
Adaptive Analytics 솔루션으로 AI/ML 연결
 검색:363
검색:363
오늘날의 데이터 환경에서 기업은 다양한 과제에 직면해 있습니다. 그 중 하나는 모든 소비자가 사용할 수 있는 통합되고 조화된 데이터 계층을 기반으로 분석을 수행하는 것입니다. 사용되는 방언이나 도구와 상관없이 동일한 질문에 대해 동일한 답변을 전달할 수 있는 레이어입니다.
InterSystems IRIS 데이터 플랫폼은 통합된 의미 계층을 제공할 수 있는 Adaptive Analytics의 추가 기능으로 이에 답합니다. DevCommunity에는 BI 도구를 통해 사용하는 방법에 대한 많은 기사가 있습니다. 이번 글에서는 AI로 이를 소비하는 방법과 인사이트를 되살리는 방법에 대한 부분을 다룰 것입니다.
한걸음씩 나아가자...
적응형 분석이란 무엇입니까?
개발자 커뮤니티 웹사이트에서 일부 정의를 쉽게 찾을 수 있습니다.
간단히 말해서, 추가 소비 및 분석을 위해 선택한 다양한 도구에 구조화되고 조화된 형태로 데이터를 전달할 수 있습니다. 다양한 BI 도구에 동일한 데이터 구조를 제공합니다. 하지만... AI/ML 도구에 동일한 데이터 구조를 제공할 수도 있습니다!
Adaptive Analytics에는 AI에서 BI로의 연결을 구축하는 AI-Link라는 추가 구성 요소가 있습니다.
AI-Link란 정확히 무엇인가요?
기계 학습(ML) 워크플로(예: 기능 엔지니어링)의 주요 단계를 간소화하기 위해 의미 계층과 프로그래밍 방식으로 상호 작용할 수 있도록 설계된 Python 구성 요소입니다.
AI-Link를 사용하면 다음을 수행할 수 있습니다.
- 분석 데이터 모델의 기능에 프로그래밍 방식으로 액세스합니다.
- 쿼리 작성, 차원 및 측정값 탐색,
- ML 파이프라인에 피드를 제공합니다. ... 그리고 다른 사람이 다시 사용할 수 있도록 결과를 의미 체계 계층으로 다시 전달합니다(예: Tableau 또는 Excel을 통해).
Python 라이브러리이므로 어떤 Python 환경에서도 사용할 수 있습니다. 노트북도 포함됩니다.
그리고 이 기사에서는 AI-Link의 도움으로 Jupyter Notebook에서 Adaptive Analytics 솔루션에 도달하는 간단한 예를 제시하겠습니다.
다음은 완전한 노트북을 포함하는 git 저장소입니다: https://github.com/v23ent/aa-hands-on
전제조건
추가 단계에서는 다음 사전 요구 사항이 완료되었다고 가정합니다.
- 적응형 분석 솔루션 실행 중(IRIS 데이터 플랫폼을 데이터 웨어하우스로 사용)
- Jupyter Notebook 실행 중
- 1.과 2.간의 연결이 가능합니다.
1단계: 설정
먼저 우리 환경에 필요한 구성 요소를 설치해 보겠습니다. 그러면 추가 단계 작업에 필요한 몇 가지 패키지가 다운로드됩니다.
'atscale' - 연결을 위한 주요 패키지입니다
'선지자' - 예측을 수행하는 데 필요한 패키지
pip install atscale prophet
그런 다음 의미 계층의 일부 주요 개념을 나타내는 주요 클래스를 가져와야 합니다.
클라이언트 - Adaptive Analytics에 대한 연결을 설정하는 데 사용할 클래스입니다.
프로젝트 - Adaptive Analytics 내부의 프로젝트를 나타내는 클래스입니다.
DataModel - 가상 큐브를 나타내는 클래스
from atscale.client import Client from atscale.data_model import DataModel from atscale.project import Project from prophet import Prophet import pandas as pd
2단계: 연결
이제 데이터 소스에 대한 연결 설정이 모두 완료되었습니다.
client = Client(server='http://adaptive.analytics.server', username='sample') client.connect()
Adaptive Analytics 인스턴스의 연결 세부 정보를 지정하세요. 대화 상자에서 조직의 응답을 요청한 후 AtScale 인스턴스의 비밀번호를 입력하세요.
