
Fastly で AI を使用して「あなた向け」のレコメンデーションを作成します。
 ブラウズ:725
ブラウズ:725
誇大広告は忘れてください。 AI はどこで真の価値を提供しているのでしょうか?エッジ コンピューティングを使用して AI の力を活用し、高速で安全かつ信頼性の高い、よりスマートなユーザー エクスペリエンスを実現しましょう。
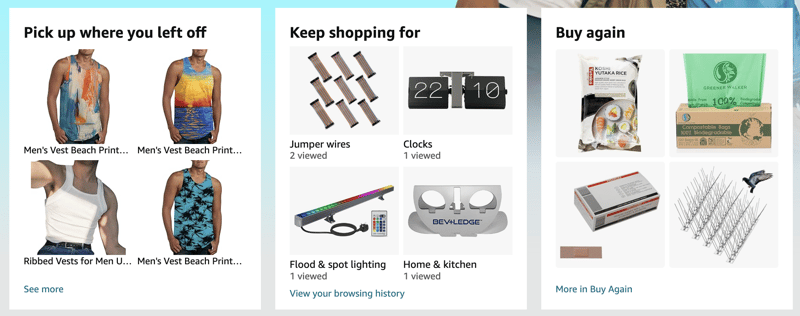
推奨事項はどこにでもあり、Web エクスペリエンスをよりパーソナライズすることで、より魅力的で成功するものになることは誰もが知っています。 私の Amazon ホームページでは、私が家具、キッチン用品、そして今は夏服が好きであることを知っています:
今日、ほとんどのプラットフォームでは、高速かパーソナライズのどちらかを選択する必要があります。 Fastly では、あなたとあなたのユーザーは両方を持つに値すると考えています。 Web サーバーがページを生成するたびに、そのページが 1 人のエンド ユーザーにのみ適している場合は、そのページをキャッシュするメリットが得られません。これは、Fastly のようなエッジ ネットワークがうまく機能することです。
では、エッジ キャッシュの恩恵を受けながら、コンテンツをパーソナライズするにはどうすればよいでしょうか? 私たちは、複雑なクライアント リクエストを複数の小さなキャッシュ可能なバックエンド リクエストに分割する方法についてこれまでに何度も書いてきました。また、開発者ハブのパーソナライゼーション トピックにチュートリアル、コード例、デモが掲載されています。
しかし、さらに進んでパーソナライゼーション データを エッジ で生成したい場合はどうすればよいでしょうか? 「エッジ」、つまり Web サイトのトラフィックを処理する Fastly サーバーは、エンド ユーザーに最も近い、制御範囲内にあるポイントです。 1 人のユーザーに特化したコンテンツを作成するのに最適な場所です。
「あなた向け」の使用例
製品の推奨事項は本質的に一時的であり、個々のユーザーに固有であり、頻繁に変更される可能性があります。 ただし、永続的である必要もありません。通常、各人に何を推奨したかを知る必要はありません。特定のアルゴリズムが他のアルゴリズムよりも優れた変換を達成するかどうかだけを知る必要があります。 一部の推奨アルゴリズムでは、どのユーザーがあなたに最も似ているか、その購入履歴や評価履歴など、大量の状態データにアクセスする必要がありますが、多くの場合、そのデータは一括で簡単に事前生成できます。
基本的に、推奨事項の生成では通常、トランザクションは作成されず、データ ストアでのロックも必要ありません。また、現在のユーザーのセッションからすぐに利用できる入力データ、またはオフラインのビルド プロセスで作成された入力データが使用されます。
エッジで推奨事項を生成できるようです!
