
AI/ML とアダプティブ アナリティクス ソリューションの橋渡し
 ブラウズ:599
ブラウズ:599
今日のデータ環境では、企業はさまざまな課題に直面しています。その 1 つは、すべての消費者が利用できる、統合され調和されたデータ層上で分析を行うことです。使用されている方言やツールに関係なく、同じ質問に対して同じ回答を提供できるレイヤー。
InterSystems IRIS Data Platform は、この統合されたセマンティック レイヤーを提供できる Adaptive Analytics のアドオンによってその問題に答えます。 DevCommunity には、BI ツール経由での使用に関する記事がたくさんあります。この記事では、AI を使用してそれを活用する方法と、洞察を元に戻す方法について説明します。
一歩ずつ進んでいきましょう...
アダプティブ アナリティクスとは何ですか?
開発者コミュニティ Web サイトで定義を簡単に見つけることができます
一言で言えば、データを構造化され調和された形式で、選択したさまざまなツールに配信して、さらなる利用と分析を行うことができます。同じデータ構造をさまざまな BI ツールに提供します。しかし...同じデータ構造を AI/ML ツールに提供することもできます!
アダプティブ アナリティクスには、AI から BI への橋渡しをする AI-Link と呼ばれる追加コンポーネントがあります。
AI-Link とは何ですか?
これは、機械学習 (ML) ワークフローの主要な段階 (特徴エンジニアリングなど) を合理化する目的で、セマンティック レイヤーとのプログラムによる対話を可能にするように設計された Python コンポーネントです。
AI-Link を使用すると、次のことができます:
- 分析データ モデルの機能にプログラムでアクセスします;
- クエリを作成し、ディメンションとメジャーを調べます;
- ML パイプラインをフィードします。 ...結果をセマンティック レイヤーに返し、他のユーザー (Tableau や Excel など) で再度利用できるようにします。
Pythonライブラリなので、どのPython環境でも使用できます。ノートブックを含む。
この記事では、AI-Link を利用して Jupyter Notebook から Adaptive Analytics ソリューションに到達する簡単な例を示します。
これは、例として完全なノートブックを含む git リポジトリです: https://github.com/v23ent/aa-hands-on
前提条件
これ以降の手順は、次の前提条件が完了していることを前提としています。
- Adaptive Analytics ソリューションが稼働中 (データ ウェアハウスとして IRIS Data Platform を使用)
- Jupyter Notebook が稼働中
- 1.と2.の間の接続が確立できます
ステップ 1: セットアップ
まず、必要なコンポーネントを環境にインストールしましょう。これにより、以降の手順を実行するために必要ないくつかのパッケージがダウンロードされます。
'atscale' - これは接続するメインのパッケージです
'prophet' - 予測を行うために必要なパッケージ
pip install atscale prophet
次に、セマンティック レイヤーのいくつかの主要な概念を表す主要なクラスをインポートする必要があります。
Client - Adaptive Analytics への接続を確立するために使用するクラス;
Project - Adaptive Analytics 内のプロジェクトを表すクラス。
DataModel - 仮想キューブを表すクラス;
