
PyMuPDFM を使用して PDF を Markdown に変換する方法とその評価
 ブラウズ:471
ブラウズ:471
PyMuPDF4LLM は、PDF を Markdown 形式に変換するために設計されたライブラリです。ここでは、このライブラリをテストした私の経験を共有します。
インストール
次のコマンドを使用してライブラリをインストールすることから始めます:
pip install pymupdf4llm
使用法
基本的な使用法は非常に簡単で、PDF を Markdown に変換するのに必要なコードは 3 行だけです。
import pymupdf4llm
md_text = pymupdf4llm.to_markdown("input.pdf")
print(md_text)
引数を指定して、コンテンツの抽出方法を調整できます。
ページごとのテキストの抽出
デフォルトでは、PDF 全体が 1 つのテキスト出力に変換されます。ただし、page_chunks=True.
を指定すると、ページごとにテキストを抽出できます。
md_text = pymupdf4llm.to_markdown("input.pdf", page_chunks=True)
画像の抽出
画像をファイルとして抽出するには、write_images=True オプションを使用します:
md_text = pymupdf4llm.to_markdown("input.pdf", write_images=True)
base64 エンコーディングを使用して画像をマークダウンに直接埋め込むこともできます:
md_text = pymupdf4llm.to_markdown("input.pdf", embed_images=True)
変換結果の評価
テストには、さまざまな Markdown 要素を含むさまざまな PDF が使用されました。

ヘッダー変換
ヘッダーは正しく Markdown 形式に変換されます。以下は結果の一部です:
# Sample Markdown Guide This is a sample markdown file that includes various features for quick reference. ## 1. Headers ... ## 3. Lists
太字と斜体のテキスト
太字と斜体の書式も適切に変換されます:
**Bold: **Bold Text**** _Italic: *Italic Text*_ **_Bold and Italic: ***Bold and Italic***_**
リスト変換
最初のレベルの順序付きリストは問題なく変換されますが、入れ子になったリストと順序なしリストは正確に変換されません。
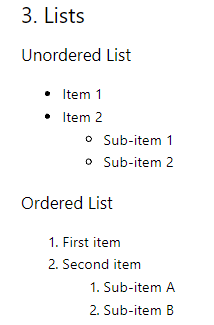
## 3. Lists ### Unordered List Item 1 Item 2 Sub-item 1 Sub-item 2 ### Ordered List 1. First item 2. Second item 1. Sub-item A 2. Sub-item B
リンク変換
リンクの URL は抽出されますが、リンクを含む行全体がハイパーリンクになり、元の形式から逸脱します。
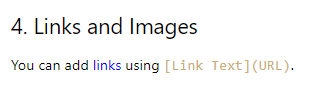
## 4. Links and Images [You can add links using [Link Text](URL).](https://www.example.com/)
画像抽出
画像はデフォルトでは抽出されませんが、write_images=True を使用してローカルに保存できます。
md_text = pymupdf4llm.to_markdown("input.pdf", write_images=True)
保存された画像は、次のようにマークダウンで参照されます:
### Image Example

テーブル変換
垂直方向の境界線のない単純なテーブルは正確に変換されません (列の境界があいまいなため、テーブルがプレーン テキストとして扱われる可能性があります)。

## 5. Tables
**Column 1** **Column 2** **Column 3**
Row 1 Data A Data B
Row 2 Data C Data D
コード変換
コード ブロックは正しく変換されますが、言語仕様 (Python など) は保持されません。インラインコード変換にも問題があります。

## 6. Code
### Inline Code
Use backticks for inline code: print("Hello, world!")
### Code Block
Use triple backticks for code blocks:
```
def greet(name):
return f"Hello, {name}!"
print(greet("Markdown"))
```
複数行のテキスト
複数行のテキストの場合、改行は元の PDF に表示されるとおりに保持されます。

