
Go sync.Pool とその背後にある仕組み
 ブラウズ:301
ブラウズ:301
これは投稿の抜粋です。投稿全文はこちらからご覧いただけます: https://victoriametrics.com/blog/go-sync-pool/
この投稿は、Go での同時実行性の処理に関するシリーズの一部です:
- 同期ミューテックスに移行: 通常モードと飢餓モード
- Go sync.WaitGroup と調整の問題
- Go sync.Pool とその背後にあるメカニズム (ここにいます)
- Go sync.Cond、最も見落とされている同期メカニズム
VictoriaMetrics ソース コードでは、sync.Pool を頻繁に使用します。正直に言って、一時オブジェクト、特にバイト バッファーやスライスの処理方法に非常に適しています。
標準ライブラリでよく使われます。たとえば、encoding/json パッケージでは:
package json
var encodeStatePool sync.Pool
// An encodeState encodes JSON into a bytes.Buffer.
type encodeState struct {
bytes.Buffer // accumulated output
ptrLevel uint
ptrSeen map[any]struct{}
}
この場合、sync.Pool は、JSON を bytes.Buffer にエンコードするプロセスを処理する *encodeState オブジェクトを再利用するために使用されています。
これらのオブジェクトを使用のたびにスローするだけではガベージ コレクターの作業が増えるだけですが、代わりに、それらをプール (sync.Pool) に隠します。次回同様のものが必要になったときは、新しいものを最初から作成するのではなく、プールから取得するだけです。
net/http パッケージには、I/O 操作の最適化に使用される複数の sync.Pool インスタンスもあります:
package http
var (
bufioReaderPool sync.Pool
bufioWriter2kPool sync.Pool
bufioWriter4kPool sync.Pool
)
サーバーは、リクエスト本文を読み取るか応答を書き込むときに、事前に割り当てられたリーダーまたはライターをこれらのプールから迅速に取得し、追加の割り当てをスキップできます。さらに、2 つのライター プール *bufioWriter2kPool と *bufioWriter4kPool は、さまざまな書き込みニーズを処理するために設定されています。
func bufioWriterPool(size int) *sync.Pool {
switch size {
case 2
さて、イントロはこれで十分です。
今日は、sync.Pool の概要、定義、使用方法、内部で何が起こっているのか、その他知りたいことすべてについて詳しく説明します。
ところで、もっと実用的なものが必要な場合は、VictoriaMetrics での sync.Pool の使用方法を示す Go 専門家による優れた記事があります: 時系列データベースのパフォーマンス最適化手法: CPU バウンド操作のための sync.Pool
同期プールとは何ですか?
簡単に言うと、Go の sync.Pool は、後で再利用できるように一時オブジェクトを保存できる場所です。
しかし、問題は、プールに残すオブジェクトの数を制御することはできず、そこに置いたものはいつでも、警告なしに削除される可能性があるということです。その理由は、最後のセクションを読むとわかります。
良い点は、プールがスレッドセーフになるように構築されているため、複数のゴルーチンが同時にプールを利用できることです。これが同期パッケージの一部であることを考えると、それほど驚くべきことではありません。
「でも、なぜわざわざオブジェクトを再利用するのでしょうか?」
一度に多くのゴルーチンを実行している場合、多くの場合、同様のオブジェクトが必要になります。 go f() を複数回同時に実行することを想像してください。