from atscale.client import Client from atscale.data_model import DataModel from atscale.project import Project from prophet import Prophet import pandas as pd
ステップ 2: 接続
これで、データ ソースへの接続を確立する準備が整いました。
client = Client(server='http://adaptive.analytics.server', username='sample') client.connect()
Adaptive Analytics インスタンスの接続の詳細を指定してください。組織を尋ねられたら、ダイアログ ボックスに応答し、AtScale インスタンスからのパスワードを入力してください。
接続が確立されたら、サーバー上で公開されているプロジェクトのリストからプロジェクトを選択する必要があります。プロジェクトのリストが対話型プロンプトとして表示され、その答えはプロジェクトの整数 ID になります。そして、データ モデルが唯一の場合は自動的に選択されます。
project = client.select_project() data_model = project.select_data_model()
ステップ 3: データセットを探索する
AI-Link コンポーネント ライブラリには AtScale が用意したメソッドが多数あります。これらを使用すると、所有しているデータ カタログを探索したり、データをクエリしたり、一部のデータを取り込んだりすることもできます。 AtScale のドキュメントには、利用可能なものすべてを説明する広範な API リファレンスが含まれています。
まず、data_model:
data_model.get_features() data_model.get_all_categorical_feature_names() data_model.get_all_numeric_feature_names()
出力は次のようになります
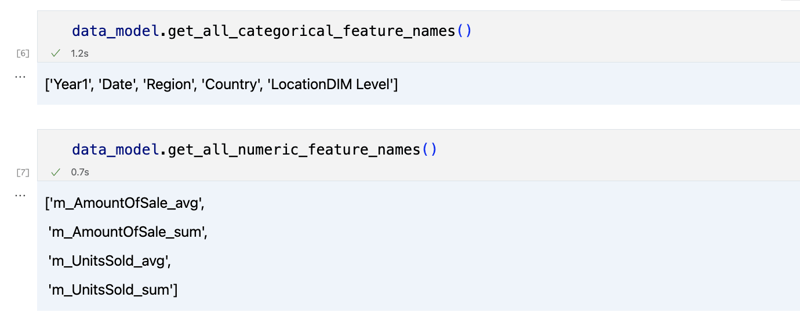
少し見て回ったら、「get_data」メソッドを使用して、関心のある実際のデータをクエリできます。クエリ結果を含むパンダ データフレームが返されます。
df = data_model.get_data(feature_list = ['Country','Region','m_AmountOfSale_sum']) df = df.sort_values(by='m_AmountOfSale_sum') df.head()
データドラマが表示されます:
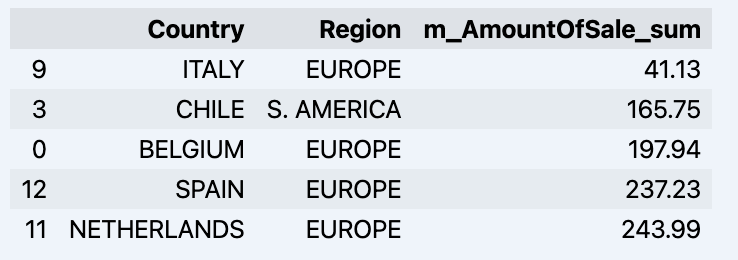
データセットを準備して、グラフにすぐに表示しましょう
import matplotlib.pyplot as plt
# We're taking sales for each date
dataframe = data_model.get_data(feature_list = ['Date','m_AmountOfSale_sum'])
# Create a line chart
plt.plot(dataframe['Date'], dataframe['m_AmountOfSale_sum'])
# Add labels and a title
plt.xlabel('Days')
plt.ylabel('Sales')
plt.title('Daily Sales Data')
# Display the chart
plt.show()
出力:
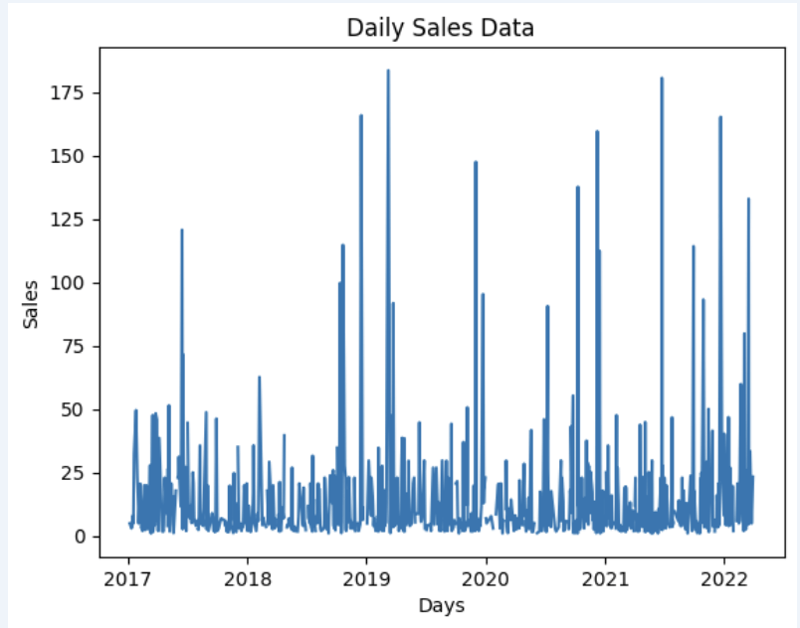
ステップ 4: 予測
次のステップは、実際に AI-Link ブリッジから何らかの値を取得することです - 簡単な予測をしてみましょう!
