
Python 行で Google Gemini を使用してトリッキーな PDF からデータを抽出する
 ブラウズ:840
ブラウズ:840
このガイドでは、Gemini Flash や GPT-4o などのビジョン言語モデル (VLM) を使用して PDF から構造化データを抽出する方法を説明します。
Google の視覚言語モデルの最新シリーズである Gemini は、テキストと画像の理解において最先端のパフォーマンスを示しました。この改善されたマルチモーダル機能と長いコンテキスト ウィンドウにより、図、チャート、表、ダイアグラムなど、従来の抽出モデルでは困難であった視覚的に複雑な PDF データの処理に特に役立ちます。
これにより、ビジュアル ファイルや Web 抽出用の独自のデータ抽出ツールを簡単に構築できます。方法は次のとおりです:
Gemini の長いコンテキスト ウィンドウとマルチモーダル機能により、従来の抽出モデルでは困難であった視覚的に複雑な PDF データの処理に特に役立ちます。
環境のセットアップ
抽出に入る前に、開発環境をセットアップしましょう。このガイドは、システムに Python がインストールされていることを前提としています。そうでない場合は、https://www.python.org/downloads/
からダウンロードしてインストールします。⚠️ Python を使用したくない場合は、thepi.pe のクラウド プラットフォームを使用して、コードを記述せずにファイルをアップロードし、結果を CSV としてダウンロードできることに注意してください。
必要なライブラリをインストールする
ターミナルまたはコマンド プロンプトを開き、次のコマンドを実行します:
pip install git https://github.com/emcf/thepipe pip install pandas
Python を初めて使用する人のために説明すると、pip は Python のパッケージ インストーラーであり、これらのコマンドは必要なライブラリをダウンロードしてインストールします。
API キーを設定する
パイプを使用するには、API キーが必要です。
免責事項: thepi.pe は無料のオープンソース ツールですが、API にはトークンあたり約 0.00002 ドルのコストがかかります。このようなコストを回避したい場合は、GitHub でローカル設定手順を確認してください。選択した LLM プロバイダーに引き続き料金を支払う必要があることに注意してください。
入手して設定する方法は次のとおりです:
- https://thepi.pe/platform/ にアクセスしてください
- アカウントを作成するかログインします
- 設定ページで API キーを見つけます

次に、これを環境変数として設定する必要があります。プロセスはオペレーティング システムによって異なります:
- pi.pe プラットフォームの設定メニューから API キーをコピーします
Windows の場合:
- スタート メニューで「環境変数」を検索
- 「システム環境変数の編集」をクリックします
- 「環境変数」ボタンをクリックします
- [ユーザー変数] で [新規] をクリックします
- 変数名をTHEPIPE_API_KEY、値をAPIキーとして設定します
- 「OK」をクリックして保存します
macOS および Linux の場合:
ターミナルを開き、シェル設定ファイル (例: ~/.bashrc または ~/.zshrc) に次の行を追加します:
export THEPIPE_API_KEY=your_api_key_here
次に、設定をリロードします:
source ~/.bashrc # or ~/.zshrc
抽出スキーマの定義
抽出を成功させる鍵は、抽出するデータの明確なスキーマを定義することです。数量明細書ドキュメントからデータを抽出するとします:

数量明細書ドキュメントのページの例。各ページのデータは他のページから独立しているため、抽出は「ページごと」に行われます。ページごとに抽出するデータが複数あるため、複数の抽出を True
に設定します。
列名を確認すると、次のようなスキーマを抽出できます:
