
ClassiSage: Terraform IaC 자동화된 AWS SageMaker 기반 HDFS 로그 분류 모델
 검색:716
검색:716
ClassiSage
A Machine Learning model made with AWS SageMaker and its Python SDK for Classification of HDFS Logs using Terraform for automation of infrastructure setup.
Link: GitHub
Language: HCL (terraform), Python
Content
- Overview: Project Overview.
- System Architecture: System Architecture Diagram
- ML Model: Model Overview.
- Getting Started: How to run the project.
- Console Observations: Changes in instances and infrastructure that can be observed while running the project.
- Ending and Cleanup: Ensuring no additional charges.
- Auto Created Objects: Files and Folders created during execution process.
- Firstly follow the Directory Structure for better project setup.
- Take major reference from the ClassiSage's Project Repository uploaded in GitHub for better understanding.
Overview
- The model is made with AWS SageMaker for Classification of HDFS Logs along with S3 for storing dataset, Notebook file (containing code for SageMaker instance) and Model Output.
- The Infrastructure setup is automated using Terraform a tool to provide infrastructure-as-code created by HashiCorp
- The data set used is HDFS_v1.
- The project implements SageMaker Python SDK with the model XGBoost version 1.2
System Architecture
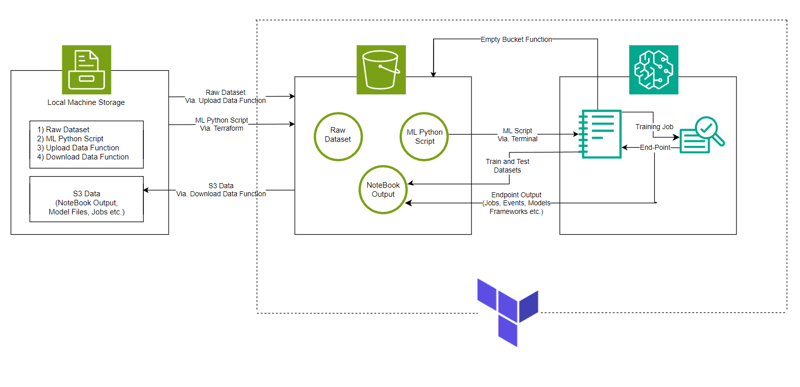
ML Model
- Image URI
# Looks for the XGBoost image URI and builds an XGBoost container. Specify the repo_version depending on preference.
container = get_image_uri(boto3.Session().region_name,
'xgboost',
repo_version='1.0-1')

- Initializing Hyper Parameter and Estimator call to the container
hyperparameters = {
"max_depth":"5", ## Maximum depth of a tree. Higher means more complex models but risk of overfitting.
"eta":"0.2", ## Learning rate. Lower values make the learning process slower but more precise.
"gamma":"4", ## Minimum loss reduction required to make a further partition on a leaf node. Controls the model’s complexity.
"min_child_weight":"6", ## Minimum sum of instance weight (hessian) needed in a child. Higher values prevent overfitting.
"subsample":"0.7", ## Fraction of training data used. Reduces overfitting by sampling part of the data.
"objective":"binary:logistic", ## Specifies the learning task and corresponding objective. binary:logistic is for binary classification.
"num_round":50 ## Number of boosting rounds, essentially how many times the model is trained.
}
# A SageMaker estimator that calls the xgboost-container
estimator = sagemaker.estimator.Estimator(image_uri=container, # Points to the XGBoost container we previously set up. This tells SageMaker which algorithm container to use.
hyperparameters=hyperparameters, # Passes the defined hyperparameters to the estimator. These are the settings that guide the training process.
role=sagemaker.get_execution_role(), # Specifies the IAM role that SageMaker assumes during the training job. This role allows access to AWS resources like S3.
train_instance_count=1, # Sets the number of training instances. Here, it’s using a single instance.
