
ETL: テキストから人名を抽出する
 ブラウズ:297
ブラウズ:297
chicagomusiccompass.com.
をスクレイピングするとします。ご覧のとおり、複数のカードがあり、それぞれがイベントを表しています。では、次の項目をチェックしてみましょう:
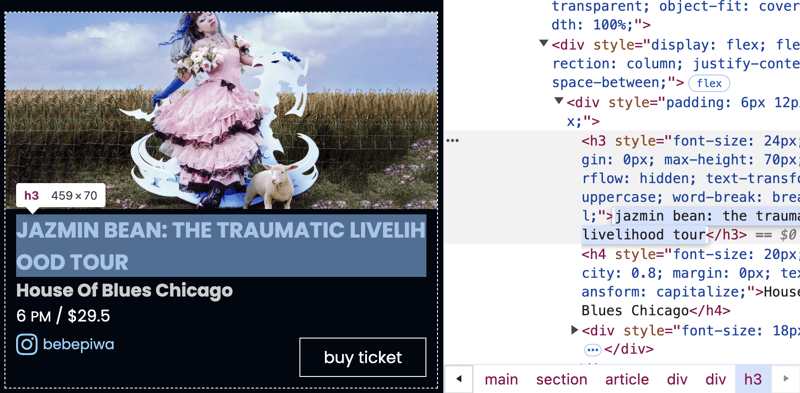
イベントの名前は次のとおりです:
jazmin bean: the traumatic livelihood tour
それでは次の質問です: テキストからアーティストの名前を抽出するにはどうすればよいですか?
人間として、jazmin Bean がアーティストであることは「簡単に」わかります。彼らの wiki ページをチェックしてみてください。ただし、その名前を抽出するコードを記述するのは難しい場合があります。
「: より前の部分はアーティスト名でなければなりません」と考えることもできます。これは賢明だと思われますよね?この場合はうまくいきますが、次の場合はどうでしょうか:
happy hour on the patio: kathryn & chris
ここで順序が逆転します。さまざまなケースを処理するロジックを追加し続けることもできますが、すぐに、脆弱でおそらくすべてをカバーできない大量のルールが作成されることになります。
そこで、固有表現認識 (NER) モデルが役立ちます。これらはオープンソースであり、テキストから名前を抽出するのに役立ちます。すべてのケースを検出できるわけではありませんが、ほとんどの場合、必要な情報が得られます。
このアプローチを使用すると、抽出がはるかに簡単になります。 Python の機械学習に関するコミュニティは無敵であるため、私は Python を使用します。
from gliner import GLiNER
model = GLiNER.from_pretrained("urchade/gliner_base")
text = "jazmin bean: the traumatic livelihood tour"
labels = ["person", "bands", "projects"]
entities = model.predict_entities(text, labels)
for entity in entities:
print(entity["text"], "=>", entity["label"])
出力を生成します:
jazmin bean => person
それでは、他のケースを見てみましょう:
happy hour on the patio: kathryn & chris
出力:
kathryn => person chris => person
ソース-GLiNER
すごいですよね?名前を抽出するための面倒なロジックはもう必要ありません。モデルを使用するだけです。もちろん、考えられるすべてのケースをカバーしているわけではありませんが、私のプロジェクトでは、このレベルの柔軟性が問題なく機能します。より正確な精度が必要な場合は、いつでも次のことができます:
- 別のモデルを試してください
- 既存のモデルに貢献
- プロジェクトをフォークし、ニーズに合わせて微調整します
結論
ソフトウェア開発者として、機械学習分野のツールを常に最新の状態に保つことを強くお勧めします。単純なプログラミングとロジックだけですべてを解決できるわけではありません。一部の課題には、モデルと統計を使用する方がうまく対処できます。
-
 \ "while(1)vs。for(;;):コンパイラの最適化はパフォーマンスの違いを排除しますか?\"while(1)vs。for(;;):速度の違いはありますか? loops? 回答: では、ほとんどの最新のコンパイラでは、(1)と(;;)。コンパイラー: perl: の両方が(1)と(;;)が同じオプコードをもたらします。 1 入力 - > 2を入力します 2 NextSt...プログラミング 2025-07-04に投稿
\ "while(1)vs。for(;;):コンパイラの最適化はパフォーマンスの違いを排除しますか?\"while(1)vs。for(;;):速度の違いはありますか? loops? 回答: では、ほとんどの最新のコンパイラでは、(1)と(;;)。コンパイラー: perl: の両方が(1)と(;;)が同じオプコードをもたらします。 1 入力 - > 2を入力します 2 NextSt...プログラミング 2025-07-04に投稿 -
decimal.parse()を使用して指数表記で数値を解析する方法は?指数表記 からの数字を解析する場合、decimal.parse( "1.2345e-02")を使用して指数表記で表現された文字列を解析しようとすると、エラーが発生します。これは、デフォルトの解析方法が指数表記法を認識しないためです。次の例に示すように、numberSty...プログラミング 2025-07-04に投稿
-
ポイントインポリゴン検出により効率的な方法:Ray TracingまたはMatplotlib \ 's path.contains_points?Pythonの効率的なポイントインポリゴン検出 ポリゴン内にあるかどうかを決定することは、計算ジオメトリの頻繁なタスクです。このタスクの効率的な方法を見つけることは、多数のポイントを評価する場合に有利です。ここでは、一般的に使用される2つの方法を調査して比較します:Ray TracingとM...プログラミング 2025-07-04に投稿
-
なぜPHPのDateTime :: Modify( '+1 Month')が予期しない結果を生み出すのですか?PHP DateTimeで月数の変更:PHPのDateTimeクラスを操作する場合、数か月を追加または減算する場合、意図した動作を発見します。ドキュメントが警告しているように、これらの操作は見た目ほど直感的ではないため、これらの操作に「注意してください」。 $ date-> modify(...プログラミング 2025-07-04に投稿
