
OpenCV による画像圧縮の完全ガイド
 ブラウズ:250
ブラウズ:250
画像圧縮は、視覚的な品質を維持しながら、画像をより効率的に保存および送信できるようにする、コンピュータ ビジョンにおける重要なテクノロジです。理想的には、小さなファイルを最高の品質で提供したいと考えています。ただし、トレードオフを考慮して、どちらがより重要かを決定する必要があります。
このチュートリアルでは、理論と実践的なアプリケーションをカバーしながら、OpenCV を使用した画像圧縮について説明します。最後には、コンピューター ビジョン プロジェクト (またはその他のプロジェクト) で写真を適切に圧縮する方法を理解できるようになります。
画像圧縮とは何ですか?
画像圧縮とは、許容可能なレベルの視覚的な品質を維持しながら、画像のファイル サイズを削減することです。圧縮には主に 2 つのタイプがあります:
- ロスレス圧縮: 元のデータをすべて保存し、正確な画像の再構築を可能にします。
- 非可逆圧縮: ファイル サイズを小さくするために一部のデータを破棄し、画質が低下する可能性があります。
画像を圧縮する理由
よく聞くように「ディスク容量が安い」のであれば、なぜ画像を圧縮する必要があるのでしょうか?小規模な規模では画像圧縮はあまり重要ではありませんが、大規模な規模では非常に重要になります。
たとえば、ハード ドライブにいくつかの画像がある場合、それらを圧縮して数メガバイトのデータを保存できます。ハードドライブがテラバイト単位で測定される場合、これは大きな影響はありません。しかし、ハード ドライブに 100,000 枚の画像がある場合はどうなるでしょうか?いくつかの基本的な圧縮により、リアルタイムの時間と費用が節約されます。パフォーマンスの観点から見ても、それは同じです。 Web サイトに大量の画像があり、1 日に 10,000 人が Web サイトにアクセスする場合、圧縮が重要になります。
そうする理由は次のとおりです:
- ストレージ要件の削減: 同じスペースにより多くの画像を保存できます
- 高速伝送: Web アプリケーションや帯域幅に制約のあるシナリオに最適
- 処理速度の向上: 画像が小さいほど、読み込みと処理が速くなります
画像圧縮の背後にある理論
画像圧縮技術は 2 種類の冗長性を利用します:
- 空間冗長性: 隣接するピクセル間の相関
- 色の冗長性: 隣接する領域の色の値の類似性
空間冗長性は、ほとんどの自然画像では隣接するピクセルが同様の値を持つ傾向があるという事実を利用します。これにより、スムーズなトランジションが作成されます。ある領域から別の領域への自然な流れがあるため、多くの写真は「本物のように見えます」。隣接するピクセルの値が大きく異なる場合、「ノイズの多い」画像が得られます。ピクセルを単一の色にグループ化し、画像を小さくすることで、トランジションの「滑らかさ」を低下させるためにピクセルが変更されました。

色の冗長性は、画像内の隣接する領域がどのように類似した色を共有することが多いかに焦点を当てています。青い空や緑の野原を思い浮かべてください。画像の大部分が非常に似た色の値を持っている可能性があります。グループ化して単色にしてスペースを節約することもできます。

OpenCV は、これらのアイデアに取り組むための強力なツールを提供します。たとえば、OpenCV の cv2.inpaint() 関数は、空間的冗長性を使用して、近くのピクセルからの情報を使用して画像の欠落または破損した領域を埋めます。 OpenCV では、開発者は cv2.cvtColor() を使用して、色の冗長性に関して複数の色空間間で画像を変換できます。特定の種類の画像をエンコードする場合、一部の色空間が他の色空間より効果的であるため、これは多くの圧縮技術の前処理ステップとしてある程度役立ちます。
この理論の一部を今からテストしてみます。遊んでみましょう。
画像圧縮の実践
OpenCV の Python バインディングを使用して画像を圧縮する方法を見てみましょう。このコードを書き出すかコピーします:
ここからソース コードも入手できます
import cv2
import numpy as np
def compress_image(image_path, quality=90):
# Read the image
img = cv2.imread(image_path)
# Encode the image with JPEG compression
encode_param = [int(cv2.IMWRITE_JPEG_QUALITY), quality]
