
通常の等変 CNN を構築するための原則
 ブラウズ:711
ブラウズ:711
The one principle is simply stated as 'Let the kernel rotate' and we will focus in this article on how you can apply it in your architectures.
Equivariant architectures allow us to train models which are indifferent to certain group actions.
To understand what this exactly means, let us train this simple CNN model on the MNIST dataset (a dataset of handwritten digits from 0-9).
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.cl1 = nn.Conv2d(in_channels=1, out_channels=8, kernel_size=3, padding=1)
self.max_1 = nn.MaxPool2d(kernel_size=2)
self.cl2 = nn.Conv2d(in_channels=8, out_channels=16, kernel_size=3, padding=1)
self.max_2 = nn.MaxPool2d(kernel_size=2)
self.cl3 = nn.Conv2d(in_channels=16, out_channels=16, kernel_size=7)
self.dense = nn.Linear(in_features=16, out_features=10)
def forward(self, x: torch.Tensor):
x = nn.functional.silu(self.cl1(x))
x = self.max_1(x)
x = nn.functional.silu(self.cl2(x))
x = self.max_2(x)
x = nn.functional.silu(self.cl3(x))
x = x.view(len(x), -1)
logits = self.dense(x)
return logits
| Accuracy on test | Accuracy on 90-degree rotated test |
|---|---|
| 97.3% | 15.1% |
Table 1: Test accuracy of the SimpleCNN model
As expected, we get over 95% accuracy on the testing dataset, but what if we rotate the image by 90 degrees? Without any countermeasures applied, the results drop to just slightly better than guessing. This model would be useless for general applications.
In contrast, let us train a similar equivariant architecture with the same number of parameters, where the group actions are exactly the 90-degree rotations.
| Accuracy on test | Accuracy on 90-degree rotated test |
|---|---|
| 96.5% | 96.5% |
Table 2: Test accuracy of the EqCNN model with the same amount of parameters as the SimpleCNN model
The accuracy remains the same, and we did not even opt for data augmentation.
These models become even more impressive with 3D data, but we will stick with this example to explore the core idea.
In case you want to test it out for yourself, you can access all code written in both PyTorch and JAX for free under Github-Repo, and training with Docker or Podman is possible with just two commands.
Have fun!
So What is Equivariance?
Equivariant architectures guarantee stability of features under certain group actions. Groups are simple structures where group elements can be combined, reversed, or do nothing.
You can look up the formal definition on Wikipedia if you are interested.
For our purposes, you can think of a group of 90-degree rotations acting on square images. We can rotate an image by 90, 180, 270, or 360 degrees. To reverse the action, we apply a 270, 180, 90, or 0-degree rotation respectively. It is straightforward to see that we can combine, reverse, or do nothing with the group denoted as C4 . The image visualizes all actions on an image.
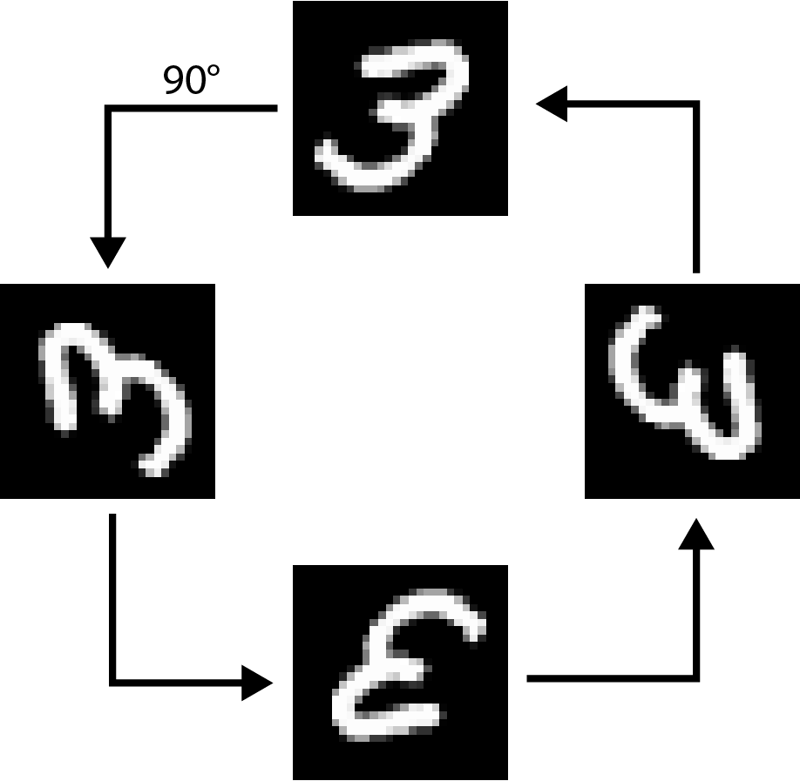
Figure 1: Rotated MNIST image by 90°, 180°, 270°, 360°, respectively
Now, given an input image
x
, our CNN model classifier
fθ
, and an arbitrary 90-degree rotation
g
, the equivariant property can be expressed as
fθ(rotate x by g)=fθ(x)
Generally speaking, we want our image-based model to have the same outputs when rotated.