各ゴルーチンが独自のオブジェクトを作成すると、メモリ使用量が急速に増加する可能性があり、不要になったオブジェクトをすべてクリーンアップする必要があるため、ガベージ コレクターに負担がかかります。
この状況では、同時実行性が高いとメモリ使用量が多くなり、ガベージ コレクターの速度が低下するというサイクルが発生します。 sync.Pool は、このサイクルを打破するために設計されています。
type Object struct {
Data []byte
}
var pool sync.Pool = sync.Pool{
New: func() any {
return &Object{
Data: make([]byte, 0, 1024),
}
},
}
プールを作成するには、プールが空のときに新しいオブジェクトを返す New() 関数を提供します。この関数はオプションです。指定しない場合、プールは空の場合に nil を返すだけです。
上記のスニペットの目的は、Object struct インスタンス、特にその内部のスライスを再利用することです。
スライスを再利用すると、不必要な成長を減らすことができます。
たとえば、使用中にスライスが 8192 バイトに増加した場合、プールに戻す前にその長さをゼロにリセットできます。基になる配列にはまだ 8192 の容量があるため、次回必要になったときに、これらの 8192 バイトを再利用できるようになります。
func (o *Object) Reset() {
o.Data = o.Data[:0]
}
func main() {
testObject := pool.Get().(*Object)
// do something with testObject
testObject.Reset()
pool.Put(testObject)
}
フローは非常に明確です。プールからオブジェクトを取得し、それを使用し、リセットして、プールに戻します。オブジェクトのリセットは、オブジェクトを戻す前またはプールから取得した直後に行うことができますが、必須ではなく一般的な方法です。
型アサーション pool.Get().(*Object) の使用が好きではない場合は、それを回避する方法がいくつかあります。
- 専用の関数を使用してプールからオブジェクトを取得します。
func getObjectFromPool() *Object {
obj := pool.Get().(*Object)
return obj
}
- 独自の汎用バージョンの sync.Pool を作成します。
type Pool[T any] struct {
sync.Pool
}
func (p *Pool[T]) Get() T {
return p.Pool.Get().(T)
}
func (p *Pool[T]) Put(x T) {
p.Pool.Put(x)
}
func NewPool[T any](newF func() T) *Pool[T] {
return &Pool[T]{
Pool: sync.Pool{
New: func() interface{} {
return newF()
},
},
}
}
汎用ラッパーを使用すると、型アサーションを回避して、プールを操作するためのより型安全な方法が得られます。
間接層が追加されるため、わずかなオーバーヘッドが追加されることに注意してください。ほとんどの場合、このオーバーヘッドは最小限ですが、CPU に非常に敏感な環境にいる場合は、ベンチマークを実行して、それだけの価値があるかどうかを確認することをお勧めします。
しかし、待ってください。それだけではありません。
sync.Pool と割り当てトラップ
標準ライブラリの例を含む、これまでの多くの例からお気づきかと思いますが、プールに保存するのは通常、オブジェクト自体ではなく、オブジェクトへのポインタです。
その理由を例を挙げて説明しましょう:
var pool = sync.Pool{
New: func() any {
return []byte{}
},
}
func main() {
bytes := pool.Get().([]byte)
// do something with bytes
_ = bytes
pool.Put(bytes)
}