_, encoded_img = cv2.imencode('.jpg', img, encode_param)
# Decode the compressed image
decoded_img = cv2.imdecode(encoded_img, cv2.IMREAD_COLOR)
return decoded_img
# Example usage
original_img = cv2.imread('original_image.jpg')
compressed_img = compress_image('original_image.jpg', quality=50)
# Display results
cv2.imshow('Original', original_img)
cv2.imshow('Compressed', compressed_img)
cv2.waitKey(0)
cv2.destroyAllWindows()
# Calculate compression ratio
original_size = original_img.nbytes
compressed_size = compressed_img.nbytes
compression_ratio = original_size / compressed_size
print(f"Compression ratio: {compression_ratio:.2f}")
この例には、2 つのパラメータを取る compress_image 関数が含まれています:
- 画像パス (画像が配置されている場所)
- 品質 (希望する画像の品質)
次に、元の画像をoriginal_imgに読み込みます。次に、同じ画像を 50% 圧縮して、新しいインスタンス (compressed_image) にロードします。
次に、元の画像と圧縮された画像を並べて表示します。
次に圧縮率を計算して表示します。
この例では、OpenCV で JPEG 圧縮を使用して画像を圧縮する方法を示します。品質パラメータは、ファイル サイズと画質のトレードオフを制御します。
実行しましょう:
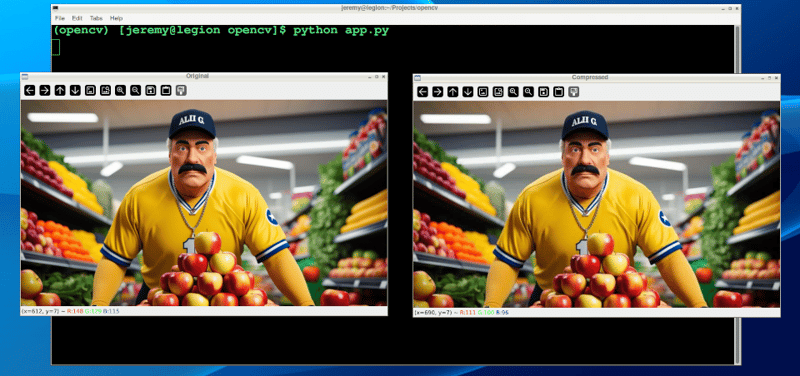
最初に画像を見てみると、ほとんど違いがわかりません。ただし、ズームインすると品質の違いがわかります:
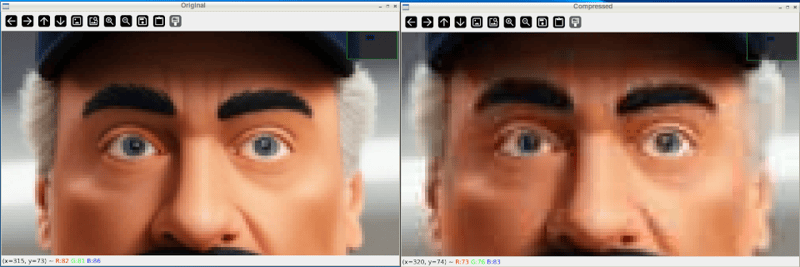
そしてウィンドウを閉じてファイルを見ると、ファイルのサイズが大幅に縮小していることがわかります:

また、さらに下げると、品質を 10% に変更できます
compressed_img = compress_image('sampleimage.jpg', quality=10)
そして結果はさらに劇的です:
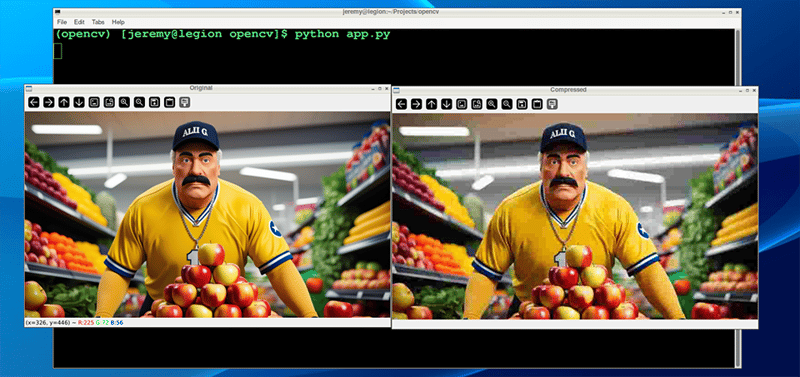
ファイル サイズの結果もさらに大幅に大きくなります:

これらのパラメータを非常に簡単に調整して、品質とファイル サイズの間で望ましいバランスを実現できます。
圧縮品質の評価
圧縮の影響を評価するには、次のような指標を使用できます:
- 平均二乗誤差 (MSE)
平均二乗誤差 (MSE) は、2 つの画像が互いにどの程度異なっているかを測定します。イメージを圧縮する場合、MSE は、圧縮されたイメージが元のイメージと比較してどの程度変更されたかを判断するのに役立ちます。
これは、2 つの画像内の対応するピクセルの色の違いをサンプリングし、それらの差を 2 乗して平均することによって行われます。結果は 1 つの数値になります。MSE が低いほど、圧縮されたイメージがオリジナルに近いことを意味します。比較すると、MSE が高いということは、品質の低下がより顕著であることを意味します。
これを測定するための Python コードをいくつか示します:
def calculate_mse(img1, img2):
return np.mean((img1 - img2) ** 2)
mse = calculate_mse(original_img, compressed_img)
print(f"Mean Squared Error: {mse:.2f}")
デモ画像の圧縮は次のようになります:

- ピーク信号対雑音比 (PSNR)
