
faker および pandas Python ライブラリを使用してテスト用の合成データを作成する
 ブラウズ:670
ブラウズ:670
導入:
データ駆動型アプリケーションには包括的なテストが不可欠ですが、多くの場合、常に適切なデータセットが利用できるとは限りません。 Web アプリケーション、機械学習モデル、バックエンド システムのいずれを開発している場合でも、適切な検証と堅牢なパフォーマンスの確保には、現実的で構造化されたデータが不可欠です。現実世界のデータの取得は、プライバシー上の懸念、ライセンス制限、または単に関連データが利用できないことにより制限される場合があります。ここで合成データが価値を持ちます。
このブログでは、Python を使用して次のようなさまざまなシナリオの合成データを生成する方法を検討します。
- 相互関連テーブル: 1 対多の関係を表します。
- 階層データ: 組織構造でよく使用されます。
- 複雑な関係: 登録システムにおける多対多の関係など。
faker ライブラリと pandas ライブラリを活用して、これらのユースケース向けの現実的なデータセットを作成します。
例 1: 顧客と注文の合成データの作成 (1 対多の関係)
多くのアプリケーションでは、データは外部キー関係を持つ複数のテーブルに保存されます。顧客とその注文の合成データを生成してみましょう。顧客は 1 対多の関係を表す複数の注文を行うことができます。
顧客テーブルの生成
Customers テーブルには、CustomerID、名前、電子メール アドレスなどの基本情報が含まれています。
import pandas as pd
from faker import Faker
import random
fake = Faker()
def generate_customers(num_customers):
customers = []
for _ in range(num_customers):
customer_id = fake.uuid4()
name = fake.name()
email = fake.email()
customers.append({'CustomerID': customer_id, 'CustomerName': name, 'Email': email})
return pd.DataFrame(customers)
customers_df = generate_customers(10)
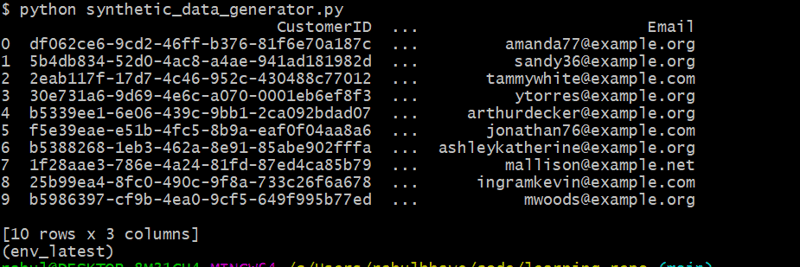
このコードは、Faker を使用して現実的な名前と電子メール アドレスを作成する 10 人のランダムな顧客を生成します。
注文テーブルの生成
ここで、各注文が CustomerID を通じて顧客に関連付けられる Orders テーブルを生成します。
def generate_orders(customers_df, num_orders):
orders = []
for _ in range(num_orders):
order_id = fake.uuid4()
customer_id = random.choice(customers_df['CustomerID'].tolist())
product = fake.random_element(elements=('Laptop', 'Phone', 'Tablet', 'Headphones'))
price = round(random.uniform(100, 2000), 2)
orders.append({'OrderID': order_id, 'CustomerID': customer_id, 'Product': product, 'Price': price})
return pd.DataFrame(orders)
orders_df = generate_orders(customers_df, 30)
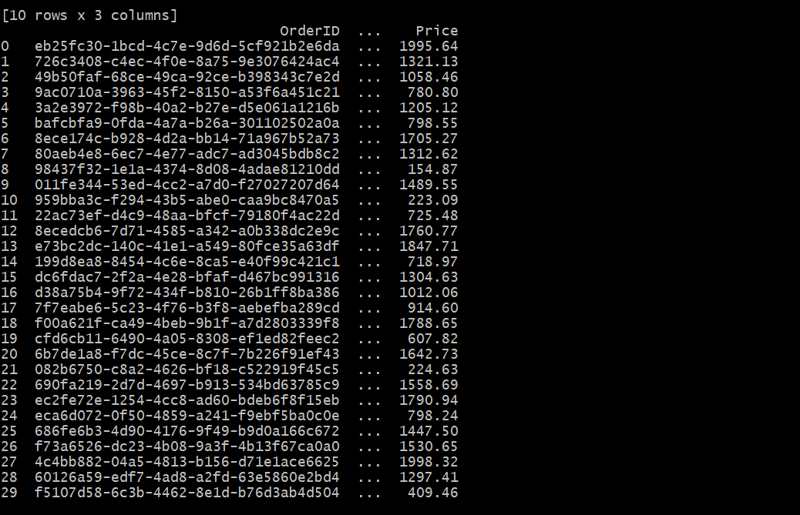
この場合、Orders テーブルは、CustomerID を使用して各注文を顧客にリンクします。各顧客は複数の注文を出し、1 対多の関係を形成できます。
例 2: 部門と従業員の階層データの生成
階層データは、部門に複数の従業員がいる組織環境でよく使用されます。各部門に複数の従業員がいる組織をシミュレートしてみましょう。
部門テーブルの生成
Departments テーブルには、各部門の一意のDepartmentID、名前、およびマネージャーが含まれています。
def generate_departments(num_departments):
departments = []
for _ in range(num_departments):
department_id = fake.uuid4()
department_name = fake.company_suffix()
manager = fake.name()
departments.append({'DepartmentID': department_id, 'DepartmentName': department_name, 'Manager': manager})