[]バイトのプールを使用しています。一般に (常にではありませんが)、インターフェイスに値を渡すと、その値がヒープに配置されることがあります。これはここでも発生します。スライスだけでなく、ポインタではない pool.Put() に渡すものすべてで発生します。
エスケープ解析を使用してチェックする場合:
// escape analysis $ go build -gcflags=-m bytes escapes to heap
さて、変数バイトがヒープに移動するとは言いません。「バイトの値がインターフェイスを介してヒープにエスケープされる」と言いたいです。
なぜこれが起こるのかを本当に理解するには、エスケープ分析がどのように機能するかを詳しく調べる必要があります (これについては別の記事で行う可能性があります)。ただし、ポインタを pool.Put() に渡す場合、追加の割り当てはありません:
var pool = sync.Pool{
New: func() any {
return new([]byte)
},
}
func main() {
bytes := pool.Get().(*[]byte)
// do something with bytes
_ = bytes
pool.Put(bytes)
}
エスケープ分析を再度実行すると、ヒープへのエスケープがなくなっていることがわかります。さらに詳しく知りたい場合は、Go のソース コードに例があります。
同期プールの内部構造
sync.Pool が実際にどのように機能するかを説明する前に、Go の PMG スケジューリング モデルの基本を理解する価値があります。これが、sync.Pool が非常に効率的である理由のバックボーンです。
PMG モデルをいくつかのビジュアルで詳細に説明した優れた記事があります: Go の PMG モデル
今日は怠けていると感じていて、簡単な概要を探しているなら、私がサポートします:
PMG は、P (論理 p プロセッサ)、M (m マシン スレッド)、および G (goroutines) を表します。重要な点は、各論理プロセッサ (P) 上で実行できるマシン スレッド (M) は常に 1 つだけであるということです。また、ゴルーチン (G) を実行するには、スレッド (M) にアタッチする必要があります。
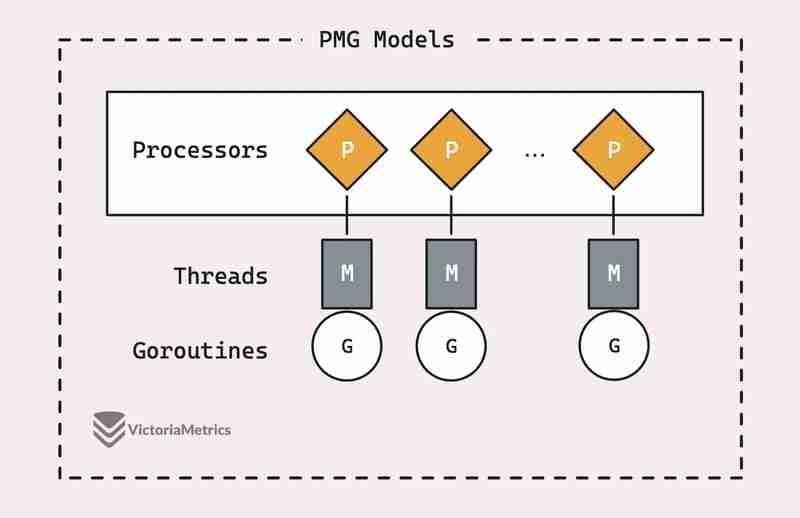
これは 2 つの重要なポイントに要約されます:
- n 個の論理プロセッサ (P) がある場合、少なくとも n 個のマシン スレッド (M) が利用可能である限り、最大 n 個のゴルーチンを並列実行できます。
- 一度に 1 つのプロセッサ (P) 上で実行できるゴルーチン (G) は 1 つだけです。したがって、P1 が G でビジー状態の場合、現在の G がブロックされるか、終了するか、あるいは何か他のことが起こって G が解放されるまで、他の G はその P1 上で実行できません。
しかし実際には、Go の sync.Pool は単なる 1 つの大きなプールではなく、実際にはいくつかの「ローカル」プールで構成されており、それぞれが Go のランタイムである特定のプロセッサ コンテキスト (P) に関連付けられています。いつでも管理できます。
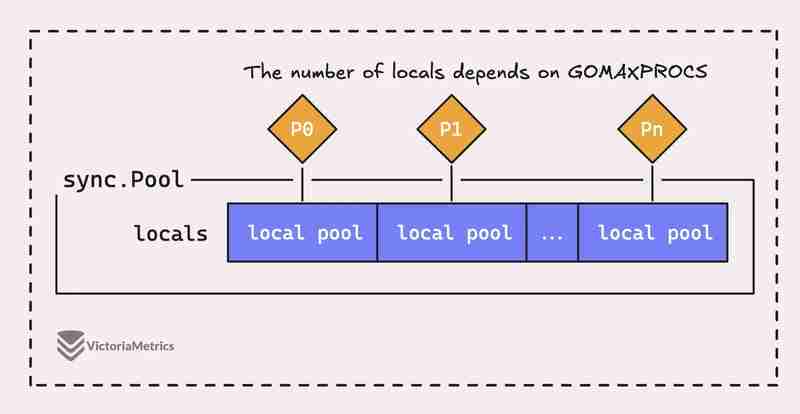
プロセッサ (P) 上で実行されているゴルーチンがプールからのオブジェクトを必要とする場合、他の場所を探す前に、まず自身の P ローカル プールをチェックします。
投稿全文はこちらからご覧いただけます: https://victoriametrics.com/blog/go-sync-pool/
-
 eval()vs。ast.literal_eval():ユーザー入力の方が安全なPython関数はどれですか?の重量eval()およびast.literal_eval()in python security をユーザー入力を処理する場合、セキュリティに優先順位を付けることが不可欠です。強力なPython関数であるeval()は、潜在的な解決策として発生することがよくありますが、懸念は潜在的なリス...プログラミング 2025-03-25に投稿されました
