
OpenVINO と Postgres を使用した高速かつ効率的なセマンティック検索システムの構築
 ブラウズ:629
ブラウズ:629

Pixabayのreal-napsterによる写真
最近のプロジェクトの 1 つでは、高パフォーマンスで拡張でき、レポート検索に対してリアルタイムの応答を提供できるセマンティック検索システムを構築する必要がありました。これを実現するために、AWS RDS 上で PostgreSQL と pgvector を AWS Lambda と組み合わせて使用しました。課題は、ユーザーが厳密なキーワードに依存するのではなく、自然言語クエリを使用して検索できるようにしながら、応答が 1 ~ 2 秒未満、あるいはそれ以下であることを保証し、CPU リソースのみを活用できるようにすることでした。
この投稿では、検索から再ランキングまで、この検索システムを構築するために行った手順と、OpenVINO とトークン化のためのインテリジェントなバッチ処理を使用した最適化について説明します。
セマンティック検索の概要: 取得と再ランキング
現代の最先端の検索システムは通常、検索と再ランキングという 2 つの主要なステップで構成されます。
1) 取得: 最初のステップでは、ユーザーのクエリに基づいて関連ドキュメントのサブセットを取得します。これは、OpenAI の大小のエンベディング、Cohere の Embed モデル、Mixbread の mxbai エンベディングなど、事前トレーニングされたエンベディング モデルを使用して実行できます。検索では、クエリとの類似性を測定することでドキュメントのプールを絞り込むことに重点を置いています。
これは、この目的で私のお気に入りのライブラリの 1 つである Huggingface の文変換ライブラリを検索に使用した簡略化された例です。
from sentence_transformers import SentenceTransformer
import numpy as np
# Load a pre-trained sentence transformer model
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2")
# Sample query and documents (vectorize the query and the documents)
query = "How do I fix a broken landing gear?"
documents = ["Report 1 on landing gear failure", "Report 2 on engine problems"]
# Get embeddings for query and documents
query_embedding = model.encode(query)
document_embeddings = model.encode(documents)
# Calculate cosine similarity between query and documents
similarities = np.dot(document_embeddings, query_embedding)
# Retrieve top-k most relevant documents
top_k = np.argsort(similarities)[-5:]
print("Top 5 documents:", [documents[i] for i in top_k])
2) 再ランキング: 最も関連性の高いドキュメントが取得されたら、クロスエンコーダー モデルを使用してこれらのドキュメントのランキングをさらに向上させます。このステップでは、より深い文脈の理解に重点を置き、クエリに関連して各ドキュメントをより正確に再評価します。
再ランキングは、各ドキュメントの関連性をより正確にスコアリングすることで、さらに洗練された層を追加するため、有益です。
これは、軽量クロスエンコーダーであるcross-encoder/ms-marco-TinyBERT-L-2-v2を使用した再ランキングのコード例です:
from sentence_transformers import CrossEncoder
# Load the cross-encoder model
cross_encoder = CrossEncoder("cross-encoder/ms-marco-TinyBERT-L-2-v2")
# Use the cross-encoder to rerank top-k retrieved documents
query_document_pairs = [(query, doc) for doc in documents]
scores = cross_encoder.predict(query_document_pairs)
# Rank documents based on the new scores
top_k_reranked = np.argsort(scores)[-5:]
print("Top 5 reranked documents:", [documents[i] for i in top_k_reranked])
ボトルネックの特定: トークン化と予測のコスト
開発中に、文変換のデフォルト設定で 1,000 件のレポートを処理すると、トークン化と予測の段階にかなりの時間がかかることがわかりました。特にリアルタイムの応答を目指していたため、これによりパフォーマンスのボトルネックが発生しました。
以下では、パフォーマンスを視覚化するために SnakeViz を使用してコードをプロファイリングしました:
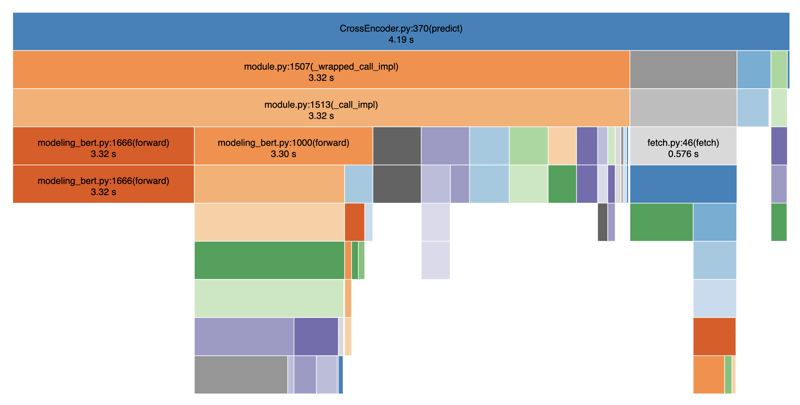
ご覧のとおり、トークン化と予測の手順が不釣り合いに遅く、検索結果の提供に大幅な遅れが生じます。全体的には平均して 4 ~ 5 秒かかりました。これは、トークン化と予測のステップの間にブロック操作があるためです。データベース呼び出しやフィルタリングなどの他の操作も追加すると、合計で簡単に 8 ~ 9 秒かかります。
OpenVINO によるパフォーマンスの最適化
私が直面した質問は次のとおりです: 高速化はできますか? 答えは「はい、CPU 推論用に最適化されたバックエンドである OpenVINO を活用することで可能です」です。 OpenVINO は、AWS Lambda で使用している Intel ハードウェアでのディープ ラーニング モデル推論の高速化に役立ちます。
OpenVINO 最適化のコード例
推論を高速化するために OpenVINO を検索システムに統合した方法は次のとおりです:
import argparse
import numpy as np
import pandas as pd
from typing import Any
from openvino.runtime import Core
from transformers import AutoTokenizer
def load_openvino_model(model_path: str) -> Core:
core = Core()
model = core.read_model(model_path ".xml")
compiled_model = core.compile_model(model, "CPU")
return compiled_model
def rerank(
compiled_model: Core,
query: str,
results: list[str],
tokenizer: AutoTokenizer,
batch_size: int,
) -> np.ndarray[np.float32, Any]:
max_length = 512
all_logits = []
# Split results into batches
for i in range(0, len(results), batch_size):
batch_results = results[i : i batch_size]
inputs = tokenizer(
[(query, item) for item in batch_results],
padding=True,
truncation="longest_first",
max_length=max_length,
return_tensors="np",
)
# Extract input tensors (convert to NumPy arrays)
input_ids = inputs["input_ids"].astype(np.int32)
attention_mask = inputs["attention_mask"].astype(np.int32)
token_type_ids = inputs.get("token_type_ids", np.zeros_like(input_ids)).astype(
np.int32
)
infer_request = compiled_model.create_infer_request()
output = infer_request.infer(
{
"input_ids": input_ids,
"attention_mask": attention_mask,
"token_type_ids": token_type_ids,
}
)
logits = output["logits"]
all_logits.append(logits)
all_logits = np.concatenate(all_logits, axis=0)
return all_logits
def fetch_search_data(search_text: str) -> pd.DataFrame:
# Usually you would fetch the data from a database
df = pd.read_csv("cnbc_headlines.csv")
df = df[~df["Headlines"].isnull()]
texts = df["Headlines"].tolist()
# Load the model and rerank
openvino_model = load_openvino_model("cross-encoder-openvino-model/model")
tokenizer = AutoTokenizer.from_pretrained("cross-encoder/ms-marco-TinyBERT-L-2-v2")
rerank_scores = rerank(openvino_model, search_text, texts, tokenizer, batch_size=16)
# Add the rerank scores to the DataFrame and sort by the new scores
df["rerank_score"] = rerank_scores
df = df.sort_values(by="rerank_score", ascending=False)
return df
if __name__ == "__main__":
parser = argparse.ArgumentParser(
description="Fetch search results with reranking using OpenVINO"
)
parser.add_argument(
"--search_text",
type=str,
required=True,
help="The search text to use for reranking",
)
args = parser.parse_args()
df = fetch_search_data(args.search_text)
print(df)
このアプローチにより、2 ~ 3 倍のスピードアップが得られ、元の 4 ~ 5 秒が 1 ~ 2 秒に短縮されます。完全に動作するコードは Github にあります。
速度の微調整: バッチ サイズとトークン化
パフォーマンスを向上させるもう 1 つの重要な要素は、トークン化プロセスを最適化し、バッチ サイズとトークンの長さを調整することでした。バッチ サイズ (batch_size=16) を増やし、トークンの長さ (max_length=512) を減らすことで、トークン化を並列化し、反復操作のオーバーヘッドを減らすことができます。私たちの実験では、batch_size が 16 から 64 の間でうまく機能し、それより大きいとパフォーマンスが低下することがわかりました。同様に、max_length を 128 に決定しました。これは、レポートの平均長が比較的短い場合に実行可能です。これらの変更により、全体で 8 倍の高速化を達成し、CPU 上でも再ランキング時間を 1 秒未満に短縮しました。
実際には、これは、データの速度と精度の間の適切なバランスを見つけるために、さまざまなバッチ サイズとトークンの長さを実験することを意味しました。これにより、応答時間が大幅に改善され、1,000 件のレポートでも検索システムを拡張できるようになりました。
結論
OpenVINO を使用し、トークン化とバッチ処理を最適化することで、CPU のみのセットアップでリアルタイム要件を満たす高性能のセマンティック検索システムを構築することができました。実際、全体で 8 倍の高速化が実現しました。センテンストランスフォーマーを使用した検索とクロスエンコーダーモデルを使用した再ランキングの組み合わせにより、強力でユーザーフレンドリーな検索エクスペリエンスが作成されます。
応答時間と計算リソースに制約がある同様のシステムを構築している場合は、OpenVINO とインテリジェントなバッチ処理を検討して、パフォーマンスを向上させることを強くお勧めします。
この記事をお楽しみいただければ幸いです。この記事が役立つと思われた場合は、他の人も見つけられるように「いいね」を押して、お友達と共有してください。私の仕事の最新情報を入手するには、Linkedin で私をフォローしてください。読んでいただきありがとうございます!