train_instance_type='ml.m5.large', # Specifies the type of instance to use for training. ml.m5.2xlarge is a general-purpose instance with a balance of compute, memory, and network resources.
train_volume_size=5, # 5GB # Sets the size of the storage volume attached to the training instance, in GB. Here, it’s 5 GB.
output_path=output_path, # Defines where the model artifacts and output of the training job will be saved in S3.
train_use_spot_instances=True, # Utilizes spot instances for training, which can be significantly cheaper than on-demand instances. Spot instances are spare EC2 capacity offered at a lower price.
train_max_run=300, # Specifies the maximum runtime for the training job in seconds. Here, it's 300 seconds (5 minutes).
train_max_wait=600) # Sets the maximum time to wait for the job to complete, including the time waiting for spot instances, in seconds. Here, it's 600 seconds (10 minutes).
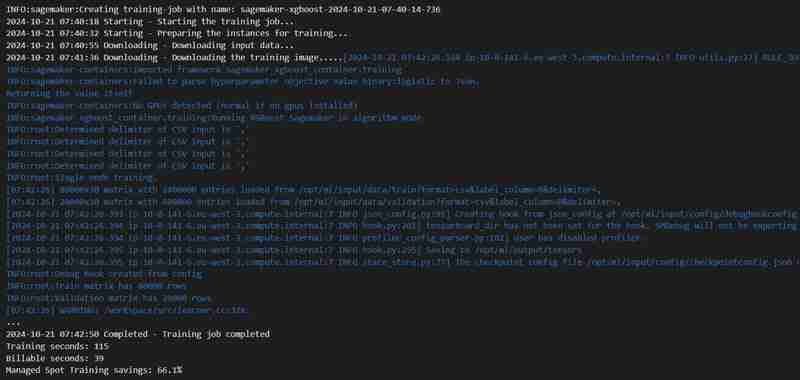
- Training Job
estimator.fit({'train': s3_input_train,'validation': s3_input_test})
- Deployment
xgb_predictor = estimator.deploy(initial_instance_count=1,instance_type='ml.m5.large')

- Validation
from sagemaker.serializers import CSVSerializer
import numpy as np
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix
# Drop the label column from the test data
test_data_features = test_data_final.drop(columns=['Label']).values
# Set the content type and serializer
xgb_predictor.serializer = CSVSerializer()
xgb_predictor.content_type = 'text/csv'
# Perform prediction
predictions = xgb_predictor.predict(test_data_features).decode('utf-8')
y_test = test_data_final['Label'].values
# Convert the predictions into a array
predictions_array = np.fromstring(predictions, sep=',')
print(predictions_array.shape)
# Converting predictions them to binary (0 or 1)
threshold = 0.5
binary_predictions = (predictions_array >= threshold).astype(int)
# Accuracy
accuracy = accuracy_score(y_test, binary_predictions)
# Precision
precision = precision_score(y_test, binary_predictions)
# Recall
recall = recall_score(y_test, binary_predictions)
# F1 Score
f1 = f1_score(y_test, binary_predictions)
# Confusion Matrix
cm = confusion_matrix(y_test, binary_predictions)
# False Positive Rate (FPR) using the confusion matrix
tn, fp, fn, tp = cm.ravel()
false_positive_rate = fp / (fp tn)
# Print the metrics
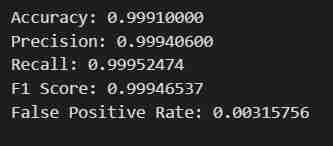
print(f"Accuracy: {accuracy:.8f}")
print(f"Precision: {precision:.8f}")
print(f"Recall: {recall:.8f}")
print(f"F1 Score: {f1:.8f}")
print(f"False Positive Rate: {false_positive_rate:.8f}")
Getting Started
- Clone the repository using Git Bash / download a .zip file / fork the repository.
- Go to your AWS Management Console, click on your account profile on the Top-Right corner and select My Security Credentials from the dropdown.