ピーク信号対雑音比 (PSNR) は、圧縮後に画像の品質がどの程度劣化したかを示す尺度です。これは多くの場合、目で見ることができますが、設定された値が割り当てられます。元の画像と圧縮された画像を比較し、その差を比率で表します。
PSNR 値が高いほど、圧縮された画像の品質がオリジナルに近く、品質の低下が少ないことを意味します。 PSNR が低いほど、劣化が目立ちやすくなります。 PSNR は MSE と併用されることが多く、PSNR は高いほど優れているという解釈しやすいスケールを提供します。
これを測定する Python コードを次に示します:
def calculate_psnr(img1, img2):
mse = calculate_mse(img1, img2)
if mse == 0:
return float('inf')
max_pixel = 255.0
return 20 * np.log10(max_pixel / np.sqrt(mse))
psnr = calculate_psnr(original_img, compressed_img)
print(f"PSNR: {psnr:.2f} dB")
デモ画像の圧縮は次のようになります:
圧縮後の画像を「目視」して品質に問題がないことを判断します。ただし、大規模な場合は、スクリプトでこれを実行する方が、標準を設定し、画像がそれに従うようにするためのはるかに簡単な方法です。
他のテクニックをいくつか見てみましょう:
高度な圧縮技術
より高度な圧縮のために、OpenCV はさまざまなアルゴリズムをサポートしています:
- PNG 圧縮:
画像を PNG 形式に変換すると、多くの利点があります。次のコード行を使用すると、ニーズに応じて圧縮を 0 から 9 まで設定できます。 0 は圧縮がまったくないことを意味し、9 は最大です。 PNG は「ロスレス」形式であるため、最大圧縮しても画像はそのまま残ることに注意してください。大きなトレードオフは、ファイル サイズと圧縮時間です。
OpenCV で PNG 圧縮を使用するコードは次のとおりです:
cv2.imwrite('compressed.png', img, [cv2.IMWRITE_PNG_COMPRESSION, 9])
結果は次のとおりです:
注: この場合のように、PNG ファイルのサイズが実際には大きいことに気づく場合があります。画像の内容により異なります。
- WebP 圧縮:
画像を .webp 形式に変換することもできます。これは、人気が高まっている新しい圧縮方法です。私は何年もブログの画像にこの圧縮を使用してきました。
次のコードでは、画像を webp ファイルに書き込み、圧縮レベルを 0 から 100 まで設定できます。0 であるため、PNG のスケールとは逆になります。これは、代わりに quality を設定しているためです。 圧縮。 0 に設定すると、ファイル サイズが小さくなり、損失が大きくなり、品質が最低となるため、この小さな違いは重要です。 100 が最高品質です。これは、最高の画質を持つ大きなファイルを意味します。
これを実現するための Python コードは次のとおりです:
cv2.imwrite('compressed.webp', img, [cv2.IMWRITE_WEBP_QUALITY, 80])
結果は次のとおりです:

これら 2 つの手法は、大量のデータを圧縮するのに最適です。スクリプトを作成して、数千または数十万の画像を自動的に圧縮できます。
結論
画像圧縮は素晴らしいです。これは、特にスペースを節約したり処理速度を向上させたりする場合に、さまざまな点でコンピューター ビジョン タスクに不可欠です。ハード ドライブの容量を減らしたり、帯域幅を節約したい場合には、コンピューター ビジョン以外にも多くの使用例があります。画像圧縮は非常に役立ちます。
その背後にある理論を理解し、それを適用することで、プロジェクトで強力な効果を得ることができます。
効果的な圧縮の鍵は、ファイル サイズの削減とアプリケーションにとって許容可能なビジュアル品質の維持の間のスイート スポットを見つけることであることを覚えておいてください。
お読みいただきありがとうございます。コメントやご質問がございましたら、お気軽にお問い合わせください。
-
 MySQL を使用して今日が誕生日のユーザーを見つけるにはどうすればよいですか?MySQL を使用して今日の誕生日を持つユーザーを識別する方法MySQL を使用して今日がユーザーの誕生日かどうかを判断するには、誕生日が一致するすべての行を検索する必要があります。今日の日付。これは、UNIX タイムスタンプとして保存されている誕生日と今日の日付を比較する単純な MySQL クエリ...プログラミング 2024 年 12 月 29 日に公開
