
Dify API के साथ रीयल-टाइम स्पीच कैसे प्राप्त करें
 ब्राउज़ करें:353
ब्राउज़ करें:353
Dify एलएलएम वर्कफ़्लो ऑनलाइन बनाने के लिए एक ओपन-सोर्स SaaS प्लेटफ़ॉर्म है। मैं अपने ऐप पर संवादात्मक एआई अनुभव बनाने के लिए एपीआई का उपयोग कर रहा हूं। मैं एपीआई प्रतिक्रिया के रूप में टीटीएस स्ट्रीम प्राप्त करने और इसे चलाने के लिए संघर्ष कर रहा था। यहां मैं दर्शाता हूं कि ऑडियो स्ट्रीम को कैसे संसाधित किया जाए और इसे सही तरीके से कैसे चलाया जाए।
मैं टेक्स्ट चैट के लिए एपीआई एंडपॉइंट https://api.dify.ai/v1/chat-messages का उपयोग कर रहा हूं। यदि हम अपने Dify ऐप्स में टेक्स्ट टू स्पीच सुविधा सक्षम करते हैं तो यह टेक्स्ट प्रतिक्रिया के समान स्ट्रीम में ऑडियो डेटा लौटाता है।
फीचर जोड़ें बटन दबाएं और टेक्स्ट टू स्पीच फीचर जोड़ें।
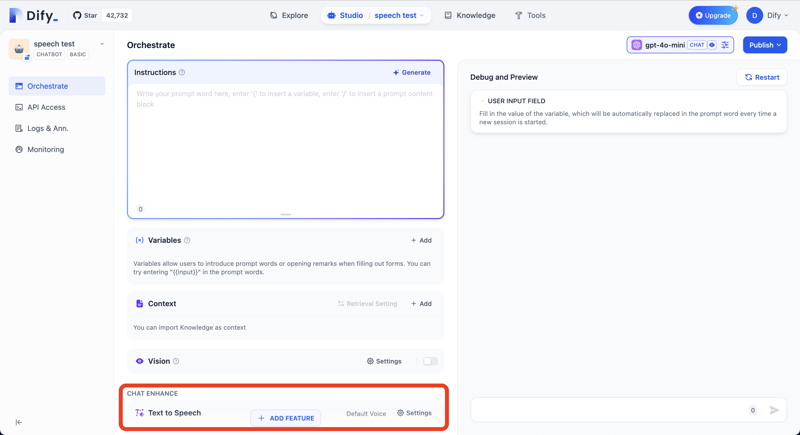
आप निम्नलिखित कर्ल कमांड के साथ एपीआई से प्रतिक्रिया की जांच कर सकते हैं।
curl -X POST 'https://api.dify.ai/v1/chat-messages' \
--header 'Authorization: Bearer YOUR_API_KEY' \
--header 'Content-Type: application/json' \
--data-raw '{
"inputs": {},
"query": "What are the specs of the iPhone 13 Pro Max?",
"response_mode": "streaming",
"conversation_id": "",
"user": "abc-123",
"files": []
}'
मैं टाइपस्क्रिप्ट/जावास्क्रिप्ट में प्रदर्शित करता हूं लेकिन आप अपनी प्रोग्रामिंग भाषा में वही तर्क लागू कर सकते हैं।
स्ट्रीम किए गए डेटा का एनाटॉमी
सबसे पहले, आइए समझें कि Dify स्ट्रीम के लिए किस प्रकार का डेटा उपयोग कर रहा है।
स्ट्रीम किया गया डेटा प्रारूप
Dify निम्नलिखित टेक्स्ट डेटा प्रारूप का उपयोग कर रहा है। यह JSON लाइनों की तरह है लेकिन यह बिल्कुल वैसा नहीं है।
data: {"event": "workflow_started", "conversation_id": "065fb118-35d4-4524-a067-a70338ece575", "message_id": "3f0fe3cf-5aa1-4f7c-8abe-2505bf07ae8f", "created_at": 1724478014, "task_id": "dacb2d5c-a6f5-44b5-b5a6-de000f24aeba", "workflow_run_id": "50100b30-e458-4632-ad7d-8dd383823376", "data": {"id": "50100b30-e458-4632-ad7d-8dd383823376", "workflow_id": "debdb4fa-dcab-4233-9413-fd6d17b9e36a", "sequence_number": 334, "inputs": {"sys.query": "What are the specs of the iPhone 13 Pro Max?", "sys.files": [], "sys.conversation_id": "065fb118-35d4-4524-a067-a70338ece575", "sys.user_id": "abc-123"}, "created_at": 1724478014}}