- Create Access Key: In the Access keys section, click on Create New Access Key, a dialog will appear with your Access Key ID and Secret Access Key.
- Download or Copy Keys: (IMPORTANT) Download the .csv file or copy the keys to a secure location. This is the only time you can view the secret access key.
- Open the cloned Repo. in your VS Code
- Create a file under ClassiSage as terraform.tfvars with its content as
# terraform.tfvars access_key = "" secret_key = " " aws_account_id = " "
- Download and install all the dependancies for using Terraform and Python.
In the terminal type/paste terraform init to initialize the backend.
Then type/paste terraform Plan to view the plan or simply terraform validate to ensure that there is no error.
Finally in the terminal type/paste terraform apply --auto-approve
This will show two outputs one as bucket_name other as pretrained_ml_instance_name (The 3rd resource is the variable name given to the bucket since they are global resources ).
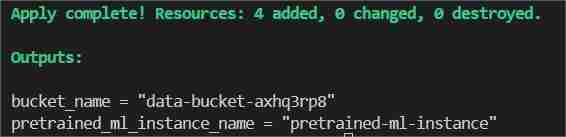
- After Completion of the command is shown in the terminal, navigate to ClassiSage/ml_ops/function.py and on the 11th line of the file with code
output = subprocess.check_output('terraform output -json', shell=True, cwd = r'' #C:\Users\Saahen\Desktop\ClassiSage
and change it to the path where the project directory is present and save it.
- Then on the ClassiSage\ml_ops\data_upload.ipynb run all code cell till cell number 25 with the code
# Try to upload the local CSV file to the S3 bucket
try:
print(f"try block executing")
s3.upload_file(
Filename=local_file_path,
Bucket=bucket_name,
Key=file_key # S3 file key (filename in the bucket)
)
print(f"Successfully uploaded {file_key} to {bucket_name}")
# Delete the local file after uploading to S3
os.remove(local_file_path)
print(f"Local file {local_file_path} deleted after upload.")
except Exception as e:
print(f"Failed to upload file: {e}")
os.remove(local_file_path)
to upload dataset to S3 Bucket.
- Output of the code cell execution

- After the execution of the notebook re-open your AWS Management Console.
- You can search for S3 and Sagemaker services and will see an instance of each service initiated (A S3 bucket and a SageMaker Notebook)
S3 Bucket with named 'data-bucket-' with 2 objects uploaded, a dataset and the pretrained_sm.ipynb file containing model code.
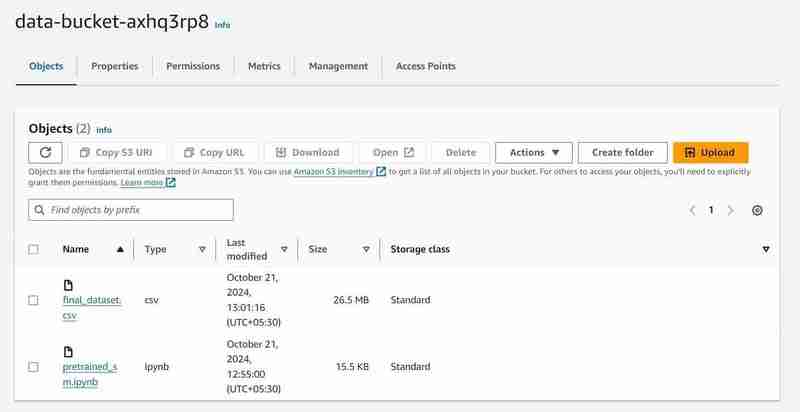
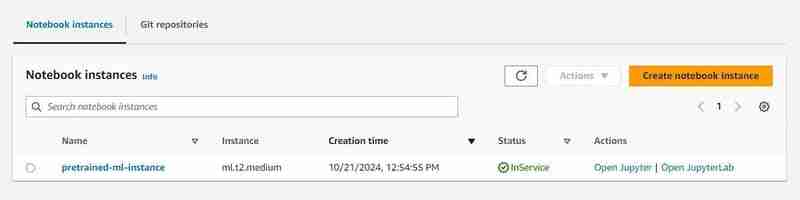
- Go to the notebook instance in the AWS SageMaker, click on the created instance and click on open Jupyter.