MySQL を使用して今日が誕生日のユーザーを見つけるにはどうすればよいですか?MySQL を使用して今日の誕生日を持つユーザーを識別する方法MySQL を使用して今日がユーザーの誕生日かどうかを判断するには、誕生日が一致するすべての行を検索する必要があります。今日の日付。これは、UNIX タイムスタンプとして保存されている誕生日と今日の日付を比較する単純な MySQL クエリ...プログラミング 2024 年 12 月 29 日に公開 -
Go で WebSocket を使用してリアルタイム通信を行うチャット アプリケーション、ライブ通知、共同作業ツールなど、リアルタイムの更新が必要なアプリを構築するには、従来の HTTP よりも高速でインタラクティブな通信方法が必要です。そこで WebSocket が登場します。今日は、アプリケーションにリアルタイム機能を追加できるように、Go で WebSo...プログラミング 2024 年 12 月 29 日に公開
-
一意の ID を保持し、重複した名前を処理しながら、PHP で 2 つの連想配列を結合するにはどうすればよいですか?PHP での連想配列の結合PHP では、2 つの連想配列を 1 つの配列に結合するのが一般的なタスクです。次のリクエストを考えてみましょう:問題の説明:提供されたコードは 2 つの連想配列 $array1 と $array2 を定義します。目標は、両方の配列のすべてのキーと値のペアを統合する新しい配...プログラミング 2024 年 12 月 29 日に公開
-
Bootstrap 4 ベータ版の列オフセットはどうなりましたか?Bootstrap 4 ベータ: 列オフセットの削除と復元Bootstrap 4 は、ベータ 1 リリースで、その方法に大幅な変更を導入しました。列がオフセットされました。ただし、その後の Beta 2 リリースでは、これらの変更は元に戻されました。offset-md-* から ml-autoBoo...プログラミング 2024 年 12 月 29 日に公開
-
macOS 上の Django で「ImproperlyConfigured: MySQLdb モジュールのロード中にエラーが発生しました」を修正する方法?MySQL の不適切な構成: 相対パスの問題Django で python manage.py runserver を実行すると、次のエラーが発生する場合があります:ImproperlyConfigured: Error loading MySQLdb module: dlopen(/Library...プログラミング 2024 年 12 月 29 日に公開
-
データ挿入時の「一般エラー: 2006 MySQL サーバーが消えました」を修正するにはどうすればよいですか?レコードの挿入中に「一般エラー: 2006 MySQL サーバーが消えました」を解決する方法はじめに:MySQL データベースにデータを挿入すると、「一般エラー: 2006 MySQL サーバーが消えました。」というエラーが発生することがあります。このエラーは、通常、MySQL 構成内の 2 つの変...プログラミング 2024 年 12 月 29 日に公開
-
「if」ステートメントを超えて: 明示的な「bool」変換を伴う型をキャストせずに使用できる場所は他にありますか?キャストなしで bool へのコンテキスト変換が可能クラスは bool への明示的な変換を定義し、そのインスタンス 't' を条件文で直接使用できるようにします。ただし、この明示的な変換では、キャストなしで bool として 't' を使用できる場所はどこですか?コン...プログラミング 2024 年 12 月 29 日に公開
-
React でクラス属性を条件付きで適用するにはどうすればよいですか?React でクラス属性を条件付きで適用するReact では、親コンポーネントから渡された props に基づいて要素を表示または非表示にするのが一般的です。これを実現するには、条件付きで CSS クラスを適用できます。ただし、構文 {this.props.condition ? を使用すると、潜在...プログラミング 2024 年 12 月 28 日に公開
-
