
5가지 최고의 오픈 소스 AI 이미지 생성기
 검색:912
검색:912
인터넷에는 특정 종류의 이미지를 전문으로 하는 수십 개의 무료 오픈 소스 AI 텍스트-이미지 생성기가 있습니다. 그래서 우리는 더미를 살펴보고 지금 당장 사용해 볼 수 있는 최고의 오픈 소스 AI 텍스트-이미지 생성기를 찾았습니다.
1 Craiyon
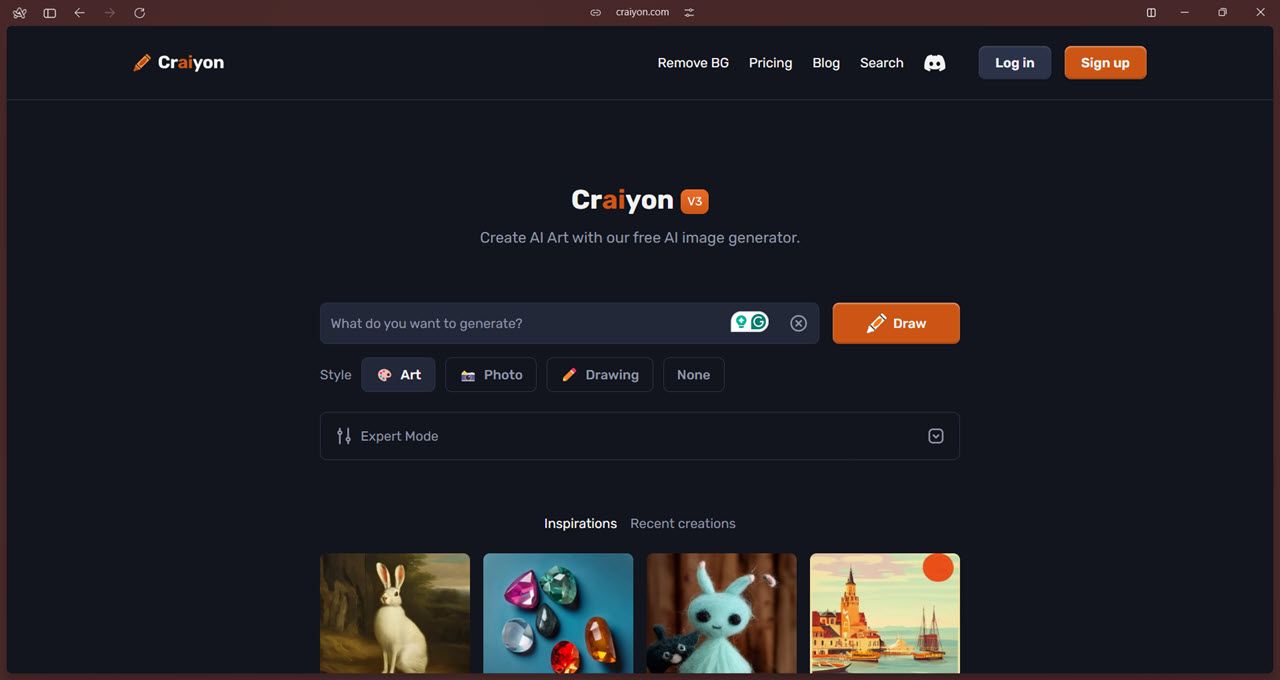
Craiyon은 가장 쉽게 액세스할 수 있는 오픈 소스 AI 이미지 생성기 중 하나입니다. 이는 DALL-E Mini를 기반으로 하며 Github 저장소를 복제하고 컴퓨터에 로컬로 모델을 설치할 수 있지만 Craiyon은 웹 사이트를 선호하여 이 접근 방식을 중단한 것으로 보입니다.
공식 Github 저장소는 2022년 6월 이후 업데이트되지 않았지만 공식 Craiyon 사이트에서는 최신 모델을 여전히 무료로 사용할 수 있습니다. Android 또는 iOS 앱도 없습니다.
기능 측면에서 AI 이미지 생성기에서 기대하는 일반적인 옵션이 모두 표시됩니다. 프롬프트를 입력하고 이미지를 얻은 후에는 고급 기능을 사용하여 더 높은 해상도의 사본을 얻을 수 있습니다. 아트, 사진, 드로잉의 세 가지 스타일 중에서 선택할 수 있습니다. 모델이 결정하도록 하려면 "없음" 옵션을 선택할 수도 있습니다.