연결이 설정되면 서버에 게시된 프로젝트 목록에서 프로젝트를 선택해야 합니다. 대화형 프롬프트로 프로젝트 목록이 표시되며 대답은 프로젝트의 정수 ID여야 합니다. 그런 다음 데이터 모델이 유일한 경우 자동으로 선택됩니다.
project = client.select_project() data_model = project.select_data_model()
3단계: 데이터 세트 탐색
AI-Link 컴포넌트 라이브러리에는 AtScale에서 준비한 여러 메소드가 있습니다. 보유한 데이터 카탈로그를 탐색하고, 데이터를 쿼리하고, 일부 데이터를 다시 수집할 수도 있습니다. AtScale 문서에는 사용 가능한 모든 것을 설명하는 광범위한 API 참조가 있습니다.
먼저 data_model의 몇 가지 메소드를 호출하여 데이터 세트가 무엇인지 살펴보겠습니다:
data_model.get_features() data_model.get_all_categorical_feature_names() data_model.get_all_numeric_feature_names()
출력은 다음과 같아야 합니다.
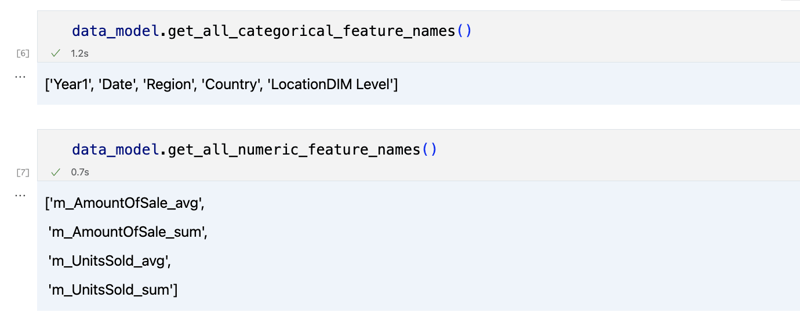
조금 둘러본 후 'get_data' 메소드를 사용하여 관심 있는 실제 데이터를 쿼리할 수 있습니다. 쿼리 결과가 포함된 Pandas DataFrame을 반환합니다.
df = data_model.get_data(feature_list = ['Country','Region','m_AmountOfSale_sum']) df = df.sort_values(by='m_AmountOfSale_sum') df.head()
귀하의 데이터드램이 표시됩니다:
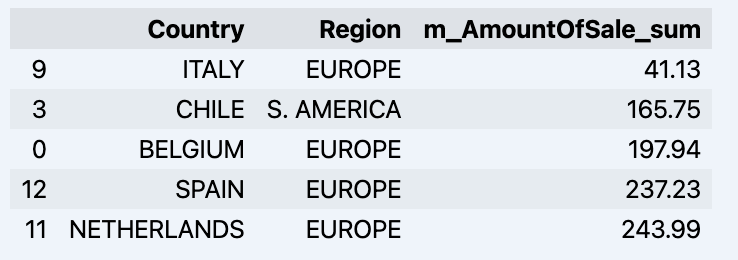
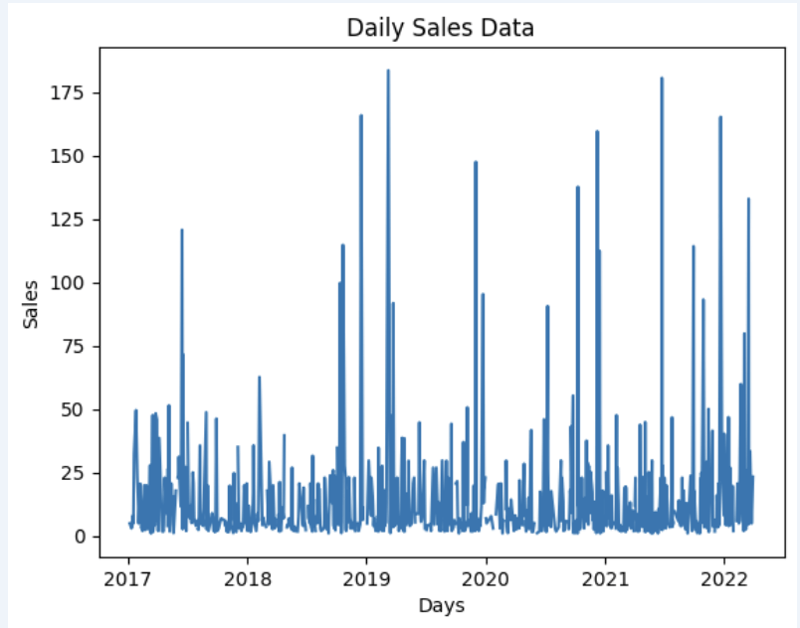
데이터 세트를 준비하고 빠르게 그래프에 표시해 보겠습니다.
