 表紙 > プログラミング > AWS SDK for Java を使用した Amazon Aurora サーバーレスのデータ API - パート Aurora サーバーレス vata API は DevOps Guru に適合しますか?
表紙 > プログラミング > AWS SDK for Java を使用した Amazon Aurora サーバーレスのデータ API - パート Aurora サーバーレス vata API は DevOps Guru に適合しますか?
AWS SDK for Java を使用した Amazon Aurora サーバーレスのデータ API - パート Aurora サーバーレス vata API は DevOps Guru に適合しますか?
 ブラウズ:410
ブラウズ:410
導入
私の記事「サーバーレスアプリケーション用の Amazon DevOps Guru - パート 10 Aurora Serverless v2 の異常検出」では、DevOps Guru が Java 21 で管理された Lambda 関数の場合に Aurora (Serverless v2) PostgreSQL データベースの異常を正常に検出できたことを学びました。ランタイムは JDBC 経由で接続されました。データベースを 0.5 から 1 ACU までしかスケールしませんでしたが、ID によって製品を取得する Lambda 関数を数分間にわたって同時に数百回呼び出すことで、データベースに非常に高い負荷が生じました。 DevOps Guru がデータベース接続の合計の増加と常に高いデータベース (CPU) 負荷を正しく指摘していることがわかりました。 この記事では、JDBC の代わりに AWS SDK for Java と Aurora Serverless v2 の Data API を使用して同じ実験を行い、DevOps Guru が異常を検出するかどうかを判断したいと思います。
Data API を使用した Aurora Serverless v2 での異常検出
サンプル アプリケーションを調べて、SAM テンプレートを使用してインフラストラクチャを作成し、次の図で説明されているアプリケーションをデプロイしてみましょう。
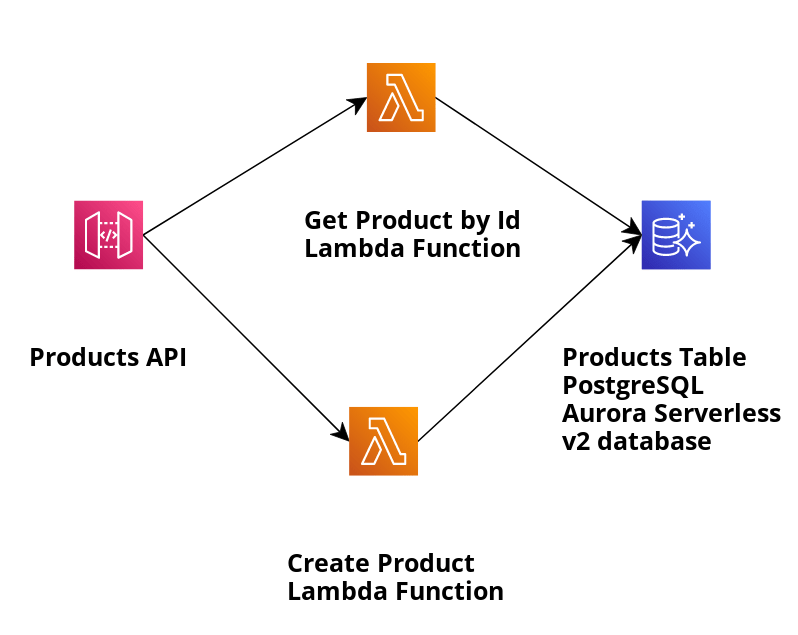
アプリケーションは、Aurora Serverless v2 PostgreSQL データベースに保存された製品を作成し、Data API を使用して ID によって製品を取得します。 ID で製品を取得するために使用する関連する Lambda 関数は GetProductByIdViaAuroraServerlessV2DataApi で、そのハンドラー実装は GetProductByIdViaAuroraServerlessV2DataApiHandler.
