
비교 최적화로 Python 정렬을 더 빠르게 만드는 방법
 검색:324
검색:324
이 텍스트에서는 Python과 언어의 참조 구현인 CPython이라는 용어가 같은 의미로 사용됩니다. 이 문서에서는 특히 CPython을 다루며 Python의 다른 구현과 관련이 없습니다.
Python은 프로그래머가 실제 구현의 복잡성을 이면에 남겨두고 간단한 용어로 자신의 아이디어를 표현할 수 있게 해주는 아름다운 언어입니다.
추상화하는 것 중 하나는 정렬입니다.
"파이썬에서 정렬이 어떻게 구현되나요?"라는 질문에 대한 답을 쉽게 찾을 수 있습니다. 이는 거의 항상 "파이썬은 어떤 정렬 알고리즘을 사용합니까?"라는 또 다른 질문에 답합니다.
그러나 이로 인해 흥미로운 구현 세부 사항이 뒤처지는 경우가 많습니다.
7년 전 Python 3.7에서 소개되었음에도 불구하고 충분히 논의되지 않은 구현 세부 사항이 하나 있습니다.
sorted() 및 list.sort()는 일반적인 경우에 최적화되어 최대 40~75% 더 빨라졌습니다. (bpo-28685의 Elliot Gorokhovsky가 제공)
하지만 시작하기 전에...
Python 정렬에 대한 간략한 재소개
파이썬에서 목록을 정렬해야 하는 경우 다음 두 가지 옵션이 있습니다.
- 목록 메소드: list.sort(*, key=None, reverse=False), 주어진 목록을 제자리에서 정렬합니다.
- 내장 함수: sorted(iterable, /, *, key=None, reverse= False), 인수 를 수정하지 않고 정렬된 목록을 반환합니다.
다른 내장 iterable을 정렬해야 하는 경우 iterable 유형이나 매개변수로 전달된 생성기에 관계없이 sorted만 사용할 수 있습니다.
sorted는 내부적으로 list.sort를 사용하기 때문에 항상 목록을 반환합니다.
다음은 순수 Python으로 재작성된 CPython의 정렬된 C 구현과 대략적으로 동등한 것입니다:
def sorted(iterable: Iterable[Any], key=None, reverse=False):
new_list = list(iterable)
new_list.sort(key=key, reverse=reverse)
return new_list
네, 아주 간단합니다.
Python이 정렬을 더 빠르게 만드는 방법
정렬에 대한 Python의 내부 문서에 따르면:
때때로 더 느린 일반 PyObject_RichCompareBool을 더 빠른 유형별 비교로 대체하는 것이 가능합니다.
요컨대 이 최적화는 다음과 같이 설명할 수 있습니다.
목록이 동질적일 때 Python은 유형별 비교 함수
를 사용합니다.
동종 목록이란 무엇입니까?
동질 목록은 한 가지 유형의 요소만 포함하는 목록입니다.
예를 들어:
homogeneous = [1, 2, 3, 4]
반면에 이것은 동질적인 목록이 아닙니다.
heterogeneous = [1, "2", (3, ), {'4': 4}]
흥미롭게도 공식 Python 튜토리얼에서는 다음과 같이 설명합니다.
목록은 변경 가능하며 해당 요소는 일반적으로 동종이며 목록을 반복하여 액세스합니다
튜플에 대한 추가 참고 사항
동일한 튜토리얼 내용:
튜플은 변경할 수 없으며 일반적으로 요소의 이질적인 시퀀스를 포함합니다
따라서 언제 튜플이나 리스트를 사용해야 하는지 궁금하다면 다음의 경험 법칙을 따르세요.
요소가 동일한 유형이면 목록을 사용하고, 그렇지 않으면 튜플
잠깐, 배열은 어떻습니까?
Python은 숫자 값에 대해 동종 배열 컨테이너 개체를 구현합니다.
그러나 Python 3.12부터 배열은 자체 정렬 방법을 구현하지 않습니다.
정렬하는 유일한 방법은 내부적으로 배열에서 목록을 생성하고 프로세스에서 모든 유형 관련 정보를 삭제하는 sorted를 사용하는 것입니다.
유형별 비교 기능을 사용하면 왜 도움이 되나요?