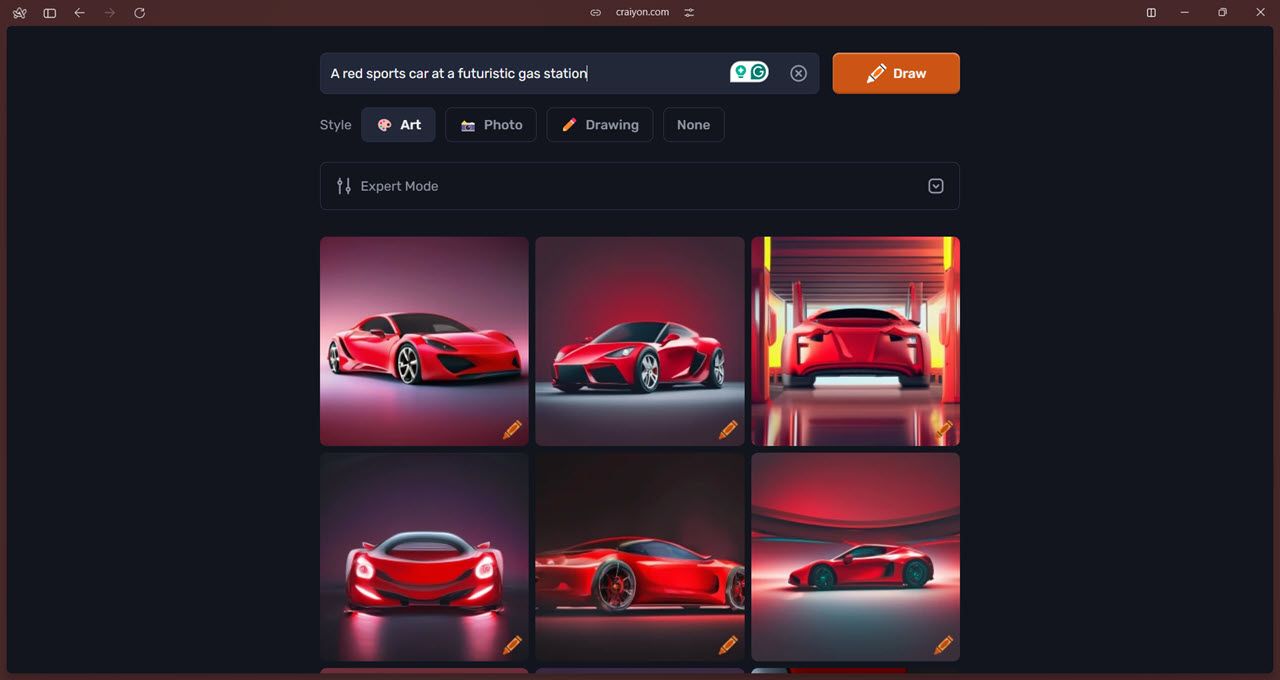
또한 "전문가 모드"를 사용하면 모델에 특정 항목을 피하도록 지시하는 부정적인 단어를 포함할 수 있습니다. ChatGPT를 사용하여 사용자가 가능한 가장 상세하고 최상의 프롬프트를 작성할 수 있도록 돕는 프롬프트 예측 기능도 있습니다. 마지막으로, AI 기반 배경 제거 기능을 사용하면 이미지에서 배경을 자르는 시간과 노력을 절약할 수 있습니다.
이것이 바로 Craiyon이 하는 모든 일입니다. 가장 정교한 AI 이미지 생성 모델은 아니지만, 디테일하거나 사실적인 것을 원하지 않는 경우 기본 모델로는 좋습니다.
모델은 무료로 사용할 수 있지만 무료 사용자는 1분 내에 한 번에 9개의 무료 이미지로 제한됩니다. Supporter 또는 Professional 계층(각각 월 5달러 및 20달러, 연간 청구)을 구독하면 광고나 워터마크가 없고 생성 속도가 빨라지며 생성된 이미지를 비공개로 유지하는 옵션을 얻을 수 있습니다. 사용자 정의 구독 계층에서는 사용자 정의 모델, 통합, 전용 지원 및 개인 서버도 허용됩니다.