data: {"event": "node_started", "conversation_id": "065fb118-35d4-4524-a067-a70338ece575", "message_id": "3f0fe3cf-5aa1-4f7c-8abe-2505bf07ae8f", "created_at": 1724478014, "task_id": "dacb2d5c-a6f5-44b5-b5a6-de000f24aeba", "workflow_run_id": "50100b30-e458-4632-ad7d-8dd383823376", "data": {"id": "bf912f43-29dd-4ee2-aefa-0fabdf379257", "node_id": "1721365917005", "node_type": "start", "title": "\u958b\u59cb", "index": 1, "predecessor_node_id": null, "inputs": null, "created_at": 1724478013, "extras": {}}}
data: {"event": "node_finished", "conversation_id": "065fb118-35d4-4524-a067-a70338ece575", "message_id": "3f0fe3cf-5aa1-4f7c-8abe-2505bf07ae8f", "created_at": 1724478014, "task_id": "dacb2d5c-a6f5-44b5-b5a6-de000f24aeba", "workflow_run_id": "50100b30-e458-4632-ad7d-8dd383823376", "data": {"id": "bf912f43-29dd-4ee2-aefa-0fabdf379257", "node_id": "1721365917005", "node_type": "start", "title": "\u958b\u59cb", "index": 1, "predecessor_node_id": null, "inputs": {"sys.query": "What are the specs of the iPhone 13 Pro Max?", "sys.files": [], "sys.conversation_id": "065fb118-35d4-4524-a067-a70338ece575", "sys.user_id": "abc-123", "sys.dialogue_count": 1}, "process_data": null, "outputs": {"sys.query": "What are the specs of the iPhone 13 Pro Max?", "sys.files": [], "sys.conversation_id": "065fb118-35d4-4524-a067-a70338ece575", "sys.user_id": "abc-123", "sys.dialogue_count": 1}, "status": "succeeded", "error": null, "elapsed_time": 0.001423838548362255, "execution_metadata": null, "created_at": 1724478013, "finished_at": 1724478013, "files": []}}
data: {"event": "node_started", "conversation_id": "065fb118-35d4-4524-a067-a70338ece575", "message_id": "3f0fe3cf-5aa1-4f7c-8abe-2505bf07ae8f", "created_at": 1724478014, "task_id": "dacb2d5c-a6f5-44b5-b5a6-de000f24aeba", "workflow_run_id": "50100b30-e458-4632-ad7d-8dd383823376", "data": {"id": "89ed58ab-6157-499b-81b2-92b1336969a5", "node_id": "llm", "node_type": "llm", "title": "LLM", "index": 2, "predecessor_node_id": "1721365917005", "inputs": null, "created_at": 1724478013, "extras": {}}}
...