eval()vs。ast.literal_eval():ユーザー入力の方が安全なPython関数はどれですか?の重量eval()およびast.literal_eval()in python security をユーザー入力を処理する場合、セキュリティに優先順位を付けることが不可欠です。強力なPython関数であるeval()は、潜在的な解決策として発生することがよくありますが、懸念は潜在的なリス...プログラミング 2025-03-25に投稿されました -
JavaScriptは、文字列を数値比較にどのように処理しますか?javascript in javascriptのstring to number比較の理由は、オペレーターの固有の柔軟性のために文字列と数の比較が可能です。この機能は、仕様の§11.8.5で定義されています。 この動作は、 "90"> "100&q...プログラミング 2025-03-25に投稿されました
-
複数のユーザータイプ(学生、教師、および管理者)をFireBaseアプリでそれぞれのアクティビティにリダイレクトする方法は?red:複数のユーザータイプをそれぞれのアクティビティにリダイレクトする方法 ログイン。現在のコードは、2つのユーザータイプのリダイレクトを正常に管理しますが、3番目のタイプ(admin)を組み込もうとするときに課題に直面します。元のスキーマは、2種類のユーザーのみに対応していました。 3...プログラミング 2025-03-25に投稿されました
-
PHPを使用してXMLファイルから属性値を効率的に取得するにはどうすればよいですか?XMLファイルから属性値をPHP の取得します。提供されている例のような属性を含むXMLファイルを使用する場合: $xml = simplexml_load_file($file); foreach ($xml->Var[0]->attributes() as $att...プログラミング 2025-03-25に投稿されました
-
コンテナ内のdiv用のスムーズな左右のCSSアニメーションを作成する方法は?左右の動きのための一般的なCSSアニメーション この記事では、一般的なCSSアニメーションを作成して、その容器の端に到達する左右に移動することを探ります。このアニメーションは、その未知の長さに関係なく、絶対的なポジショニングで任意のdivに適用できます。これは、100%で、divの左のプロ...プログラミング 2025-03-25に投稿されました
-
順序付けられていないコレクションにタプルの一般的なハッシュ関数を実装する方法は?std :: unordered_mapとunordered_setコンテナは、ハスド値に基づいて効率的なルックアップと元素の挿入を提供します。ただし、カスタムハッシュ関数を定義せずにこれらのコレクションのキーとしてタプルを使用すると、予期しない動作につながる可能性があります。 st...プログラミング 2025-03-25に投稿されました
-
Pythonの理解を使用して辞書を効率的に作成するにはどうすればよいですか?python辞書の理解 Pythonでは、辞書の概念は新しい辞書を生成するための簡潔な方法を提供します。それらはリストの概念に似ていますが、いくつかの顕著な違いがあります。キーと値を明示的に指定する必要があります。たとえば、 d = {n:n ** 2の範囲(5)} これは、0から4の...プログラミング 2025-03-25に投稿されました
-
すべての開発者がマスターする必要がある重要なJavaScriptの概念1。現代のJavaScriptのマスター:あなたが知る必要があるトップES6機能 ES6(ECMAScript 2015)およびその後のバージョンの導入により、JavaScriptは大幅に進化しました。 Let and const、矢印関数、テンプレートリテラル、破壊などの...プログラミング 2025-03-25に投稿されました
-
なぜ私はPHPで「HTTPSラッパーを見つけることができない」エラーを得るのですか?httpsラッパーを見つけることができません - 問題の解決 背景: このエラーメッセージは、通常、Phpのfile_get_contents()機能を使用してHTTPSを介してリソースを介してリソースにアクセスしようとするときに発生します。根本的な原因は、PHPの構成で有効にする必要があ...プログラミング 2025-03-25に投稿されました