2 Stable Diffusion 1.5
Stable Diffusion은 아마도 가장 인기 있는 오픈 소스 텍스트-이미지 생성 모델 중 하나일 것입니다. 또한 아래에 언급된 세 가지 이미지 생성기를 포함한 다른 모델에도 전원을 공급합니다. 2022년에 출시되었으며 그 이후로 많은 구현이 있었습니다.
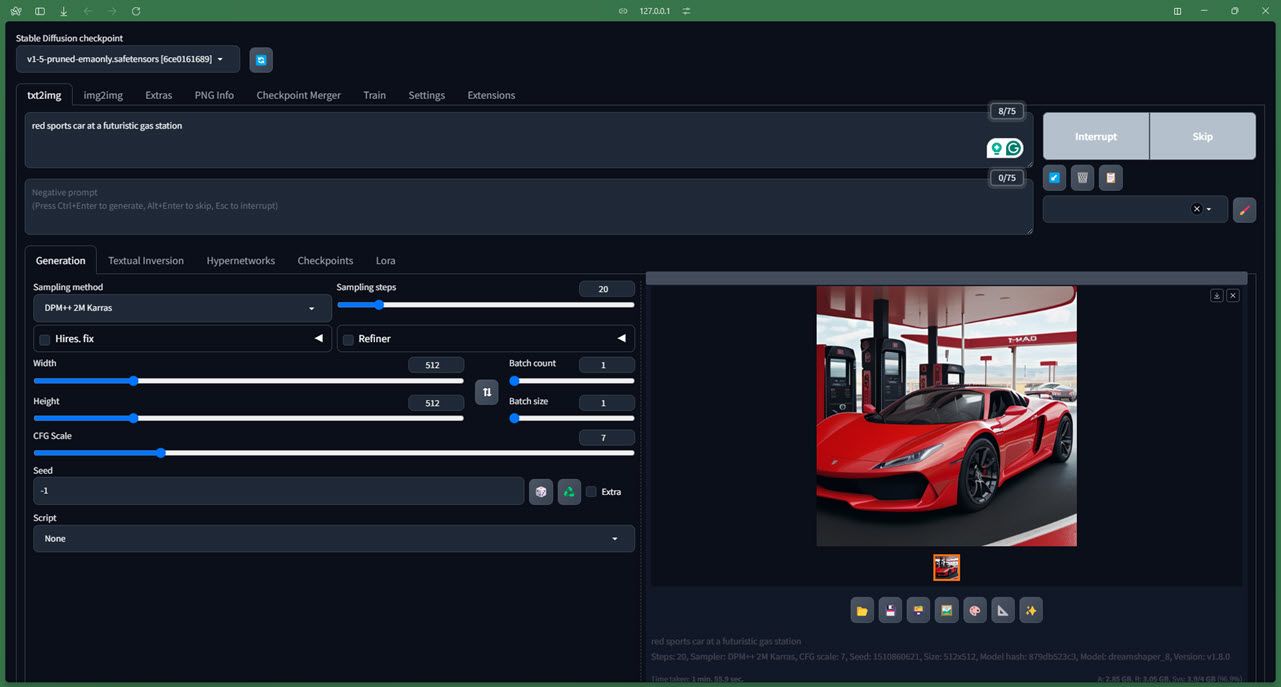
모델 작동 방식에 대한 지나치게 기술적인 세부 사항은 생략하겠습니다(공식 Github 저장소에서 확인할 수 있음). 하지만 이 모델은 완전 초보자라도 설치하기 쉽고 잘 작동합니다. 최소 4GB의 메모리를 갖춘 전용 GPU가 있는 한. 온라인으로 Stable Diffusion에 액세스할 수도 있으며, Mac에서 Stable Diffusion을 실행하려는 경우에도 저희가 도와드리겠습니다.
Stable Diffusion에 사용할 수 있는 여러 체크포인트(버전 고려)가 있습니다. 버전 1.5를 테스트하는 동안 버전 2.1도 활발히 개발 중이며 더 정확합니다.

모델을 실행하는 것도 다소 쉽습니다. AUTOMATIC1111 Stable Diffusion 웹 사용자 인터페이스로 테스트한 결과 모든 컨트롤과 매개변수가 잘 작동했습니다. 또한 모델이 훈련한 LAION-5B 데이터베이스 덕분에 NSFW를 완벽하게 방지할 수 있습니다(비록 완벽하지는 않지만 주의하세요). 생성 시간 자체는 하드웨어에 따라 다르지만 기본 프롬프트에서도 이미지가 상세하고 사실적일 것으로 기대할 수 있습니다.