파이썬에서는 실제 비교를 수행하기 전에 다양한 검사를 수행하므로 비교에는 비용이 많이 듭니다.
다음은 Python에서 두 값을 비교할 때 내부적으로 어떤 일이 발생하는지에 대한 간단한 설명입니다.
- Python은 비교 함수에 전달된 값이 NULL이 아닌지 확인합니다.
- 값의 유형이 다르지만 오른쪽 피연산자가 왼쪽의 하위 유형인 경우 Python은 오른쪽 피연산자의 비교 함수를 사용하지만 그 반대입니다(예: >에
- 값이 동일한 유형이거나 다른 유형이지만 둘 다 다른 유형의 하위 유형이 아닌 경우:
- 파이썬은 먼저 왼쪽 피연산자의 비교 함수를 시도합니다.
- 실패하면 오른쪽 피연산자의 비교 함수를 시도하지만 그 반대입니다.
- 그것도 실패하고 비교가 같음 또는 같지 않음에 대한 것이라면 ID 비교를 반환합니다(메모리에서 동일한 개체를 참조하는 값의 경우 True).
- 그렇지 않으면 TypeError가 발생합니다.
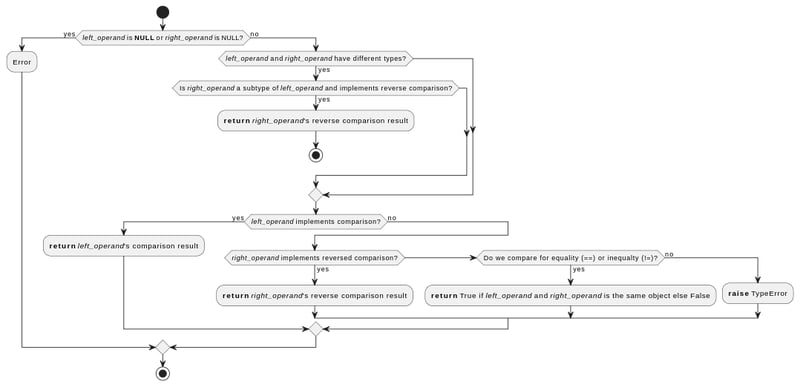
이 밖에도 각 유형별 자체 비교 기능을 통해 추가 검사를 구현합니다.
예를 들어, 문자열을 비교할 때 Python은 문자열 문자가 1바이트 이상의 메모리를 차지하는지 확인하고 부동 소수점 비교는 부동 소수점과 부동 소수점 및 int 쌍을 다르게 비교합니다.
더 자세한 설명과 다이어그램은 여기에서 찾을 수 있습니다: CPython에 데이터 인식 정렬 최적화 추가
이 최적화가 도입되기 전에 Python은 정렬 중에 두 값을 비교할 때마다 다양한 유형별 및 비유형별 검사를 모두 실행해야 했습니다.
목록 요소의 유형을 미리 확인하기
목록을 반복하고 각 요소를 확인하는 것 외에 목록의 모든 요소가 동일한 유형인지 알 수 있는 마법 같은 방법은 없습니다.
Python은 거의 정확하게 이를 수행합니다. list.sort에 전달되거나 매개변수로 정렬된 키 함수에 의해 생성된 정렬 키 유형을 확인합니다.
키 목록 구성
키 함수가 제공되면 Python은 이를 사용하여 키 목록을 구성하고, 그렇지 않으면 목록 자체 값을 정렬 키로 사용합니다.
너무 단순화된 방식으로 키 구성은 다음 Python 코드로 표현될 수 있습니다.
if key is None:
keys = list_items
else:
keys = [key(list_item) for list_item in list_item]
CPython에서 내부적으로 사용되는 키는 Python 목록이 아니라 CPython 객체 참조의 C 배열입니다.
키가 구성되면 Python은 해당 유형을 확인합니다.
키 유형 확인
키 유형을 확인할 때 Python의 정렬 알고리즘은 키 배열의 모든 요소가 str, int, float 또는 tuple인지, 아니면 기본 유형에 대한 몇 가지 제약 조건과 함께 단순히 동일한 유형인지 확인하려고 시도합니다.
키 유형을 확인하면 사전에 추가 작업이 추가된다는 점은 주목할 가치가 있습니다. Python이 이를 수행하는 이유는 특히 긴 목록의 경우 실제 정렬 속도를 더 빠르게 만들어 일반적으로 이점이 있기 때문입니다.
