
रास्पबेरी पाई पर एक डिस्कोर्ड बॉट चलाना
 ब्राउज़ करें:330
ब्राउज़ करें:330
अनस्प्लैश पर डैनियल टैफजॉर्ड द्वारा कवर फ़ोटो
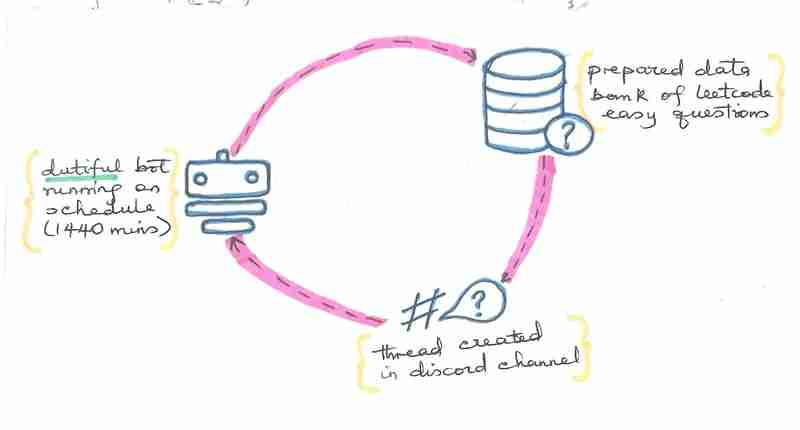
मैंने हाल ही में एक सॉफ्टवेयर इंजीनियरिंग बूटकैंप पूरा किया है, लीटकोड के आसान प्रश्नों पर काम करना शुरू किया है और मुझे लगा कि अगर मुझे प्रश्नों को हल करने के लिए दैनिक अनुस्मारक मिले तो इससे मुझे जवाबदेह बने रहने में मदद मिलेगी। मैंने इसे 24 घंटे के शेड्यूल पर चलने वाले एक डिसॉर्डर बॉट का उपयोग करके लागू करने का निर्णय लिया (बेशक, मेरे भरोसेमंद रास्पबेरी पाई पर) जो निम्नलिखित कार्य करेगा:
- आसान लेटकोड प्रश्नों के पूर्वनिर्धारित डेटाबैंक पर जाएं
- एक ऐसा प्रश्न लें जो डिसॉर्डर चैनल पर पोस्ट नहीं किया गया है
- लीटकोड प्रश्न को डिसॉर्डर चैनल में एक थ्रेड के रूप में पोस्ट करें (ताकि आप आसानी से अपना समाधान जोड़ सकें)
- चैनल पर दोबारा पोस्ट करने से बचने के लिए प्रश्न को पोस्ट किया गया के रूप में चिह्नित किया गया है
मुझे एहसास है कि केवल लीटकोड पर जाना और एक दिन में एक प्रश्न हल करना आसान हो सकता है लेकिन मुझे इस मिनी-प्रोजेक्ट पर चैटजीपीटी की मदद से पायथन और डिस्कॉर्ड के बारे में बहुत कुछ सीखने को मिला। स्केचनोटिंग में भी यह मेरा पहला प्रयास है, इसलिए कृपया धैर्य रखें
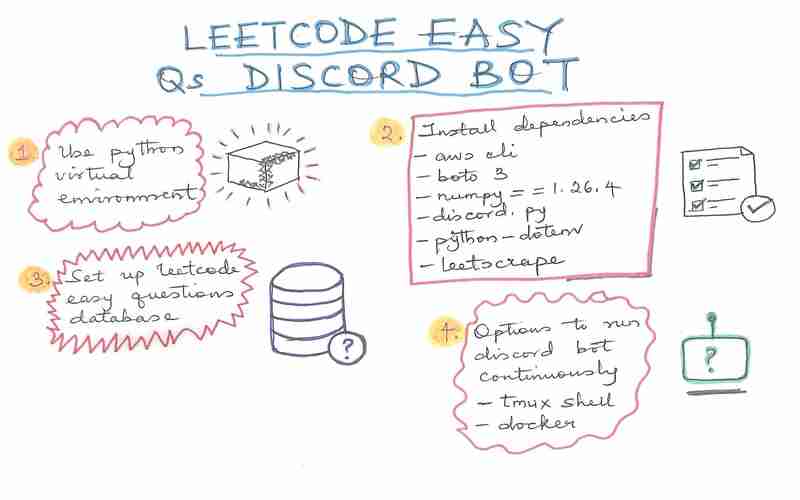
स्थापित करना
1. पायथन वर्चुअल वातावरण का उपयोग करें
2. निर्भरताएँ स्थापित करें
3. लीटकोड आसान प्रश्न डेटाबेस सेट करें
4. पर्यावरण चर सेट करें
5. डिस्कॉर्ड ऐप बनाएं
6. बॉट चलाएँ!