3 DreamShaper
DreamShaper는 Stable Diffusion을 기반으로 한 이미지 생성 모델입니다. 이는 MidJourney의 오픈 소스 대안으로 의도되었으며 생성된 이미지의 사실적인 표현에 중점을 두었습니다. 단 몇 가지 조정을 통해 애니메이션 및 그림 스타일도 처리할 수 있습니다.
이 모델은 Stable Diffusion보다 성능이 뛰어나 사용자가 번개 개선부터 느슨한 NSFW 제한에 이르기까지 최종 출력에 대해 더 많은 자유를 누릴 수 있습니다. 로컬 액세스를 위해 온라인으로 다운로드할 수 있는 사전 훈련된 버전과 Sinkin.ai, RandomSeed 및 Mage.space(기본 구독 필요)를 포함한 다양한 웹사이트를 통해 모델을 실행하는 것도 쉽습니다. GPU 가속.
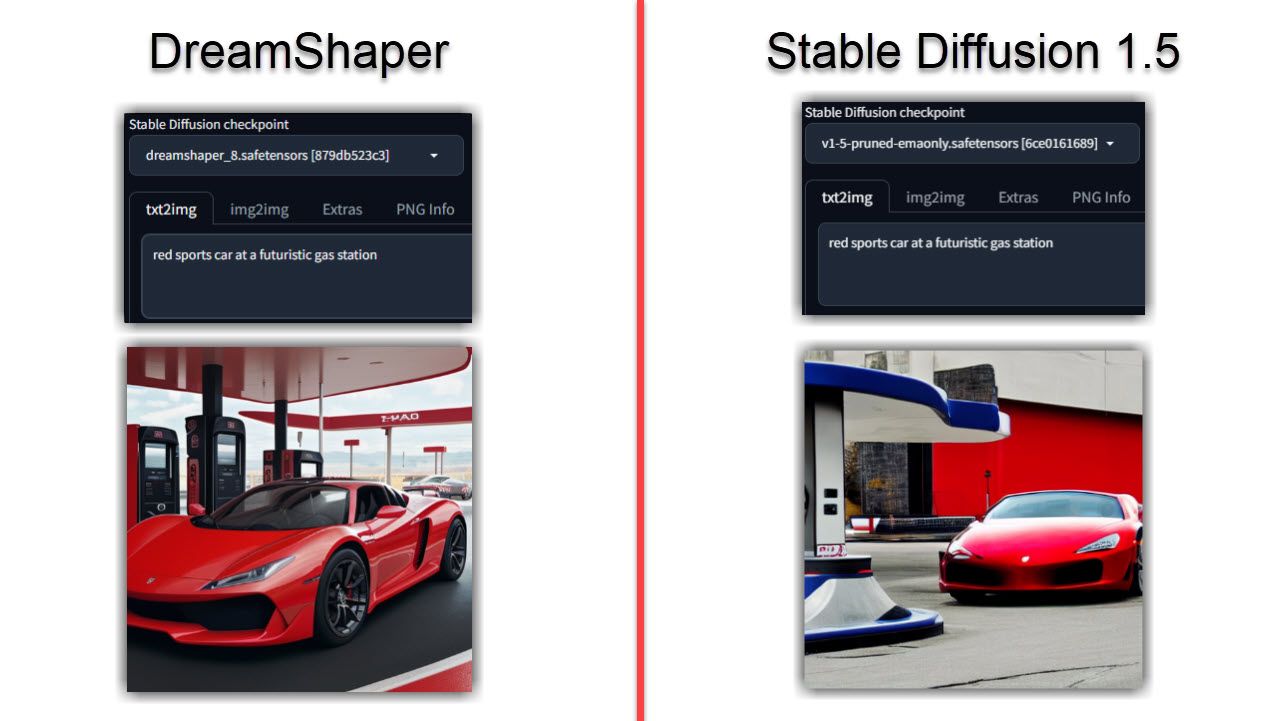
지금쯤 추측할 수 있듯이 DreamShaper로 생성된 이미지는 Stable Diffusion에 비해 더 사실적으로 보이는 경향이 있습니다. 두 모델 모두에서 동일한 프롬프트를 실행하더라도 DreamShaper 모델은 더 현실적이고 상세하며 조명이 더 밝을 것입니다.