प्रतिक्रिया में, Dify टेक्स्ट उत्तर और ऑडियो डेटा को आगे बढ़ाता है।
पाठ उत्तर की उदाहरण पंक्ति
data: {"event": "message", "conversation_id": "aa13eb24-e90a-4c5d-a36b-756f0e3be8f8", "message_id": "5be739a9-09ba-4444-9905-a2f37f8c7a21", "created_at": 1724301648, "task_id": "0643f770-e9d3-408f-b771-bb2e9430b4f9", "id": "5be739a9-09ba-4444-9905-a2f37f8c7a21", "answer": "MP"}
ऑडियो डेटा की उदाहरण पंक्ति
data: {"event": "tts_message", "conversation_id": "aa13eb24-e90a-4c5d-a36b-756f0e3be8f8", "message_id": "5be739a9-09ba-4444-9905-a2f37f8c7a21", "created_at": 1724301648, "task_id": "0643f770-e9d3-408f-b771-bb2e9430b4f9", "audio": "//PkxABhvDm0DVp4ACUUfvWc1CFlh0tR9Oh7LxzHRsGBuGx155x3JqTJiwKKZf8wIcxpMzJU0h4zhgyQwwwIsgWQMAALQMkanBTjfCPgZwFsDOGGIYJoJoJoJoPQPQLYEgAOwM4SMXMW8TcNWGrEPEME0HoIQTg0DQNA0C5k7IOLeJuDnDVi5nWyJwgghAagQwTQQgJAGrDVibiFhqw1YR8HOEjBUA5AcgagQwTQTQQgJAAtgLYKsQ8hZc0PV7OrE4SgQgFIAsAQAwA6H0Uv4t4m4m49Yt4uYOQHIBkAyAqAkAuB0Mm6UeKxDGRrIODkByBqBNBCA1ARwHIEgBVg5wkY41W2GgdEVDFBNe HicQw0ydk7HrHrIWXM62d48ePNfCkNATcTcNWGrCRhqxDxcwMYBwBkByCGC4EILgoJTQUDeW8W8TcTchZ1qBWIYchOBbBCA1AhgSMJGGrFzLmh6fL LeBkAyAZAcgSAXAhB0Kxnj4YDkJwXA6FAzwj8IIJoJoPQXA6EPOcg4R8FOBnCRljRAwlwoh4EUwLhFTCVA MR0R8wyxOhgAwwDgJjBUABMM0hMxBgnTPtMrMBEEcwJQCzIXIdMZMG821DmjDKHJAwLDKHRMQsJkwbwVRoFs//PkxEx5dDnwAZ7wANHgEUFJHGCUCQp3LWCQQYGAATI5QzwHBJF4UFktpfATT2l0goAGNADLOU64HAMCQCK50szABAIkDS2/j8gl6l6Di7QgBEiAfMEADBnyZBgeAWCMK4xvBbhoRZj1M ktsNMTrMNcHEwHQEzAjAHMGQAQwRQZTBHALMGMDkzhh2jGhLtMgsMMwfhOzCnGLMMcKgwOw8pqHMoGtvdDzos0AIAiXIsBAmGsRFtYcBABmB0AUYjQfhhDAfjoCrETAGArMOAJ4iAAMCMFkwXwh5fffuhpYMhyP2bl3MVAJQrSYQDsna7G2 fx/GvyAwUQbTAdAFCAHVKyIAduTXHZZXDjNS57/VeVJ5 JBJ 0kATkCSells8/NBt/2/5Dj1s chDBYSINutNS9FQwDwBWHjgASKRgAAJOyYC4Ao0CMNAKBgB6KK1hYBkAAHROM9mLsknb8avTcB0MerV6jl7llE70egOerRh9WcP/FoHqtVsO/In2f G2tsdnH L/KSSvBQB4OATam27Yi4jiBgBFOpq15bTQU6k1G4LoWo1mMAwDQwlBEzEnKsMkA7c5JYuTOzK2MvAbEysSPTM dOOn1XEzGgIzXzmPODVvs1cyNTJxQ9MsAWwy//PkxDlz7DIMAd7gAek5EwnjcjX9QVN1N0czFyijQKOmMi4IYw8RvzFvCHMHYBQwdQlTRxVNvm8ycGjLYlMTAQ=="}