です。前の記事と同様に、Hey ツールを使用して次のようにストレス テストを実行します
hey -z 15m -c 300 -H "X-API-Key: XXXa6XXXX" https://XXX.execute-api.eu-central-1.amazonaws.com/prod/productsWithDataApi/1
この例では、300 個の同時コンテナーを使用して API Gateway エンドポイントを 15 分間呼び出します。 prod/productsWithoutDataApi エンドポイントの背後で、Lambda 関数 GetProductByIdViaAuroraServerlessV2WithoutDataApi が呼び出され、Aurora Serverless v2 PostgreSQL データベースから ID 1 で製品を取得します。
[SAM テンプレート]((https://github.com/Vadym79/AWSLambdaJavaAuroraServerlessV2DataApi/blob/master/template.yaml) Aurora データベース クラスターを構成して、最小容量 0.5 から最大容量 1 ACU (つまり、データベース サイズが非常に小さい)コスト削減を目的として負荷が増加した場合に備えて。
AuroraServerlessV2Cluster:
Type: 'AWS::RDS::DBCluster'
...
ServerlessV2ScalingConfiguration:
MinCapacity: 0.5
MaxCapacity: 1
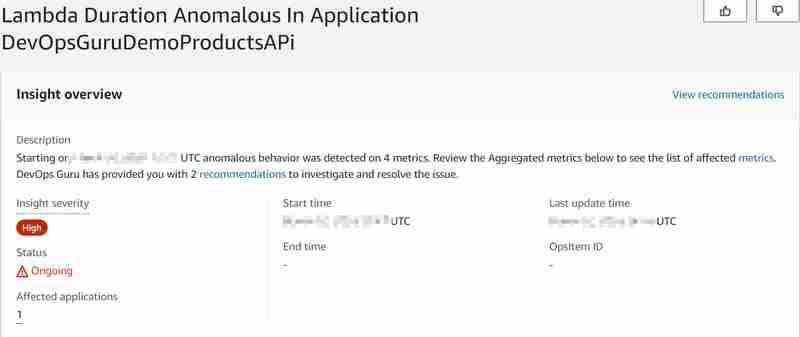
Aurora (サーバーレス v2) データベースは、データベース サイズ (この場合は ACU 設定) に比例して、使用可能なデータベース接続の最大数を管理します。また、Aurora サーバーレス v2 のデータ API (これは、今後の v1 との大きな違いです) 1 秒あたり 1000 のデータベース接続というハード クォータがあった場合、サポートは 2024 年末に終了します)。詳細については、Aurora Serverless v2 の最大接続数に関するドキュメントを参照してください。そのため、呼び出し数が増加すると、すぐに利用可能なデータベース接続の最大数に達し、データベース (CPU) の負荷が高くなることが予想されます。そのため、データベースは、製品を取得するための新しい Lambda 関数リクエストに応答できなくなります。 id (Lambda も実行されます)。 これにより異常を引き起こし、DevOps Guru がそれを検出できるかどうかを判断したいと考えています。そして、それは可能でした。次のような洞察が生成されました:
そして、以下の集計された異常な指標が特定されました:
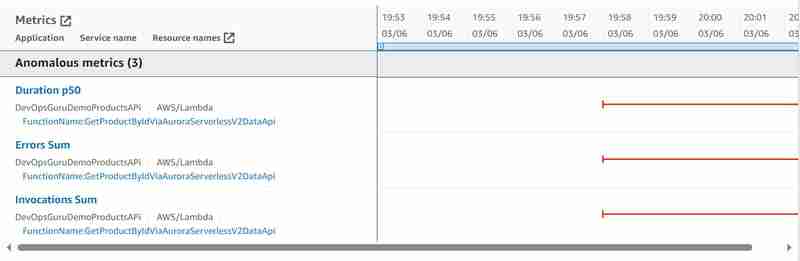
私の記事「サーバーレスアプリケーションの Amazon DevOps Guru - パート 10 Aurora Serverless v2 での異常検出」で説明した、Data API の代わりに JDBC を使用した場合に特定された集約された異常メトリクスと比較すると、Aurora データベースの異常メトリクス: データベース接続が完全にわかりません。合計とデータベース (CPU) の負荷はありますが、データベースとして 15 秒のうち定義された時間に達した Lambda のエラーが正しく表示されます。応答できませんでした。
 .
.