이는 초상화나 캐릭터의 경우 특히 그렇습니다. 동일한 프롬프트에 비해 Stable Diffusion이 부족하다는 점을 발견했습니다. 이미지가 너무 사실적으로 변하는 경우 AI 생성 이미지를 식별하는 네 가지 방법이 있습니다.
모델을 실행하는 데 거대한 PC가 필요하지 않습니다. 4GB VRAM을 탑재한 내 GTX 1650Ti는 모델을 완벽하게 실행했습니다. 생성 시간이 조금 더 길어졌지만 실제 출력에는 영향을 미치지 않는 것 같습니다. 즉, Stable Diffusion XL 모델을 기반으로 하는 DreamShaper XL을 실행하려면 더 많은 VRAM이 있는 GPU가 필요할 수 있습니다.
4 InvokeAI
Invoke AI는 Stable Diffusion XL을 기반으로 하는 XL 버전이 있는 Stable Diffusion을 기반으로 하는 또 다른 AI 기반 이미지 생성 모델입니다. 또한 자체 웹 및 명령줄 사용자 인터페이스가 있으므로 Stable Diffusion 웹 UI와 같은 작업을 수행할 필요가 없습니다.
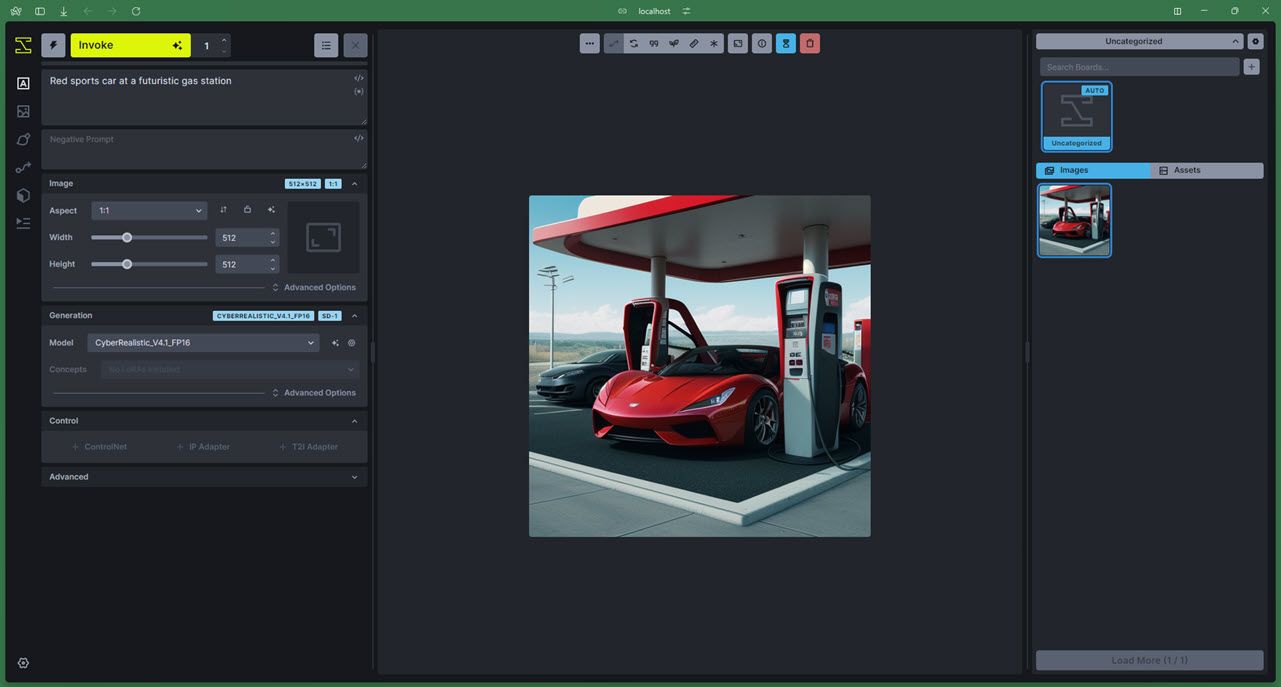
이 모델은 사용자가 맞춤형 워크플로를 통해 지적 재산을 기반으로 시각적 개체를 만들 수 있도록 하는 데 중점을 둡니다. InvokeAI는 사용자 정의 모델을 교육하고 지적 재산 작업을 위한 최고의 오픈 소스 AI 이미지 생성 모델 중 하나입니다.