हम इवेंट प्रॉपर्टी की जांच करके ऑडियो डेटा की JSON लाइनों को अलग कर सकते हैं। ऑडियो JSON का मान tts_message है। ऑडियो एमपी3 बाइनरी को JSONs की ऑडियो प्रॉपर्टी में बेस64 प्रारूप में संग्रहीत किया जाता है।
डेटा संभालने में समस्याएँ
जब हम टीटीएस ऑडियो रीयल-टाइम चलाते हैं तो पहली समस्या यह होती है कि JSON लाइनें पैकेट में विभाजित हो जाती हैं और प्रत्येक पैकेट वैध JSON डेटा नहीं होता है।
उदाहरण पैकेट जो बीच में कटा हुआ है
euimRrhsPMZiMAl BqSZMDmIkQEcDb/8 TEtHm8MhwA3p/p8dA0CCpAxwMMPABoYMIWwUDG6BRmiYZg2G6gRidGanOm5i5iaIYmfkH8Z/FmEopqJGZKXihYEIRxCKYKtlQuMvPjPQIwUVFFECDRnRCYEimGmA6cji41yQMImMEmhaHrVKpCxo2OYx6Q5RcJKAKkah4X6MckHEqdwKgHGHltDUjCy46HMgTCpwodAM8KijREwSSEk5hB4gRGFfC0ouYoeDiYtNREDgKQsTT6EI4egmMMBxpQZmoUJmAAg6YPDmQISgSECAZQOLfAUEQAG/dgxAVkxfFHGorEHB4CS Yugwk2gq8akIwMsZIuIzUSrCAGm1iBnoYA8lcoYSlaIJ5RjCblwbsh8sB3skA7Gcx3zmSOKnXNJO6ObKklhuYjlVL1dSMhgwVJtFzMeWFufNKy3ODmCExBTUUzLjEwMKqqqqqqqqqqqqqqqqqqCIEWFIAA4DAWKkMDDIBA4lBqGDdmZwzAkGJFoYiwEV0IQOQHg1AATJiUM6F0z2fDE6PMvlc6DhTMJ MNH4xWwzBwKMMCgHAwwUFQwjGEgMgovgIBMIMECYxYSDKAwSoMOBC4Ez682pEZIB8kBuiawZEaSnFAjIEwSFRxGUJIXMGRMmfNCPApcKL/8 TEiVdEKlJm5pM9gz0MyScwo04BgqjEFh489MGKVw=="}
पैकेट JSON लाइन के मध्य से प्रारंभ हो रहा है। वैध JSON लाइन प्राप्त करने के लिए हमें कई पैकेटों को संयोजित करना होगा।
दूसरी समस्या यह है कि JSON में ऑडियो डेटा खंड वैध ऑडियो डेटा नहीं है। डेटा को एमपी3 फ्रेम के बीच में काटा जाता है।
कार्यान्वयन
JSON और mp3 के स्प्लिट डेटा को संभालने के लिए हमें कुछ स्मार्ट तरीके अपनाने होंगे। प्रक्रिया का प्रवाह इस प्रकार है:
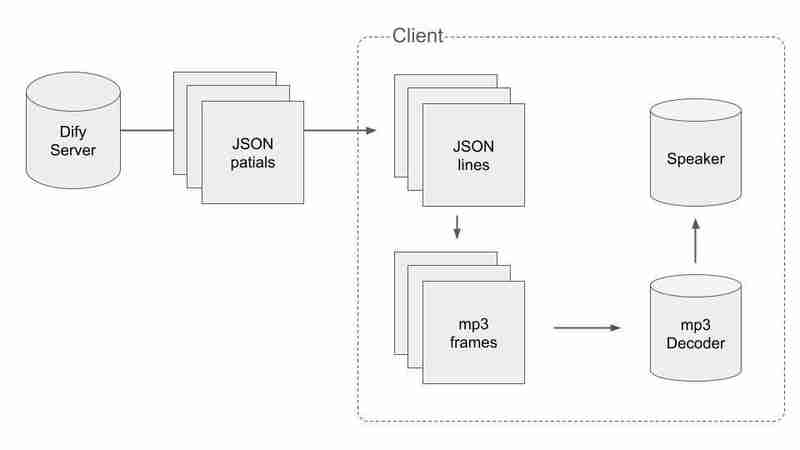
सबसे पहले, हमें वैध JSON डेटा प्राप्त करना होगा और पैकेट प्राप्त करते समय JSON में विभाजित करना होगा। जब हमें अंत में \n वाला एक पैकेट मिलता है, तो हम कह सकते हैं कि अब तक प्राप्त पैकेटों का संयोजन बीच में नहीं काटा गया है। छद्म कोड इस प्रकार है।
let packets = []
stream.on('data', (bytes) => {
const text = bytes.toString()
packets.push(text)
if (text.endsWith('\n')) {
// Extract audio data from the packets.
