
画像セグメンテーションをマスターする: デジタル時代でも伝統的な技術がどのように輝き続けるのか
 ブラウズ:562
ブラウズ:562
導入
コンピュータ ビジョンの最も基本的な手順の 1 つである画像セグメンテーションにより、システムは画像内のさまざまな領域を分解して分析できます。物体認識、医療画像処理、自動運転のいずれを扱う場合でも、セグメンテーションは画像を意味のある部分に分割するものです。
このタスクではディープ ラーニング モデルの人気が高まり続けていますが、デジタル画像処理における従来の技術は依然として強力で実用的です。この投稿でレビューされているアプローチには、しきい値処理、エッジ検出、領域ベース、および細胞画像解析用のよく知られたデータセットである MIVIA HEp-2 画像データセットを実装することによるクラスタリングが含まれます。
MIVIA HEp-2 画像データセット
MIVIA HEp-2 画像データセットは、HEp-2 細胞による抗核抗体 (ANA) のパターンを分析するために使用される細胞の写真のセットです。これは、蛍光顕微鏡によって撮影された 2D 写真で構成されています。これにより、セグメンテーション タスク、特に細胞領域の検出が最も重要な医療画像分析に関係するタスクに非常に適しています。
ここで、これらの画像の処理に使用されるセグメンテーション手法に移り、F1 スコアに基づいてパフォーマンスを比較しましょう。
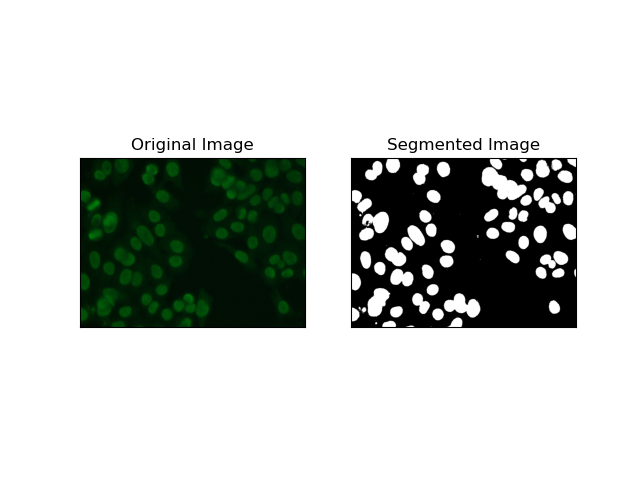
1. 閾値セグメンテーション
しきい値処理は、ピクセル強度に基づいてグレースケール イメージをバイナリ イメージに変換するプロセスです。 MIVIA HEp-2 データセットでは、このプロセスはバックグラウンドからの細胞抽出に役立ちます。これは、最適なしきい値を自己計算するため、特に Otsu の方法 では、比較的大きなレベルまでシンプルかつ効果的です。
Otsu のメソッド は自動しきい値処理方法であり、クラス内分散を最小限に抑える最適なしきい値を見つけようとし、それによって前景 (セル) と背景の 2 つのクラスを分離します。このメソッドは、画像のヒストグラムを調べて、各クラスのピクセル強度分散の合計が最小化される完全なしきい値を計算します。
# Thresholding Segmentation
def thresholding(img):
# Convert image to grayscale
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# Apply Otsu's thresholding
_, thresh = cv.threshold(gray, 0, 255, cv.THRESH_BINARY cv.THRESH_OTSU)
return thresh
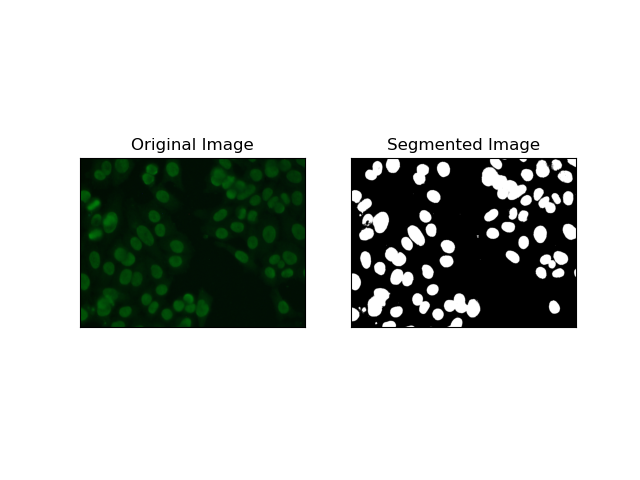
2. エッジ検出セグメンテーション
エッジ検出は、MIVIA HEp-2 データセット内のセル エッジなど、オブジェクトまたは領域の境界の識別に関係します。突然の強度変化を検出するために利用可能な多くの方法の中で、Canny Edge Detector が最良であり、したがって細胞境界の検出に使用するのに最も適した方法です。
Canny Edge Detector は、強度の強い勾配の領域を検出することでエッジを検出できる多段階アルゴリズムです。このプロセスには、ガウス フィルターによる平滑化、強度勾配の計算、スプリアス応答を除去するための非最大抑制の適用、および顕著なエッジのみを保持するための最終的な二重しきい値処理操作が組み込まれています。
# Edge Detection Segmentation
def edge_detection(img):
# Convert image to grayscale
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# Apply Gaussian blur
gray = cv.GaussianBlur(gray, (3, 3), 0)
# Calculate lower and upper thresholds for Canny edge detection
sigma = 0.33
v = np.median(gray)
lower = int(max(0, (1.0 - sigma) * v))
upper = int(min(255, (1.0 sigma) * v))
# Apply Canny edge detection
edges = cv.Canny(gray, lower, upper)
# Dilate the edges to fill gaps
kernel = np.ones((5, 5), np.uint8)