공식 Github 저장소에는 두 가지 설치 방법이 나열되어 있습니다. InvokeAI 설치 프로그램을 통해 설치하거나 터미널과 Python에 익숙하고 모델과 함께 설치된 패키지에 대한 더 많은 제어가 필요한 경우 PyPI를 사용하는 것입니다.
그러나 추가 제어에는 몇 가지 제한 사항이 있으며, 특히 더 엄격한 하드웨어 요구 사항이 있습니다. InvokeAI는 최소 4GB의 메모리를 갖춘 전용 GPU를 권장하며, XL 변형을 실행하려면 6~8GB가 권장됩니다. VRAM 요구 사항은 AMD 및 Nvidia GPU 모두에 적용됩니다. 또한 모델, 해당 종속성 및 Python을 위해 최소 12GB의 RAM과 12GB의 여유 디스크 공간이 필요합니다.

문서에서는 비디오 메모리 부족으로 인해 Nvidia의 GTX 10 시리즈 및 16 시리즈 GPU를 권장하지 않지만 제공된 설치 프로그램은 제대로 실행되었습니다. 마일리지는 다를 수 있지만 저가형 GPU를 사용하는 경우 메시지가 이미지로 변환되는 것을 보려면 더 오래 기다려야 합니다. 마지막으로, Windows를 사용하는 경우 현재 AMD GPU가 지원되지 않으므로 Nvidia GPU만 사용할 수 있습니다.
이미지 생성 부분에서 모델은 사실주의보다는 예술적인 스타일에 더 치우치는 경향이 있습니다. 물론, 데이터세트를 사용하여 모델을 훈련하고 원하는 이미지에 더 가까운 이미지를 생성하도록 할 수 있습니다. 특히 제품 디자인, 건축 또는 소매 공간에서 작업하는 경우 사실적인 이미지가 포함된 경우에도 마찬가지입니다. 그러나 명심해야 할 한 가지 중요한 점은 InvokeAI가 기본적으로 이미지 생성 엔진이라는 것입니다. 즉, 최상의 결과를 얻으려면 자체 모델(웹 인터페이스에 제공되는 모델 관리자를 통해 쉽게 찾을 수 있음)을 기본값으로 사용해야 할 가능성이 높습니다. 모델은 Stable Diffusion 자체와 매우 유사합니다.
5 Openjourney
Openjourney는 Stable Diffusion을 기반으로 한 무료 오픈 소스 AI 이미지 생성 모델입니다. 모델 이름이 Openjourney인 이유가 궁금하다면 Midjourney 이미지에 대해 훈련되었으며 생성된 이미지에서 해당 스타일을 모방할 수 있기 때문입니다.
Openjourney를 개발한 회사인 PromptHero를 사용하면 Stable Diffusion(버전 1.5 및 2), DreamShaper 및 Realistic Vision을 포함한 다른 모델과 함께 모델을 테스트할 수 있습니다. 가입 시 25개의 무료 크레딧(생성된 각 이미지당 1개의 크레딧)을 받게 되며, 그 후에는 Pro 구독 등급을 구독해야 합니다. Pro 구독 등급은 한 달에 9달러이며 다른 독점 기능과 함께 매월 300크레딧에 액세스할 수 있습니다.

하지만 로컬에서 무료로 실행하려면 HuggingFace에서 모델 파일을 다운로드한 후 Stable Diffusion 웹 UI를 사용하여 실행할 수 있습니다. Openjourney는 HuggingFace에서 Stable Diffusion 바로 다음으로 두 번째로 많이 다운로드된 AI 이미지 생성 모델이기도 합니다.
Openjourney는 웹 사이트에서 모델을 로컬로 실행하기 위한 특정 하드웨어 요구 사항을 나열하지 않지만 Stable Diffusion과 유사한 하드웨어 요구 사항을 기대할 수 있습니다. 이는 모델과 해당 종속성을 저장하기 위해 4GB VRAM, 16GB RAM 및 약 12~15GB의 컴퓨터 여유 공간을 갖춘 전용 GPU를 의미합니다.