정수 제약
int는 빅넘이 안 됩니다
실질적으로 이는 이 최적화가 작동하려면 정수가 2^30 - 1(플랫폼에 따라 다를 수 있음)보다 작아야 함을 의미합니다.
참고로, Python이 큰 정수를 처리하는 방법을 설명하는 훌륭한 기사가 있습니다: # Python이 초장 정수를 구현하는 방법은 무엇입니까?
str 제약
문자열의 모든 문자는 1바이트 미만의 메모리를 차지해야 합니다. 즉, 0~255 범위의 정수 값으로 표현되어야 합니다.
실제로 이는 문자열이 라틴 문자, 공백 및 ASCII 테이블에 있는 일부 특수 문자로만 구성되어야 함을 의미합니다.
부동 제약조건
이 최적화가 작동하려면 부동 소수점에 대한 제약이 없습니다.
튜플 제약
- 첫 번째 요소의 유형만 확인합니다.
- 이 요소 자체는 튜플 자체가 아니어야 합니다.
- 모든 튜플이 첫 번째 요소에 대해 동일한 유형을 공유하는 경우 비교 최적화가 적용됩니다.
- 다른 모든 요소는 평소와 같이 비교됩니다.
이 지식을 어떻게 적용할 수 있습니까?
우선 알면 신기하지 않나요?
둘째, 이 지식을 언급하는 것은 Python 개발자 인터뷰에서 좋은 감동이 될 수 있습니다.
실제 코드 개발 시 이러한 최적화를 이해하면 정렬 성능을 향상시키는 데 도움이 될 수 있습니다.
가치 유형을 현명하게 선택하여 최적화
이 최적화를 도입한 PR의 벤치마크에 따르면 끝에 단일 정수가 있는 부동 소수점 목록이 아닌 부동 소수점만으로 구성된 목록을 정렬하는 것이 거의 두 배 빠릅니다.
그래서 최적화할 때가 되면 목록을 이렇게 변환하세요.
floats_and_int = [1.0, -1.0, -0.5, 3]
다음과 같은 목록으로
just_floats = [1.0, -1.0, -0.5, 3.0] # note that 3.0 is a float now
성능이 향상될 수 있습니다.
개체 목록에 대한 키를 사용하여 최적화
Python의 정렬 최적화는 내장 유형과 잘 작동하지만 사용자 정의 클래스와 상호 작용하는 방식을 이해하는 것이 중요합니다.
사용자 정의 클래스의 객체를 정렬할 때 Python은 __lt__(보다 작음) 또는 __gt__(보다 큼)과 같이 정의한 비교 방법을 사용합니다.
그러나 유형별 최적화는 맞춤 클래스에 적용되지 않습니다.
Python은 항상 이러한 객체에 대해 일반적인 비교 방법을 사용합니다.
예는 다음과 같습니다.
class MyClass:
def __init__(self, value):
self.value = value
def __lt__(self, other):
return self.value
이 경우 Python은 비교를 위해 __lt__ 메서드를 사용하지만 유형별 최적화의 이점은 없습니다. 정렬은 여전히 올바르게 작동하지만 내장 유형을 정렬하는 것만큼 빠르지는 않을 수 있습니다.
사용자 정의 개체를 정렬할 때 성능이 중요한 경우 내장 유형을 반환하는 주요 함수 사용을 고려해 보세요.
sorted_list = sorted(my_list, key=lambda x: x.value)
후문
특히 Python에서 조기 최적화는 해롭습니다.
CPython의 특정 최적화를 중심으로 전체 애플리케이션을 설계해서는 안 되지만 이러한 최적화에 대해 알아 두는 것이 좋습니다. 도구를 잘 아는 것이 더 숙련된 개발자가 되는 방법입니다.
다음과 같은 최적화에 주의를 기울이면 상황이 필요할 때, 특히 성능이 중요할 때 이를 활용할 수 있습니다.
타임스탬프를 기반으로 정렬하는 시나리오를 생각해 보세요. 날짜/시간 객체 대신 동질적인 정수 목록(Unix 타임스탬프)을 사용하면 이 최적화를 효과적으로 활용할 수 있습니다.