- After that click on new on the top right side of the window and select on terminal.
- This will create a new terminal.
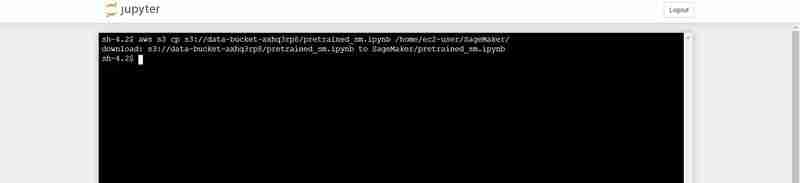
- On the terminal paste the following (Replacing with the bucket_name output that is shown in the VS Code's terminal output):
aws s3 cp s3:///pretrained_sm.ipynb /home/ec2-user/SageMaker/
Terminal command to upload the pretrained_sm.ipynb from S3 to Notebook's Jupyter environment
- Go Back to the opened Jupyter instance and click on the pretrained_sm.ipynb file to open it and assign it a conda_python3 Kernel.
- Scroll Down to the 4th cell and replace the variable bucket_name's value by the VS Code's terminal output for bucket_name = "
"
# S3 bucket, region, session
bucket_name = 'data-bucket-axhq3rp8'
my_region = boto3.session.Session().region_name
sess = boto3.session.Session()
print("Region is " my_region " and bucket is " bucket_name)
Output of the code cell execution

- On the top of the file do a Restart by going to the Kernel tab.
- Execute the Notebook till code cell number 27, with the code
# Print the metrics
print(f"Accuracy: {accuracy:.8f}")
print(f"Precision: {precision:.8f}")
print(f"Recall: {recall:.8f}")
print(f"F1 Score: {f1:.8f}")
print(f"False Positive Rate: {false_positive_rate:.8f}")
- You will get the intended result. The data will be fetched, split into train and test sets after being adjusted for Labels and Features with a defined output path, then a model using SageMaker's Python SDK will be Trained, Deployed as a EndPoint, Validated to give different metrics.
Console Observation Notes
Execution of 8th cell
# Set an output path where the trained model will be saved
prefix = 'pretrained-algo'
output_path ='s3://{}/{}/output'.format(bucket_name, prefix)
print(output_path)
- An output path will be setup in the S3 to store model data.
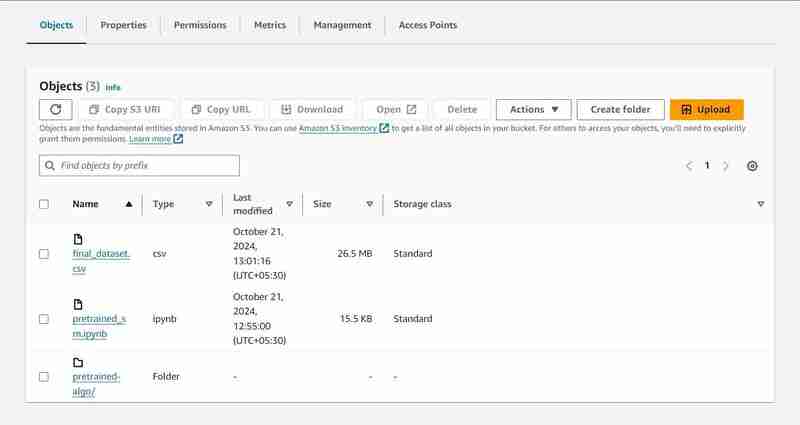
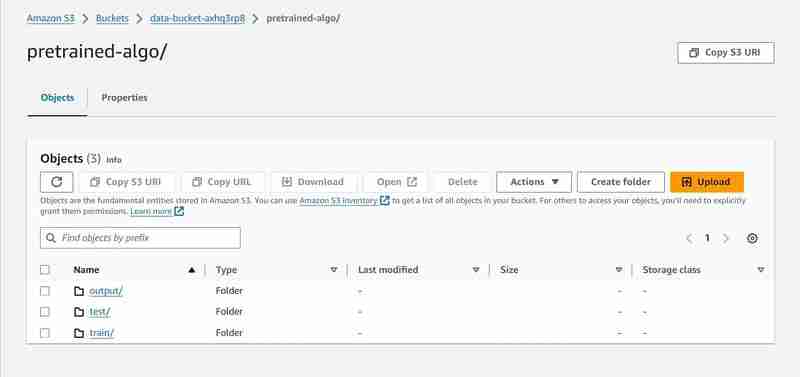
Execution of 23rd cell
estimator.fit({'train': s3_input_train,'validation': s3_input_test})
- A training job will start, you can check it under the training tab.