return pd.DataFrame(departments)
departments_df = generate_departments(10)
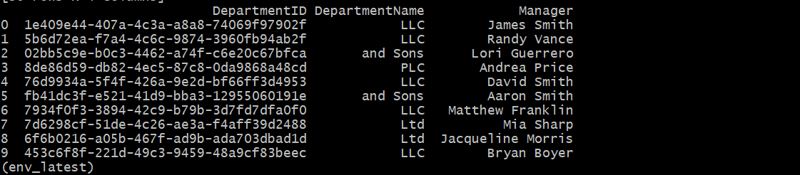
従業員テーブルの生成
次に、Employees テーブルを生成します。ここで、各従業員は、DepartmentID を介して部門に関連付けられます。
def generate_employees(departments_df, num_employees):
employees = []
for _ in range(num_employees):
employee_id = fake.uuid4()
employee_name = fake.name()
email = fake.email()
department_id = random.choice(departments_df['DepartmentID'].tolist())
salary = round(random.uniform(40000, 120000), 2)
employees.append({
'EmployeeID': employee_id,
'EmployeeName': employee_name,
'Email': email,
'DepartmentID': department_id,
'Salary': salary
})
return pd.DataFrame(employees)
employees_df = generate_employees(departments_df, 100)
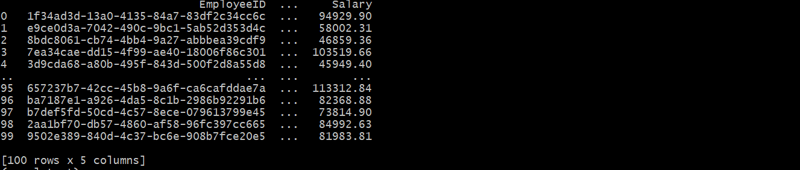
この階層構造は、DepartmentID を通じて各従業員を部門にリンクし、親子関係を形成します。
例 3: コース登録のための多対多の関係のシミュレーション
特定のシナリオでは、1 つのエンティティが他の多数のエンティティに関連する多対多の関係が存在します。各コースに複数の学生がいる複数のコースに登録する学生でこれをシミュレーションしてみましょう。
コース テーブルの生成
def generate_courses(num_courses):
courses = []
for _ in range(num_courses):
course_id = fake.uuid4()
course_name = fake.bs().title()
instructor = fake.name()
courses.append({'CourseID': course_id, 'CourseName': course_name, 'Instructor': instructor})
return pd.DataFrame(courses)
courses_df = generate_courses(20)
生徒テーブルの生成
def generate_students(num_students):
students = []
for _ in range(num_students):
student_id = fake.uuid4()
student_name = fake.name()
email = fake.email()
students.append({'StudentID': student_id, 'StudentName': student_name, 'Email': email})
return pd.DataFrame(students)
students_df = generate_students(50)
print(students_df)
コース登録テーブルの生成
CourseEnrollments テーブルは、学生とコース間の多対多の関係をキャプチャします。
def generate_course_enrollments(students_df, courses_df, num_enrollments):
enrollments = []
for _ in range(num_enrollments):
enrollment_id = fake.uuid4()
student_id = random.choice(students_df['StudentID'].tolist())
course_id = random.choice(courses_df['CourseID'].tolist())
enrollment_date = fake.date_this_year()
enrollments.append({
'EnrollmentID': enrollment_id,
'StudentID': student_id,
'CourseID': course_id,
'EnrollmentDate': enrollment_date
})
return pd.DataFrame(enrollments)
enrollments_df = generate_course_enrollments(students_df, courses_df, 200)