그러나 코드 가독성과 유지 관리 가능성이 이러한 최적화보다 우선해야 한다는 점을 기억하는 것이 중요합니다.
이러한 낮은 수준의 세부 사항을 아는 것도 중요하지만 Python을 생산적인 언어로 만드는 높은 수준의 추상화를 이해하는 것도 그만큼 중요합니다.
Python은 놀라운 언어입니다. Python의 깊이를 탐구하면 Python을 더 잘 이해하고 더 나은 Python 프로그래머가 될 수 있습니다.
-
 오른쪽 테이블의 where 조항에서 필터링 할 때 왼쪽 결합이 연결된 이유는 무엇입니까?다음 쿼리를 상상해보십시오 : select A.Foo, B. 바, c.foobar a로 테이블온에서 내부는 a.pk = b.fk에서 b로 tabletwo를 결합합니다 b.pk = c.fk에서 c as c로 왼쪽으로 결합하십시오 여기서 a.foo = '...프로그램 작성 2025-07-12에 게시되었습니다
오른쪽 테이블의 where 조항에서 필터링 할 때 왼쪽 결합이 연결된 이유는 무엇입니까?다음 쿼리를 상상해보십시오 : select A.Foo, B. 바, c.foobar a로 테이블온에서 내부는 a.pk = b.fk에서 b로 tabletwo를 결합합니다 b.pk = c.fk에서 c as c로 왼쪽으로 결합하십시오 여기서 a.foo = '...프로그램 작성 2025-07-12에 게시되었습니다 -
오른쪽에서 CSS 배경 이미지를 찾는 방법은 무엇입니까?/ 오른쪽에서 10px 요소를 배치하려면 / 배경 위치 : 오른쪽 10px 상단; 이 CSS 상단 코너는 오른쪽 상단의 왼쪽에서 10 pixels가되어야합니다. 요소의 상단 에지. 이 기능은 Internet Explorer 8 또는 이...프로그램 작성 2025-07-12에 게시되었습니다
-
전체 HTML 문서에서 특정 요소 유형의 첫 번째 인스턴스를 어떻게 스타일링하려면 어떻게해야합니까?javascript 솔루션 < /h2> : 최초의 유형 문서 전체를 달성합니다 유형의 첫 번째 요소와 일치하는 JavaScript 솔루션이 필요합니다. 문서에서 첫 번째 일치 요소를 선택하고 사용자 정의를 적용 할 수 있습니다. 그런 ...프로그램 작성 2025-07-12에 게시되었습니다
-
FormData ()로 여러 파일 업로드를 처리하려면 어떻게해야합니까?); 그러나이 코드는 첫 번째 선택된 파일 만 처리합니다. 파일 : var files = document.getElementById ( 'filetOUpload'). 파일; for (var x = 0; x프로그램 작성 2025-07-12에 게시되었습니다
-
두 날짜 사이의 일 수를 계산하는 JavaScript 방법const date1 = 새로운 날짜 ( '7/13/2010'); const date2 = new 날짜 ('12/15/2010 '); const difftime = math.abs (date2 -date1); const diff...프로그램 작성 2025-07-12에 게시되었습니다
-
동적 인 크기의 부모 요소 내에서 요소의 스크롤 범위를 제한하는 방법은 무엇입니까?문제 : 고정 된 사이드 바로 조정을 유지하면서 사용자의 수직 스크롤과 함께 이동하는 스크롤 가능한 맵 디브가있는 레이아웃을 고려합니다. 그러나 맵의 스크롤은 뷰포트의 높이를 초과하여 사용자가 페이지 바닥 글에 액세스하는 것을 방지합니다. ...프로그램 작성 2025-07-12에 게시되었습니다
-
regex를 사용하여 PHP에서 괄호 안에서 텍스트를 추출하는 방법$ fullstring = "이 (텍스트)을 제외한 모든 것을 무시하는 것"; $ start = strpos ( ', $ fullstring); $ fullString); $ shortstring = substr ($ fulls...프로그램 작성 2025-07-12에 게시되었습니다
-
교체 지시문을 사용하여 GO MOD에서 모듈 경로 불일치를 해결하는 방법은 무엇입니까?[ github.com/coreos/coreos/client github.com/coreos/etcd/client.test imports github.com/coreos/etcd/integration에 의해 테스트 된 Echoed 메시지에 의해 입증 된 바와...프로그램 작성 2025-07-12에 게시되었습니다