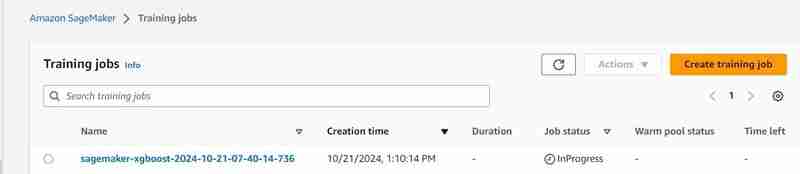
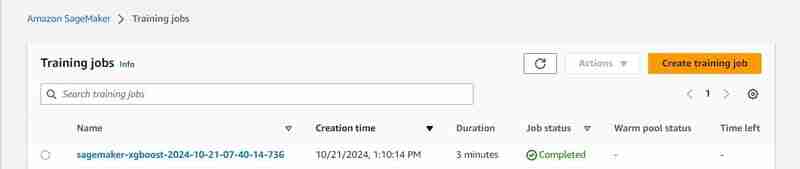
- After some time (3 mins est.) It shall be completed and will show the same.
Execution of 24th code cell
xgb_predictor = estimator.deploy(initial_instance_count=1,instance_type='ml.m5.large')
- An endpoint will be deployed under Inference tab.
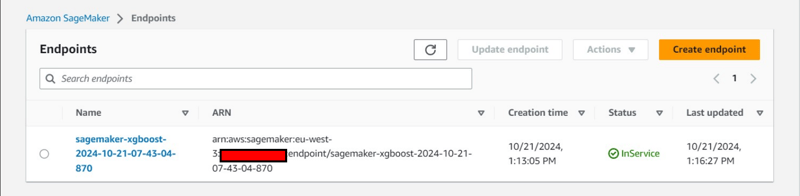
Additional Console Observation:
- Creation of an Endpoint Configuration under Inference tab.
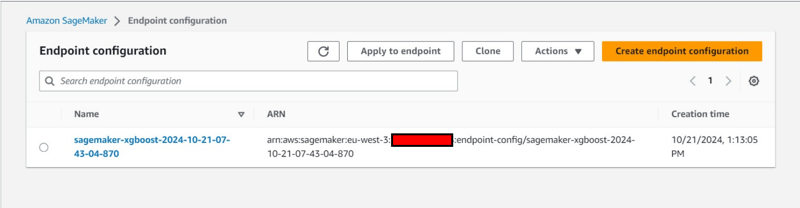
- Creation of an model also under under Inference tab.