import matplotlib.pyplot as plt
# We're taking sales for each date
dataframe = data_model.get_data(feature_list = ['Date','m_AmountOfSale_sum'])
# Create a line chart
plt.plot(dataframe['Date'], dataframe['m_AmountOfSale_sum'])
# Add labels and a title
plt.xlabel('Days')
plt.ylabel('Sales')
plt.title('Daily Sales Data')
# Display the chart
plt.show()
산출:
4단계: 예측
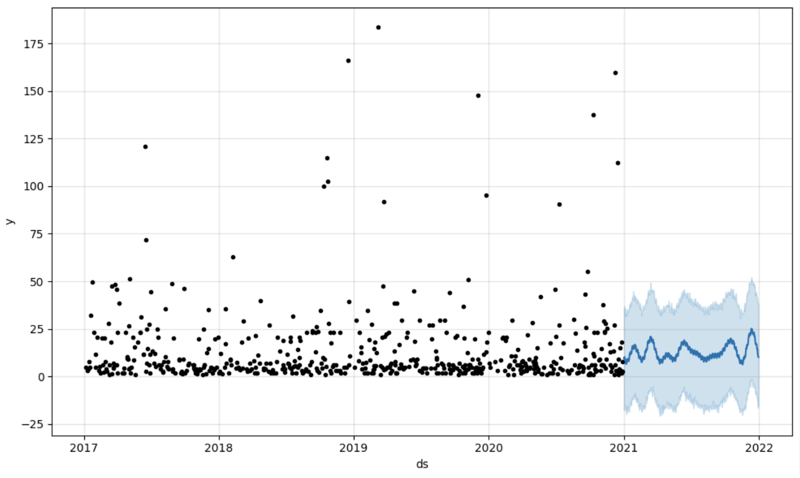
다음 단계는 AI-Link 브리지에서 실제로 가치를 얻는 것입니다. 간단한 예측을 해보겠습니다.
# Load the historical data to train the model
data_train = data_model.get_data(
feature_list = ['Date','m_AmountOfSale_sum'],
filter_less = {'Date':'2021-01-01'}
)
data_test = data_model.get_data(
feature_list = ['Date','m_AmountOfSale_sum'],
filter_greater = {'Date':'2021-01-01'}
)
여기에는 모델을 훈련하고 테스트하기 위한 2개의 다른 데이터 세트가 있습니다.
# For the tool we've chosen to do the prediction 'Prophet', we'll need to specify 2 columns: 'ds' and 'y'
data_train['ds'] = pd.to_datetime(data_train['Date'])
data_train.rename(columns={'m_AmountOfSale_sum': 'y'}, inplace=True)
data_test['ds'] = pd.to_datetime(data_test['Date'])
data_test.rename(columns={'m_AmountOfSale_sum': 'y'}, inplace=True)
# Initialize and fit the Prophet model
model = Prophet()
model.fit(data_train)
그런 다음 예측을 수용하고 그래프에 표시하기 위해 또 다른 데이터 프레임을 생성합니다.
# Create a future dataframe for forecasting future = pd.DataFrame() future['ds'] = pd.date_range(start='2021-01-01', end='2021-12-31', freq='D') # Make predictions forecast = model.predict(future) fig = model.plot(forecast) fig.show()
산출:
5단계: 쓰기 저장
예측이 완료되면 이를 데이터 웨어하우스에 다시 넣고 의미 체계 모델에 집계를 추가하여 다른 소비자에게 반영할 수 있습니다. 예측은 BI 분석가 및 비즈니스 사용자를 위한 다른 BI 도구를 통해 사용할 수 있습니다.