Openjourney에서 생성된 이미지는 달리 명시되지 않는 한 사실주의와 예술 사이에서 균형을 이루는 경향이 있습니다. 만능 모델을 찾고 있고 구독 비용을 지불하지 않고 Midjourney 모양과 느낌을 선호한다면 Openjourney가 최고의 옵션 중 하나입니다.
-
 상위 5 개 AI 지능형 예산 도구AI로 재무 자유 잠금 해제 : 인도 최고의 예산 앱 돈이 어디로 가는지 궁금해하는 것에 지쳤습니까? 청구서는 수입을 삼키는 것처럼 보입니까? 인공 지능 (AI)은 강력한 솔루션을 제공합니다. AI 예산 책정 도구는 실시간 재무 통찰력, 개인화 된 권장 사항 ...일체 포함 2025-04-17에 게시되었습니다
상위 5 개 AI 지능형 예산 도구AI로 재무 자유 잠금 해제 : 인도 최고의 예산 앱 돈이 어디로 가는지 궁금해하는 것에 지쳤습니까? 청구서는 수입을 삼키는 것처럼 보입니까? 인공 지능 (AI)은 강력한 솔루션을 제공합니다. AI 예산 책정 도구는 실시간 재무 통찰력, 개인화 된 권장 사항 ...일체 포함 2025-04-17에 게시되었습니다 -
Excel SumProduct 기능에 대한 자세한 설명 - 데이터 분석 학교Excel의 SumProduct 기능 : 데이터 분석 강국 간소화 된 데이터 분석을 위해 Excel의 SumProduct 기능의 힘을 잠금 해제합니다. 이 다재다능한 기능은 합산 및 곱셈 기능을 쉽게 결합하여 해당 범위 또는 배열에 걸쳐 추가, 뺄셈 및 분할까지 ...일체 포함 2025-04-16에 게시되었습니다
-
심층적 인 연구는 완전히 개방적이며 Chatgpt와 사용자 혜택이 있습니다Openai의 깊은 연구 : AI Research의 게임 체인저 Openai는 모든 Chatgpt Plus 가입자에 대한 깊은 연구를 시작하여 연구 효율성이 크게 향상되었습니다. Gemini, Grok 3 및 Perplexity와 같은 경쟁사들로부터 유사한 기능...일체 포함 2025-04-16에 게시되었습니다
-
Amazon Nova 오늘 실제 경험 및 검토 - 분석 VidhyaAmazon은 Nova : 향상된 AI 및 컨텐츠 제작을위한 최첨단 기초 모델을 공개합니다 Amazon의 최근 Re : Invent 2024 이벤트는 AI 및 컨텐츠 제작에 혁명을 일으키기 위해 고안된 가장 진보 된 기초 모델 인 Nova를 선보였습니다. 이 기사...일체 포함 2025-04-16에 게시되었습니다
-
chatgpt 타이밍 작업 기능을 사용하는 5 가지 방법Chatgpt의 새로운 예정된 작업 : ai 로 하루를 자동화하십시오. Chatgpt는 최근 게임 변화 기능을 소개했습니다 : 예약 된 작업. 이를 통해 사용자는 반복적 인 프롬프트를 자동화하여 오프라인에서도 미리 정해진 시간에 알림이나 응답을받을 수 있습니다. ...일체 포함 2025-04-16에 게시되었습니다
-
세 개의 AI 챗봇 중 어느 것이 동일한 프롬프트에 응답하는 것이 가장 좋습니까?여기에 내가 찾은 것이 있습니다. 가 잘 생산되는 프롬프트를 만들어냅니다. 모든 도구와 마찬가지로 출력은 사용하는 사람의 기술만큼이나 좋습니다. ai 챗봇은 다르지 않습니다. 이 이해를 통해 각 모델에 개인 금융에 중점을 둔 기본 안내서...일체 포함 2025-04-15에 게시되었습니다
-
chatgpt는 충분하고 전용 AI 채팅 기계가 필요하지 않습니다.새로운 AI 챗봇이 매일 시작되는 세상에서 어느 것이 "하나"인지 결정하는 것이 압도적 일 수 있습니다. 그러나 내 경험상, Chatgpt는 약간의 신속한 엔지니어링으로 플랫폼간에 전환 할 필요없이 내가 던지는 거의 모든 것을 처리합니다. 전...일체 포함 2025-04-14에 게시되었습니다
-
Indian AI Moment : Generative AI에서 중국 및 미국과의 경쟁인도의 AI 야망 : 2025 업데이트 중국과 미국이 생성 AI에 많은 투자를하면서 인도는 자체 Genai 이니셔티브를 가속화하고 있습니다. 인도의 다양한 언어 및 문화 환경을 수용하는 토착민 대형 언어 모델 (LLM)과 AI 도구에 대한 긴급한 필요성은 부인할...일체 포함 2025-04-13에 게시되었습니다