const audioChunks = extractAudioChunks(packets.join(''))
// Clear the packet array
packets = []
}
})
दूसरा, हमें ऑडियो हिस्सों को एमपी3 फ्रेम में विभाजित करना होगा। हम ऑडियो खंडों को एक बाइनरी में जोड़ते हैं और उसमें प्रत्येक एमपी3 फ़्रेम ढूंढते हैं।
const mp3Frames = [] const binaryToProcess = Buffer.concat([...audioChunks]) let frameStartIndex = 0 for (let i = 0; iयह एमपी3 फ्रेम में विभाजन का पूर्ण कार्यान्वयन नहीं है। वास्तविक प्रक्रिया में, हमें उन मामलों पर विचार करना होगा जब हमने ऑडियो बाइनरी से एमपी3 फ्रेम निकाले थे और शेष बाइट्स को अगले पुनरावृत्ति में ऑडियो बाइट्स की शुरुआत के रूप में उपयोग किया था। पूर्ण कार्यान्वयन के लिए कृपया मेरा जीथब रेपो जांचें।
-
 Microsoft Visual C ++ दो-चरण टेम्पलेट तात्कालिकता को सही ढंग से लागू करने में विफल क्यों होता है?तंत्र के कौन से विशिष्ट पहलू अपेक्षित रूप से संचालित करने में विफल होते हैं? हालाँकि, इस बारे में संदेह उत्पन्न होता है कि क्या यह चेक सत्यापित करता ...प्रोग्रामिंग 2025-03-12 को पोस्ट किया गया
Microsoft Visual C ++ दो-चरण टेम्पलेट तात्कालिकता को सही ढंग से लागू करने में विफल क्यों होता है?तंत्र के कौन से विशिष्ट पहलू अपेक्षित रूप से संचालित करने में विफल होते हैं? हालाँकि, इस बारे में संदेह उत्पन्न होता है कि क्या यह चेक सत्यापित करता ...प्रोग्रामिंग 2025-03-12 को पोस्ट किया गया -
UTF-8 बनाम लैटिन -1: द सीक्रेट ऑफ कैरेक्टर एन्कोडिंग!] उनके अनुप्रयोगों के बीच, एक मौलिक प्रश्न उठता है: क्या समझदार विशेषताएं इन दो एन्कोडिंग को अलग करती हैं? जबकि लैटिन 1 विशेष रूप से लैटिन पात्रों को ...प्रोग्रामिंग 2025-03-12 को पोस्ट किया गया
-
सरणी] एरेज़ ऑब्जेक्ट हैं, इसलिए उनके पास जेएस में भी तरीके हैं। स्लाइस (शुरुआत): मूल सरणी को म्यूट किए बिना, एक नए सरणी में सरणी का हिस्सा निकाले...प्रोग्रामिंग 2025-03-12 को पोस्ट किया गया
-
मैं जावा स्ट्रिंग में कई सब्सट्रेट्स को कुशलता से कैसे बदल सकता हूं?] हालाँकि, यह बड़े तार के लिए अक्षम हो सकता है या जब कई तार के साथ काम कर रहा है। नियमित अभिव्यक्तियाँ आपको जटिल खोज पैटर्न को परिभाषित करने और एकल ऑप...प्रोग्रामिंग 2025-03-12 को पोस्ट किया गया
-
भाग SQL इंजेक्शन श्रृंखला: उन्नत SQL इंजेक्शन तकनीकों की विस्तृत व्याख्यावेमैप पेंटिंग टूल: यहां क्लिक करें TrixSec github: यहाँ क्लिक करें TRIXSEC टेलीग्राम: यहां क्लिक करें ] हमारी SQL इंजेक्शन श्रृंखला के...प्रोग्रामिंग 2025-03-12 को पोस्ट किया गया
-
PYTZ शुरू में अप्रत्याशित समय क्षेत्र ऑफसेट क्यों दिखाता है?] उदाहरण के लिए, एशिया/hong_kong शुरू में एक सात घंटे और 37 मिनट की ऑफसेट दिखाता है: आयात pytz Std> विसंगति स्रोत समय क्षेत्र और ऑफसेट प...प्रोग्रामिंग 2025-03-12 को पोस्ट किया गया
-
कैसे ठीक करें "सामान्य त्रुटि: 2006 MySQL सर्वर डेटा डालते समय दूर चला गया है?] यह त्रुटि तब होती है जब सर्वर का कनेक्शन खो जाता है, आमतौर पर MySQL कॉन्फ़िगरेशन में दो चर में से एक के कारण। ये चर उस अधिकतम समय को नियंत्रित करते ...प्रोग्रामिंग 2025-03-12 को पोस्ट किया गया
-
