
अपने डेटा को समझना: खोजपूर्ण डेटा विश्लेषण की अनिवार्यताएँ।
 ब्राउज़ करें:177
ब्राउज़ करें:177
परिचय
मशीन लर्निंग मॉडल, विज़ुअलाइज़ेशन के विकास और उपयोगकर्ता के अनुकूल अनुप्रयोगों के समावेश के परिणामस्वरूप आपके डेटा के बारे में आपके अंतिम लक्ष्य के आधार पर, प्रोजेक्ट की शुरुआत में डेटा में प्रवाह विकसित करने से अंतिम सफलता मिलेगी।
ईडीए की अनिवार्यताएं
यहीं पर हमें यह सीखने को मिलता है कि डेटा प्रीप्रोसेसिंग की आवश्यकता डेटा विश्लेषकों के लिए कैसे फायदेमंद है।
विशालता और विभिन्न स्रोतों के कारण आज का डेटा असामान्य होने की अधिक संभावना है। डेटा की प्रीप्रोसेसिंग डेटा विज्ञान के क्षेत्र में आधारभूत चरण बन गई है क्योंकि उच्च गुणवत्ता वाले डेटा के परिणामस्वरूप अधिक मजबूत मॉडल और भविष्यवाणियां होती हैं।
खोजपूर्ण डेटा विश्लेषण एक डेटा वैज्ञानिक का उपकरण है जो यह देखता है कि डेटा औपचारिक मॉडलिंग या धारणा परीक्षण कार्य के बाहर क्या उजागर कर सकता है।
विश्वसनीय परिणाम सुनिश्चित करने और किसी भी प्रभावी परिणाम और उद्देश्यों पर लागू होने के लिए डेटा वैज्ञानिक को हमेशा ईडीए निष्पादित करना चाहिए। यह वैज्ञानिकों और विश्लेषकों को यह पुष्टि करने में भी सहायता करता है कि वे वांछित परिणाम प्राप्त करने के लिए उचित रास्ते पर हैं।
शोध प्रश्नों के कुछ उदाहरण जो अध्ययन का मार्गदर्शन करते हैं वे हैं:
1.क्या डेटा की प्रीप्रोसेसिंग का कोई महत्वपूर्ण प्रभाव है
विश्लेषण दृष्टिकोण - सटीक डेटा विश्लेषण परिणामों पर लापता मान, मूल्यों का समुच्चय, डेटा फ़िल्टरिंग, आउटलेयर, परिवर्तनीय परिवर्तन और परिवर्तनीय कमी?
2। अनुसंधान अध्ययनों में प्रीप्रोसेसिंग डेटा विश्लेषण किस महत्वपूर्ण स्तर पर आवश्यक है?
खोजपूर्ण डेटा विश्लेषण मेट्रिक्स और उनका महत्व
1.डेटा फ़िल्टरिंग
यह डेटासेट के एक छोटे हिस्से को चुनने और देखने या विश्लेषण के लिए उस सबसेट का उपयोग करने की प्रथा है। पूरा डेटा सेट रखा जाता है, लेकिन गणना के लिए इसका केवल एक सबसेट उपयोग किया जाता है; फ़िल्टरिंग आमतौर पर एक अस्थायी प्रक्रिया है. अध्ययन से ग़लत, गलत, या घटिया टिप्पणियों की खोज करना, किसी विशिष्ट रुचि समूह के लिए डेटा निकालना, या किसी विशिष्ट अवधि के लिए जानकारी की तलाश करना, सभी को फ़िल्टर का उपयोग करके सारांशित किया जा सकता है। अध्ययन के लिए मामले निकालने के लिए डेटा वैज्ञानिक को फ़िल्टरिंग के दौरान एक नियम या तर्क निर्दिष्ट करना होगा।