As such, equivariant models promise us architectures with baked-in symmetries. In the following section, we will see how our principle can be applied to achieve this property.
How to Make Our CNN Equivariant
The problem is the following: When the image rotates, the features rotate too. But as already hinted, we could also compute the features for each rotation upfront by rotating the kernel.
We could actually rotate the kernel, but it is much easier to rotate the feature map itself, thus avoiding interference with PyTorch's autodifferentiation algorithm altogether.
So, in code, our CNN kernel
x = nn.functional.silu(self.cl1(x))
now acts on all four rotated images:
x_0 = x x_90 = torch.rot90(x, k=1, dims=(2, 3)) x_180 = torch.rot90(x, k=2, dims=(2, 3)) x_270 = torch.rot90(x, k=3, dims=(2, 3)) x_0 = nn.functional.silu(self.cl1(x_0)) x_90 = nn.functional.silu(self.cl1(x_90)) x_180 = nn.functional.silu(self.cl1(x_180)) x_270 = nn.functional.silu(self.cl1(x_270))
Or more compactly written as a 3D convolution:
self.cl1 = nn.Conv3d(in_channels=1, out_channels=8, kernel_size=(1, 3, 3)) ... x = torch.stack([x_0, x_90, x_180, x_270], dim=-3) x = nn.functional.silu(self.cl1(x))
The resulting equivariant model has just a few lines more compared to the version above:
class EqCNN(nn.Module):
def __init__(self):
super(EqCNN, self).__init__()
self.cl1 = nn.Conv3d(in_channels=1, out_channels=8, kernel_size=(1, 3, 3))
self.max_1 = nn.MaxPool3d(kernel_size=(1, 2, 2))
self.cl2 = nn.Conv3d(in_channels=8, out_channels=16, kernel_size=(1, 3, 3))
self.max_2 = nn.MaxPool3d(kernel_size=(1, 2, 2))
self.cl3 = nn.Conv3d(in_channels=16, out_channels=16, kernel_size=(1, 5, 5))
self.dense = nn.Linear(in_features=16, out_features=10)
def forward(self, x: torch.Tensor):
x_0 = x
x_90 = torch.rot90(x, k=1, dims=(2, 3))
x_180 = torch.rot90(x, k=2, dims=(2, 3))
x_270 = torch.rot90(x, k=3, dims=(2, 3))
x = torch.stack([x_0, x_90, x_180, x_270], dim=-3)
x = nn.functional.silu(self.cl1(x))
x = self.max_1(x)
x = nn.functional.silu(self.cl2(x))
x = self.max_2(x)
x = nn.functional.silu(self.cl3(x))
x = x.squeeze()
x = torch.max(x, dim=-1).values
logits = self.dense(x)
return logits
But why is this equivariant to rotations?
First, observe that we get four copies of each feature map at each stage. At the end of the pipeline, we combine all of them with a max operation.
This is key, the max operation is indifferent to which place the rotated version of the feature ends up in.
To understand what is happening, let us plot the feature maps after the first convolution stage.
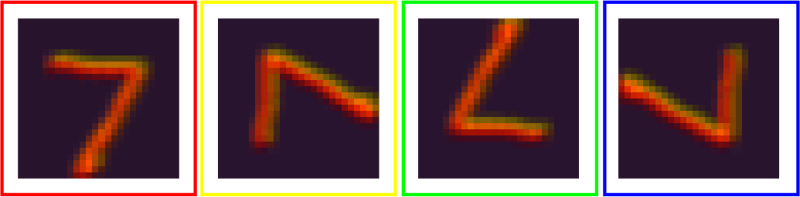
Figure 2: Feature maps for all four rotations
And now the same features after we rotate the input by 90 degrees.
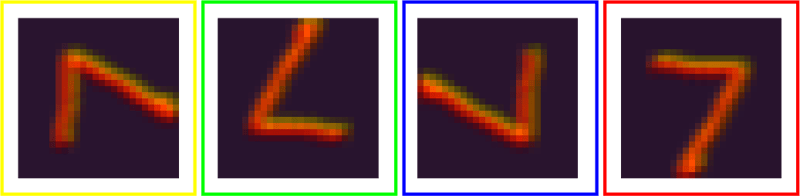
Figure 3: Feature maps for all four rotations after the input image was rotated
I color-coded the corresponding maps. Each feature map is shifted by one. As the final max operator computes the same result for these shifted feature maps, we obtain the same results.