それで、違いは何ですか? JDBC(非データ API) とデータ API を使用して Aurora Serverless v2 PostgreSQL クラスターで再現した両方のインシデントを調べてみましょう:
ACU の使用率/スケーリングの観点からは、どちらも同じように見えます:
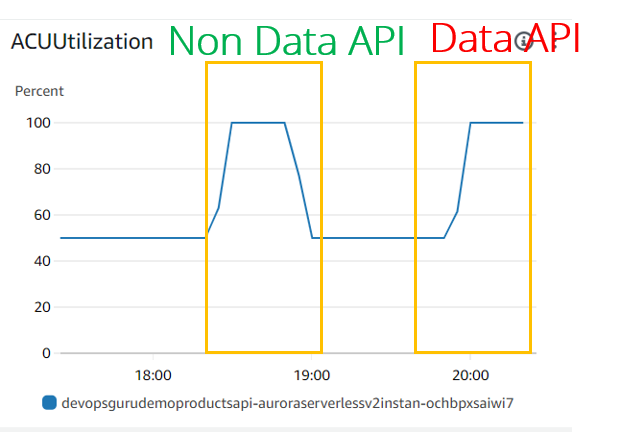
CPU 使用率、DatabaseConnection DBLoad(CPU) などの他のデータベース メトリックに関しては、大きな違いがあります:
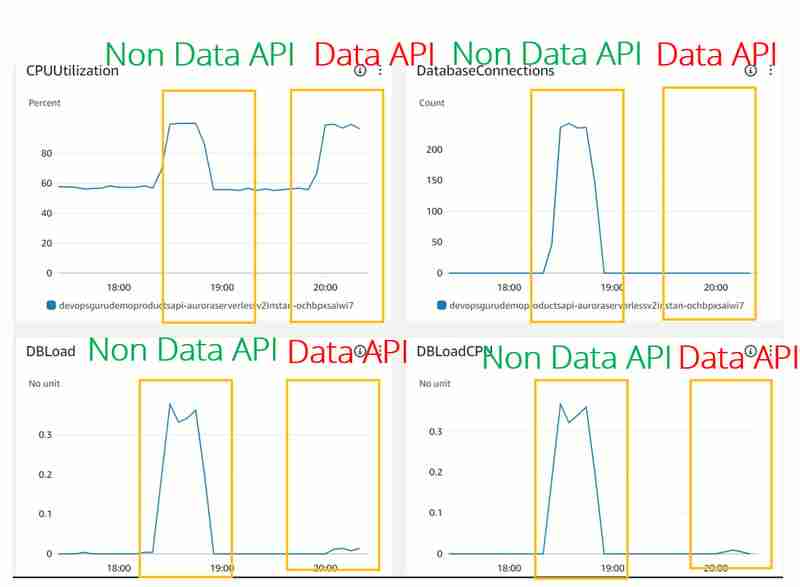
- CPU 使用率は、JDBC (非データ API) とデータ API の場合で同じように見えます。しかし、DevOps Guru はこのメトリクスを考慮していないようです。JDBC の実験でも見られなかったためです
- DBLoad(CPU) は、データ API の使用率が非常に低いです。 Dat API の場合、Aurora Serverless v2 データベースの前にロード バランサーがあり、接続の使用状況を監視し、データベースを過負荷から保護しているようです。
- Data API の使用状況については、DatabaseConnection メトリックが表示されません (または 0 として表示されます)。その理由は、Data API のデータベース接続を管理するのではなく、反対側で行われるためです。もちろん、それらは依然として「Aurora Serverless v2 の最大接続数」で学んだ重要な役割を果たしていますが、このメトリクスは CloudWatch メトリクスで外部に公開されているようで、DevOps Guru ですら実際の数値にはアクセスできません。
そのため、DBLoad(CPU) が非常に低いため、JDBC ユースケースと比較して、データ API を使用する Aurora Serverless v2 クラスターに関する DevOps Guru の洞察は生成されません。
Aurora Serverless v2 クラスターに直接接続して 2 番目の実験を行い、標準的な方法 (非データ API) を使用して ID によって製品を複数百回フェッチするスクリプトを作成して負荷テストを作成するスクリプトを作成しました。 hey ツールで行ったのと似ていますが、Api Gateway を呼び出す代わりにデータベースに直接アクセスします。データベースに負荷をかけた後、上で説明したように hey ツールを使用して同じ実験を開始し、何が起こるかを確認したいと思いました。同じ洞察が生成されましたが、今回は次のような異常なメトリクスが使用されました:
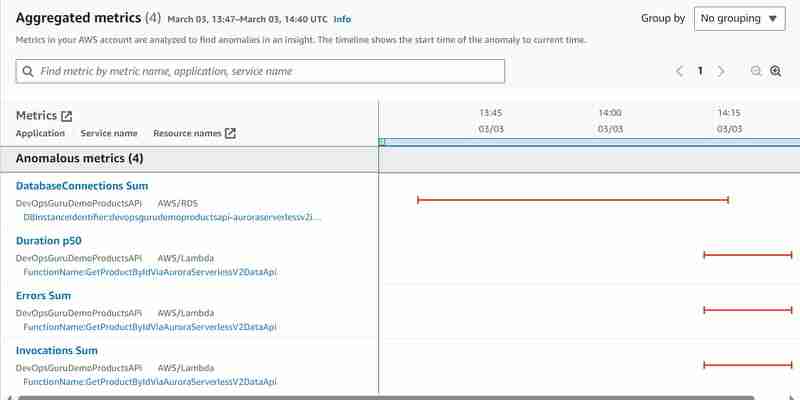
これで、少なくとも追加の Aurora Serverless v2 データベース接続合計の異常なメトリクスが確認されましたが、DBLoad(CPU) メトリクスはまだ見つかりません。
グラフ化された異常は次のようになります:
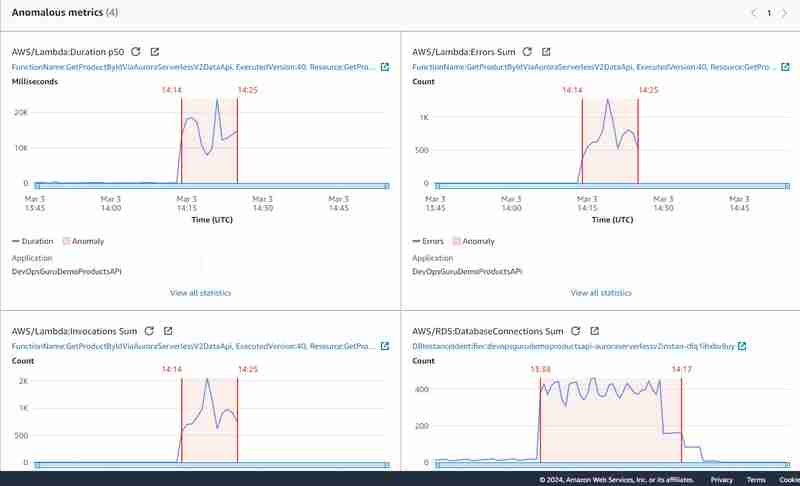
もちろん、実験はきれいではありませんでした。2 つの負荷テストを交互に、部分的に並行して実行しました。1 つ目は API Gateway を使用せずにデータベースに直接接続し、2 つ目は Data API を使用しました。これにより、データベース接続合計メトリクスは、Aurora Serverless v2 (および RDS 一般) の DevOps Guru 洞察を生成するための非常に重要な基準であり、Data API を使用する場合には一般に公開されないという最初の仮定が裏付けられました。