예측 자체는 당사의 데이터 웨어하우스에 저장됩니다.
from atscale.db.connections import Iris
db = Iris(
username,
host,
namespace,
driver,
schema,
port=1972,
password=None,
warehouse_id=None
)data_model.writeback(dbconn=db,
table_name= 'SalesPrediction',
DataFrame = forecast)data_model.create_aggregate_feature(dataset_name='SalesPrediction',
column_name='SalesForecasted',
name='sum_sales_forecasted',
aggregation_type='SUM')
지느러미
그렇습니다!
행운을 빕니다!
-
 자바 스크립트 객체의 키를 알파벳순으로 정렬하는 방법은 무엇입니까?object.keys (...) . .sort () . 정렬 된 속성을 보유 할 새 개체를 만듭니다. 정렬 된 키 어레이를 반복하고 리소셔 함수를 사용하여 원래 객체에서 새 객체에 해당 값과 함께 각 키를 추가합니다. 다음 코드는 프로세...프로그램 작성 2025-04-28에 게시되었습니다
자바 스크립트 객체의 키를 알파벳순으로 정렬하는 방법은 무엇입니까?object.keys (...) . .sort () . 정렬 된 속성을 보유 할 새 개체를 만듭니다. 정렬 된 키 어레이를 반복하고 리소셔 함수를 사용하여 원래 객체에서 새 객체에 해당 값과 함께 각 키를 추가합니다. 다음 코드는 프로세...프로그램 작성 2025-04-28에 게시되었습니다 -
유효한 코드에도 불구하고 PHP의 입력을 캡처하는 사후 요청이없는 이유는 무엇입니까?post request 오작동 주소 php action='' var_dump를 사용하여 양식 제출 후 $ _post 배열의 내용을 확인합니다. action="<?php echo $_SERVER['PHP_SELF'];?>&...프로그램 작성 2025-04-28에 게시되었습니다
-
McRypt에서 OpenSSL로 암호화를 마이그레이션하고 OpenSSL을 사용하여 McRypt 암호화 데이터를 해제 할 수 있습니까?질문 : McRypt에서 OpenSSL로 내 암호화 라이브러리를 업그레이드 할 수 있습니까? 그렇다면 어떻게? 대답 : 대답 : 예, McRypt에서 암호화 라이브러리를 OpenSSL로 업그레이드 할 수 있습니다. OpenSSL을 사용하여 McRyp...프로그램 작성 2025-04-28에 게시되었습니다
-
크롬에서 상자 텍스트를 선택하는 방법은 무엇입니까?초기 시도 한 가지 일반적인 접근 방식은 다음과 같습니다. 주) & lt;/옵션 & gt; & lt; 옵션> select .lt {text-align : center; } <option value=""&a...프로그램 작성 2025-04-28에 게시되었습니다
-
`JSON '패키지를 사용하여 이동하는 JSON 어레이를 구문 분석하는 방법은 무엇입니까?JSON 어레이를 Parsing JSON 패키지 문제 : JSON 패키지를 사용하여 어레이를 나타내는 JSON 스트링을 어떻게 구문 분석 할 수 있습니까? 예 : type JsonType struct { Array []string ...프로그램 작성 2025-04-28에 게시되었습니다
-
열의 열이 다른 데이터베이스 테이블을 어떻게 통합하려면 어떻게해야합니까?다른 열이있는 결합 테이블 ] 는 데이터베이스 테이블을 다른 열로 병합하려고 할 때 도전에 직면 할 수 있습니다. 간단한 방법은 열이 적은 테이블의 누락 된 열에 null 값을 추가하는 것입니다. 예를 들어, 표 B보다 더 많은 열이있는 두 개의 테이블,...프로그램 작성 2025-04-28에 게시되었습니다
-
동적 인 크기의 부모 요소 내에서 요소의 스크롤 범위를 제한하는 방법은 무엇입니까?문제 : 고정 된 사이드 바로 조정을 유지하면서 사용자의 수직 스크롤과 함께 이동하는 스크롤 가능한 맵 디브가있는 레이아웃을 고려합니다. 그러나 맵의 스크롤은 뷰포트의 높이를 초과하여 사용자가 페이지 바닥 글에 액세스하는 것을 방지합니다. ...프로그램 작성 2025-04-28에 게시되었습니다
-