In my code, I did not rotate back after the final convolution, since my kernels condense the image to a one-dimensional array. If you want to expand on this example, you would need to account for this fact.
Accounting for group actions or "kernel rotations" plays a vital role in the design of more sophisticated architectures.
Is it a Free Lunch?
No, we pay in computational speed, inductive bias, and a more complex implementation.
The latter point is somewhat solved with libraries such as E3NN, where most of the heavy math is abstracted away. Nevertheless, one needs to account for a lot during architecture design.
One superficial weakness is the 4x computational cost for computing all rotated feature layers. However, modern hardware with mass parallelization can easily counteract this load. In contrast, training a simple CNN with data augmentation would easily exceed 10x in training time. This gets even worse for 3D rotations where data augmentation would require about 500x the training amount to compensate for all possible rotations.
Overall, equivariance model design is more often than not a price worth paying if one wants stable features.
What is Next?
Equivariant model designs have exploded in recent years, and in this article, we barely scratched the surface. In fact, we did not even exploit the full C4 group yet. We could have used full 3D kernels. However, our model already achieves over 95% accuracy, so there is little reason to go further with this example.
Besides CNNs, researchers have successfully translated these principles to continuous groups, including SO(2) (the group of all rotations in the plane) and SE(3) (the group of all translations and rotations in 3D space).
In my experience, these models are absolutely mind-blowing and achieve performance, when trained from scratch, comparable to the performance of foundation models trained on multiple times larger datasets.
Let me know if you want me to write more on this topic.
Further References
In case you want a formal introduction to this topic, here is an excellent compilation of papers, covering the complete history of equivariance in Machine Learning.
AEN
I actually plan to create a deep-dive, hands-on tutorial on this topic. You can already sign up for my mailing list, and I will provide you with free versions over time, along with a direct channel for feedback and Q&A.
See you around :)
-
 Firefoxバックボタンを使用すると、JavaScriptの実行が停止するのはなぜですか?navigational Historyの問題:JavaScriptは、Firefoxバックボタンを使用した後に実行を停止します ユーザーは、JavaScriptスクリプトが以前の訪問ページを介して回復したときに実行されない問題に遭遇する可能性があります。この問題は、ChromeやInt...プログラミング 2025-03-28に投稿されました
Firefoxバックボタンを使用すると、JavaScriptの実行が停止するのはなぜですか?navigational Historyの問題:JavaScriptは、Firefoxバックボタンを使用した後に実行を停止します ユーザーは、JavaScriptスクリプトが以前の訪問ページを介して回復したときに実行されない問題に遭遇する可能性があります。この問題は、ChromeやInt...プログラミング 2025-03-28に投稿されました -
3つのMySQLテーブルのデータを新しいテーブルに組み合わせる方法は?mysql:3つのテーブルのデータと列から新しいテーブルを作成する 質問: 人々、詳細、および分類表の表? P。*、d.contentを年齢として選択します psとしての人々から D.Person_id = p.idのDとして詳細を結合します t.id = d.detail_idでt...プログラミング 2025-03-28に投稿されました
-
なぜ `body {margin:0; } `常にCSSの上限を削除しますか?css の扱います。多くの場合、「ボディ{マージン:0;}」などの提供されたコードは、目的の結果を生成しません。これは、コンテンツの親要素が正のパディング値を持っている場合に発生する可能性があります。特定のマージンの問題に対処することをお勧めします。親要素にパディングがある場合、それを...プログラミング 2025-03-28に投稿されました