-
底の右側に浮かぶ写真のヒントとテキストの周りを包むは、Webデザインで を包み回して画像を右下に浮かびます。ページの右下隅に画像をフロートさせ、テキストを巻き付けることが望ましい場合があります。これにより、画像を効果的に紹介しながら魅力的な視覚効果が生じる可能性があります。このコンテナ内で、画像のテキストコンテンツとIMG要素を追加しま...プログラミング 2025-07-04に投稿
-
純粋なCSSでは、複数の粘着性要素を互いに積み重ねることができますか?純粋なCSSで複数の粘着性要素を互いに積み重ねることは可能ですか?ここ: https://webthemez.com/demo/sticky-multi-header-scroll/index.html JavaScriptの実装ではなく、純粋なCSSを使用することのみです。複数の粘...プログラミング 2025-07-04に投稿
-
右のテーブルの句でフィルタリングするとき、なぜ左結合が接続内に見えるのですか?left join conundrum:witching時間:データベースウィザードの領域で内側の結合 に変わる時間は、左結合を使用して複雑なデータ検索を実行することは一般的な慣行です。ただし、時々、左の結合が予想通りに動作しないことがあります。 A.foo、 B.BAR、 C.Foobar...プログラミング 2025-07-04に投稿
-
PHPで空の配列を効率的に検出する方法は?チェックアレイ空虚のphp の空の配列は、さまざまなアプローチを通じてPHPで決定できます。アレイ要素の存在を確認する必要がある場合、PHPのルーズタイピングにより、配列自体の直接評価が可能になります。 //リストは空です。 } if (!$playerlist) { ...プログラミング 2025-07-04に投稿
-
PHPのファイルシステム機能でUTF-8ファイル名を処理するにはどうすればよいですか?PHPのファイルシステム関数のUTF-8ファイル名の処理 PHPのMKDIR関数を使用してUTF-8文字を含むフォルダーを作成する場合、 が掲載しているWindows explorerの発生する問題を発生させる可能性があります。 urlエンコードファイル名 この問題を解決するには、...プログラミング 2025-07-04に投稿
-
Codeigniterがmysqliに切り替えた後にmysqlデータベースに接続する理由MySQLデータベースに接続できません:エラーメッセージのトラブルシューティング は、MySQLドライバーからMySQLIドライバーのコードジニターのMySQLIドライバーに切り替えようとする場合、ユーザーは、設定を使用してデータベースサーバーを接続できます。このエラーは、誤ったPHP構...プログラミング 2025-07-04に投稿
-
なぜ私のCSSの背景画像が現れるのですか?トラブルシューティング:css背景画像が表示されない チュートリアルの指示にもかかわらず、背景画像が読み込まれない問題に遭遇しました。画像とスタイルのシートは同じディレクトリに存在していますが、背景は空白の白いキャンバスのままです。画像ファイル名を囲む引用: background-ima...プログラミング 2025-07-04に投稿
-
JavaScriptオブジェクトのキーをアルファベット順に並べ替える方法は?javascriptオブジェクトをキー で並べ替える方法JavaScriptオブジェクトがある場合は、読みやすさまたは処理目的の改善のためにそのプロパティをアルファベット順に再編成することができます。これは、次の手順を利用することで実現できます。 const unordered = { ...プログラミング 2025-07-04に投稿
-
CSSは、属性値に基づいてHTML要素を見つけることができますか?をCSS の属性値でHTML要素をターゲットとするCSSのターゲティング、以下の例に示すように、特定の属性に基づいてターゲット要素をターゲットにすることが可能です: [型]入力[型]入力[タイプ] { フォントファミリー:コンソラ。 } input[type=text] { ...プログラミング 2025-07-04に投稿
-
コンパイラエラー「USR/BIN/LD:-L」ソリューションが見つかりませんエラーが発生したエラー: "usr/bin/ld:l " はプログラムをコンパイルしようとすると、次のエラーメッセージに遭遇する可能性があります: -l usr/bin/ld: cannot find -l<nameOfTheLibrary> ld ...プログラミング 2025-07-04に投稿















中国語を勉強する
- 1 「歩く」は中国語で何と言いますか? 走路 中国語の発音、走路 中国語学習
- 2 「飛行機に乗る」は中国語で何と言いますか? 坐飞机 中国語の発音、坐飞机 中国語学習
- 3 「電車に乗る」は中国語で何と言いますか? 坐火车 中国語の発音、坐火车 中国語学習
- 4 「バスに乗る」は中国語で何と言いますか? 坐车 中国語の発音、坐车 中国語学習
- 5 中国語でドライブは何と言うでしょう? 开车 中国語の発音、开车 中国語学習
- 6 水泳は中国語で何と言うでしょう? 游泳 中国語の発音、游泳 中国語学習
- 7 中国語で自転車に乗るってなんて言うの? 骑自行车 中国語の発音、骑自行车 中国語学習
- 8 中国語で挨拶はなんて言うの? 你好中国語の発音、你好中国語学習
- 9 中国語でありがとうってなんて言うの? 谢谢中国語の発音、谢谢中国語学習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