हम दुर्भावनापूर्ण सामग्री के खिलाफ फ़ाइल अपलोड को कैसे सुरक्षित कर सकते हैं?] इन खतरों को समझना और प्रभावी शमन रणनीतियों को लागू करना आपके आवेदन की सुरक्षा को बनाए रखने के लिए महत्वपूर्ण है। इसलिए, अपलोड की गई फ़ाइल के हर पहलू...प्रोग्रामिंग 2025-03-12 को पोस्ट किया गया
-
जावास्क्रिप्ट में नियमित अभिव्यक्तियों का उपयोग करके स्ट्रिंग्स से लाइन ब्रेक कैसे निकालें?] सवाल उठता है: .replace विधि के भीतर एक नियमित अभिव्यक्ति में लाइन ब्रेक का प्रतिनिधित्व कैसे किया जा सकता है? विंडोज "\ r \ n" अनुक्रम का ...प्रोग्रामिंग 2025-03-12 को पोस्ट किया गया
-
फ़ायरफ़ॉक्स बैक बटन का उपयोग करते समय जावास्क्रिप्ट निष्पादन क्यों बंद हो जाता है?] यह समस्या क्रोम और इंटरनेट एक्सप्लोरर जैसे अन्य ब्राउज़रों में नहीं होती है। इस समस्या को हल करने के लिए और बाद के पृष्ठ के दौरे पर स्क्रिप्ट निष्पा...प्रोग्रामिंग 2025-03-12 को पोस्ट किया गया
-
PHP का उपयोग करके MySQL में बूँदों (चित्र) को ठीक से कैसे डालें?] यह गाइड आपके छवि डेटा को सफलतापूर्वक संग्रहीत करने के लिए समाधान प्रदान करेगा। ImageStore (ImageId, Image) मान ('$ यह- & gt; image_id', ...प्रोग्रामिंग 2025-03-12 को पोस्ट किया गया
-
क्या मैं McRypt से OpenSSL में अपने एन्क्रिप्शन को माइग्रेट कर सकता हूं, और OpenSSL का उपयोग करके McRypt-encrypted डेटा को डिक्रिप्ट कर सकता हूं?] OpenSSL में, क्या McRypt के साथ एन्क्रिप्ट किए गए डेटा को डिक्रिप्ट करना संभव है? दो अलग -अलग पोस्ट परस्पर विरोधी जानकारी प्रदान करते हैं। यदि ऐसा ह...प्रोग्रामिंग 2025-03-12 को पोस्ट किया गया
-
जेएस और मूल बातें] ] जेएस और कोर प्रोग्रामिंग अवधारणाओं की मूल बातें समझना किसी को भी वेब विकास या सामान्य सॉफ्टवेयर प्रोग्रामिंग में गोता लगाने के लिए आवश्यक है। यह म...प्रोग्रामिंग 2025-03-12 को पोस्ट किया गया
-
क्या जावा में कलेक्शन ट्रैवर्सल के लिए एक-प्रत्येक लूप और एक पुनरावृत्ति का उपयोग करने के बीच एक प्रदर्शन अंतर है?के लिए यह लेख इन दो दृष्टिकोणों के बीच दक्षता के अंतर की पड़ताल करता है। यह आंतरिक रूप से iterator का उपयोग करता है: सूची a = new ArrayList ...प्रोग्रामिंग 2025-03-12 को पोस्ट किया गया
-
कैसे जांचें कि क्या किसी वस्तु की पायथन में एक विशिष्ट विशेषता है?] निम्नलिखित उदाहरण पर विचार करें जहां एक अपरिभाषित संपत्ति तक पहुंचने का प्रयास एक त्रुटि उठाता है: >>> a = someclass () >>> a.property ट्रेसबैक (स...प्रोग्रामिंग 2025-03-12 को पोस्ट किया गया















चीनी भाषा का अध्ययन करें
- 1 आप चीनी भाषा में "चलना" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 2 आप चीनी भाषा में "विमान ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 3 आप चीनी भाषा में "ट्रेन ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 4 आप चीनी भाषा में "बस ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 5 चीनी भाषा में ड्राइव को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 6 तैराकी को चीनी भाषा में क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 7 आप चीनी भाषा में साइकिल चलाने को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 8 आप चीनी भाषा में नमस्ते कैसे कहते हैं? 你好चीनी उच्चारण, 你好चीनी सीखना
- 9 आप चीनी भाषा में धन्यवाद कैसे कहते हैं? 谢谢चीनी उच्चारण, 谢谢चीनी सीखना
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