2.डेटा एकत्रीकरण
डेटा एकत्रीकरण के लिए असंसाधित डेटा को एक ही स्थान पर एकत्र करना और उसे विश्लेषण के लिए सारांशित करना आवश्यक है। डेटा एकत्रीकरण डेटा के सूचनात्मक, व्यावहारिक और उपयोग योग्य मूल्य को बढ़ाता है। वाक्यांश को परिभाषित करने के लिए अक्सर तकनीकी उपयोगकर्ता के दृष्टिकोण का उपयोग किया जाता है। डेटा एकत्रीकरण एक विश्लेषक या इंजीनियर के उदाहरण में कई डेटाबेस या डेटा स्रोतों से असंसाधित डेटा को एक केंद्रीकृत डेटाबेस में एकीकृत करने की प्रक्रिया है। फिर कच्चे डेटा को मिलाकर समग्र संख्याएँ बनाई जाती हैं। योग या औसत कुल मूल्य का सीधा-सीधा चित्रण है। एकत्रित डेटा का उपयोग विश्लेषण, रिपोर्टिंग, डैशबोर्डिंग और अन्य डेटा उत्पादों में किया जाता है। डेटा एकत्रीकरण उत्पादकता, निर्णय लेने और अंतर्दृष्टि के लिए समय बढ़ा सकता है।
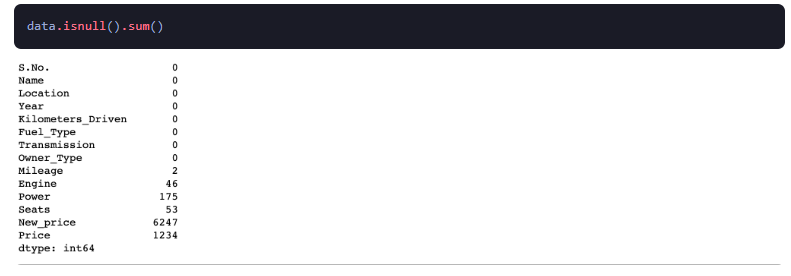
3.अनुपलब्ध डेटा
डेटा एनालिटिक्स में, गायब मान गायब होने का दूसरा नाम है
डेटा। यह तब होता है जब विशिष्ट चर या उत्तरदाताओं को छोड़ दिया जाता है या छोड़ दिया जाता है। गलत डेटा प्रविष्टि, खोई हुई फ़ाइलें, या टूटी हुई तकनीक के कारण चूक हो सकती है। डेटा गुम होने से उनके प्रकार के आधार पर रुक-रुक कर मॉडल पूर्वाग्रह हो सकता है, जो उन्हें समस्याग्रस्त बना देता है। गुम डेटा का तात्पर्य यह है कि चूंकि डेटा कभी-कभी भ्रामक नमूने से आया हो सकता है, परिणाम केवल अध्ययन के मापदंडों के भीतर सामान्यीकरण योग्य हो सकते हैं। संपूर्ण डेटासेट में एकरूपता सुनिश्चित करने के लिए, सभी लापता मानों को "एन/ए" ("लागू नहीं" का संक्षिप्त रूप) के लेबल के साथ फिर से कोड करना आवश्यक है।
4.डेटा परिवर्तन
डेटा को किसी फ़ंक्शन या अन्य गणितीय का उपयोग करके पुन: स्केल किया जाता है
परिवर्तन के दौरान प्रत्येक अवलोकन पर संचालन। हम
जब यह