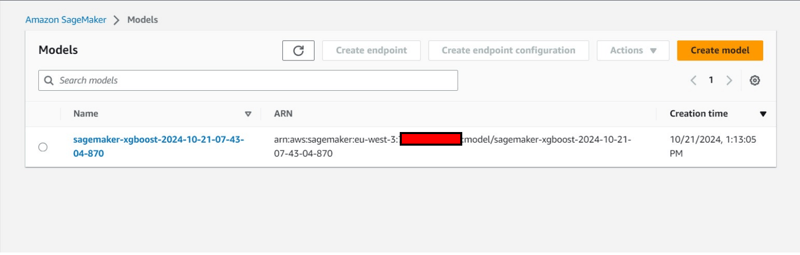
Ending and Cleanup
- In the VS Code comeback to data_upload.ipynb to execute last 2 code cells to download the S3 bucket's data into the local system.
- The folder will be named downloaded_bucket_content. Directory Structure of folder Downloaded.
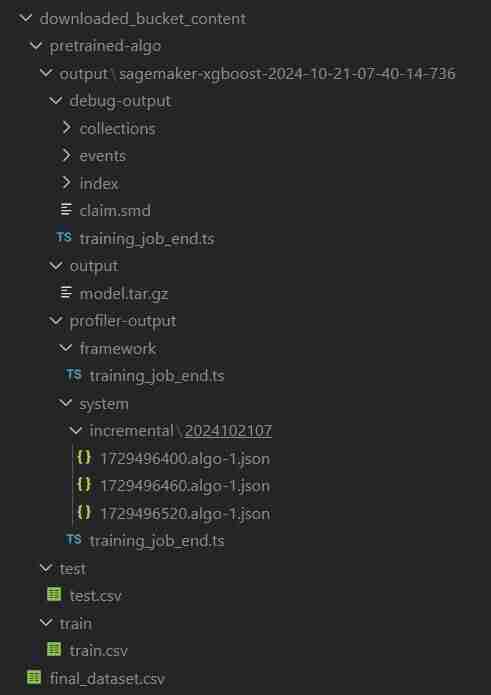
- You will get a log of downloaded files in the output cell. It will contain a raw pretrained_sm.ipynb, final_dataset.csv and a model output folder named 'pretrained-algo' with the execution data of the sagemaker code file.
- Finally go into pretrained_sm.ipynb present inside the SageMaker instance and execute the final 2 code cells. The end-point and the resources within the S3 bucket will be deleted to ensure no additional charges.
- Deleting The EndPoint
sagemaker.Session().delete_endpoint(xgb_predictor.endpoint)

- Clearing S3: (Needed to destroy the instance)
bucket_to_delete = boto3.resource('s3').Bucket(bucket_name)
bucket_to_delete.objects.all().delete()
- Come back to the VS Code terminal for the project file and then type/paste terraform destroy --auto-approve
- All the created resource instances will be deleted.
Auto Created Objects
ClassiSage/downloaded_bucket_content
ClassiSage/.terraform
ClassiSage/ml_ops/pycache
ClassiSage/.terraform.lock.hcl
ClassiSage/terraform.tfstate
ClassiSage/terraform.tfstate.backup
NOTE:
If you liked the idea and the implementation of this Machine Learning Project using AWS Cloud's S3 and SageMaker for HDFS log classification, using Terraform for IaC (Infrastructure setup automation), Kindly consider liking this post and starring after checking-out the project repository at GitHub.