Markdown is a lightweight and versatile markup language favored by developers, writers, and bloggers alike
due to its simplicity in formatting text, enabling users to create readable and well-structured documents—
whether for documentation, blog posts, or articles—without the complexity of HTML, while also offering the
ability to convert content seamlessly into other formats like HTML, PDF, and even slideshows, making it an
ideal choice for projects that require both clarity and flexibility in presentation.
結論
リストやリンクを正確に変換するのは困難ですが、PyMuPDF4LLM は PDF を Markdown に変換するための便利なツールです。外部言語モデルを必要とせずにローカルで動作できるため、インターネット アクセスが利用できない環境に適しています。
-
 ubuntu/linuxにmysql-pythonをインストールするときに\ "mysql_configが見つかりません\"エラーを修正する方法は?mysql-pythonインストールエラー: "mysql_config not obst" をubuntu/linuxボックスにインストールしようとする試みを試みます。このエラーは、MySQL開発ライブラリが欠落しているために発生します。 この問題を解決するには、...プログラミング 2025-04-04に投稿されました
ubuntu/linuxにmysql-pythonをインストールするときに\ "mysql_configが見つかりません\"エラーを修正する方法は?mysql-pythonインストールエラー: "mysql_config not obst" をubuntu/linuxボックスにインストールしようとする試みを試みます。このエラーは、MySQL開発ライブラリが欠落しているために発生します。 この問題を解決するには、...プログラミング 2025-04-04に投稿されました -
formdata()で複数のファイルアップロードを処理するにはどうすればよいですか?formdata() を使用して複数のファイルアップロードを処理すると、複数のファイルアップロードを処理する必要があることがよくあります。 fd.append("fileToUpload[]", files[x]);メソッドはこの目的に使用でき、単一のリクエストで複数...プログラミング 2025-04-04に投稿されました
-
JavaScriptオブジェクトのキーをアルファベット順に並べ替える方法は?javascriptオブジェクトをキー で並べ替える方法JavaScriptオブジェクトがある場合は、読みやすさまたは処理目的の改善のためにそのプロパティをアルファベット順に再編成することができます。これは、次の手順を利用することで実現できます。 const unordered = { ...プログラミング 2025-04-04に投稿されました
-
ポイントインポリゴン検出により効率的な方法:Ray TracingまたはMatplotlib \ 's path.contains_points?Pythonの効率的なポイントインポリゴン検出 ポリゴン内にあるかどうかを決定することは、計算ジオメトリの頻繁なタスクです。このタスクの効率的な方法を見つけることは、多数のポイントを評価する場合に有利です。ここでは、一般的に使用される2つの方法を調査して比較します:Ray TracingとM...プログラミング 2025-04-04に投稿されました
-
最大カウントを見つけるときにmysqlで\ "無効なグループ関数の使用を解決する方法\"エラーは?mysql を使用して最大カウントを取得する方法mysqlでは、次のコマンドを使用して特定の列によってグループ化された値の最大値を見つけようとする際に問題に遭遇する可能性があります。 emp1グループからmax(count(*))を名前で選択します。 エラー1111(HY000):グル...プログラミング 2025-04-04に投稿されました
-
マウスクリック時にDiv内のすべてのテキストをプログラム的に選択するにはどうすればよいですか?マウスクリックでプログラムをプログラム的に選択する 質問 テキストコンテンツのdiv要素が与えられた場合、ユーザーは1つのマウスクリックでdiv内のテキスト全体をプログラム的に選択できますか?これにより、ユーザーは選択したテキストを簡単にドラッグアンドドロップしたり、直接コピーしたりできます。...プログラミング 2025-04-04に投稿されました
-