dilated_edges = cv.dilate(edges, kernel, iterations=2)
# Clean the edges using morphological opening
cleaned_edges = cv.morphologyEx(dilated_edges, cv.MORPH_OPEN, kernel, iterations=1)
# Find connected components and filter out small components
num_labels, labels, stats, _ = cv.connectedComponentsWithStats(
cleaned_edges, connectivity=8
)
min_size = 500
filtered_mask = np.zeros_like(cleaned_edges)
for i in range(1, num_labels):
if stats[i, cv.CC_STAT_AREA] >= min_size:
filtered_mask[labels == i] = 255
# Find contours of the filtered mask
contours, _ = cv.findContours(
filtered_mask, cv.RETR_EXTERNAL, cv.CHAIN_APPROX_SIMPLE
)
# Create a filled mask using the contours
filled_mask = np.zeros_like(gray)
cv.drawContours(filled_mask, contours, -1, (255), thickness=cv.FILLED)
# Perform morphological closing to fill holes
final_filled_image = cv.morphologyEx(
filled_mask, cv.MORPH_CLOSE, kernel, iterations=2
)
# Dilate the final filled image to smooth the edges
final_filled_image = cv.dilate(final_filled_image, kernel, iterations=1)
return final_filled_image
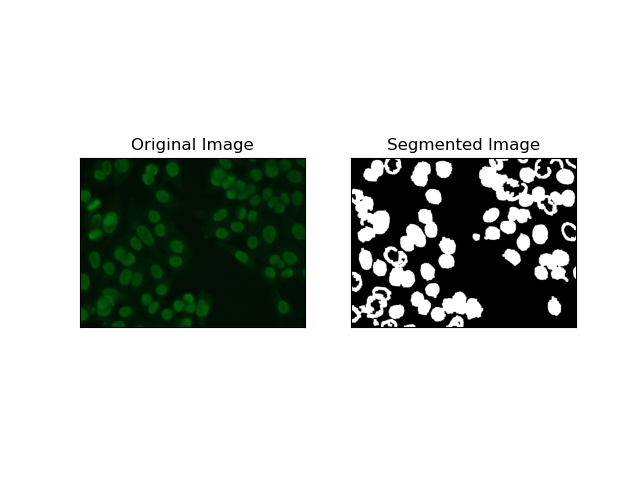
3. 地域ベースのセグメンテーション
領域ベースのセグメンテーションは、強度や色などの特定の基準に応じて、類似したピクセルを領域にグループ化します。 ウォーターシェッドセグメンテーション技術を使用すると、HEp-2 細胞画像をセグメント化し、細胞を表す領域を検出できるようになります。ピクセル強度を地形的な表面として考慮し、特徴的な領域の輪郭を描きます。
流域セグメンテーションは、ピクセルの強度を地形的な表面として扱います。このアルゴリズムは「盆地」を特定し、その中で極小値を特定し、これらの盆地を徐々に浸水させて個別の領域を拡大します。この技術は、顕微鏡画像内の細胞の場合のように、接触しているオブジェクトを分離したい場合に非常に役立ちますが、ノイズに敏感になる可能性があります。プロセスはマーカーによってガイドでき、多くの場合、過剰なセグメント化を減らすことができます。
# Region-Based Segmentation
def region_based(img):
# Convert image to grayscale
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# Apply Otsu's thresholding
_, thresh = cv.threshold(gray, 0, 255, cv.THRESH_BINARY_INV cv.THRESH_OTSU)
# Apply morphological opening to remove noise
kernel = np.ones((3, 3), np.uint8)
opening = cv.morphologyEx(thresh, cv.MORPH_OPEN, kernel, iterations=2)
# Dilate the opening to get the background
sure_bg = cv.dilate(opening, kernel, iterations=3)
# Calculate the distance transform
dist_transform = cv.distanceTransform(opening, cv.DIST_L2, 5)