1. पायथन आभासी वातावरण का प्रयोग करें
मैं एक पायथन वर्चुअल वातावरण के उपयोग की अनुशंसा करता हूं क्योंकि जब मैंने शुरुआत में उबंटू 24.04 पर इसका परीक्षण किया, तो मुझे नीचे दी गई त्रुटि का सामना करना पड़ा
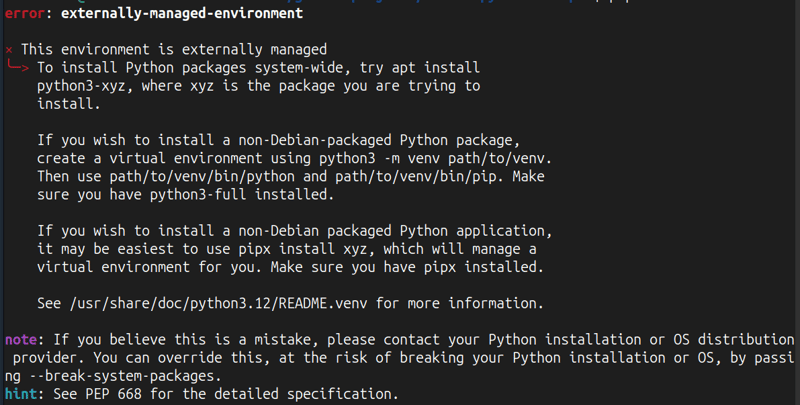
इसे सेट करना अपेक्षाकृत आसान है, बस निम्नलिखित कमांड चलाएं और वॉइला, आप एक पायथन आभासी वातावरण में हैं!
python3 -m venv ~/py_envs ls ~/py_envs # to confirm the environment was created source ~/py_envs/bin/activate
2. निर्भरताएँ स्थापित करें
निम्नलिखित निर्भरताएँ आवश्यक हैं:
- एडब्ल्यूएस सीएलआई
निम्नलिखित चलाकर AWS CLI स्थापित करें:
curl -O 'https://awscli.amazonaws.com/awscli-exe-linux-aarch64.zip' unzip awscli-exe-linux-aarch64.zip sudo ./aws/install aws --version
फिर आवश्यक क्रेडेंशियल जोड़ने के लिए awsconfig चलाएँ। AWS CLI दस्तावेज़ कॉन्फ़िगर करें देखें।
- पिप निर्भरताएं
निम्नलिखित पाइप निर्भरता को pip install -r require.txt चलाकर एक आवश्यकता फ़ाइल के साथ स्थापित किया जा सकता है।
# requirements.txt discord.py # must install this version of numpy to prevent conflict with # pandas, both of which are required by leetscrape numpy==1.26.4 leetscrape python-dotenv
3. लेटकोड आसान प्रश्न डेटाबेस सेट करें
लीटस्क्रेप इस कदम के लिए महत्वपूर्ण था। इसके बारे में अधिक जानने के लिए, लीट्सक्रैप दस्तावेज़ देखें।
मैं केवल लेटकोड के आसान प्रश्नों पर काम करना चाहता हूं (मेरे लिए, वे काफी कठिन भी हैं) इसलिए मैंने निम्नलिखित कार्य किया:
- लीटस्क्रेप का उपयोग करके लेटकोड से सभी प्रश्नों की सूची प्राप्त करें और सूची को सीएसवी में सहेजें
from leetscrape import GetQuestionsList ls = GetQuestionsList() ls.scrape() # Scrape the list of questions ls.questions.head() # Get the list of questions ls.to_csv(directory="path/to/csv/file")
- एक अमेज़ॅन डायनेमोडीबी तालिका बनाएं और इसे पिछले चरण में सहेजे गए सीएसवी से फ़िल्टर किए गए आसान प्रश्नों की सूची से भर दें।
import csv
import boto3
from botocore.exceptions import BotoCoreError, ClientError
# Initialize the DynamoDB client
dynamodb = boto3.resource('dynamodb')
def filter_and_format_csv_for_dynamodb(input_csv):
result = []
with open(input_csv, mode='r') as file:
csv_reader = csv.DictReader(file)
for row in csv_reader:
# Filter based on difficulty and paidOnly fields
if row['difficulty'] == 'Easy' and row['paidOnly'] == 'False':
item = {
'QID': {'N': str(row['QID'])},
'titleSlug': {'S': row['titleSlug']},
'topicTags': {'S': row['topicTags']},
'categorySlug': {'S': row['categorySlug']},
'posted': {'BOOL': False}
}
result.append(item)
return result
def upload_to_dynamodb(items, table_name):
table = dynamodb.Table(table_name)
try:
with table.batch_writer() as batch:
for item in items:
batch.put_item(Item={
'QID': int(item['QID']['N']),
'titleSlug': item['titleSlug']['S'],
'topicTags': item['topicTags']['S'],
'categorySlug': item['categorySlug']['S'],
'posted': item['posted']['BOOL']
})
print(f"Data uploaded successfully to {table_name}")
except (BotoCoreError, ClientError) as error:
print(f"Error uploading data to DynamoDB: {error}")
def create_table():
try:
table = dynamodb.create_table(
TableName='leetcode-easy-qs',
KeySchema=[
{
'AttributeName': 'QID',
'KeyType': 'HASH' # Partition key
}
],
AttributeDefinitions=[
{
'AttributeName': 'QID',
'AttributeType': 'N' # Number type
}
],
ProvisionedThroughput={
'ReadCapacityUnits': 5,
'WriteCapacityUnits': 5
}
)
# Wait until the table exists
table.meta.client.get_waiter('table_exists').wait(TableName='leetcode-easy-qs')
print(f"Table {table.table_name} created successfully!")
except Exception as e:
print(f"Error creating table: {e}")
# Call function to create the table
create_table()
# Example usage
input_csv = 'getql.pyquestions.csv' # Your input CSV file
table_name = 'leetcode-easy-qs' # DynamoDB table name
# Step 1: Filter and format the CSV data
questions = filter_and_format_csv_for_dynamodb(input_csv)
# Step 2: Upload data to DynamoDB
upload_to_dynamodb(questions, table_name)
4. पर्यावरण चर सेट करें
पर्यावरण चर संग्रहीत करने के लिए एक .env फ़ाइल बनाएं
DISCORD_BOT_TOKEN=*****
5. डिस्कॉर्ड ऐप बनाएं
पर्याप्त अनुमतियों के साथ एक डिस्कॉर्ड ऐप और बॉट बनाने के लिए डिस्कॉर्ड डेवलपर डॉक्स में दिए गए निर्देशों का पालन करें। बॉट को कम से कम निम्नलिखित OAuth अनुमतियों के साथ अधिकृत करना सुनिश्चित करें:
- संदेश भेजें
- सार्वजनिक थ्रेड बनाएं
- थ्रेड्स में संदेश भेजें
6. बॉट चलाएँ!