-
 McRypt에서 OpenSSL로 암호화를 마이그레이션하고 OpenSSL을 사용하여 McRypt 암호화 데이터를 해제 할 수 있습니까?질문 : McRypt에서 OpenSSL로 내 암호화 라이브러리를 업그레이드 할 수 있습니까? 그렇다면 어떻게? 대답 : 대답 : 예, McRypt에서 암호화 라이브러리를 OpenSSL로 업그레이드 할 수 있습니다. OpenSSL을 사용하여 McRyp...프로그램 작성 2025-07-03에 게시되었습니다
McRypt에서 OpenSSL로 암호화를 마이그레이션하고 OpenSSL을 사용하여 McRypt 암호화 데이터를 해제 할 수 있습니까?질문 : McRypt에서 OpenSSL로 내 암호화 라이브러리를 업그레이드 할 수 있습니까? 그렇다면 어떻게? 대답 : 대답 : 예, McRypt에서 암호화 라이브러리를 OpenSSL로 업그레이드 할 수 있습니다. OpenSSL을 사용하여 McRyp...프로그램 작성 2025-07-03에 게시되었습니다 -
FormData ()로 여러 파일 업로드를 처리하려면 어떻게해야합니까?); 그러나이 코드는 첫 번째 선택된 파일 만 처리합니다. 파일 : var files = document.getElementById ( 'filetOUpload'). 파일; for (var x = 0; x프로그램 작성 2025-07-03에 게시되었습니다
-
\ "일반 오류 : 2006 MySQL Server가 사라졌습니다 \"데이터를 삽입 할 때?"일반 오류 : 2006 MySQL Server가 사라졌습니다. 이 오류는 일반적으로 MySQL 구성의 두 변수 중 하나로 인해 서버에 대한 연결이 손실 될 때 발생합니다. 솔루션 : 이 오류를 해결하기위한 키는 Wait_Timeout 및 ...프로그램 작성 2025-07-03에 게시되었습니다
-
유효한 코드에도 불구하고 PHP의 입력을 캡처하는 사후 요청이없는 이유는 무엇입니까?post request 오작동 주소 php action='' action = "프로그램 작성 2025-07-03에 게시되었습니다
-
교체 지시문을 사용하여 GO MOD에서 모듈 경로 불일치를 해결하는 방법은 무엇입니까?[ github.com/coreos/coreos/client github.com/coreos/etcd/client.test imports github.com/coreos/etcd/integration에 의해 테스트 된 Echoed 메시지에 의해 입증 된 바와...프로그램 작성 2025-07-03에 게시되었습니다
-
Java는 여러 반환 유형을 허용합니까 : 일반적인 방법을 자세히 살펴보십시오.public 목록 getResult (문자열 s); 여기서 foo는 사용자 정의 클래스입니다. 이 방법 선언은 두 가지 반환 유형을 자랑하는 것처럼 보입니다. 목록과 E. 그러나 이것이 사실인가? 일반 방법 : 미스터리 메소드는 단일...프로그램 작성 2025-07-03에 게시되었습니다
-
PostgreSQL의 각 고유 식별자에 대한 마지막 행을 효율적으로 검색하는 방법은 무엇입니까?postgresql : 각각의 고유 식별자에 대한 마지막 행을 추출하는 select distinct on (id) id, date, another_info from the_table order by id, date desc; id ...프로그램 작성 2025-07-03에 게시되었습니다
-
Visual Studio 2012의 DataSource 대화 상자에 MySQL 데이터베이스를 추가하는 방법은 무엇입니까?MySQL 커넥터 v.6.5.4가 설치되어 있지만 Entity 프레임 워크의 DataSource 대화 상자에 MySQL 데이터베이스를 추가 할 수 없습니다. 이를 해결하기 위해 MySQL 용 공식 Visual Studio 2012 통합은 MySQL 커넥터 v.6....프로그램 작성 2025-07-03에 게시되었습니다
-