schema = {
"item": "string",
"unit": "string",
"quantity": "int",
}
pi.pe プラットフォームでお好みに合わせてスキーマを変更できます。 [スキーマの表示] をクリックすると、Python API
で使用するためにコピーして貼り付けることができるスキーマが表示されます。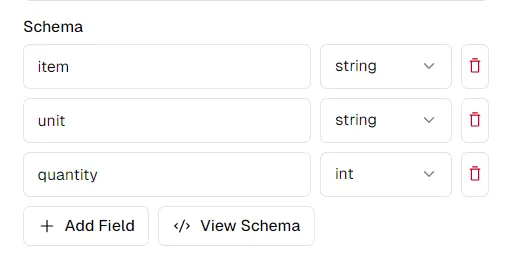
PDF からのデータの抽出
次に、extract_from_file を使用して PDF からデータを取得しましょう:
from thepipe.extract import extract_from_file results = extract_from_file( file_path = "bill_of_quantity.pdf", schema = schema, ai_model = "google/gemini-flash-1.5b", chunking_method = "chunk_by_page" )
ここでは、各ページを AI モデルに個別に送信したいため、chunking_method="chunk_by_page" としています (PDF は大きすぎて一度にすべてを送信できません)。 PDF ページにはそれぞれ複数行のデータが含まれるため、multiple_extractions=True も設定します。 PDF のページは次のようになります:
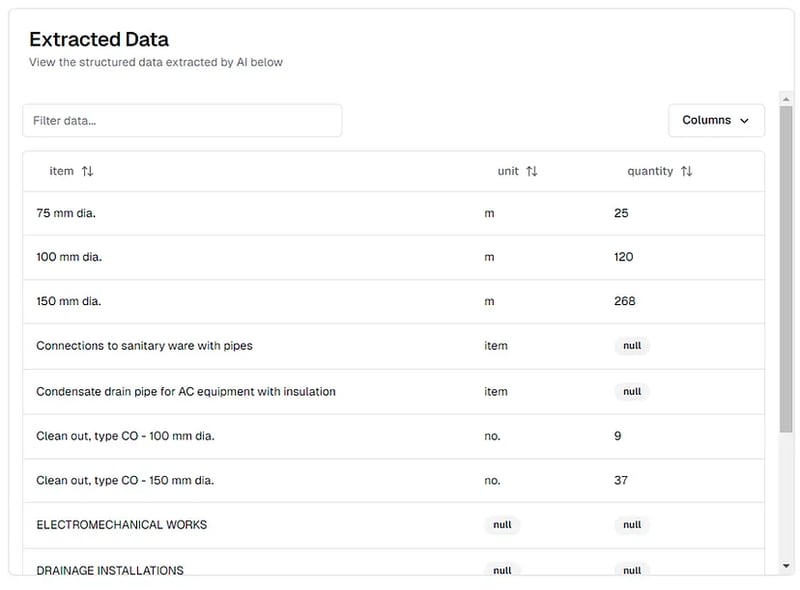
pi.pe プラットフォームで表示された数量明細書 PDF の抽出結果
結果の処理
抽出結果は辞書のリストとして返されます。これらの結果を処理して pandas DataFrame:
を作成できます。
import pandas as pd df = pd.DataFrame(results) # Display the first few rows of the DataFrame print(df.head())
これにより、テキスト コンテンツや図や表などの視覚要素の説明など、抽出されたすべての情報を含む DataFrame が作成されます。
さまざまな形式へのエクスポート
データを DataFrame に保存したので、それをさまざまな形式に簡単にエクスポートできます。以下にいくつかのオプションがあります:
Excel へのエクスポート
df.to_excel("extracted_research_data.xlsx", index=False, sheet_name="Research Data")
これにより、「Research Data」という名前のシートを含む「extracted_research_data.xlsx」という名前の Excel ファイルが作成されます。 Index=False パラメーターにより、DataFrame インデックスが別の列として含まれることがなくなります。
CSVにエクスポートする
より単純な形式を希望する場合は、CSV にエクスポートできます:
df.to_csv("extracted_research_data.csv", index=False)
これにより、Excel または任意のテキスト エディタで開くことができる CSV ファイルが作成されます。
エンディングノート
抽出を成功させる鍵は、明確なスキーマを定義し、AI モデルのマルチモーダル機能を活用することにあります。これらの手法に慣れてくると、カスタム チャンク方法、カスタム抽出プロンプト、抽出プロセスを大規模なデータ パイプラインに統合するなど、より高度な機能を探索できるようになります。
-
 PHPを使用してXMLファイルから属性値を効率的に取得するにはどうすればよいですか?XMLファイルから属性値をPHP の取得します。提供されている例のような属性を含むXMLファイルを使用する場合: $xml = simplexml_load_file($file); foreach ($xml->Var[0]->attributes() as $att...プログラミング 2025-04-03に投稿されました