# Threshold the distance transform to get the foreground
_, sure_fg = cv.threshold(dist_transform, 0.2 * dist_transform.max(), 255, 0)
sure_fg = np.uint8(sure_fg)
# Find the unknown region
unknown = cv.subtract(sure_bg, sure_fg)
# Label the markers for watershed algorithm
_, markers = cv.connectedComponents(sure_fg)
markers = markers 1
markers[unknown == 255] = 0
# Apply watershed algorithm
markers = cv.watershed(img, markers)
# Create a mask for the segmented region
mask = np.zeros_like(gray, dtype=np.uint8)
mask[markers == 1] = 255
return mask
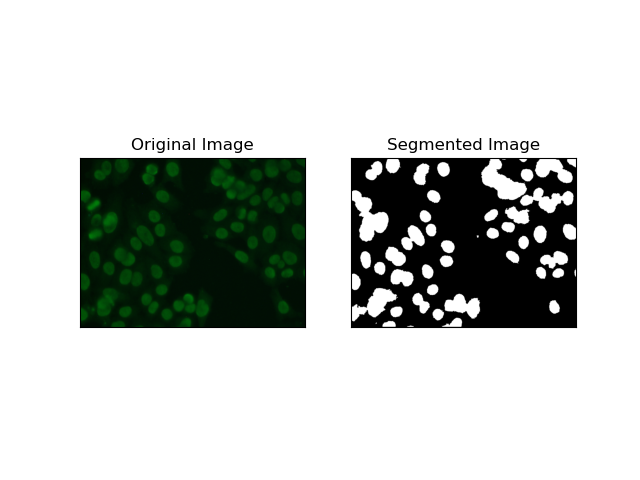
4. クラスタリングベースのセグメンテーション
K-Means などの クラスタリング手法は、ピクセルを同様のクラスターにグループ化する傾向があり、HEp-2 細胞画像に見られるように、多色または複雑な環境で細胞をセグメント化する場合にうまく機能します。基本的に、これは細胞領域と背景などのさまざまなクラスを表すことができます。
K-means は、色または強度のピクセル類似性に基づいて画像をクラスタリングするための教師なし学習アルゴリズムです。このアルゴリズムは K 個の重心をランダムに選択し、各ピクセルを最も近い重心に割り当て、収束するまで重心を繰り返し更新します。これは、互いに大きく異なる複数の関心領域を含む画像をセグメント化する場合に特に効果的です。
# Clustering Segmentation
def clustering(img):
# Convert image to grayscale
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# Reshape the image
Z = gray.reshape((-1, 3))
Z = np.float32(Z)
# Define the criteria for k-means clustering
criteria = (cv.TERM_CRITERIA_EPS cv.TERM_CRITERIA_MAX_ITER, 10, 1.0)
# Set the number of clusters
K = 2
# Perform k-means clustering
_, label, center = cv.kmeans(Z, K, None, criteria, 10, cv.KMEANS_RANDOM_CENTERS)
# Convert the center values to uint8
center = np.uint8(center)
# Reshape the result
res = center[label.flatten()]
res = res.reshape((gray.shape))
# Apply thresholding to the result
_, res = cv.threshold(res, 0, 255, cv.THRESH_BINARY cv.THRESH_OTSU)
return res
F1 スコアを使用したテクニックの評価
F1 スコアは、予測されたセグメンテーション イメージとグラウンド トゥルース イメージを比較するために精度と再現率を組み合わせた尺度です。これは精度と再現率の調和平均であり、医療画像データセットなど、データの不均衡が大きい場合に役立ちます。
グラウンド トゥルースとセグメント化された画像の両方を平坦化し、重み付けされた F1 スコアを計算することで、各セグメンテーション方法の F1 スコアを計算しました。
def calculate_f1_score(ground_image, segmented_image):
ground_image = ground_image.flatten()
segmented_image = segmented_image.flatten()
return f1_score(ground_image, segmented_image, average="weighted")
次に、単純な棒グラフを使用して、さまざまなメソッドの F1 スコアを視覚化しました。