この例では、学生とコース間の多対多の関係を表すリンク テーブルを作成します。
結論:
Python と Faker や Pandas などのライブラリを使用すると、さまざまなテストのニーズを満たす現実的で多様な合成データセットを生成できます。このブログでは次のことを取り上げました:
- 相互関連テーブル: 顧客と注文の間の 1 対多の関係を示します。
- 階層データ: 部門と従業員の間の親子関係を示します。
- 複雑な関係: 学生とコース間の多対多の関係をシミュレートします。
これらの例は、ニーズに合わせた合成データを生成するための基礎を築きます。より複雑な関係の作成、特定のデータベースのデータのカスタマイズ、パフォーマンス テスト用のデータセットのスケーリングなどのさらなる機能強化により、合成データの生成を次のレベルに引き上げることができます。
これらの例は、合成データを生成するための強固な基盤を提供します。ただし、次のようなさらなる機能強化を行って、複雑さと具体性を高めることができます。
- データベース固有のデータ: さまざまなデータベース システムに合わせてデータ生成をカスタマイズします (SQL と NoSQL など)。
- より複雑な関係: 一時的な関係、マルチレベル階層、一意の制約などの追加の相互依存関係を作成します。
- データのスケーリング: パフォーマンス テストまたはストレス テスト用に大規模なデータセットを生成し、システムが現実世界の条件を大規模に処理できるようにします。 ニーズに合わせた合成データを生成することで、機密データセットや取得が困難なデータセットに依存せずに、アプリケーションの開発、テスト、最適化のための現実的な条件をシミュレートできます。
-
 Javaのオブザーバーパターンを使用してカスタムイベントを実装する方法は?Javaでカスタムイベントを作成する カスタムイベントは、多くのプログラミングシナリオで不可欠であり、特定のトリガーに基づいてコンポーネントが相互に通信できるようにします。この記事は、以下に対処することを目的としています。オブザーバーパターンの概要を次に示します。 サンプル実装 次の...プログラミング 2025-07-02に投稿
Javaのオブザーバーパターンを使用してカスタムイベントを実装する方法は?Javaでカスタムイベントを作成する カスタムイベントは、多くのプログラミングシナリオで不可欠であり、特定のトリガーに基づいてコンポーネントが相互に通信できるようにします。この記事は、以下に対処することを目的としています。オブザーバーパターンの概要を次に示します。 サンプル実装 次の...プログラミング 2025-07-02に投稿 -
UTF8 MySQLテーブルでLATIN1文字をUTF8に正しく変換する方法latin1文字をUTF8テーブル内のutf8に変換する diaCriticsのキャラクターが遭遇した問題に遭遇しました( "Jáuòiñe")がUTF8テーブルで存在していないために、utf8テーブルが不足しているために存在していませんでした。 「mysql_se...プログラミング 2025-07-02に投稿
-
C ++の関数またはコンストラクターパラメーターとして排他的なポインターを渡す方法は?コンストラクターと機能のパラメーターとしてユニークなポインターを管理する ユニークなポインター( unique_ptr この方法は、関数/オブジェクトへの一意のポインターの所有権を転送します。ポインターの内容は関数に移動し、操作後に元のポインターが空になります。 :next(std ::...プログラミング 2025-07-02に投稿
-
PDOパラメーターを使用してクエリのように正しく使用する方法は?を使用してpdo PDOで同様のクエリを実装しようとすると、以下のクエリのような問題に遭遇する可能性があります: $query = "SELECT * FROM tbl WHERE address LIKE '%?%' OR address LIKE '%?%'";...プログラミング 2025-07-02に投稿
-
ネストされた機能とPythonの閉鎖の違いは何ですかネストされた関数とpython の閉鎖と閉鎖は、表面的に閉鎖に似ている一方で、キー差のために根本的に異なります: [非閉ざされた Pythonのネストされた関数は、以下の要件を満たしていないため閉鎖とは見なされません: は、それらは、エンクルの外側に実行される場合、 に実行...プログラミング 2025-07-02に投稿
-
交換指令を使用して、GO modのモジュールパスの不一致を解決する方法は?go mod のモジュールパスの不一致を克服するgo modを利用する場合、輸入パッケージと実際の輸入パスの間のパスミスマッチとのパスミスマッチで、第三者パッケージが別のパッケージをインポートする紛争に遭遇する可能性があります。エコーされたメッセージで示されているように、これはGo M...プログラミング 2025-07-02に投稿
-