現実世界の例
ニューヨーク メトロポリタン美術館のウェブサイトを見てみましょう:
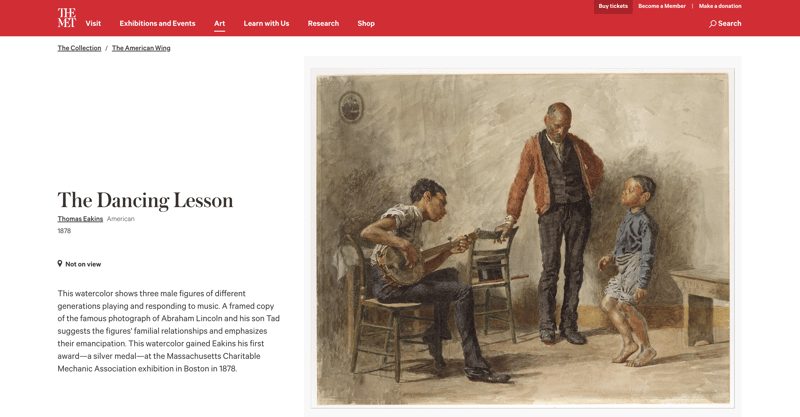
メトロポリタン美術館のコレクションにある約 500,000 点のオブジェクトには、それぞれ写真とそれに関する情報が記載されたページがあります。 関連オブジェクトのリストも含まれています:
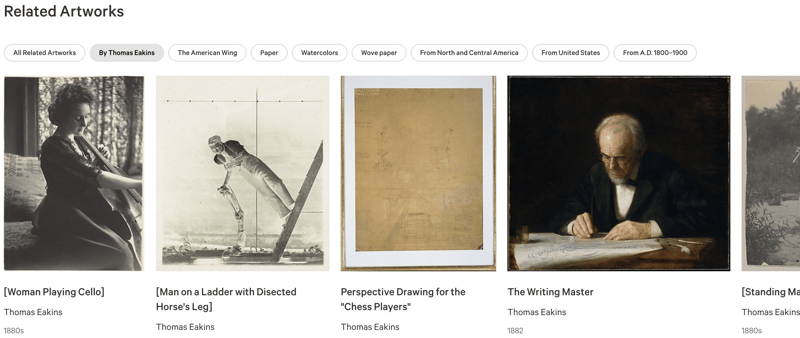
これは、これらの関係を生成するために非常に単純なファセット システムを使用しているようで、同じアーティストによる他の作品、美術館の同じ棟にある他のオブジェクト、または同じ紙で作られているか、同じ紙で作られた他のオブジェクトを示しています。期間。
このシステムの良い点は (開発者の観点から!) 1 つの入力オブジェクトのみに基づいているため、それをページ内に事前生成できることです。
この 1 つのオブジェクトだけではなく、エンド ユーザーがメトロポリタン美術館の Web サイト内を移動する際の個人的な閲覧履歴に基づいた推奨事項の選択でこれを強化したい場合はどうすればよいでしょうか?
パーソナライズされた推奨事項の追加
これを行う方法はたくさんありますが、私は言語モデルを使ってみたかったのです。なぜなら、AI は現在起こっているし、それはメトロポリタン美術館の既存の関連芸術作品の仕組みとは大きく異なるからです。仕事。 計画は次のとおりです:
- メトロポリタン美術館のオープンアクセス コレクション データセットをダウンロードします。
- 言語モデルを通じて実行して、機械学習タスクに適した数値のリストであるベクトル埋め込みを作成します。
- 結果として得られる 50 万個のベクトル (メトロポリタン美術館の芸術作品を表す) に対して高性能な類似性検索エンジンを構築し、それを KV ストアにロードして、Fastly Compute から使用できるようにします。
これをすべて完了すると、メトロポリタン美術館の Web サイトを閲覧するときに次のことができるようになります。
- 訪問した作品を Cookie で追跡します。
- これらのアートワークに対応するベクトルを検索します。
- 閲覧の興味を表す平均ベクトルを計算します。
- これを類似検索エンジンに接続すると、最も類似したアートワークが見つかります。
- Met の Object API からこれらのアートワークに関する詳細を読み込み、パーソナライズされた推奨事項でページを強化します。
さあ、パーソナライズされたおすすめ情報です:

それでは、詳しく見ていきましょう。
データセットの作成
Met の生データセットは多数の列を含む CSV で、次のようになります:
Object Number,Is Highlight,Is Timeline Work,Is Public Domain,Object ID,Gallery Number,Department,AccessionYear,Object Name,Title,Culture,Period,Dynasty,Reign,Portfolio,Constituent ID,Artist Role,Artist Prefix,Artist Display Name,Artist Display Bio,Artist Suffix,Artist Alpha Sort,Artist Nationality,Artist Begin Date,Artist End Date,Artist Gender,Artist ULAN URL,Artist Wikidata URL,Object Date,Object Begin Date,Object End Date,Medium,Dimensions,Credit Line,Geography Type,City,State,County,Country,Region,Subregion,Locale,Locus,Excavation,River,Classification,Rights and Reproduction,Link Resource,Object Wikidata URL,Metadata Date,Repository,Tags,Tags AAT URL,Tags Wikidata URL 1979.486.1,False,False,False,1,,The American Wing,1979,Coin,One-dollar Liberty Head Coin,,,,,,16429,Maker," ",James Barton Longacre,"American, Delaware County, Pennsylvania 