नीचे बॉट के लिए कोड है जिसे Python3 discord-leetcode-qs.py कमांड के साथ चलाया जा सकता है।
import os
import discord
import boto3
from leetscrape import GetQuestion
from discord.ext import tasks
from dotenv import load_dotenv
import re
load_dotenv()
# Discord bot token
TOKEN = os.getenv('DISCORD_TOKEN')
# Set the intents for the bot
intents = discord.Intents.default()
intents.message_content = True # Ensure the bot can read messages
# Initialize the bot
bot = discord.Client(intents=intents)
# DynamoDB setup
dynamodb = boto3.client('dynamodb')
TABLE_NAME = 'leetcode-easy-qs'
CHANNEL_ID = 1211111111111111111 # Replace with the actual channel ID
# Function to get the first unposted item from DynamoDB
def get_unposted_item():
response = dynamodb.scan(
TableName=TABLE_NAME,
FilterExpression='posted = :val',
ExpressionAttributeValues={':val': {'BOOL': False}},
)
items = response.get('Items', [])
if items:
return items[0]
return None
# Function to mark the item as posted in DynamoDB
def mark_as_posted(qid):
dynamodb.update_item(
TableName=TABLE_NAME,
Key={'QID': {'N': str(qid)}},
UpdateExpression='SET posted = :val',
ExpressionAttributeValues={':val': {'BOOL': True}}
)
MAX_MESSAGE_LENGTH = 2000
AUTO_ARCHIVE_DURATION = 2880
# Function to split a question into words by spaces or newlines
def split_question(question, max_length):
parts = []
while len(question) > max_length:
split_at = question.rfind(' ', 0, max_length)
if split_at == -1:
split_at = question.rfind('\n', 0, max_length)
if split_at == -1:
split_at = max_length
parts.append(question[:split_at].strip())
# Continue with the remaining text
question = question[split_at:].strip()
if question:
parts.append(question)
return parts
def clean_question(question):
first_line, _, remaining_question = message.partition('\n')
return re.sub(r'\n{3,}', '\n', remaining_question)
def extract_first_line(question):
lines = question.splitlines()
return lines[0] if lines else ""
# Task that runs on a schedule
@tasks.loop(minutes=1440)
async def scheduled_task():
channel = bot.get_channel(CHANNEL_ID)
item = get_unposted_item()
if item:
title_slug = item['titleSlug']['S']
qid = item['QID']['N']
question = "%s" % (GetQuestion(titleSlug=title_slug).scrape())
first_line = extract_first_line(question)
cleaned_question = clean_message(question)
parts = split_message(cleaned_question, MAX_MESSAGE_LENGTH)
thread = await channel.create_thread(
name=first_line,
type=discord.ChannelType.public_thread
)
for part in parts:
await thread.send(part)
mark_as_posted(qid)
else:
print("No unposted items found.")
@bot.event
async def on_ready():
print(f'{bot.user} has connected to Discord!')
scheduled_task.start()
@bot.event
async def on_thread_create(thread):
await thread.send("\nYour challenge starts here! Good Luck!")
# Run the bot
bot.run(TOKEN)
बॉट चलाने के लिए कई विकल्प हैं। अभी, मैं इसे केवल tmux शेल में चला रहा हूं, लेकिन आप इसे डॉकर कंटेनर में या AWS, Azure, DigitalOcean या अन्य क्लाउड प्रदाताओं के VPC पर भी चला सकते हैं।
अब मुझे वास्तव में लेटकोड प्रश्नों को हल करने का प्रयास करना है...