# Load the historical data to train the model
data_train = data_model.get_data(
feature_list = ['Date','m_AmountOfSale_sum'],
filter_less = {'Date':'2021-01-01'}
)
data_test = data_model.get_data(
feature_list = ['Date','m_AmountOfSale_sum'],
filter_greater = {'Date':'2021-01-01'}
)
ここでは、モデルのトレーニングとテストのために、2 つの 異なる データセットを取得します。
# For the tool we've chosen to do the prediction 'Prophet', we'll need to specify 2 columns: 'ds' and 'y'
data_train['ds'] = pd.to_datetime(data_train['Date'])
data_train.rename(columns={'m_AmountOfSale_sum': 'y'}, inplace=True)
data_test['ds'] = pd.to_datetime(data_test['Date'])
data_test.rename(columns={'m_AmountOfSale_sum': 'y'}, inplace=True)
# Initialize and fit the Prophet model
model = Prophet()
model.fit(data_train)
そして、予測に対応する別のデータフレームを作成し、グラフに表示します
# Create a future dataframe for forecasting future = pd.DataFrame() future['ds'] = pd.date_range(start='2021-01-01', end='2021-12-31', freq='D') # Make predictions forecast = model.predict(future) fig = model.plot(forecast) fig.show()
出力:
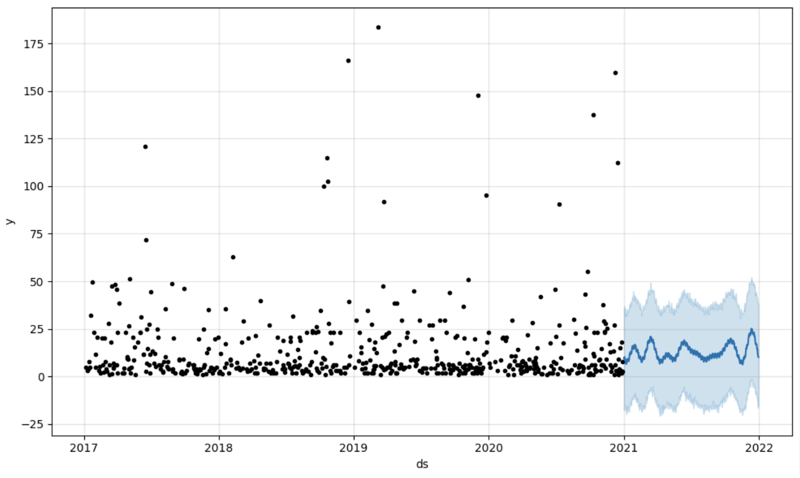
ステップ 5: ライトバック
予測を適切に設定したら、それをデータ ウェアハウスに戻し、セマンティック モデルに集計を追加して、他の消費者に反映できます。この予測は、BI アナリストやビジネス ユーザーにとって、他の BI ツールを通じて利用できます。
予測自体はデータ ウェアハウスに配置され、そこに保存されます。
from atscale.db.connections import Iris
db = Iris(
username,
host,
namespace,
driver,
schema,
port=1972,
password=None,
warehouse_id=None
)data_model.writeback(dbconn=db,
table_name= 'SalesPrediction',
DataFrame = forecast)data_model.create_aggregate_feature(dataset_name='SalesPrediction',
column_name='SalesForecasted',
name='sum_sales_forecasted',
aggregation_type='SUM')
フィン
それです!
あなたの予想がうまくいきますように!