1794–1869 Philadelphia, Pennsylvania"," ","Longacre, James Barton",American,1794 ,1869 ,,http://vocab.getty.edu/page/ulan/500011409,https://www.wikidata.org/wiki/Q3806459,1853,1853,1853,Gold,Dimensions unavailable,"Gift of Heinz L. Stoppelmann, 1979",,,,,,,,,,,,,,http://www.metmuseum.org/art/collection/search/1,,,"Metropolitan Museum of Art, New York, NY",,, 1980.264.5,False,False,False,2,,The American Wing,1980,Coin,Ten-dollar Liberty Head Coin,,,,,,107,Maker," ",Christian Gobrecht,1785–1844," ","Gobrecht, Christian",American,1785 ,1844 ,,http://vocab.getty.edu/page/ulan/500077295,https://www.wikidata.org/wiki/Q5109648,1901,1901,1901,Gold,Dimensions unavailable,"Gift of Heinz L. Stoppelmann, 1980",,,,,,,,,,,,,,http://www.metmuseum.org/art/collection/search/2,,,"Metropolitan Museum of Art, New York, NY",,,
これを ID と文字列の 2 つの列に変換するのは簡単です:
id,description 1,"One-dollar Liberty Head Coin; Type: Coin; Artist: James Barton Longacre; Medium: Gold; Date: 1853; Credit: Gift of Heinz L. Stoppelmann, 1979" 2,"Ten-dollar Liberty Head Coin; Type: Coin; Artist: Christian Gobrecht; Medium: Gold; Date: 1901; Credit: Gift of Heinz L. Stoppelmann, 1980" 3,"Two-and-a-Half Dollar Coin; Type: Coin; Medium: Gold; Date: 1927; Credit: Gift of C. Ruxton Love Jr., 1967"
これで、Hugging Face AI ツールセットのトランスフォーマー パッケージを使用して、これらの各記述の埋め込みを生成できるようになりました。 文変換/all-MiniLM-L12-v2 モデルを使用し、主成分分析 (PCA) を使用して結果のベクトルを 5 次元に削減しました。 これにより、次のような結果が得られます:
[
{
"id": 1,
"vector": [ -0.005544120445847511, -0.030924081802368164, 0.008597176522016525, 0.20186401903629303, 0.0578165128827095 ]
},
{
"id": 2,
"vector": [ -0.005544120445847511, -0.030924081802368164, 0.008597176522016525, 0.20186401903629303, 0.0578165128827095 ]
},
…
]
これらは 50 万個あるため、このデータセット全体をエッジ アプリのメモリ内に保存することはできません。 そして、このデータに対してカスタム タイプの類似性検索を実行したいと考えています。これは、従来の Key-Value ストアでは提供されていません。私たちはリアルタイムのエクスペリエンスを構築しているので、一度に 50 万個のベクトルを検索する必要も避けたいと考えています。
それでは、データを分割しましょう。 KMeans クラスタリングを使用して、互いに類似したベクトルをグループ化できます。 データをさまざまなサイズの 500 個のクラスターにスライスし、それらのクラスターごとに「重心ベクトル」と呼ばれる中心点を計算しました。 このベクトル空間を 2 次元でプロットして拡大すると、次のようになります。