-
Airflow 및 Docker를 사용하여 CSV의 CSV 가져 오기이 튜토리얼은 CSV 파일에서 데이터베이스로 데이터 전송을 자동화하기 위해 Apache Airflow, Docker 및 PostgreSQL을 사용하여 강력한 데이터 파이프 라인을 구축하는 것을 보여줍니다. 효율적인 워크 플로 관리를위한 DAG, 작업 및 운영자와 같은...일체 포함 2025-04-12에 게시되었습니다
-
Swarm Intelligence 알고리즘 : 세 가지 파이썬 구현Imagine watching a flock of birds in flight. There's no leader, no one giving directions, yet they swoop and glide together in perfect harmony. It may...일체 포함 2025-03-24에 게시되었습니다
-
래그 및 미세 조정으로 LLM을 더 정확하게 만드는 방법Imagine studying a module at university for a semester. At the end, after an intensive learning phase, you take an exam – and you can recall th...일체 포함 2025-03-24에 게시되었습니다
-
Google Gemini는 무엇입니까? Google의 Chatgpt 라이벌에 대해 알아야 할 모든 것Google recently released its new Generative AI model, Gemini. It results from a collaborative effort by a range of teams at Google, including members ...일체 포함 2025-03-23에 게시되었습니다
-
DSPY와 함께 프롬프트 안내서dspy : LLM 응용 프로그램을 구축하고 개선하기위한 선언적 프레임 워크 dspy (선언적 자체 개선 언어 프로그램)는 신속한 엔지니어링의 복잡성을 추상화하여 LLM 애플리케이션 개발에 혁명을 일으킨다. 이 튜토리얼은 DSPY의 선언적 접근 방식을 사용하여 ...일체 포함 2025-03-22에 게시되었습니다
-
블로그를 트위터 스레드로 자동화하십시오이 기사는 Google의 Gemini-2.0 LLM, ChromADB 및 Streamlit을 사용하여 긴 형식의 컨텐츠 (예 : 블로그 게시물)를 트위터 스레드로 전환하는 것을 자동화합니다. 수동 스레드 생성은 시간이 많이 걸립니다. 이 응용 프로그램은 프로세스를 간...일체 포함 2025-03-11에 게시되었습니다
-
인공 면역계 (AIS) : 파이썬 사례가있는 안내서이 기사는 인공 면역 체계 (AIS)를 탐구합니다.이 기사는 인간 면역 체계의 위협을 식별하고 중화시키는 놀라운 능력에서 영감을 얻은 계산 모델 인 인공 면역 체계 (AIS)를 탐구합니다. 우리는 AIS의 핵심 원칙을 탐구하고, 클론 선택, 부정적인 선택 및 면역 네...일체 포함 2025-03-04에 게시되었습니다















중국어 공부
- 1 "걷다"를 중국어로 어떻게 말하나요? 走路 중국어 발음, 走路 중국어 학습
- 2 "비행기를 타다"를 중국어로 어떻게 말하나요? 坐飞机 중국어 발음, 坐飞机 중국어 학습
- 3 "기차를 타다"를 중국어로 어떻게 말하나요? 坐火车 중국어 발음, 坐火车 중국어 학습
- 4 "버스를 타다"를 중국어로 어떻게 말하나요? 坐车 중국어 발음, 坐车 중국어 학습
- 5 운전을 중국어로 어떻게 말하나요? 开车 중국어 발음, 开车 중국어 학습
- 6 수영을 중국어로 뭐라고 하나요? 游泳 중국어 발음, 游泳 중국어 학습
- 7 자전거를 타다 중국어로 뭐라고 하나요? 骑自行车 중국어 발음, 骑自行车 중국어 학습
- 8 중국어로 안녕하세요를 어떻게 말해요? 你好중국어 발음, 你好중국어 학습
- 9 감사합니다를 중국어로 어떻게 말하나요? 谢谢중국어 발음, 谢谢중국어 학습
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