PHPを使用してXMLファイルから属性値を効率的に取得するにはどうすればよいですか?XMLファイルから属性値をPHP の取得します。提供されている例のような属性を含むXMLファイルを使用する場合: $xml = simplexml_load_file($file); foreach ($xml->Var[0]->attributes() as $att...プログラミング 2025-04-03に投稿されました -
Java文字列に複数のサブストリングを効率的に交換するにはどうすればよいですか?java で複数のサブストリングを弦の複数のサブストリングを置き換えると、文字列内の複数のサブストリングを置き換える必要性に直面すると、弦楽列の方法を繰り返し担当するブルートのアプローチに頼ることに魅力的です。ただし、これは大きな文字列や多数の文字列を使用する場合は非効率的です。正規表...プログラミング 2025-04-03に投稿されました
-
Node-MYSQLを使用して単一のクエリで複数のSQLステートメントを実行するにはどうすればよいですか?node-mysql in node.jsでのマルチステートメントクエリサポート、ノード-Mysqlパッケージを使用してnode-mysqlを使用してnode-mysqlを使用して、1つのクエリを使用してnode-mysqlの記録を使用して、1つのクエリで複数のsqlステートメントを...プログラミング 2025-04-03に投稿されました
-
PHPのUnicode文字列からURLに優しいナメクジを効率的に生成するにはどうすればよいですか?効率的なナメクジ生成のための関数を作成する スラッグの作成、URLで使用されるユニコード文字列の単純化された表現は挑戦的な作業になります。この記事では、スラッグを効率的に生成し、特殊文字と非ASCII文字をURLに優しい形式に変換するための簡潔なソリューションを紹介します。一連の操作を使用...プログラミング 2025-04-03に投稿されました
-
なぜPHPのDateTime :: Modify( '+1 Month')が予期しない結果を生み出すのですか?PHP DateTimeで月数の変更:PHPのDateTimeクラスを操作する場合、数か月を追加または減算する場合、意図した動作を発見します。ドキュメントが警告しているように、これらの操作は見た目ほど直感的ではないため、これらの操作に「注意してください」。 $ date-> modify(...プログラミング 2025-04-03に投稿されました
-
なぜ私の線形勾配の背景にストライプがあるのか、どうすればそれらを修正できますか?リニアグラデーションからの背景ストライプを追放する 背景に線形勾配プロパティを使用する場合、方向が上または下に設定されているときに顕著なストライプに遭遇する場合があります。これらの見苦しいアーティファクトは、複雑なバックグラウンド伝播現象に起因する可能性があります。その後、線形勾配はこの高...プログラミング 2025-04-03に投稿されました
-
マウスクリック時にDiv内のすべてのテキストをプログラム的に選択するにはどうすればよいですか?マウスクリックでプログラムをプログラム的に選択する 質問 テキストコンテンツのdiv要素が与えられた場合、ユーザーは1つのマウスクリックでdiv内のテキスト全体をプログラム的に選択できますか?これにより、ユーザーは選択したテキストを簡単にドラッグアンドドロップしたり、直接コピーしたりできます。...プログラミング 2025-04-03に投稿されました
-
なぜ有効なコードにもかかわらず、PHPで入力をキャプチャするリクエストを要求するのはなぜですか?アドレス指定Php action='' を使用して、フォームの提出後に$ _POSTアレイの内容を確認します。適切に: if(empty($ _ server ['content_type'])) { $ _Server ['content_typ...プログラミング 2025-04-03に投稿されました
-
コンテナ内のdiv用のスムーズな左右のCSSアニメーションを作成する方法は?左右の動きのための一般的なCSSアニメーション この記事では、一般的なCSSアニメーションを作成して、その容器の端に到達する左右に移動することを探ります。このアニメーションは、その未知の長さに関係なく、絶対的なポジショニングで任意のdivに適用できます。これは、100%で、divの左のプロ...プログラミング 2025-04-03に投稿されました