हो तो इसे मॉडल करना आसान बनाने के लिए कभी-कभी डेटा को बदल दें
बहुत महत्वपूर्ण रूप से तिरछा है (या तो सकारात्मक या नकारात्मक)।
दूसरे शब्दों में, किसी को पैरामीट्रिक सांख्यिकीय परीक्षण लागू करने की धारणा के अनुरूप डेटा परिवर्तन का प्रयास करना चाहिए यदि
चर(वेरिएबल्स) सामान्य वितरण में फिट नहीं होते हैं। सबसे लोकप्रिय डेटा परिवर्तन लॉग (या प्राकृतिक लॉग) है, जिसका उपयोग अक्सर तब किया जाता है जब सभी अवलोकन सकारात्मक होते हैं, और डेटा सेट में अधिक महत्वपूर्ण मानों के संबंध में अधिकांश डेटा मान शून्य के आसपास क्लस्टर होते हैं।

आरेख चित्रण
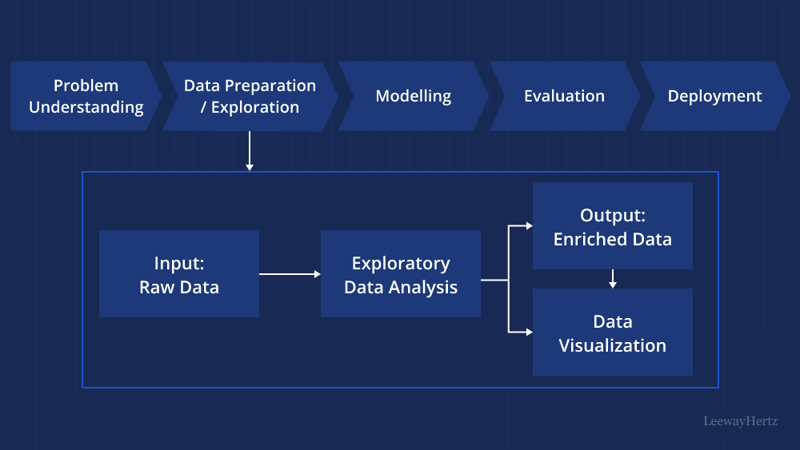
ईडीए में विज़ुअलाइज़ेशन तकनीक
विज़ुअलाइज़ेशन तकनीक ईडीए में एक आवश्यक भूमिका निभाती है, जो हमें जटिल डेटा संरचनाओं और संबंधों को दृष्टिगत रूप से तलाशने और समझने में सक्षम बनाती है। ईडीए में उपयोग की जाने वाली कुछ सामान्य विज़ुअलाइज़ेशन तकनीकें हैं:
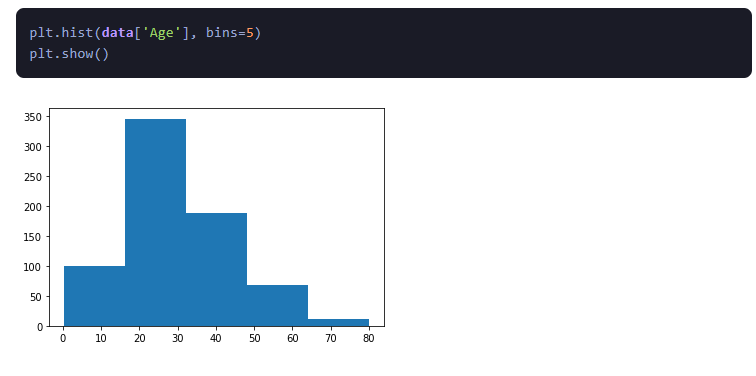
1.हिस्टोग्राम:
हिस्टोग्राम ग्राफिकल निरूपण हैं जो संख्यात्मक चर के वितरण को दर्शाते हैं। वे आवृत्ति वितरण की कल्पना करके डेटा की केंद्रीय प्रवृत्ति और प्रसार को समझने में मदद करते हैं।
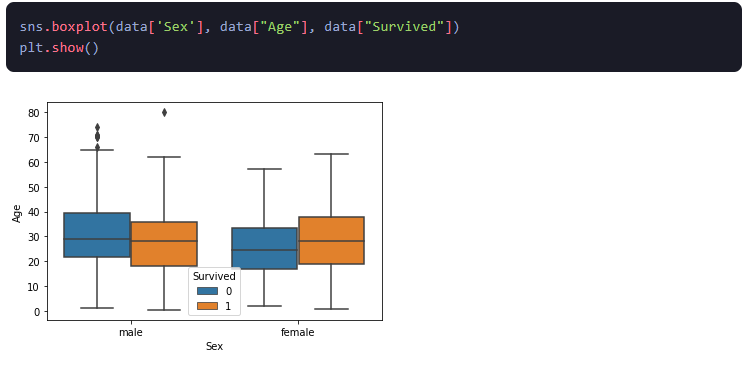
2.बॉक्सप्लॉट: बॉक्सप्लॉट एक ग्राफ़ है जो संख्यात्मक चर का वितरण दिखाता है। यह विज़ुअलाइज़ेशन तकनीक किसी भी आउटलेर की पहचान करने और उसके चतुर्थक को विज़ुअलाइज़ करके डेटा के प्रसार को समझने में मदद करती है।
3.हीटमैप्स: वे डेटा का ग्राफिकल प्रतिनिधित्व हैं जिसमें रंग मूल्यों का प्रतिनिधित्व करते हैं। इनका उपयोग अक्सर जटिल डेटा सेट प्रदर्शित करने के लिए किया जाता है, जो बड़ी मात्रा में डेटा में पैटर्न और रुझानों को देखने का त्वरित और आसान तरीका प्रदान करता है।
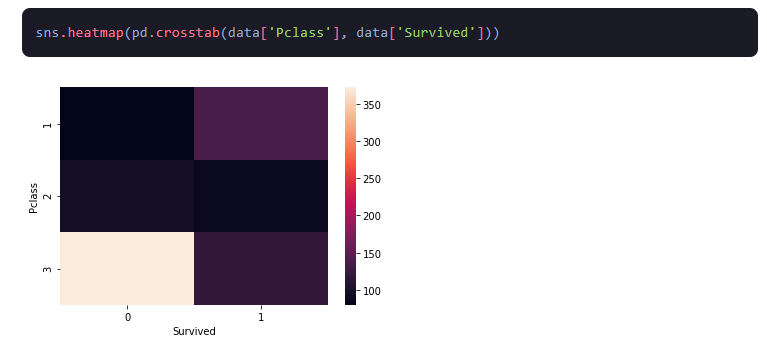
4.बार चार्ट: एक बार चार्ट एक ग्राफ है जो एक श्रेणीबद्ध चर का वितरण दिखाता है। इसका उपयोग डेटा के आवृत्ति वितरण को देखने के लिए किया जाता है, जो प्रत्येक श्रेणी की सापेक्ष आवृत्ति को समझने में मदद करता है।
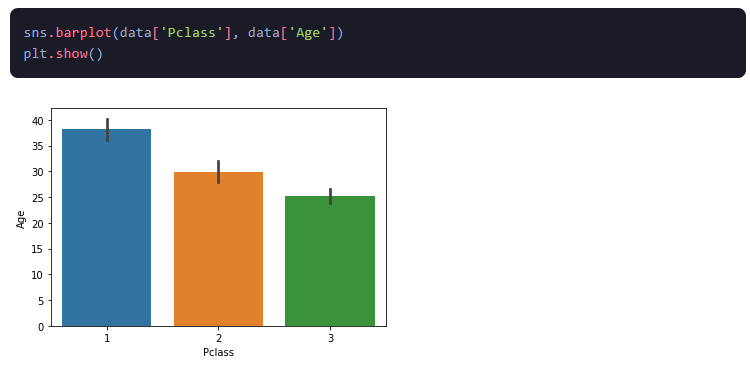
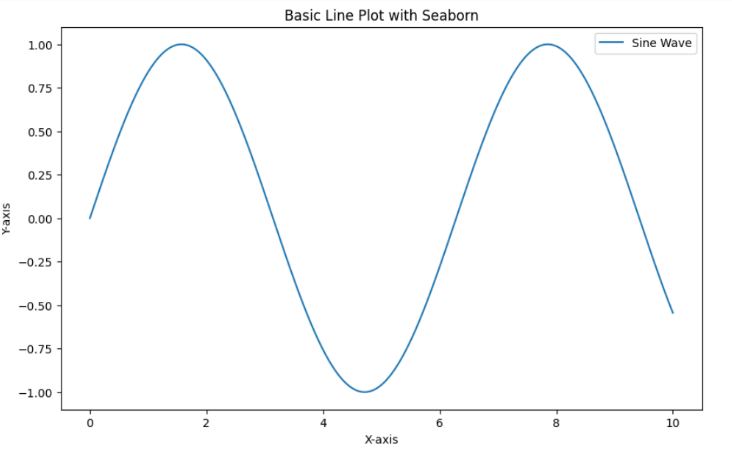