私はすでに Devops Guru チームに連絡し、サービスが改善されることを期待して自分の洞察を共有しました。または、まず、Data API で Aurora Serverless v2 を使用するために、データベース接続を CloudWatch メトリクスとして公開する問題が修正されます。
結論
この記事では、Data API 経由で Java 21 マネージド ランタイムが接続されている Lambda 関数の場合、DevOps Guru が Aurora (サーバーレス v2) PostgreSQL データベースの異常を正常に検出できるものの、Lambda 関数に関連する異常なメトリクスしか表示できないことを学びました。データベースが応答しなかったためタイムアウトしました。その主な理由は、Data API で Aurora Serverless v2 を使用する場合、CloudWatch メトリクスとしてのデータベース接続が公開されない (または常に 0 として表示される) ことだと思われます。 Aurora Serverless v2 データベース メトリクス (データベース接続の合計) は、2 回目の人工実験中にのみ表示されました。
-
 Java文字列に複数のサブストリングを効率的に交換するにはどうすればよいですか?java で複数のサブストリングを弦の複数のサブストリングを置き換えると、文字列内の複数のサブストリングを置き換える必要性に直面すると、弦楽列の方法を繰り返し担当するブルートのアプローチに頼ることに魅力的です。ただし、これは大きな文字列や多数の文字列を使用する場合は非効率的です。正規表...プログラミング 2025-07-12に投稿されました
Java文字列に複数のサブストリングを効率的に交換するにはどうすればよいですか?java で複数のサブストリングを弦の複数のサブストリングを置き換えると、文字列内の複数のサブストリングを置き換える必要性に直面すると、弦楽列の方法を繰り返し担当するブルートのアプローチに頼ることに魅力的です。ただし、これは大きな文字列や多数の文字列を使用する場合は非効率的です。正規表...プログラミング 2025-07-12に投稿されました -
CSSを使用してChromeとFirefoxのコンソール出力を着色できますか?javaScriptコンソールの色の表示 は、クロムのコンソールを使用してエラー用の赤、警告用のオレンジ、コンソール用グリーンなどの色のテキストを表示することは可能です。メッセージ? 回答 はい、CSSを使用して、ChromeとFirefox(バージョン31以降)のコンソールに表示さ...プログラミング 2025-07-12に投稿されました
-
匿名のJavaScriptイベントハンドラーをきれいに削除する方法は?匿名イベントリスナーを削除する]イベントリスナーを追加する要素を追加すると、柔軟性とシンプルさを提供しますが、要素自体を置き換えることなく挑戦をもたらすことができます。 element? element.addeventlistener(event、function(){/はここで動作し...プログラミング 2025-07-12に投稿されました
-