MySQL 오류 #1089 : 잘못된 접두사 키를 얻는 이유는 무엇입니까?오류 설명 [#1089- 잘못된 접두사 키 "는 테이블에서 열에 프리픽스 키를 만들려고 시도 할 때 나타날 수 있습니다. 접두사 키는 특정 접두사 길이의 문자열 열 길이를 색인화하도록 설계되었으며, 접두사를 더 빠르게 검색 할 수 있습니...프로그램 작성 2025-07-03에 게시되었습니다
-
오른쪽 테이블의 where 조항에서 필터링 할 때 왼쪽 결합이 연결된 이유는 무엇입니까?다음 쿼리를 상상해보십시오 : select A.Foo, B. 바, c.foobar a로 테이블온에서 내부는 a.pk = b.fk에서 b로 tabletwo를 결합합니다 b.pk = c.fk에서 c as c로 왼쪽으로 결합하십시오 여기서 a.foo = '...프로그램 작성 2025-07-03에 게시되었습니다
-
PHP를 사용하여 XML 파일에서 속성 값을 효율적으로 검색하려면 어떻게해야합니까?옵션> 1 varnum "varnum"을 복원 할 수 있습니다. stumped. 이 기능은 XML 요소의 속성에 대한 액세스를 연관 배열로 제공합니다. $ xml = simplexml_load_file ($ file);...프로그램 작성 2025-07-03에 게시되었습니다
-
익명의 JavaScript 이벤트 처리기를 깨끗하게 제거하는 방법은 무엇입니까?익명 이벤트 리스너를 제거하는 데 익명의 이벤트 리스너 추가 요소를 추가하면 유연성과 단순성을 제공하지만 유연성과 단순성을 제공하지만, 그것들을 제거 할 시간이되면, 요소 자체를 교체하지 않고 도전 할 수 있습니다. 요소? element.addevent...프로그램 작성 2025-07-03에 게시되었습니다
-
\ "(1) 대 (;;) : 컴파일러 최적화는 성능 차이를 제거합니까? \"대답 : 대부분의 최신 컴파일러에는 (1)과 (;;). 컴파일러 : s-> 7 8 v-> 4를 풀립니다 -e syntax ok gcc : GCC에서 두 루프는 다음과 같이 동일한 어셈블리 코드로 컴파일합니다. . t_while : ...프로그램 작성 2025-07-03에 게시되었습니다
-
Firefox Back 버튼을 사용할 때 JavaScript 실행이 중단되는 이유는 무엇입니까?원인 및 솔루션 : 이 동작은 브라우저 캐싱 자바 스크립트 리소스에 의해 발생합니다. 이 문제를 해결하고 후속 페이지 방문에서 스크립트가 실행되도록하기 위해 Firefox 사용자는 Window.onload 이벤트에서 호출되도록 빈 기능을 설정해야합니다. ...프로그램 작성 2025-07-03에 게시되었습니다
-
순수한 CS로 여러 끈적 끈적한 요소를 서로 쌓을 수 있습니까?순수한 CSS에서 서로 위에 여러 개의 끈적 끈적 요소가 쌓일 수 있습니까? 원하는 동작을 볼 수 있습니다. 여기 : https://webthemez.com/demo/sticky-multi-header-scroll/index.html Java...프로그램 작성 2025-07-03에 게시되었습니다















중국어 공부
- 1 "걷다"를 중국어로 어떻게 말하나요? 走路 중국어 발음, 走路 중국어 학습
- 2 "비행기를 타다"를 중국어로 어떻게 말하나요? 坐飞机 중국어 발음, 坐飞机 중국어 학습
- 3 "기차를 타다"를 중국어로 어떻게 말하나요? 坐火车 중국어 발음, 坐火车 중국어 학습
- 4 "버스를 타다"를 중국어로 어떻게 말하나요? 坐车 중국어 발음, 坐车 중국어 학습
- 5 운전을 중국어로 어떻게 말하나요? 开车 중국어 발음, 开车 중국어 학습
- 6 수영을 중국어로 뭐라고 하나요? 游泳 중국어 발음, 游泳 중국어 학습
- 7 자전거를 타다 중국어로 뭐라고 하나요? 骑自行车 중국어 발음, 骑自行车 중국어 학습
- 8 중국어로 안녕하세요를 어떻게 말해요? 你好중국어 발음, 你好중국어 학습
- 9 감사합니다를 중국어로 어떻게 말하나요? 谢谢중국어 발음, 谢谢중국어 학습
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