5.लाइन चार्ट: एक लाइन चार्ट एक ग्राफ है जो समय के साथ एक संख्यात्मक चर की प्रवृत्ति को दर्शाता है। इसका उपयोग समय के साथ डेटा में होने वाले परिवर्तनों को देखने और किसी पैटर्न या रुझान की पहचान करने के लिए किया जाता है।

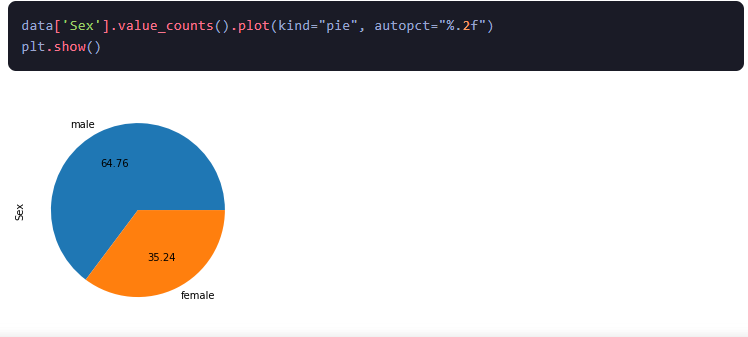
5.पाई चार्ट: पाई चार्ट एक ग्राफ है जो एक श्रेणीगत चर के अनुपात को दर्शाता है। इसका उपयोग प्रत्येक श्रेणी के सापेक्ष अनुपात को देखने और डेटा वितरण को समझने के लिए किया जाता है।
-
 जावा का मानचित्र कैसे है। एंट्री और सिंपलेंट्री कुंजी-मूल्य जोड़ी प्रबंधन को सरल बनाते हैं?] हालांकि, परिदृश्यों के लिए जहां तत्वों के क्रम को बनाए रखना महत्वपूर्ण है और विशिष्टता एक चिंता का विषय नहीं है, वहाँ एक मूल्यवान विकल्प है: जावा का...प्रोग्रामिंग 2025-07-08 पर पोस्ट किया गया
जावा का मानचित्र कैसे है। एंट्री और सिंपलेंट्री कुंजी-मूल्य जोड़ी प्रबंधन को सरल बनाते हैं?] हालांकि, परिदृश्यों के लिए जहां तत्वों के क्रम को बनाए रखना महत्वपूर्ण है और विशिष्टता एक चिंता का विषय नहीं है, वहाँ एक मूल्यवान विकल्प है: जावा का...प्रोग्रामिंग 2025-07-08 पर पोस्ट किया गया -
PHP का उपयोग करके MySQL में बूँदों (चित्र) को ठीक से कैसे डालें?] यह गाइड आपके छवि डेटा को सफलतापूर्वक संग्रहीत करने के लिए समाधान प्रदान करेगा। ImageStore (ImageId, Image) मान ('$ यह- & gt; image_id', ...प्रोग्रामिंग 2025-07-08 पर पोस्ट किया गया
-
दशमलव का उपयोग करके घातीय संकेतन में संख्या को कैसे पार्स करें।] ऐसा इसलिए है क्योंकि डिफ़ॉल्ट पार्सिंग विधि घातीय संकेतन को पहचान नहींती है। इस तरह के स्ट्रिंग को सफलतापूर्वक पार्स करने के लिए, आपको स्पष्ट रूप ...प्रोग्रामिंग 2025-07-08 पर पोस्ट किया गया
-
एक पांडस डेटाफ्रेम कॉलम को डेटटाइम प्रारूप में कैसे परिवर्तित करें और तिथि तक फ़िल्टर करें?] अस्थायी डेटा के साथ काम करते समय, टाइमस्टैम्प शुरू में तार के रूप में दिखाई दे सकते हैं, लेकिन सटीक विश्लेषण के लिए एक डेटाइम प्रारूप में परिवर्तित ...प्रोग्रामिंग 2025-07-08 पर पोस्ट किया गया
-