-
 MySQL を使用して今日が誕生日のユーザーを見つけるにはどうすればよいですか?MySQL を使用して今日の誕生日を持つユーザーを識別する方法MySQL を使用して今日がユーザーの誕生日かどうかを判断するには、誕生日が一致するすべての行を検索する必要があります。今日の日付。これは、UNIX タイムスタンプとして保存されている誕生日と今日の日付を比較する単純な MySQL クエリ...プログラミング 2024 年 11 月 15 日に公開
MySQL を使用して今日が誕生日のユーザーを見つけるにはどうすればよいですか?MySQL を使用して今日の誕生日を持つユーザーを識別する方法MySQL を使用して今日がユーザーの誕生日かどうかを判断するには、誕生日が一致するすべての行を検索する必要があります。今日の日付。これは、UNIX タイムスタンプとして保存されている誕生日と今日の日付を比較する単純な MySQL クエリ...プログラミング 2024 年 11 月 15 日に公開 -
Go で WebSocket を使用してリアルタイム通信を行うチャット アプリケーション、ライブ通知、共同作業ツールなど、リアルタイムの更新が必要なアプリを構築するには、従来の HTTP よりも高速でインタラクティブな通信方法が必要です。そこで WebSocket が登場します。今日は、アプリケーションにリアルタイム機能を追加できるように、Go で WebSo...プログラミング 2024 年 11 月 15 日に公開
-
**インデックスを無効にせずに InnoDB での一括挿入を最適化する方法**InnoDB での最適化された一括挿入のインデックスを無効にする一括挿入のパフォーマンスを向上させるために InnoDB テーブルのインデックスを無効にしようとすると、次のような問題が発生する可能性があります。 InnoDB のストレージ エンジンにはこの機能がないため、警告が表示されます。目的を達...プログラミング 2024 年 11 月 15 日に公開
-
「if」ステートメントを超えて: 明示的な「bool」変換を伴う型をキャストせずに使用できる場所は他にありますか?キャストなしで bool へのコンテキスト変換が可能クラスは bool への明示的な変換を定義し、そのインスタンス 't' を条件文で直接使用できるようにします。ただし、この明示的な変換では、キャストなしで bool として 't' を使用できる場所はどこですか?コン...プログラミング 2024 年 11 月 15 日に公開
-
一意の ID を保持し、重複した名前を処理しながら、PHP で 2 つの連想配列を結合するにはどうすればよいですか?PHP での連想配列の結合PHP では、2 つの連想配列を 1 つの配列に結合するのが一般的なタスクです。次のリクエストを考えてみましょう:問題の説明:提供されたコードは 2 つの連想配列 $array1 と $array2 を定義します。目標は、両方の配列のすべてのキーと値のペアを統合する新しい配...プログラミング 2024 年 11 月 15 日に公開
-
命令的アプローチを使用して React のネストされた状態を更新するにはどうすればよいですか?ネストされた状態を更新するための命令的アプローチReact では、状態の更新は不変です。これは、ネストされたオブジェクトまたは配列を更新する場合、そのプロパティを変更するだけでは、その変更が UI に反映されることを期待できないことを意味します。代わりに、更新された値を含む新しいオブジェクトまたは配...プログラミング 2024 年 11 月 14 日公開
-
アトミック変数のさまざまなメモリ順序モデルとは何ですか?メモリ順序の意味を理解するアトミック変数は、スレッド間での安全なメモリ アクセスと同期を提供します。さまざまなメモリの順序を効果的に利用するには、これらの順序を理解することが重要です。リラックス:メモリ同期なし。順序が変更される可能性がある最適化された操作読み取りと書き込み。順次一貫性(seq_cs...プログラミング 2024 年 11 月 14 日公開
-
For ループ内で return ステートメントを間違えると入力ループに影響するのはなぜですか?For ループ内の Return ステートメントの配置が間違っています課題で、目的にもかかわらず、プログラムが 1 匹のペットの入力しか許可しないという問題が発生しました。 3人分。この問題は、make_list 関数内の return ステートメントの位置に起因します。for ループ内では、ret...プログラミング 2024 年 11 月 14 日公開
-