-
 MySQL डेटाबेस विधि को उसी उदाहरण को डंप करने की आवश्यकता नहीं है] निम्नलिखित विधियाँ पारंपरिक डंप-एंड-इम्पोर्ट प्रक्रिया के लिए सरल विकल्प प्रदान करती हैं। mysql new_db_name यह कमांड new_db_name नाम के साथ db_nam...प्रोग्रामिंग 2025-07-06 पर पोस्ट किया गया
MySQL डेटाबेस विधि को उसी उदाहरण को डंप करने की आवश्यकता नहीं है] निम्नलिखित विधियाँ पारंपरिक डंप-एंड-इम्पोर्ट प्रक्रिया के लिए सरल विकल्प प्रदान करती हैं। mysql new_db_name यह कमांड new_db_name नाम के साथ db_nam...प्रोग्रामिंग 2025-07-06 पर पोस्ट किया गया -
मैं PHP का उपयोग करके XML फ़ाइलों से विशेषता मानों को कैसे प्राप्त कर सकता हूं?] एक XML फ़ाइल के साथ काम करते समय, जिसमें प्रदान किए गए उदाहरण की विशेषताएं होती हैं: var [0]-> विशेषताएँ () () के रूप में $ atributename => $ a...प्रोग्रामिंग 2025-07-06 पर पोस्ट किया गया
-
पीडीओ मापदंडों के साथ क्वेरी की तरह सही तरीके से उपयोग कैसे करें?$ params = सरणी ($ var1, $ var2); $ stmt = $ हैंडल-> तैयार करें ($ क्वेरी); $ stmt-> निष्पादित ($ params); त्रुटि % संकेतों के गलत समावेश में निहित ह...प्रोग्रामिंग 2025-07-06 पर पोस्ट किया गया
-
मैं PHP के फाइलसिस्टम फ़ंक्शंस में UTF-8 फ़ाइल नाम कैसे संभाल सकता हूं?असंगतता। mkdir ($ dir_name); मूल UTF-8 फ़ाइल नाम को पुनः प्राप्त करने के लिए, urldecode का उपयोग करें। केवल) विंडोज पर, आप UTF-8 फ़ाइल नाम ...प्रोग्रामिंग 2025-07-06 पर पोस्ट किया गया
-
ASP.NET में Async void बनाम Async कार्य: Async void विधि कभी -कभी अपवादों को क्यों फेंकती है?] हालांकि, Async void और Async कार्य विधियों के बीच महत्वपूर्ण अंतर को गलत समझना अप्रत्याशित त्रुटियों को जन्म दे सकता है। यह प्रश्न यह बताता है कि क्...प्रोग्रामिंग 2025-07-06 पर पोस्ट किया गया
-
होमब्रे से मेरा गो सेटअप क्यों कमांड लाइन निष्पादन मुद्दों का कारण बनता है?] जबकि HomeBrew स्थापना प्रक्रिया को सरल करता है, यह कमांड लाइन निष्पादन और अपेक्षित व्यवहार के बीच एक संभावित विसंगति का परिचय देता है। आपके द्वारा...प्रोग्रामिंग 2025-07-06 पर पोस्ट किया गया
-
नीचे के दाईं ओर फ़्लोटिंग चित्रों के लिए टिप्स और पाठ के चारों ओर लपेटते हैं] यह छवि को प्रभावी ढंग से दिखाने के दौरान एक आकर्षक दृश्य प्रभाव पैदा कर सकता है। इस कंटेनर के भीतर, छवि के लिए पाठ सामग्री और एक IMG तत्व जोड़ें। HT...प्रोग्रामिंग 2025-07-06 पर पोस्ट किया गया
-
रिप्लेस डायरेक्टिव का उपयोग करके GO MOD में मॉड्यूल पथ विसंगतियों को कैसे हल करें?यह गूँज के संदेशों द्वारा प्रदर्शित होने के रूप में, ` github.com/coreos/etcd/client द्वारा github.com/koreos/tcd/client.test आयात &&&] आयात gi...प्रोग्रामिंग 2025-07-06 पर पोस्ट किया गया
-
मेरी रैखिक ढाल पृष्ठभूमि में धारियां क्यों हैं, और मैं उन्हें कैसे ठीक कर सकता हूं?] इन भद्दे कलाकृतियों को एक जटिल पृष्ठभूमि प्रसार घटना के लिए जिम्मेदार ठहराया जा सकता है। इसके बाद, रैखिक-ग्रेडिएंट इस पूरी ऊंचाई पर फैलता है, दोहराए...प्रोग्रामिंग 2025-07-06 पर पोस्ट किया गया