नीचे के दाईं ओर फ़्लोटिंग चित्रों के लिए टिप्स और पाठ के चारों ओर लपेटते हैं] यह छवि को प्रभावी ढंग से दिखाने के दौरान एक आकर्षक दृश्य प्रभाव पैदा कर सकता है। इस कंटेनर के भीतर, छवि के लिए पाठ सामग्री और एक IMG तत्व जोड़ें। HT...प्रोग्रामिंग 2025-07-08 पर पोस्ट किया गया
-
मैं पूरे HTML दस्तावेज़ में एक विशिष्ट तत्व प्रकार के पहले उदाहरण को कैसे स्टाइल कर सकता हूं?] : प्रथम-प्रकार के छद्म-क्लास अपने मूल तत्व के भीतर एक प्रकार के पहले तत्व से मेल खाने तक सीमित है। एक प्रकार का पहला तत्व, एक जावास्क्रिप्ट सम...प्रोग्रामिंग 2025-07-08 पर पोस्ट किया गया
-
`JSON` पैकेज का उपयोग करके जाने में JSON सरणियों को कैसे पार्स करें?उदाहरण: निम्नलिखित गो कोड पर विचार करें: सरणी [] स्ट्रिंग } func मुख्य () { datajson: = `[" 1 "," 2 "," 3 "...प्रोग्रामिंग 2025-07-08 पर पोस्ट किया गया
-
एक लेनदेन में कई MySQL तालिकाओं में डेटा को कुशलता से कैसे सम्मिलित करें?] हालांकि ऐसा लग सकता है कि कई प्रश्न समस्या को हल करेंगे, प्रोफ़ाइल तालिका के लिए मैनुअल यूजर आईडी के लिए उपयोगकर्ता तालिका से ऑटो-इनक्रेमेंट आईडी को...प्रोग्रामिंग 2025-07-08 पर पोस्ट किया गया
-
PHP में खाली सरणियों का कुशलता से कैसे पता लगाएं?] यदि आवश्यकता किसी भी सरणी तत्व की उपस्थिति को सत्यापित करने की है, तो PHP की ढीली टाइपिंग सरणी के प्रत्यक्ष मूल्यांकन के लिए ही अनुमति देती है: अग...प्रोग्रामिंग 2025-07-08 पर पोस्ट किया गया
-
गो में SQL प्रश्नों का निर्माण करते समय मैं सुरक्षित रूप से पाठ और मूल्यों को कैसे सहमत कर सकता हूं?] दृष्टिकोण जाने में मान्य नहीं है, और मापदंडों को कास्ट करने का प्रयास करने के लिए स्ट्रिंग्स के परिणामस्वरूप बेमेल त्रुटियां होती हैं। यह आपको रनटाइ...प्रोग्रामिंग 2025-07-08 पर पोस्ट किया गया
-
संस्करण 5.6.5 से पहले MySQL में टाइमस्टैम्प कॉलम के साथ current_timestamp का उपयोग करने पर क्या प्रतिबंध थे?] Current_timestamp क्लॉज। यह सीमा INT, BigInt, और SmallInt पूर्णांक को वापस बढ़ाती है जब उन्हें शुरू में 2008 में पेश किया गया था। यह सीमा विरासत क...प्रोग्रामिंग 2025-07-08 पर पोस्ट किया गया