GOコンパイラでコンパイルの最適化をカスタマイズするにはどうすればよいですか?goコンパイラ のコンピレーション最適化のカスタマイズGOのデフォルトのコンパイルプロセスは、特定の最適化戦略に従います。ただし、ユーザーは特定の要件に対してこれらの最適化を調整する必要がある場合があります。これは、コンパイラが事前に定義されたヒューリスティックに基づいて最適化を自動的に...プログラミング 2025-07-02に投稿
-
GO言語でエクスポートパッケージタイプを動的に発見する方法は?エクスポートされたパッケージタイプを動的に見つける 反射パッケージの限られたタイプの発見機能とは対照的に、この記事では、ランタイムですべてのパッケージタイプ(特に構造体)を発見するための代替方法を説明します。後で) in go 1.5および後続のバージョンでは、タイプとインポーターパッ...プログラミング 2025-07-02に投稿
-
PHP \の機能の再定義制限を克服する方法は?PHPの関数の再定義制限 をPHPで克服することは、同じ名前の関数を複数回定義することはノーではありません。提供されたコードスニペットで見られるように、そうすることは、恐ろしい「再び削除できない」エラーになります。 $ b){ $ a * $ b; } を返しますが、PHPツールベ...プログラミング 2025-07-02に投稿
-
ユーザーローカルタイムフォーマットとタイムゾーンオフセットディスプレイガイドをタイムオフセットでユーザーのロケール形式で表示する をエンドユーザーに提示する場合、ローカルタイムゾーンとフォーマットに表示することが重要です。これにより、さまざまな地理的位置にわたって明確でシームレスなユーザーエクスペリエンスが保証されます。 JavaScriptを使用してこれを達成す...プログラミング 2025-07-02に投稿
-
mysqlが絵文字を挿入するときに\\ "string値エラー\\"例外を解きます誤った文字列値例外を解決する絵文字を挿入するときに絵文字を含む文字列をMySQLデータベースに挿入しようとするときに、次の例外を遭遇する可能性があります: Java.SQL.SQL.SQL.SQL.SQL.SQL.SQL.SQL.SQL.SQL.SQL.SQL.SQL.SQL.SQL.SQL...プログラミング 2025-07-02に投稿
-
decimal.parse()を使用して指数表記で数値を解析する方法は?指数表記 からの数字を解析する場合、decimal.parse( "1.2345e-02")を使用して指数表記で表現された文字列を解析しようとすると、エラーが発生します。これは、デフォルトの解析方法が指数表記法を認識しないためです。次の例に示すように、numberSty...プログラミング 2025-07-02に投稿
-
なぜ有効なコードにもかかわらず、PHPで入力をキャプチャするリクエストを要求するのはなぜですか?アドレス指定Php action='' を使用して、フォームの提出後に$ _POSTアレイの内容を確認します。適切に: if(empty($ _ server ['content_type'])) { $ _Server ['content_typ...プログラミング 2025-07-02に投稿
-
Javaの「DD/MM/YYYY HH:MM:SS.SS」形式で現在の日付と時刻を正しく表示するにはどうすればよいですか?「dd/mm/yyyy hh:mm:ss.ss」形式で現在の日付と時刻を表示する方法。異なるフォーマットパターンを持つさまざまなSimpleDateFormatインスタンスの使用にあります。 java.text.simpledateformat; java.util.calendarをインポ...プログラミング 2025-07-02に投稿
-
PHPを使用してBlob(画像)をMySQLに適切に挿入する方法は?php mysqlデータベースを持つmysqlデータベースにブロブを挿入すると、mysqlデータベースに画像を保存しようとすると、遭遇するかもしれません問題。このガイドは、画像データを正常に保存するためのソリューションを提供します。 ImageId、image) values( &...プログラミング 2025-07-02に投稿















中国語を勉強する
- 1 「歩く」は中国語で何と言いますか? 走路 中国語の発音、走路 中国語学習
- 2 「飛行機に乗る」は中国語で何と言いますか? 坐飞机 中国語の発音、坐飞机 中国語学習
- 3 「電車に乗る」は中国語で何と言いますか? 坐火车 中国語の発音、坐火车 中国語学習
- 4 「バスに乗る」は中国語で何と言いますか? 坐车 中国語の発音、坐车 中国語学習
- 5 中国語でドライブは何と言うでしょう? 开车 中国語の発音、开车 中国語学習
- 6 水泳は中国語で何と言うでしょう? 游泳 中国語の発音、游泳 中国語学習
- 7 中国語で自転車に乗るってなんて言うの? 骑自行车 中国語の発音、骑自行车 中国語学習
- 8 中国語で挨拶はなんて言うの? 你好中国語の発音、你好中国語学習
- 9 中国語でありがとうってなんて言うの? 谢谢中国語の発音、谢谢中国語学習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