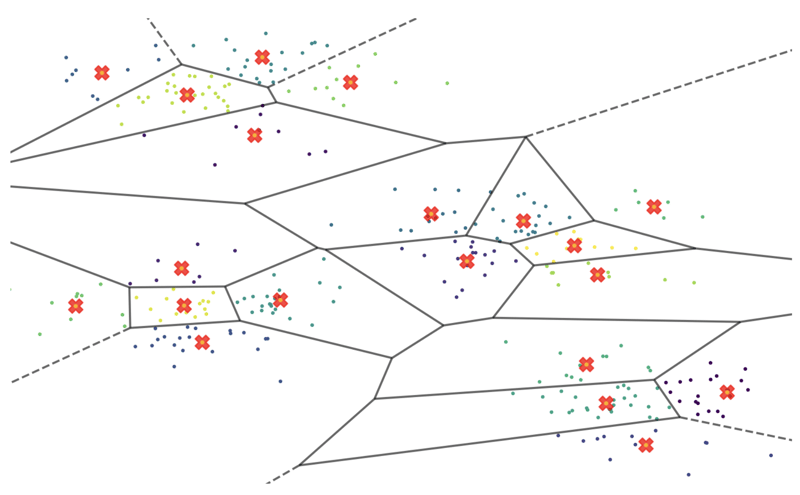
赤い十字は、重心と呼ばれるベクトルの各クラスターの数学的中心点です。これらは、50 万のベクトル空間に対するウェイファインダーのように機能します。たとえば、指定されたベクトル A に最も類似した 10 個のベクトルを見つけたい場合、まず (500 個の中から) 最も近い重心を探し、次に対応するクラスター内でのみ検索を実行できます。これは、はるかに管理しやすい領域です。
これで、500 個の小さなデータセットと、重心点を関連するデータセットにマッピングするインデックスができました。 次に、リアルタイム パフォーマンスを有効にするために、検索グラフをプリコンパイルして、実行時に検索グラフを初期化して構築する必要がなく、使用する CPU 時間をできるだけ少なくできるようにしたいと考えています。 本当に高速な最近傍アルゴリズムは Hierarchical Navigable Small Worlds (HNSW) であり、これには純粋な Rust 実装があり、エッジ アプリの作成に使用しています。 そこで、各データセットの HNSW グラフ構造体を構築するための小さなスタンドアロン Rust アプリを作成し、その後、bincode を使用してインスタンス化された構造体のメモリをバイナリ BLOB にエクスポートしました。
これで、これらのバイナリ BLOB を KV ストアにロードし、クラスター インデックスに対してキーを設定し、クラスター インデックスをエッジ アプリに含めることができます。
このアーキテクチャにより、検索インデックスの一部をオンデマンドでメモリに読み込むことができます。また、一度に数千以上のベクトルを検索する必要がないため、検索は常に安価かつ高速になります。
エッジアプリの構築
エッジで実行するアプリケーションは、いくつかの種類のリクエストを処理する必要があります:
- HTML ページ: これらをmetmuseum.orgから取得し、応答を変換して追加のフロントエンド
- これらの追加タグによって参照される Fastly スクリプトおよびスタイル リソース。エッジ アプリのバイナリから直接提供できます。
- レコメンダー エンドポイント。レコメンデーションを生成して返します。 ** その他すべての (非 HTML) リクエスト: 画像、メトロポリタン美術館独自のスクリプトとスタイルシート。これらは変更せずにドメインから直接プロキシされます。
最初はこのアプリを JavaScript で構築しましたが、即時距離での HNSW 実装が気に入ったため、最終的にレコメンダー部分を Rust に移植しました。
クライアント側の JavaScript はいくつかの興味深いことを行います:
- IntersectionObserver を使用して、ユーザーがページを関連オブジェクト セクションまで下にスクロールしたときにイベントをトリガーします。これは、onscroll のような古いメソッドを使用するよりもはるかに優れた非常に効率的な API です。
- 特別な推奨事項 API エンドポイントへのフェッチを行います (その後、エッジで処理してオブジェクト情報を返すことができます)
- クライアント側関数に組み込まれたテンプレートを使用して HTML を作成する
- その HTML をページに追加し、交差オブザーバーを新しい要素に移動します。これにより、推奨事項をスクロールすると、さらに読み込みが続けられます。
この方法では、レコメンデーション アルゴリズムを呼び出すことなくメインの HTML ペイロードを配信できますが、レコメンデーションはスクロールしながら読み込むことができるほど高速に配信されるため、レコメンデーションに到達するまでにほぼ確実に表示されます。
私はこの方法で物事を進めるのが好きです。なぜなら、最初のスクロールせずに見えるビューをできるだけ早くユーザーに届けることが最も重要だからです。 スクロールしないと表示されないものは、後で読み込むことができます。特にそれがパーソナライズされたコンテンツの複雑な部分である場合、ユーザーがスクロールする予定がなければ、生成しても意味がありません。
最後に
これで、両方の長所を利用できるようになりました。オリジンへのブロッキングフェッチをほとんど必要とせずに、高度にパーソナライズされたコンテンツを提供できる機能と、信じられないほど高速にレンダリングされる最適化された HTML ペイロードにより、アプリケーションは効果的に無限のスケーラビリティを享受できるようになります。完璧な回復力。