-
बहु-आयामी सरणियों के लिए PHP में JSON पार्सिंग को सरल कैसे करें?] To simplify the process, it's recommended to parse the JSON as an array rather than an object.To do this, use the json_decode function with the ...प्रोग्रामिंग 2025-07-08 पर पोस्ट किया गया
-
क्यों isn \ 't मेरी css पृष्ठभूमि छवि दिखाई दे रही है?] छवि और स्टाइल शीट एक ही निर्देशिका में निवास कर रही है, फिर भी पृष्ठभूमि एक खाली सफेद कैनवास बनी हुई है। छवि को संलग्न करने वाले उद्धरण फ़ाइल नाम: ...प्रोग्रामिंग 2025-07-08 पर पोस्ट किया गया
-
अपने कंटेनर के भीतर एक DIV के लिए एक चिकनी बाएं-दाएं CSS एनीमेशन कैसे बनाएं?] इस एनीमेशन को किसी भी डिव को पूर्ण स्थिति के साथ लागू किया जा सकता है, चाहे इसकी अज्ञात लंबाई की परवाह किए बिना। ऐसा इसलिए है क्योंकि 100%पर, DIV की...प्रोग्रामिंग 2025-07-08 पर पोस्ट किया गया
-
PHP भविष्य: अनुकूलन और नवाचार] 2) प्रदर्शन और डेटा प्रोसेसिंग दक्षता में सुधार करने के लिए JIT संकलक और गणना प्रकारों का परिचय; 3) लगातार प्रदर्शन का अनुकूलन करें और सर्वोत्तम प्र...प्रोग्रामिंग 2025-07-08 पर पोस्ट किया गया















चीनी भाषा का अध्ययन करें
- 1 आप चीनी भाषा में "चलना" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 2 आप चीनी भाषा में "विमान ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 3 आप चीनी भाषा में "ट्रेन ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 4 आप चीनी भाषा में "बस ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 5 चीनी भाषा में ड्राइव को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 6 तैराकी को चीनी भाषा में क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 7 आप चीनी भाषा में साइकिल चलाने को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 8 आप चीनी भाषा में नमस्ते कैसे कहते हैं? 你好चीनी उच्चारण, 你好चीनी सीखना
- 9 आप चीनी भाषा में धन्यवाद कैसे कहते हैं? 谢谢चीनी उच्चारण, 谢谢चीनी सीखना
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