macOS 上の Django で「ImproperlyConfigured: MySQLdb モジュールのロード中にエラーが発生しました」を修正する方法?MySQL の不適切な構成: 相対パスの問題Django で python manage.py runserver を実行すると、次のエラーが発生する場合があります:ImproperlyConfigured: Error loading MySQLdb module: dlopen(/Library...プログラミング 2024 年 11 月 14 日公開
-
ユーザーがブートストラップ モーダルを閉じないようにするにはどうすればよいですか?ユーザーによるブートストラップ モーダルの終了を無効にするユーザーが領域外をクリックしてブートストラップ モーダルを閉じることを防止できます。これは、続行する前にユーザーに特定のモーダル コンテンツの操作を強制したい場合に便利です。モーダル背景クリック時の終了を無効にするデフォルトでは、ユーザーは次...プログラミング 2024 年 11 月 14 日公開
-
Python でネストされたリストを CSV ファイルにエクスポートするには?Python でネストされたリストを CSV ファイルにエクスポートする各内部リストに異なるタイプの要素が含まれるネストされたリストを CSV ファイルに書き込むと、次のことが可能になります。 Python でデータを操作する場合の一般的なタスクです。この課題に取り組む方法は次のとおりです。Pyth...プログラミング 2024 年 11 月 14 日公開
-
Go スライスの最後の要素を効率的に抽出するにはどうすればよいですか?スライスの最後の要素を抽出するための Go の最良のアプローチGo でスライスを操作する場合、要素を効率的に操作することが重要です。一般的なタスクの 1 つは最後の要素を抽出することですが、これはさまざまな方法で実現できます。既存のソリューションの欠点slice[len(slice)-1 を使用した...プログラミング 2024 年 11 月 14 日公開
-
動的要素の追加後に JavaScript イベントがトリガーされないのはなぜですか?動的要素の追加後に JavaScript イベントがトリガーされないDOM に新しい要素を追加した後に JavaScript イベントが起動しないという問題が発生しています。 。これは、jQuery がページの読み込み中に最初に実行されるときに存在する要素のみを認識するためです。これを解決するには、...プログラミング 2024 年 11 月 14 日公開
-
`unshift()` は JavaScript で要素を配列の先頭に追加する最も効率的な方法ですか?JavaScript での最適な配列の先頭への追加配列の先頭に要素を先頭に追加することは、JavaScript における一般的な要件です。ここでは、質問で提案されている従来の方法よりも優れたアプローチを検討します。Unshift メソッド: ネイティブ ソリューションJavaScript には、un...プログラミング 2024 年 11 月 14 日公開
-
JavaScript でコンストラクターを介してメソッドを定義すると、関数のコピーが重複して作成されますか?JavaScript でのプロトタイプとコンストラクターによるメソッド定義のパフォーマンスへの影響JavaScript では、パブリック関数を使用して「クラス」を作成するための 2 つのアプローチが存在します。プロトタイプまたはコンストラクターを使用します。方法 1 はコンストラクターを通じてインス...プログラミング 2024 年 11 月 14 日公開















中国語を勉強する
- 1 「歩く」は中国語で何と言いますか? 走路 中国語の発音、走路 中国語学習
- 2 「飛行機に乗る」は中国語で何と言いますか? 坐飞机 中国語の発音、坐飞机 中国語学習
- 3 「電車に乗る」は中国語で何と言いますか? 坐火车 中国語の発音、坐火车 中国語学習
- 4 「バスに乗る」は中国語で何と言いますか? 坐车 中国語の発音、坐车 中国語学習
- 5 中国語でドライブは何と言うでしょう? 开车 中国語の発音、开车 中国語学習
- 6 水泳は中国語で何と言うでしょう? 游泳 中国語の発音、游泳 中国語学習
- 7 中国語で自転車に乗るってなんて言うの? 骑自行车 中国語の発音、骑自行车 中国語学習
- 8 中国語で挨拶はなんて言うの? 你好中国語の発音、你好中国語学習
- 9 中国語でありがとうってなんて言うの? 谢谢中国語の発音、谢谢中国語学習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