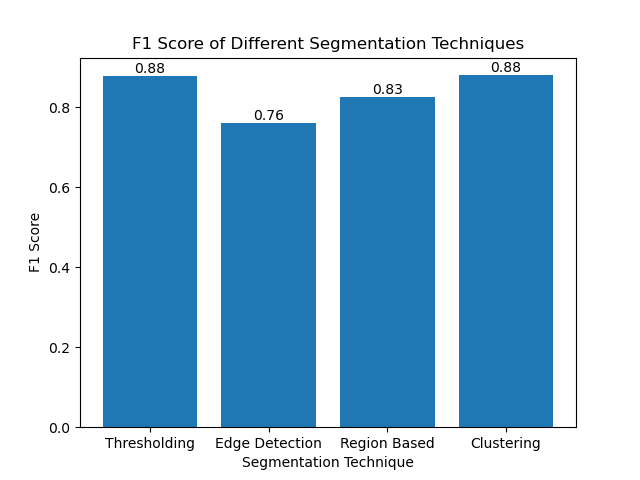
結論
画像セグメンテーションに対する最近のアプローチは数多く登場していますが、しきい値処理、エッジ検出、領域ベースの手法、クラスタリングなどの従来のセグメンテーション技術は、MIVIA HEp-2 画像データセットなどのデータセットに適用すると非常に役立ちます。
それぞれの方法には長所があります:
- しきい値は、単純なバイナリ セグメンテーションに適しています。
- エッジ検出は、境界を検出するための理想的な技術です。
- 領域ベースセグメンテーションは、接続されたコンポーネントを隣接コンポーネントから分離するのに非常に役立ちます。
- クラスタリング手法は、複数領域のセグメンテーション タスクに適しています。
F1 スコアを使用してこれらのメソッドを評価することで、これらのモデルのそれぞれが持つトレードオフを理解します。これらの手法は、深層学習の最新モデルで開発されているものほど洗練されていないかもしれませんが、依然として高速で解釈可能であり、幅広いアプリケーションで利用可能です。
読んでいただきありがとうございます!従来の画像セグメンテーション技術のこの探索が、あなたの次のプロジェクトにインスピレーションを与えることを願っています。以下のコメント欄であなたの考えや経験を自由に共有してください!
-
 PHPを使用してBlob(画像)をMySQLに適切に挿入する方法は?php mysqlデータベースを持つmysqlデータベースにブロブを挿入すると、mysqlデータベースに画像を保存しようとすると、遭遇するかもしれません問題。このガイドは、画像データを正常に保存するためのソリューションを提供します。 ImageId、image) values( &...プログラミング 2025-07-13に投稿されました
PHPを使用してBlob(画像)をMySQLに適切に挿入する方法は?php mysqlデータベースを持つmysqlデータベースにブロブを挿入すると、mysqlデータベースに画像を保存しようとすると、遭遇するかもしれません問題。このガイドは、画像データを正常に保存するためのソリューションを提供します。 ImageId、image) values( &...プログラミング 2025-07-13に投稿されました -
Go Webアプリケーションはいつデータベース接続を閉じますか?Go Webアプリケーションのデータベース接続の管理 PostgreSQLなどのデータベースを使用する単純なGO Webアプリケーションで、データベース接続の閉鎖のタイミングが考慮されます。これは、無期限に実行されるアプリケーションでこれをいつ、どのように処理するかを深く掘り下げます。 f...プログラミング 2025-07-13に投稿されました
-
なぜ `body {margin:0; } `常にCSSの上限を削除しますか?css の扱います。多くの場合、「ボディ{マージン:0;}」などの提供されたコードは、目的の結果を生成しません。これは、コンテンツの親要素が正のパディング値を持っている場合に発生する可能性があります。特定のマージンの問題に対処することをお勧めします。親要素にパディングがある場合、それを...プログラミング 2025-07-13に投稿されました
-
JavaScriptオブジェクトにキーを動的に設定する方法は?JavaScriptオブジェクト変数の動的キーを作成する方法 この構文jsObj['key' i] = 'example' 1; はjavascriptで、アレイは特殊なタイプのオブジェクトです。この特別な動作は標準のオブジェクトによって模倣されていませんが、四角いブラケット演算子は...プログラミング 2025-07-13に投稿されました
-
PHPの2つの等しいサイズの配列から値を同期して反復して印刷するにはどうすればよいですか?同じサイズの2つの配列の2つの配列から値を同期して反復して印刷する場合、同サイズの2つの配列を使用してselectboxを作成する場合、1つは対応する名前を含む1つを使用して、困難が不適切なsyntaxに起因する可能性があります。アレイ: foreach($ codes as $ code、...プログラミング 2025-07-13に投稿されました
-
PHPのファイルシステム機能でUTF-8ファイル名を処理するにはどうすればよいですか?PHPのファイルシステム関数のUTF-8ファイル名を処理する PHPのMKDIR関数を使用してUTF-8文字を含むフォルダーを作成するとき、 に遭遇するwindows explorerに遭遇する可能性があります。 urlエンコードファイル名 この問題を解決するには、urlencod...プログラミング 2025-07-13に投稿されました
-