-
 動的にサイズの親要素内の要素のスクロール範囲を制限する方法は?垂直スクロール要素のcss高さ制限の実装 インタラクティブインターフェイスで、要素のスクロール挙動を制御することは、ユーザーエクスペリエンスとアクセシビリティを確保するために不可欠です。そのようなシナリオの1つは、動的にサイズの親要素内の要素のスクロール範囲を制限することです。ただし、マッ...プログラミング 2025-04-07に投稿しました
動的にサイズの親要素内の要素のスクロール範囲を制限する方法は?垂直スクロール要素のcss高さ制限の実装 インタラクティブインターフェイスで、要素のスクロール挙動を制御することは、ユーザーエクスペリエンスとアクセシビリティを確保するために不可欠です。そのようなシナリオの1つは、動的にサイズの親要素内の要素のスクロール範囲を制限することです。ただし、マッ...プログラミング 2025-04-07に投稿しました -
Laravel Bladeテンプレートの変数をエレガントに定義するにはどうすればよいですか?Laravel Bladeテンプレートの変数を優雅さで定義する ブレードテンプレートに変数を割り当てる方法を理解することは、後で使用するためにデータを保存するために重要です。 「{{{{}}}」を使用して変数を割り当てるのは簡単ですが、常に最もエレガントなソリューションであるとは限りませ...プログラミング 2025-04-07に投稿しました
-
さまざまな数の列を持つデータベーステーブルを結合するにはどうすればよいですか?異なる列とのテーブルを組み合わせた ] は、データベーステーブルを異なる列とマージしようとする場合に課題に遭遇する可能性があります。簡単な方法は、列が少ないテーブルに欠落している列にnull値を追加することです。 たとえば、テーブルAと表Bの2つの表Aと表AがテーブルBよりも多くの列がある...プログラミング 2025-04-07に投稿しました
-
Javaの「DD/MM/YYYY HH:MM:SS.SS」形式で現在の日付と時刻を正しく表示するにはどうすればよいですか?「dd/mm/yyyy hh:mm:ss.ss」形式で現在の日付と時刻を表示する方法。異なるフォーマットパターンを持つさまざまなSimpleDateFormatインスタンスの使用にあります。 java.text.simpledateformat; java.util.calendarをインポ...プログラミング 2025-04-07に投稿しました
-
PHPでタイムゾーンを効率的に変換する方法は?php での効率的なタイムゾーン変換は、タイムゾーンの取り扱いは簡単なタスクになる可能性があります。このガイドは、異なるタイムゾーン間で日付と時間を変換するための簡単な実装方法を提供します。たとえば、 //ユーザーのタイムゾーンを定義します date_default_timezone_s...プログラミング 2025-04-07に投稿しました
-
なぜ私の線形勾配の背景にストライプがあるのか、どうすればそれらを修正できますか?リニアグラデーションからの背景ストライプを追放する 背景に線形勾配プロパティを使用する場合、方向が上または下に設定されているときに顕著なストライプに遭遇する場合があります。これらの見苦しいアーティファクトは、複雑なバックグラウンド伝播現象に起因する可能性があります。その後、線形勾配はこの高...プログラミング 2025-04-07に投稿しました
-
CSSを使用してChromeとFirefoxのコンソール出力を着色できますか?javaScriptコンソールの色の表示 は、クロムのコンソールを使用してエラー用の赤、警告用のオレンジ、コンソール用グリーンなどの色のテキストを表示することは可能です。メッセージ? 回答 はい、CSSを使用して、ChromeとFirefox(バージョン31以降)のコンソールに表示さ...プログラミング 2025-04-07に投稿しました
-
\ "while(1)vs。for(;;):コンパイラの最適化はパフォーマンスの違いを排除しますか?\"while(1)vs。for(;;):速度の違いはありますか? loops? 回答: では、ほとんどの最新のコンパイラでは、(1)と(;;)。コンパイラー: perl: の両方が(1)と(;;)が同じオプコードをもたらします。 1 入力 - > 2を入力します 2 NextSt...プログラミング 2025-04-07に投稿しました
-
