 들어, 표 B보다 더 많은 열이있는 두 개의 테이블,...프로그램 작성 2025-07-14에 게시되었습니다
-
MySQL 오류 #1089 : 잘못된 접두사 키를 얻는 이유는 무엇입니까?오류 설명 [#1089- 잘못된 접두사 키 "는 테이블에서 열에 프리픽스 키를 만들려고 시도 할 때 나타날 수 있습니다. 접두사 키는 특정 접두사 길이의 문자열 열 길이를 색인화하도록 설계되었으며, 접두사를 더 빠르게 검색 할 수 있습니...프로그램 작성 2025-07-14에 게시되었습니다
-
Spring Security 4.1 이상에서 CORS 문제를 해결하기위한 안내서Spring Security 4.1 이후 Cors 지원을 활성화하기위한보다 간단한 접근 방식이 있습니다. webmvcconfigureradapter { @override public void addcorsmappings (corsregistry Registry) {...프로그램 작성 2025-07-14에 게시되었습니다
-
PHP 배열 키-값 이상 : 07 및 08의 호기심 사례 이해이 문제는 PHP의 주요 제로 해석에서 비롯됩니다. 숫자가 0 (예 : 07 또는 08)으로 접두사를 넣으면 PHP는 소수점 값이 아닌 옥탈 값 (기본 8)으로 해석합니다. 설명 : echo 07; // 인쇄 7 (10 월 07 = 10 진수 7) ...프로그램 작성 2025-07-14에 게시되었습니다
-
Google API에서 최신 JQuery 라이브러리를 검색하는 방법은 무엇입니까?https://code.jquery.com/jquery-latest.min.js (jQuery Hosted, Minified) https://code.jquery.com/jquery-latest.js (jquery hosted, Hosted, 비 압축) 압축...프로그램 작성 2025-07-14에 게시되었습니다
-
Visual Studio 2012의 DataSource 대화 상자에 MySQL 데이터베이스를 추가하는 방법은 무엇입니까?MySQL 커넥터 v.6.5.4가 설치되어 있지만 Entity 프레임 워크의 DataSource 대화 상자에 MySQL 데이터베이스를 추가 할 수 없습니다. 이를 해결하기 위해 MySQL 용 공식 Visual Studio 2012 통합은 MySQL 커넥터 v.6....프로그램 작성 2025-07-14에 게시되었습니다
-
MySQL에서 데이터를 피벗하여 그룹을 어떻게 사용할 수 있습니까?select d.data_timestamp, sum (data_id = 1 that data_value else 0 End), 'input_1'로 0 End), sum (data_id = 2 an Els.] d.data_timestamp ...프로그램 작성 2025-07-14에 게시되었습니다
-
순수한 CS로 여러 끈적 끈적한 요소를 서로 쌓을 수 있습니까?순수한 CSS에서 서로 위에 여러 개의 끈적 끈적 요소가 쌓일 수 있습니까? 원하는 동작을 볼 수 있습니다. 여기 : https://webthemez.com/demo/sticky-multi-header-scroll/index.html Java...프로그램 작성 2025-07-14에 게시되었습니다
-
HTML 서식 태그HTML 서식 요소 **HTML Formatting is a process of formatting text for better look and feel. HTML provides us ability to format text without...프로그램 작성 2025-07-14에 게시되었습니다















중국어 공부
- 1 "걷다"를 중국어로 어떻게 말하나요? 走路 중국어 발음, 走路 중국어 학습
- 2 "비행기를 타다"를 중국어로 어떻게 말하나요? 坐飞机 중국어 발음, 坐飞机 중국어 학습
- 3 "기차를 타다"를 중국어로 어떻게 말하나요? 坐火车 중국어 발음, 坐火车 중국어 학습
- 4 "버스를 타다"를 중국어로 어떻게 말하나요? 坐车 중국어 발음, 坐车 중국어 학습
- 5 운전을 중국어로 어떻게 말하나요? 开车 중국어 발음, 开车 중국어 학습
- 6 수영을 중국어로 뭐라고 하나요? 游泳 중국어 발음, 游泳 중국어 학습
- 7 자전거를 타다 중국어로 뭐라고 하나요? 骑自行车 중국어 발음, 骑自行车 중국어 학습
- 8 중국어로 안녕하세요를 어떻게 말해요? 你好중국어 발음, 你好중국어 학습
- 9 감사합니다를 중국어로 어떻게 말하나요? 谢谢중국어 발음, 谢谢중국어 학습
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