GOでSQLクエリを構築するときに、テキストと値を安全に連結するにはどうすればよいですか?go sql queries のテキストと値を連結するgoのテキストsqlクエリを構築する際に、特に文字列を使用した場合、文字列を使用した場合に、文字列を使用する場合、アプローチはGOでは有効ではなく、文字列としてパラメーターをキャストしようとすると、タイプのミスマッチエラーが発生しま...プログラミング 2025-04-04に投稿されました
-
匿名のJavaScriptイベントハンドラーをきれいに削除する方法は?匿名イベントリスナーを削除する]イベントリスナーを追加する要素を追加すると、柔軟性とシンプルさを提供しますが、要素自体を置き換えることなく挑戦をもたらすことができます。 element? element.addeventlistener(event、function(){/はここで動作し...プログラミング 2025-04-04に投稿されました
-
Firefoxバックボタンを使用すると、JavaScriptの実行が停止するのはなぜですか?navigational Historyの問題:JavaScriptは、Firefoxバックボタンを使用した後に実行を停止します ユーザーは、JavaScriptスクリプトが以前の訪問ページを介して回復したときに実行されない問題に遭遇する可能性があります。この問題は、ChromeやInt...プログラミング 2025-04-04に投稿されました
-
なぜsqlalchemyフィルター条項で「flake8」はブールの比較にフラグを立てるのですか?flake8 Flake8 Flake8フラグをフィルター節のブール比較 SQLのブール比較に基づいてクエリ結果をフィルタリングしようとすると、開発者は「==」の使用に関してFLAKE8から警告を発する可能性があります。一般に、「condがfalse」または「condではない場合:」を...プログラミング 2025-04-04に投稿されました
-
PDOパラメーターを使用してクエリのように正しく使用する方法は?を使用してpdo PDOで同様のクエリを実装しようとすると、以下のクエリのような問題に遭遇する可能性があります: $query = "SELECT * FROM tbl WHERE address LIKE '%?%' OR address LIKE '%?%'";...プログラミング 2025-04-04に投稿されました
-
Java文字列に複数のサブストリングを効率的に交換するにはどうすればよいですか?java で複数のサブストリングを弦の複数のサブストリングを置き換えると、文字列内の複数のサブストリングを置き換える必要性に直面すると、弦楽列の方法を繰り返し担当するブルートのアプローチに頼ることに魅力的です。ただし、これは大きな文字列や多数の文字列を使用する場合は非効率的です。正規表...プログラミング 2025-04-04に投稿されました
-
PHPでCurlで生のポストリクエストを送信する方法は?php を使用して生のポストリクエストを送信する方法phpでは、curlはhttpリクエストを送信するための人気のライブラリです。この記事では、Curlを使用して、データがエンコードされていない形式で送信される生のPOSTリクエストを実行する方法を示します。次に、次のオプションを構成し...プログラミング 2025-04-04に投稿されました
-
「JSON」パッケージを使用してGOでJSONアレイを解析する方法は?json arrays in jsonパッケージ 問題: 次のGOコードを検討してください: タイプjsontype struct { 配列[]文字列 } func main(){ datajson:= `[" 1 "、" 2 "...プログラミング 2025-04-04に投稿されました
-
多次元アレイのためにPHPでのJSONの解析を簡素化する方法は?jsonをphp でphpで解析しようとする場合、特に多次元配列を扱う場合は困難な場合があります。プロセスを簡素化するには、JSONをオブジェクトではなく配列として解析することをお勧めします。 print_r($ json)を使用して配列構造を探索することは、目的の情報へのアクセス方法を決...プログラミング 2025-04-04に投稿されました















中国語を勉強する
- 1 「歩く」は中国語で何と言いますか? 走路 中国語の発音、走路 中国語学習
- 2 「飛行機に乗る」は中国語で何と言いますか? 坐飞机 中国語の発音、坐飞机 中国語学習
- 3 「電車に乗る」は中国語で何と言いますか? 坐火车 中国語の発音、坐火车 中国語学習
- 4 「バスに乗る」は中国語で何と言いますか? 坐车 中国語の発音、坐车 中国語学習
- 5 中国語でドライブは何と言うでしょう? 开车 中国語の発音、开车 中国語学習
- 6 水泳は中国語で何と言うでしょう? 游泳 中国語の発音、游泳 中国語学習
- 7 中国語で自転車に乗るってなんて言うの? 骑自行车 中国語の発音、骑自行车 中国語学習
- 8 中国語で挨拶はなんて言うの? 你好中国語の発音、你好中国語学習
- 9 中国語でありがとうってなんて言うの? 谢谢中国語の発音、谢谢中国語学習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