-
Regexを使用してPHPで括弧内で効率的にテキストを抽出する方法php:括弧内の括弧内のテキストの抽出 括弧内に囲まれたテキストの抽出を扱うとき、最も効率的なソリューションを見つけることが不可欠です。 1つのアプローチは、以下に示すように、PHPの文字列操作関数を利用することです。 $ fullstring); $ sportstring = s...プログラミング 2025-04-03に投稿されました
-
GOでSQLクエリを構築するときに、テキストと値を安全に連結するにはどうすればよいですか?go sql queries のテキストと値を連結するgoのテキストsqlクエリを構築する際に、特に文字列を使用した場合、文字列を使用した場合に、文字列を使用する場合、アプローチはGOでは有効ではなく、文字列としてパラメーターをキャストしようとすると、タイプのミスマッチエラーが発生しま...プログラミング 2025-04-03に投稿されました
-
多次元アレイのためにPHPでのJSONの解析を簡素化する方法は?jsonをphp でphpで解析しようとする場合、特に多次元配列を扱う場合は困難な場合があります。プロセスを簡素化するには、JSONをオブジェクトではなく配列として解析することをお勧めします。 print_r($ json)を使用して配列構造を探索することは、目的の情報へのアクセス方法を決...プログラミング 2025-04-03に投稿されました
-
GOコンパイラでコンパイルの最適化をカスタマイズするにはどうすればよいですか?goコンパイラ のコンピレーション最適化のカスタマイズGOのデフォルトのコンパイルプロセスは、特定の最適化戦略に従います。ただし、ユーザーは特定の要件に対してこれらの最適化を調整する必要がある場合があります。これは、コンパイラが事前に定義されたヒューリスティックに基づいて最適化を自動的に...プログラミング 2025-04-03に投稿されました
-
\ "while(1)vs。for(;;):コンパイラの最適化はパフォーマンスの違いを排除しますか?\"while(1)vs。for(;;):速度の違いはありますか? loops? 回答: では、ほとんどの最新のコンパイラでは、(1)と(;;)。コンパイラー: perl: の両方が(1)と(;;)が同じオプコードをもたらします。 1 入力 - > 2を入力します 2 NextSt...プログラミング 2025-04-03に投稿されました
-
Firefoxバックボタンを使用すると、JavaScriptの実行が停止するのはなぜですか?navigational Historyの問題:JavaScriptは、Firefoxバックボタンを使用した後に実行を停止します ユーザーは、JavaScriptスクリプトが以前の訪問ページを介して回復したときに実行されない問題に遭遇する可能性があります。この問題は、ChromeやInt...プログラミング 2025-04-03に投稿されました















中国語を勉強する
- 1 「歩く」は中国語で何と言いますか? 走路 中国語の発音、走路 中国語学習
- 2 「飛行機に乗る」は中国語で何と言いますか? 坐飞机 中国語の発音、坐飞机 中国語学習
- 3 「電車に乗る」は中国語で何と言いますか? 坐火车 中国語の発音、坐火车 中国語学習
- 4 「バスに乗る」は中国語で何と言いますか? 坐车 中国語の発音、坐车 中国語学習
- 5 中国語でドライブは何と言うでしょう? 开车 中国語の発音、开车 中国語学習
- 6 水泳は中国語で何と言うでしょう? 游泳 中国語の発音、游泳 中国語学習
- 7 中国語で自転車に乗るってなんて言うの? 骑自行车 中国語の発音、骑自行车 中国語学習
- 8 中国語で挨拶はなんて言うの? 你好中国語の発音、你好中国語学習
- 9 中国語でありがとうってなんて言うの? 谢谢中国語の発音、谢谢中国語学習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