-
Node-MYSQLを使用して単一のクエリで複数のSQLステートメントを実行するにはどうすればよいですか?node-mysql in node.jsでのマルチステートメントクエリサポート、ノード-Mysqlパッケージを使用してnode-mysqlを使用してnode-mysqlを使用して、1つのクエリを使用してnode-mysqlの記録を使用して、1つのクエリで複数のsqlステートメントを...プログラミング 2025-03-28に投稿されました
-
PHPを使用してXMLファイルから属性値を効率的に取得するにはどうすればよいですか?XMLファイルから属性値をPHP の取得します。提供されている例のような属性を含むXMLファイルを使用する場合: $xml = simplexml_load_file($file); foreach ($xml->Var[0]->attributes() as $att...プログラミング 2025-03-28に投稿されました
-
Javaで、ディレクトリの変更を含むコマンドプロンプトコマンドを実行するにはどうすればよいですか?executeコマンドプロンプトコマンドのjava 問題: を実行しているコマンドプロンプトコマンドをJavaを介して挑戦することができます。コマンドプロンプトを開くコードスニペットを見つけることができますが、ディレクトリを変更して追加のコマンドを実行する機能が不足しています。この...プログラミング 2025-03-28に投稿されました
-
解決する方法\「スクリプト... \ "Androidのコンテンツセキュリティポリシーによるエラーのロードを拒否しましたか?ミステリーを発表する:コンテンツセキュリティポリシー指示エラー 謎めいたエラーに遭遇する「スクリプトのロードを拒否する...」Androidアプリを展開するときに?この問題は、信頼されていないソースからのリソースの負荷を制限するコンテンツセキュリティポリシー(CSP)指令に由来しています。...プログラミング 2025-03-28に投稿されました
-
プログラムを終了する前に、C ++のヒープ割り当てを明示的に削除する必要がありますか?プログラム出口にもかかわらず、Cでの明示的な削除 次の例を考慮してください。 a* a = new a(); a-> dosomething(); a; 0を返します。 } この例では、「削除」ステートメントは、「a」ポインターに割り当てられたヒープメモ...プログラミング 2025-03-28に投稿されました
-
FlexBoxと垂直スクロールをフルハイトレイアウトで効果的に組み合わせるにはどうすればよいですか?FlexBoxと垂直スクロールをフルハイトレイアウトに統合する フルハイトアプリケーションを操作する場合、FlexBoxと垂直スクロールバーを組み合わせた場合、一般的な要件になります。ただし、フレックスボックスレイアウトのインタラクティブな性質により、課題を引き起こす可能性があります。こ...プログラミング 2025-03-28に投稿されました
-
PHPでタイムゾーンを効率的に変換する方法は?php での効率的なタイムゾーン変換は、タイムゾーンの取り扱いは簡単なタスクになる可能性があります。このガイドは、異なるタイムゾーン間で日付と時間を変換するための簡単な実装方法を提供します。たとえば、 //ユーザーのタイムゾーンを定義します date_default_timezone_s...プログラミング 2025-03-28に投稿されました
-
Silverlight linqクエリで「クエリパターンの実装が見つからなかった」エラーを取得するのはなぜですか?Queryパターンの実装不在:「silverlightアプリケーションで「&&&&] を解決する」cleryパターンの不在、linqを使用してデータベース接続を確立しようとする試みは、「クエリパターンの実装」を見つけることができませんでした。このエラーは通常、LINQネームスペースが省略...プログラミング 2025-03-28に投稿されました
-
Pythonの文字列から絵文字を削除する方法:一般的なエラーを修正するための初心者のガイド?emojisをpython emojisの除去する絵文字を削除するための提供されたPythonコードは、構文誤差が含まれているため失敗します。 Unicode文字列は、Python 2のU ''プレフィックスを使用して指定する必要があります。さらに、Re.Unicod...プログラミング 2025-03-28に投稿されました
-
純粋なCSSでは、複数の粘着性要素を互いに積み重ねることができますか?純粋なCSSで複数の粘着性要素を互いに積み重ねることは可能ですか?ここ: https://webthemez.com/demo/sticky-multi-header-scroll/index.html JavaScriptの実装ではなく、純粋なCSSを使用することのみです。複数の粘...プログラミング 2025-03-28に投稿されました
-
Python読み取りCSVファイルUnicodedeCodeError究極のソリューションunicode decodeエラーがcsvファイルreading 内蔵csvモジュールを使用してpythonにcsvファイルを読み込もうとする場合、エラーが発生する可能性があります: SyntaxError: (unicode error) 'unicodeescape' codec ...プログラミング 2025-03-28に投稿されました
-
GOでSQLクエリを構築するときに、テキストと値を安全に連結するにはどうすればよいですか?go sql queries のテキストと値を連結するgoのテキストsqlクエリを構築する際に、特に文字列を使用した場合、文字列を使用した場合に、文字列を使用する場合、アプローチはGOでは有効ではなく、文字列としてパラメーターをキャストしようとすると、タイプのミスマッチエラーが発生しま...プログラミング 2025-03-28に投稿されました















中国語を勉強する
- 1 「歩く」は中国語で何と言いますか? 走路 中国語の発音、走路 中国語学習
- 2 「飛行機に乗る」は中国語で何と言いますか? 坐飞机 中国語の発音、坐飞机 中国語学習
- 3 「電車に乗る」は中国語で何と言いますか? 坐火车 中国語の発音、坐火车 中国語学習
- 4 「バスに乗る」は中国語で何と言いますか? 坐车 中国語の発音、坐车 中国語学習
- 5 中国語でドライブは何と言うでしょう? 开车 中国語の発音、开车 中国語学習
- 6 水泳は中国語で何と言うでしょう? 游泳 中国語の発音、游泳 中国語学習
- 7 中国語で自転車に乗るってなんて言うの? 骑自行车 中国語の発音、骑自行车 中国語学習
- 8 中国語で挨拶はなんて言うの? 你好中国語の発音、你好中国語学習
- 9 中国語でありがとうってなんて言うの? 谢谢中国語の発音、谢谢中国語学習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