それは完璧な解決策ではありません。 Fastly が、単純なキー検索以外のクエリ メカニズムを介してエッジ データを公開するためのより高レベルの機能を提供できれば素晴らしいと思います (それが役立つ場合はお知らせください!)。この特定のメカニズムには明らかな欠陥があります。 2 つ以上の非常に異なるもの (19 世紀の油絵と古代ローマのアンフォラなど) については、それらの間の理論的な意味の「中間点」となる推奨事項が得られますが、あまり有用な結果ではありません。
それでも、これが、エッジで作業を行う方法を理解すると、スケーラビリティ、パフォーマンス、回復力の点で大きなメリットが得られることが多いという原則を示していると幸いです。
community.fastly.com で何を構築したか教えてください!
-
 フォームリフレッシュ後に重複した提出を防ぐ方法は?を更新することで重複した提出を防ぐ Web開発で、フォームの提出後にページが更新された場合に重複した提出の問題に遭遇することが一般的です。これに対処するには、次のアプローチを検討してください。 if(isset($ _ post ['name'])){ ...プログラミング 2025-05-01に投稿
フォームリフレッシュ後に重複した提出を防ぐ方法は?を更新することで重複した提出を防ぐ Web開発で、フォームの提出後にページが更新された場合に重複した提出の問題に遭遇することが一般的です。これに対処するには、次のアプローチを検討してください。 if(isset($ _ post ['name'])){ ...プログラミング 2025-05-01に投稿 -
匿名のJavaScriptイベントハンドラーをきれいに削除する方法は?匿名イベントリスナーを削除する]イベントリスナーを追加する要素を追加すると、柔軟性とシンプルさを提供しますが、要素自体を置き換えることなく挑戦をもたらすことができます。 element? element.addeventlistener(event、function(){/はここで動作し...プログラミング 2025-05-01に投稿
-
ChatBotコマンドの実行のためにリアルタイムでstdoutをキャプチャしてストリーミングする方法は?コマンド実行からリアルタイムでstdoutをキャプチャする 再起動のライン(コマンド): print(line) このコードでは、subprocess.popen()関数を使用して指定されたコマンドを実行します。 stdoutパラメーターは、subprocess....プログラミング 2025-05-01に投稿
-
formdata()で複数のファイルアップロードを処理するにはどうすればよいですか?formdata() を使用して複数のファイルアップロードを処理すると、複数のファイルアップロードを処理する必要があることがよくあります。 fd.append("fileToUpload[]", files[x]);メソッドはこの目的に使用でき、単一のリクエストで複数...プログラミング 2025-05-01に投稿
-
Laravel Bladeテンプレートの変数をエレガントに定義するにはどうすればよいですか?Laravel Bladeテンプレートの変数を優雅さで定義する ブレードテンプレートに変数を割り当てる方法を理解することは、後で使用するためにデータを保存するために重要です。 「{{{{}}}」を使用して変数を割り当てるのは簡単ですが、常に最もエレガントなソリューションであるとは限りませ...プログラミング 2025-05-01に投稿
-
編集可能なDivをテキストボックススタイルに設計する方法は?編集可能なdivを作成するテキストフィールド が多い場合、ユーザーが編集可能なDivを使用してWebページの特定のセクションを編集できるようにすることが望ましい場合があります。ただし、Div Elementsは自然に編集可能性を示す視覚的な手がかりを欠いており、ユーザーが自分と対話できるか...プログラミング 2025-05-01に投稿
-
AndroidはどのようにPHPサーバーに投稿データを送信しますか?をAndroid に送信します。これは、サーバー側の通信を扱う際の一般的なシナリオです。 apache httpclient(deprecated) httpclient httpclient = new defulthttpclient(); httppost httppost ...プログラミング 2025-05-01に投稿
-
Python Metaclass作業原則とクラスの作成とカスタマイズPythonのメタクラスとは?クラスがインスタンスを作成するのと同じように、Metaclassはクラスを作成します。クラスの作成プロセスを制御する層を提供し、クラスの動作と属性のカスタマイズを可能にします。これは、クラス自体がクラスキーワードを使用してクラスの「説明」から作成されたインスタン...プログラミング 2025-05-01に投稿