底の右側に浮かぶ写真のヒントとテキストの周りを包むは、Webデザインで を包み回して画像を右下に浮かびます。ページの右下隅に画像をフロートさせ、テキストを巻き付けることが望ましい場合があります。これにより、画像を効果的に紹介しながら、魅力的な視覚効果が生じる可能性があります。このコンテナ内で、画像のテキストコンテンツとIMG要素を追加し...プログラミング 2025-07-13に投稿されました
-
バージョン5.6.5の前にMySQLのタイムスタンプ列を使用してcurrent_timestampを使用することの制限は何でしたか?の制限current_timestampがデフォルトまたは5.6.5より前のmysqlバージョンのcurrent_timestampの更新条項の制限 は歴史的に、5.6.5以前のmysqlバージョンでは、デフォルトの列のみを制限しました。 current_timestamp句。この制限は、20...プログラミング 2025-07-13に投稿されました
-
CSS「コンテンツ」プロパティを使用してFirefoxが画像を表示しないのはなぜですか?firefox のコンテンツURLを使用して画像を表示します。これは、提供されたCSSクラスで見ることができます: .googlePic { content: url('../../img/googlePlusIcon.PNG'); margin-top: -6.5%;...プログラミング 2025-07-13に投稿されました
-
AndroidはどのようにPHPサーバーに投稿データを送信しますか?をAndroid に送信します。これは、サーバー側の通信を扱う際の一般的なシナリオです。 apache httpclient(deprecated) httpclient httpclient = new defulthttpclient(); httppost httppost ...プログラミング 2025-07-13に投稿されました
-
3つのMySQLテーブルのデータを新しいテーブルに組み合わせる方法は?mysql:3つのテーブルのデータと列から新しいテーブルを作成する 質問: 人々、詳細、および分類表の表? P。*、d.contentを年齢として選択します psとしての人々から D.Person_id = p.idのDとして詳細を結合します t.id = d.detail_idでt...プログラミング 2025-07-13に投稿されました
-
一定の列を追加するためのSpark DataFrameのヒントスパークデータフレームに一定の列を作成する すべての行に適用される任意の値で一定の列をスパークデータフレームに追加することができます。この目的を目的としたwithcolumnメソッドは、2番目の引数として直接的な値を提供しようとするときにエラーを引き起こす可能性があります。点灯 df.wi...プログラミング 2025-07-13に投稿されました
-
CSSは、属性値に基づいてHTML要素を見つけることができますか?をCSS の属性値でHTML要素をターゲットとするCSSのターゲティング、以下の例に示すように、特定の属性に基づいてターゲット要素をターゲットにすることが可能です: [型]入力[型]入力[タイプ] { フォントファミリー:コンソラ。 } input[type=text] { ...プログラミング 2025-07-13に投稿されました
-
GO言語ガベージコレクションでスライスメモリを処理する方法は?Go slices:aftertial analysis *q =(*q)[1:len(*q)] rを返します } FUNCプッシュバック(Q *[]文字列、文字列){ *q = append(*q、a) } この場合、要素が正面からポップされると、スライスが...プログラミング 2025-07-13に投稿されました















中国語を勉強する
- 1 「歩く」は中国語で何と言いますか? 走路 中国語の発音、走路 中国語学習
- 2 「飛行機に乗る」は中国語で何と言いますか? 坐飞机 中国語の発音、坐飞机 中国語学習
- 3 「電車に乗る」は中国語で何と言いますか? 坐火车 中国語の発音、坐火车 中国語学習
- 4 「バスに乗る」は中国語で何と言いますか? 坐车 中国語の発音、坐车 中国語学習
- 5 中国語でドライブは何と言うでしょう? 开车 中国語の発音、开车 中国語学習
- 6 水泳は中国語で何と言うでしょう? 游泳 中国語の発音、游泳 中国語学習
- 7 中国語で自転車に乗るってなんて言うの? 骑自行车 中国語の発音、骑自行车 中国語学習
- 8 中国語で挨拶はなんて言うの? 你好中国語の発音、你好中国語学習
- 9 中国語でありがとうってなんて言うの? 谢谢中国語の発音、谢谢中国語学習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