-
फिक्स्ड पोजिशनिंग का उपयोग करते समय 100% ग्रिड-टेम्प्लेट-कॉलम के साथ ग्रिड शरीर से परे क्यों फैलता है?] फिक्स्ड; class = "स्निपेट-कोड"> । माता-पिता { स्थिति: फिक्स्ड; चौड़ाई: 100%; 6fr; lang-html atrayprint-override ">प्रोग्रामिंग 2025-07-06 पर पोस्ट किया गया
-
संकलक त्रुटि "USR/BIN/LD: नहीं मिल सकती है -L" समाधान] -l यह त्रुटि इंगित करती है कि लिंकर आपके निष्पादन योग्य को जोड़ते समय निर्दिष्ट लाइब्रेरी का पता नहीं लगा सकता है। इस समस्या को हल करने के लिए, ह...प्रोग्रामिंग 2025-07-06 पर पोस्ट किया गया
-
क्या मैं McRypt से OpenSSL में अपने एन्क्रिप्शन को माइग्रेट कर सकता हूं, और OpenSSL का उपयोग करके McRypt-encrypted डेटा को डिक्रिप्ट कर सकता हूं?] OpenSSL में, क्या McRypt के साथ एन्क्रिप्ट किए गए डेटा को डिक्रिप्ट करना संभव है? दो अलग -अलग पोस्ट परस्पर विरोधी जानकारी प्रदान करते हैं। यदि ऐसा ह...प्रोग्रामिंग 2025-07-06 पर पोस्ट किया गया
-
आप MySQL में डेटा को पिवट करने के लिए समूह का उपयोग कैसे कर सकते हैं?] यहाँ, हम एक सामान्य चुनौती से संपर्क करते हैं: पंक्ति-आधारित से स्तंभ-आधारित डेटा को बदलना समूह द्वारा समूह का उपयोग करके। आइए निम्न क्वेरी पर विचार...प्रोग्रामिंग 2025-07-06 पर पोस्ट किया गया
-
Java.net.urlconnection और multivart/फॉर्म-डेटा एन्कोडिंग का उपयोग करके अतिरिक्त मापदंडों के साथ फ़ाइलों को कैसे अपलोड करें?] यहाँ प्रक्रिया का एक टूटना है: मल्टीपार्ट/फॉर्म-डाटा एन्कोडिंग मल्टीपार्ट/फॉर्म-डेटा को पोस्ट अनुरोधों के लिए डिज़ाइन किया गया है जो बाइनरी ...प्रोग्रामिंग 2025-07-06 पर पोस्ट किया गया
-
त्रुटि को कैसे हल करें "फ़ाइल प्रकार का अनुमान नहीं लगा सकते, एप्लिकेशन/ऑक्टेट-स्ट्रीम ..." Appengine में?] एप्लिकेशन/ऑक्टेट-स्ट्रीम ... " समस्या रिज़ॉल्यूशन /etc/mime.types फ़ाइल। AppEngine, हालांकि, इस परिभाषा तक पहुंच नहीं हो सकती है। उदाहरण...प्रोग्रामिंग 2025-07-06 पर पोस्ट किया गया















चीनी भाषा का अध्ययन करें
- 1 आप चीनी भाषा में "चलना" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 2 आप चीनी भाषा में "विमान ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 3 आप चीनी भाषा में "ट्रेन ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 4 आप चीनी भाषा में "बस ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 5 चीनी भाषा में ड्राइव को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 6 तैराकी को चीनी भाषा में क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 7 आप चीनी भाषा में साइकिल चलाने को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 8 आप चीनी भाषा में नमस्ते कैसे कहते हैं? 你好चीनी उच्चारण, 你好चीनी सीखना
- 9 आप चीनी भाषा में धन्यवाद कैसे कहते हैं? 谢谢चीनी उच्चारण, 谢谢चीनी सीखना
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