Linuxサーバーにarchive_zipをインストールした後、\ "class \ 'ziparchive \'が見つかりません\"エラーを取得するのはなぜですか?class 'ziparchive' linuxサーバーにarchive_zipをインストールする際のエラーは見つかりません 症状: を実行しようとするときに、Ziparkive follingive folling_zip 0.1.1.1.1.1.1.1.1.1.1.1...プログラミング 2025-07-12に投稿されました
-
Javaの「DD/MM/YYYY HH:MM:SS.SS」形式で現在の日付と時刻を正しく表示するにはどうすればよいですか?「dd/mm/yyyy hh:mm:ss.ss」形式で現在の日付と時刻を表示する方法。異なるフォーマットパターンを持つさまざまなSimpleDateFormatインスタンスの使用にあります。 java.text.simpledateformat; java.util.calendarをインポ...プログラミング 2025-07-12に投稿されました
-
Laravel Bladeテンプレートの変数をエレガントに定義するにはどうすればよいですか?Laravel Bladeテンプレートの変数を優雅さで定義する ブレードテンプレートに変数を割り当てる方法を理解することは、後で使用するためにデータを保存するために重要です。 「{{{{}}}」を使用して変数を割り当てるのは簡単ですが、常に最もエレガントなソリューションであるとは限りませ...プログラミング 2025-07-12に投稿されました
-
フォームリフレッシュ後に重複した提出を防ぐ方法は?を更新することで重複した提出を防ぐ Web開発で、フォームの提出後にページが更新された場合に重複した提出の問題に遭遇することが一般的です。これに対処するには、次のアプローチを検討してください。 if(isset($ _ post ['name'])){ ...プログラミング 2025-07-12に投稿されました
-
HTMLがページ番号やソリューションを印刷できない理由はhtmlページにページ番号を印刷できません。使用: @page { マージン:10%; @トップセンター{ フォントファミリー:sans-serif; font-weight:bold; font-size:2em; コンテンツ:カウンター(ページ)...プログラミング 2025-07-12に投稿されました
-
C ++ 20 consteval関数のテンプレートパラメーターは関数パラメーターに依存できますか?consteval関数とテンプレートパラメーターは関数引数 では、テンプレートパラメーターは関数引数に依存することはできません。 c 20 consteval関数 c 20 consteval関数を導入します。コンパイル時間で評価する必要があります。ただし、問題は残ります。これ...プログラミング 2025-07-12に投稿されました
-
セル編集後にカスタムJTableセルレンダリングを維持するにはどうすればよいですか?セル編集後のjtableセルレンダリングの維持 は、カスタムセルのレンダリングと編集機能を実装することでユーザーエクスペリエンスを向上させることができます。ただし、操作を編集した後でも目的のフォーマットが保存されることを保証することが重要です。このようなシナリオでは、編集がコミットされた後...プログラミング 2025-07-12に投稿されました
-