Java でシステム コマンドを実行し、他のアプリケーションと対話する方法は?Java でのプロセスの実行Java では、プロセスを起動する機能は、システム コマンドを実行し、他のアプリケーションと対話するための重要な機能です。プロセスを開始するために、Java は .Net System.Diagnostics.Process.Start メソッドと同等のメソッドを提供しま...プログラミング 2024 年 12 月 28 日に公開
-
C++ で複数行の文字列リテラルを作成するにはどうすればよいですか?C の複数行の文字列リテラル C では、複数行の文字列リテラルの定義は、Perl などの他の言語ほど簡単ではありません。ただし、これを実現するために使用できる手法がいくつかあります。連結文字列リテラル1 つの方法は、C の隣接する文字列リテラルがコンパイラによって連結されるという事実を利用することで...プログラミング 2024 年 12 月 28 日に公開
-
情報の損失を避けるために、異なるレコードを持つデータを正確にピボットするにはどうすればよいですか?個別のレコードを効果的にピボットするピボット クエリは、データを表形式に変換し、簡単なデータ分析を可能にする上で重要な役割を果たします。ただし、個別のレコードを扱う場合、ピボット クエリのデフォルトの動作に問題が生じる可能性があります。問題: 個別の値の無視次の表を検討してください:--------...プログラミング 2024 年 12 月 27 日に公開
-
C と C++ が関数シグネチャの配列の長さを無視するのはなぜですか?C および C の関数に配列を渡す 質問:なぜ C と C では、 C コンパイラでは、int dis(char a[1]) などの関数シグネチャでの配列長宣言が許可されていない場合でも許可されます。 enforced?答え:C および C で配列を関数に渡すために使用される構文は、最初の要素へのポ...プログラミング 2024 年 12 月 26 日に公開
-
MySQL でアクセントを削除してオートコンプリート検索を改善するにはどうすればよいですか?効率的なオートコンプリート検索のために MySQL でアクセントを削除する地名の大規模なデータベースを管理する場合、正確かつ効率的であることを保証することが重要ですデータの取得。地名にアクセントがあると、オートコンプリート機能を使用するときに問題が発生する可能性があります。これに対処するには、当然の...プログラミング 2024 年 12 月 26 日に公開
-
MySQL で複合外部キーを実装するにはどうすればよいですか?SQL での複合外部キーの実装一般的なデータベース設計の 1 つは、複合キーを使用してテーブル間の関係を確立することです。複合キーは、テーブル内のレコードを一意に識別する複数の列の組み合わせです。このシナリオでは、チュートリアルとグループの 2 つのテーブルがあり、チュートリアルの複合一意キーをグル...プログラミング 2024 年 12 月 26 日に公開
-
Java で JComponent が背景画像の後ろに隠れるのはなぜですか?背景画像で隠された JComponent のデバッグJava アプリケーションで JLabel などの JComponent を操作する場合、適切な動作を保証することが重要です。そして視認性。コンポーネントが背景画像の背後に隠れるという問題が発生した場合は、次のアプローチを検討してください。1.コン...プログラミング 2024 年 12 月 26 日に公開















中国語を勉強する
- 1 「歩く」は中国語で何と言いますか? 走路 中国語の発音、走路 中国語学習
- 2 「飛行機に乗る」は中国語で何と言いますか? 坐飞机 中国語の発音、坐飞机 中国語学習
- 3 「電車に乗る」は中国語で何と言いますか? 坐火车 中国語の発音、坐火车 中国語学習
- 4 「バスに乗る」は中国語で何と言いますか? 坐车 中国語の発音、坐车 中国語学習
- 5 中国語でドライブは何と言うでしょう? 开车 中国語の発音、开车 中国語学習
- 6 水泳は中国語で何と言うでしょう? 游泳 中国語の発音、游泳 中国語学習
- 7 中国語で自転車に乗るってなんて言うの? 骑自行车 中国語の発音、骑自行车 中国語学習
- 8 中国語で挨拶はなんて言うの? 你好中国語の発音、你好中国語学習
- 9 中国語でありがとうってなんて言うの? 谢谢中国語の発音、谢谢中国語学習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