-
PHP Future:適応と革新PHPの将来は、新しいテクノロジーの傾向に適応し、革新的な機能を導入することで達成されます。1)クラウドコンピューティング、コンテナ化、マイクロサービスアーキテクチャに適応し、DockerとKubernetesをサポートします。 2)パフォーマンスとデータ処理の効率を改善するために、JITコンパイ...プログラミング 2025-05-01に投稿
-
PostgreSQLの各一意の識別子の最後の行を効率的に取得するにはどうすればよいですか?postgresql:各一意の識別子の最後の行 を抽出します。次のデータを検討してください: select distinct on (id) id, date, another_info from the_table order by id, date desc; データセット内の一...プログラミング 2025-05-01に投稿
-
ubuntu/linuxにmysql-pythonをインストールするときに\ "mysql_configが見つかりません\"エラーを修正する方法は?mysql-pythonインストールエラー: "mysql_config not obst" をubuntu/linuxボックスにインストールしようとする試みを試みます。このエラーは、MySQL開発ライブラリが欠落しているために発生します。 この問題を解決するには、...プログラミング 2025-05-01に投稿
-
PHPで空の配列を効率的に検出する方法は?チェックアレイ空虚のphp の空の配列は、さまざまなアプローチを通じてPHPで決定できます。アレイ要素の存在を確認する必要がある場合、PHPのルーズタイピングにより、配列自体の直接評価が可能になります。 //リストは空です。 } if (!$playerlist) { ...プログラミング 2025-05-01に投稿
-
GOコンパイラでコンパイルの最適化をカスタマイズするにはどうすればよいですか?goコンパイラ のコンピレーション最適化のカスタマイズGOのデフォルトのコンパイルプロセスは、特定の最適化戦略に従います。ただし、ユーザーは特定の要件に対してこれらの最適化を調整する必要がある場合があります。これは、コンパイラが事前に定義されたヒューリスティックに基づいて最適化を自動的に...プログラミング 2025-05-01に投稿
-
CSSフォント属性が定義されていないときに、JavaScriptで実際のレンダリングされたフォントを取得するにはどうすればよいですか?css javascript object.style.fontfamily and object.style.style.style.style.styles fort not not not not not not not not not not not not not not ...プログラミング 2025-05-01に投稿
-
PHPを使用してBlob(画像)をMySQLに適切に挿入する方法は?php mysqlデータベースを持つmysqlデータベースにブロブを挿入すると、mysqlデータベースに画像を保存しようとすると、遭遇するかもしれません問題。このガイドは、画像データを正常に保存するためのソリューションを提供します。 ImageId、image) values( &...プログラミング 2025-05-01に投稿















中国語を勉強する
- 1 「歩く」は中国語で何と言いますか? 走路 中国語の発音、走路 中国語学習
- 2 「飛行機に乗る」は中国語で何と言いますか? 坐飞机 中国語の発音、坐飞机 中国語学習
- 3 「電車に乗る」は中国語で何と言いますか? 坐火车 中国語の発音、坐火车 中国語学習
- 4 「バスに乗る」は中国語で何と言いますか? 坐车 中国語の発音、坐车 中国語学習
- 5 中国語でドライブは何と言うでしょう? 开车 中国語の発音、开车 中国語学習
- 6 水泳は中国語で何と言うでしょう? 游泳 中国語の発音、游泳 中国語学習
- 7 中国語で自転車に乗るってなんて言うの? 骑自行车 中国語の発音、骑自行车 中国語学習
- 8 中国語で挨拶はなんて言うの? 你好中国語の発音、你好中国語学習
- 9 中国語でありがとうってなんて言うの? 谢谢中国語の発音、谢谢中国語学習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