eval()vs。ast.literal_eval():ユーザー入力の方が安全なPython関数はどれですか?の重量eval()およびast.literal_eval()in python security をユーザー入力を処理する場合、セキュリティに優先順位を付けることが不可欠です。強力なPython関数であるeval()は、潜在的な解決策として発生することがよくありますが、懸念は潜在的なリス...プログラミング 2025-07-12に投稿されました
-
名前空間コロンを使用したPHP SimplexML解析XMLメソッドXMLをphp simplexmlは、XMLをコロンと比較するXMLを接続するXMLを接続した場合、XML要素を含むXMLを解析するときに困難に遭遇します。この問題は、simplexmlがデフォルトの名前空間から逸脱するXML構造を処理できないために発生します。例: $ xml ...プログラミング 2025-07-12に投稿されました
-
純粋なCSSでは、複数の粘着性要素を互いに積み重ねることができますか?純粋なCSSで複数の粘着性要素を互いに積み重ねることは可能ですか?ここ: https://webthemez.com/demo/sticky-multi-header-scroll/index.html JavaScriptの実装ではなく、純粋なCSSを使用することのみです。複数の粘...プログラミング 2025-07-12に投稿されました
-
PHPでタイムゾーンを効率的に変換する方法は?php での効率的なタイムゾーン変換は、タイムゾーンの取り扱いは簡単なタスクになる可能性があります。このガイドは、異なるタイムゾーン間で日付と時間を変換するための簡単な実装方法を提供します。たとえば、 //ユーザーのタイムゾーンを定義します date_default_timezone_s...プログラミング 2025-07-12に投稿されました
-
formdata()で複数のファイルアップロードを処理するにはどうすればよいですか?formdata() を使用して複数のファイルアップロードを処理すると、複数のファイルアップロードを処理する必要があることがよくあります。 fd.append("fileToUpload[]", files[x]);メソッドはこの目的に使用でき、単一のリクエストで複数...プログラミング 2025-07-12に投稿されました















中国語を勉強する
- 1 「歩く」は中国語で何と言いますか? 走路 中国語の発音、走路 中国語学習
- 2 「飛行機に乗る」は中国語で何と言いますか? 坐飞机 中国語の発音、坐飞机 中国語学習
- 3 「電車に乗る」は中国語で何と言いますか? 坐火车 中国語の発音、坐火车 中国語学習
- 4 「バスに乗る」は中国語で何と言いますか? 坐车 中国語の発音、坐车 中国語学習
- 5 中国語でドライブは何と言うでしょう? 开车 中国語の発音、开车 中国語学習
- 6 水泳は中国語で何と言うでしょう? 游泳 中国語の発音、游泳 中国語学習
- 7 中国語で自転車に乗るってなんて言うの? 骑自行车 中国語の発音、骑自行车 中国語学習
- 8 中国語で挨拶はなんて言うの? 你好中国語の発音、你好中国語学習
- 9 中国語でありがとうってなんて言うの? 谢谢中国語の発音、谢谢中国語学習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