Pythonのリクエストと偽のユーザーエージェントでWebサイトブロックをバイパスする方法は?Pythonのリクエストと偽のユーザーエージェントでブラウザの動作をシミュレートする方法これは、Webサイトが実際のブラウザと自動化されたスクリプトを区別するアンチボット測定を実装できるためです。これらのブロックをバイパスするために、開発者はブラウザの動作を模倣してカスタムユーザーエージェ...プログラミング 2025-04-07に投稿しました
-
McRyptからOpenSSLに暗号化を移行し、OpenSSLを使用してMcRyptで暗号化されたデータを復号化できますか?暗号化ライブラリをMcRyptからOpenSSL にアップグレードして、暗号化ライブラリをMcRyptからOpenSLにアップグレードできますか? OpenSSLでは、McRyptで暗号化されたデータを復号化することは可能ですか? 2つの異なる投稿は矛盾する情報を提供します。もしそうなら...プログラミング 2025-04-07に投稿しました
-
ポイントインポリゴン検出により効率的な方法:Ray TracingまたはMatplotlib \ 's path.contains_points?Pythonの効率的なポイントインポリゴン検出 ポリゴン内にあるかどうかを決定することは、計算ジオメトリの頻繁なタスクです。このタスクの効率的な方法を見つけることは、多数のポイントを評価する場合に有利です。ここでは、一般的に使用される2つの方法を調査して比較します:Ray TracingとM...プログラミング 2025-04-07に投稿しました
-
Microsoft Visual C ++が2フェーズテンプレートのインスタンス化を正しく実装できないのはなぜですか?Microsoft Visual Cの「壊れた」2フェーズテンプレートのインスタンス化の謎 問題声明: ユーザーは、Microsoft Visual C(MSVC)の懸念を表現する一般的な懸念を表明します。メカニズムの特定の側面は、予想どおりに動作できませんか?ただし、このチェックがテンプ...プログラミング 2025-04-07に投稿しました
-
順序付けられていないコレクションにタプルの一般的なハッシュ関数を実装する方法は?std :: unordered_mapとunordered_setコンテナは、ハスド値に基づいて効率的なルックアップと元素の挿入を提供します。ただし、カスタムハッシュ関数を定義せずにこれらのコレクションのキーとしてタプルを使用すると、予期しない動作につながる可能性があります。 st...プログラミング 2025-04-07に投稿しました
-
JavaScriptオブジェクトにキーを動的に設定する方法は?JavaScriptオブジェクト変数の動的キーを作成する方法 この構文jsObj['key' i] = 'example' 1; はjavascriptで、アレイは特殊なタイプのオブジェクトです。この特別な動作は標準のオブジェクトによって模倣されていませんが、四角いブラケット演算子は...プログラミング 2025-04-07に投稿しました
-
Regexを使用してPHPで括弧内で効率的にテキストを抽出する方法php:括弧内の括弧内のテキストの抽出 括弧内に囲まれたテキストの抽出を扱うとき、最も効率的なソリューションを見つけることが不可欠です。 1つのアプローチは、以下に示すように、PHPの文字列操作関数を利用することです。 $ fullstring); $ sportstring = s...プログラミング 2025-04-07に投稿しました















中国語を勉強する
- 1 「歩く」は中国語で何と言いますか? 走路 中国語の発音、走路 中国語学習
- 2 「飛行機に乗る」は中国語で何と言いますか? 坐飞机 中国語の発音、坐飞机 中国語学習
- 3 「電車に乗る」は中国語で何と言いますか? 坐火车 中国語の発音、坐火车 中国語学習
- 4 「バスに乗る」は中国語で何と言いますか? 坐车 中国語の発音、坐车 中国語学習
- 5 中国語でドライブは何と言うでしょう? 开车 中国語の発音、开车 中国語学習
- 6 水泳は中国語で何と言うでしょう? 游泳 中国語の発音、游泳 中国語学習
- 7 中国語で自転車に乗るってなんて言うの? 骑自行车 中国語の発音、骑自行车 中国語学習
- 8 中国語で挨拶はなんて言うの? 你好中国語の発音、你好中国語学習
- 9 中国語でありがとうってなんて言うの? 谢谢中国語の発音、谢谢中国語学習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