MySQL에서 데이터를 피벗하여 그룹을 어떻게 사용할 수 있습니까?select d.data_timestamp, sum (data_id = 1 that data_value else 0 End), 'input_1'로 0 End), sum (data_id = 2 an Els.] d.data_timestamp ...프로그램 작성 2025-04-28에 게시되었습니다
-
MySQLI로 전환 한 후 Codeigniter가 MySQL 데이터베이스에 연결 해야하는 이유문제를 디버깅하려면 파일 끝에 다음 코드를 추가하고 출력을 검토하는 것이 좋습니다. echo ''; print_r ($ db ); echo ''; echo '데이터베이스에 연결 :'. $ db ; $ dbh = mysq...프로그램 작성 2025-04-28에 게시되었습니다
-
Point-In-Polygon 감지에 더 효율적인 방법 : Ray Tracing 또는 Matplotlib \ 's Path.contains_points?Ray Tracing MethodThe ray tracing method intersects a horizontal ray from the point under examination with the polygon's sides. 교차로의 수를 계산하고 지점이 패...프로그램 작성 2025-04-28에 게시되었습니다
-
익명의 JavaScript 이벤트 처리기를 깨끗하게 제거하는 방법은 무엇입니까?익명 이벤트 리스너를 제거하는 데 익명의 이벤트 리스너 추가 요소를 추가하면 유연성과 단순성을 제공하지만 유연성과 단순성을 제공하지만 제거 할 시간이되면 요소 자체를 교체하지 않고 도전 할 수 있습니다. 요소? element.addeventListene...프로그램 작성 2025-04-28에 게시되었습니다
-
FormData ()로 여러 파일 업로드를 처리하려면 어떻게해야합니까?); 그러나이 코드는 첫 번째 선택된 파일 만 처리합니다. 파일 : var files = document.getElementById ( 'filetOUpload'). 파일; for (var x = 0; x프로그램 작성 2025-04-28에 게시되었습니다
-
PYTZ가 처음에 예상치 못한 시간대 오프셋을 표시하는 이유는 무엇입니까?import pytz pytz.timezone ( 'Asia/Hong_kong') std> discrepancy source 역사 전반에 걸쳐 변동합니다. PYTZ가 제공하는 기본 시간대 이름 및 오프...프로그램 작성 2025-04-28에 게시되었습니다
-
전체 HTML 문서에서 특정 요소 유형의 첫 번째 인스턴스를 어떻게 스타일링하려면 어떻게해야합니까?javascript 솔루션 < /h2> : 최초의 유형 문서 전체를 달성합니다 유형의 첫 번째 요소와 일치하는 JavaScript 솔루션이 필요합니다. 문서에서 첫 번째 일치 요소를 선택하고 사용자 정의를 적용 할 수 있습니다. 그런 ...프로그램 작성 2025-04-28에 게시되었습니다
-
PHP 배열 키-값 이상 : 07 및 08의 호기심 사례 이해이 문제는 PHP의 주요 제로 해석에서 비롯됩니다. 숫자가 0 (예 : 07 또는 08)으로 접두사를 넣으면 PHP는 소수점 값이 아닌 옥탈 값 (기본 8)으로 해석합니다. 설명 : echo 07; // 인쇄 7 (10 월 07 = 10 진수 7) ...프로그램 작성 2025-04-28에 게시되었습니다















중국어 공부
- 1 "걷다"를 중국어로 어떻게 말하나요? 走路 중국어 발음, 走路 중국어 학습
- 2 "비행기를 타다"를 중국어로 어떻게 말하나요? 坐飞机 중국어 발음, 坐飞机 중국어 학습
- 3 "기차를 타다"를 중국어로 어떻게 말하나요? 坐火车 중국어 발음, 坐火车 중국어 학습
- 4 "버스를 타다"를 중국어로 어떻게 말하나요? 坐车 중국어 발음, 坐车 중국어 학습
- 5 운전을 중국어로 어떻게 말하나요? 开车 중국어 발음, 开车 중국어 학습
- 6 수영을 중국어로 뭐라고 하나요? 游泳 중국어 발음, 游泳 중국어 학습
- 7 자전거를 타다 중국어로 뭐라고 하나요? 骑自行车 중국어 발음, 骑自行车 중국어 학습
- 8 중국어로 안녕하세요를 어떻게 말해요? 你好중국어 발음, 你好중국어 학습
- 9 감사합니다를 중국어로 어떻게 말하나요? 谢谢중국어 발음, 谢谢중국어 학습
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