-
MySQL에서 데이터를 피벗하여 그룹을 어떻게 사용할 수 있습니까?select d.data_timestamp, sum (data_id = 1 that data_value else 0 End), 'input_1'로 0 End), sum (data_id = 2 an Els.] d.data_timestamp ...프로그램 작성 2025-07-12에 게시되었습니다
-
HTML 서식 태그HTML 서식 요소 **HTML Formatting is a process of formatting text for better look and feel. HTML provides us ability to format text without...프로그램 작성 2025-07-12에 게시되었습니다
-
버전 5.6.5 이전에 MySQL의 Timestamp 열을 사용하여 current_timestamp를 사용하는 데 제한 사항은 무엇입니까?5.6.5 이전에 mysql 버전의 기본적으로 또는 업데이트 클로즈가있는 타임 스탬프 열의 제한 사항 5.6.5 5.6.5 이전에 mySQL 버전에서 Timestamp Holumn에 전적으로 기본적으로 한 제한 사항이 있었는데, 이는 제한적으로 전혀 ...프로그램 작성 2025-07-12에 게시되었습니다
-
열의 열이 다른 데이터베이스 테이블을 어떻게 통합하려면 어떻게해야합니까?다른 열이있는 결합 테이블 ] 는 데이터베이스 테이블을 다른 열로 병합하려고 할 때 도전에 직면 할 수 있습니다. 간단한 방법은 열이 적은 테이블의 누락 된 열에 null 값을 추가하는 것입니다. 예를 들어, 표 B보다 더 많은 열이있는 두 개의 테이블,...프로그램 작성 2025-07-12에 게시되었습니다
-
익명의 JavaScript 이벤트 처리기를 깨끗하게 제거하는 방법은 무엇입니까?익명 이벤트 리스너를 제거하는 데 익명의 이벤트 리스너 추가 요소를 추가하면 유연성과 단순성을 제공하지만 유연성과 단순성을 제공하지만 제거 할 시간이되면 요소 자체를 교체하지 않고 도전 할 수 있습니다. 요소? element.addeventListene...프로그램 작성 2025-07-12에 게시되었습니다
-
Spring Security 4.1 이상에서 CORS 문제를 해결하기위한 안내서Spring Security 4.1 이후 Cors 지원을 활성화하기위한보다 간단한 접근 방식이 있습니다. webmvcconfigureradapter { @override public void addcorsmappings (corsregistry Registry) {...프로그램 작성 2025-07-12에 게시되었습니다
-
Object-Fit : IE 및 Edge에서 표지가 실패, 수정 방법?이 문제를 해결하기 위해 문제를 해결하는 영리한 CSS 솔루션을 사용합니다. -50%); 높이 : 100%; 너비 : 자동; // 수직 블록의 경우 높이 : 자동; 너비 : 100%; // 수평 블록의 경우 이 조합은 절대 포지셔닝을 사용하여 중앙에서 ...프로그램 작성 2025-07-12에 게시되었습니다















중국어 공부
- 1 "걷다"를 중국어로 어떻게 말하나요? 走路 중국어 발음, 走路 중국어 학습
- 2 "비행기를 타다"를 중국어로 어떻게 말하나요? 坐飞机 중국어 발음, 坐飞机 중국어 학습
- 3 "기차를 타다"를 중국어로 어떻게 말하나요? 坐火车 중국어 발음, 坐火车 중국어 학습
- 4 "버스를 타다"를 중국어로 어떻게 말하나요? 坐车 중국어 발음, 坐车 중국어 학습
- 5 운전을 중국어로 어떻게 말하나요? 开车 중국어 발음, 开车 중국어 학습
- 6 수영을 중국어로 뭐라고 하나요? 游泳 중국어 발음, 游泳 중국어 학습
- 7 자전거를 타다 중국어로 뭐라고 하나요? 骑自行车 중국어 발음, 骑自行车 중국어 학습
- 8 중국어로 안녕하세요를 어떻게 말해요? 你好중국어 발음, 你好중국어 학습
- 9 감사합니다를 중국어로 어떻게 말하나요? 谢谢중국어 발음, 谢谢중국어 학습
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