-
Regexを使用してPHPで括弧内で効率的にテキストを抽出する方法php:括弧内の括弧内のテキストの抽出 括弧内に囲まれたテキストの抽出を扱うとき、最も効率的なソリューションを見つけることが不可欠です。 1つのアプローチは、以下に示すように、PHPの文字列操作関数を利用することです。 $ fullstring); $ sportstring = s...プログラミング 2025-03-25に投稿されました
-
解決する方法\「スクリプト... \ "Androidのコンテンツセキュリティポリシーによるエラーのロードを拒否しましたか?ミステリーを発表する:コンテンツセキュリティポリシー指示エラー 謎めいたエラーに遭遇する「スクリプトのロードを拒否する...」Androidアプリを展開するときに?この問題は、信頼されていないソースからのリソースの負荷を制限するコンテンツセキュリティポリシー(CSP)指令に由来しています。...プログラミング 2025-03-25に投稿されました
-
java.net.urlconnectionとmultipart/form-dataエンコードを使用して追加のパラメーターを使用してファイルをアップロードする方法は?http requests を使用してファイルをhttpサーバーにアップロードしながら、追加のパラメーター、java.net.urlconnection、およびmultipart/dataエンコーディングを送信します。プロセスの内訳は次のとおりです。エンコーディングには、要求本体を複数...プログラミング 2025-03-25に投稿されました
-
FlexBoxと垂直スクロールをフルハイトレイアウトで効果的に組み合わせるにはどうすればよいですか?FlexBoxと垂直スクロールをフルハイトレイアウトに統合する フルハイトアプリケーションを操作する場合、FlexBoxと垂直スクロールバーを組み合わせた場合、一般的な要件になります。ただし、フレックスボックスレイアウトのインタラクティブな性質により、課題を引き起こす可能性があります。こ...プログラミング 2025-03-25に投稿されました
-
PHPのUnicode文字列からURLに優しいナメクジを効率的に生成するにはどうすればよいですか?効率的なナメクジ生成のための関数を作成する スラッグの作成、URLで使用されるユニコード文字列の単純化された表現は、挑戦的な作業になります。この記事では、スラッグを効率的に生成し、特殊文字と非ASCII文字をURLに優しい形式に変換するための簡潔なソリューションを紹介します。一連の操作を使...プログラミング 2025-03-25に投稿されました
-
データ挿入時の「一般エラー: 2006 MySQL サーバーが消えました」を修正するにはどうすればよいですか?レコードの挿入中に「一般エラー: 2006 MySQL サーバーが消えました」を解決する方法はじめに:MySQL データベースにデータを挿入すると、「一般エラー: 2006 MySQL サーバーが消えました。」というエラーが発生することがあります。このエラーは、通常、MySQL 構成内の 2 つの変...プログラミング 2025-03-25に投稿されました















中国語を勉強する
- 1 「歩く」は中国語で何と言いますか? 走路 中国語の発音、走路 中国語学習
- 2 「飛行機に乗る」は中国語で何と言いますか? 坐飞机 中国語の発音、坐飞机 中国語学習
- 3 「電車に乗る」は中国語で何と言いますか? 坐火车 中国語の発音、坐火车 中国語学習
- 4 「バスに乗る」は中国語で何と言いますか? 坐车 中国語の発音、坐车 中国語学習
- 5 中国語でドライブは何と言うでしょう? 开车 中国語の発音、开车 中国語学習
- 6 水泳は中国語で何と言うでしょう? 游泳 中国語の発音、游泳 中国語学習
- 7 中国語で自転車に乗るってなんて言うの? 骑自行车 中国語の発音、骑自行车 中国語学習
- 8 中国語で挨拶はなんて言うの? 你好中国語の発音、你好中国語学習
- 9 中国語でありがとうってなんて言うの? 谢谢中国語の発音、谢谢中国語学習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









