
K निकटतम पड़ोसी प्रतिगमन, प्रतिगमन: पर्यवेक्षित मशीन लर्निंग
 ब्राउज़ करें:693
ब्राउज़ करें:693
k-निकटतम पड़ोसी प्रतिगमन
के-निकटतम पड़ोसी (के-एनएन) प्रतिगमन एक गैर-पैरामीट्रिक विधि है जो फीचर स्पेस में के-निकटतम प्रशिक्षण डेटा बिंदुओं के औसत (या भारित औसत) के आधार पर आउटपुट मूल्य की भविष्यवाणी करता है। यह दृष्टिकोण किसी विशिष्ट कार्यात्मक रूप को ग्रहण किए बिना डेटा में जटिल संबंधों को प्रभावी ढंग से मॉडल कर सकता है।
के-एनएन प्रतिगमन विधि को निम्नानुसार संक्षेपित किया जा सकता है:
- दूरी मीट्रिक: डेटा बिंदुओं की "निकटता" निर्धारित करने के लिए एल्गोरिदम एक दूरी मीट्रिक (आमतौर पर यूक्लिडियन दूरी) का उपयोग करता है।
- k पड़ोसी: पैरामीटर k निर्दिष्ट करता है कि भविष्यवाणी करते समय कितने निकटतम पड़ोसियों पर विचार किया जाए।
- भविष्यवाणी: एक नए डेटा बिंदु के लिए अनुमानित मूल्य उसके निकटतम पड़ोसियों के मूल्यों का औसत है।
महत्वपूर्ण अवधारणाएं
गैर-पैरामीट्रिक: पैरामीट्रिक मॉडल के विपरीत, के-एनएन इनपुट सुविधाओं और लक्ष्य चर के बीच अंतर्निहित संबंध के लिए एक विशिष्ट रूप नहीं मानता है। यह इसे जटिल पैटर्न कैप्चर करने में लचीला बनाता है।
दूरी गणना: दूरी मीट्रिक का चुनाव मॉडल के प्रदर्शन को महत्वपूर्ण रूप से प्रभावित कर सकता है। सामान्य मेट्रिक्स में यूक्लिडियन, मैनहट्टन और मिन्कोव्स्की दूरियाँ शामिल हैं।
k की पसंद: पड़ोसियों की संख्या (k) को क्रॉस-वैलिडेशन के आधार पर चुना जा सकता है। एक छोटा k ओवरफिटिंग का कारण बन सकता है, जबकि एक बड़ा k पूर्वानुमान को बहुत अधिक सुचारू कर सकता है, संभावित रूप से अंडरफिटिंग।
k-निकटतम पड़ोसी प्रतिगमन उदाहरण
यह उदाहरण दर्शाता है कि के-एनएन की गैर-पैरामीट्रिक प्रकृति का लाभ उठाते हुए जटिल संबंधों को मॉडल करने के लिए बहुपद विशेषताओं के साथ के-एनएन प्रतिगमन का उपयोग कैसे किया जाए।
पायथन कोड उदाहरण
1. आयात पुस्तकालय
import numpy as np import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.preprocessing import PolynomialFeatures from sklearn.neighbors import KNeighborsRegressor from sklearn.metrics import mean_squared_error, r2_score
यह ब्लॉक डेटा हेरफेर, प्लॉटिंग और मशीन लर्निंग के लिए आवश्यक लाइब्रेरी आयात करता है।
2. नमूना डेटा उत्पन्न करें
np.random.seed(42) # For reproducibility X = np.linspace(0, 10, 100).reshape(-1, 1) y = 3 * X.ravel() np.sin(2 * X.ravel()) * 5 np.random.normal(0, 1, 100)
यह ब्लॉक वास्तविक दुनिया डेटा विविधताओं का अनुकरण करते हुए, कुछ शोर के साथ संबंध का प्रतिनिधित्व करने वाला नमूना डेटा उत्पन्न करता है।
3. डेटासेट को विभाजित करें
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
यह ब्लॉक मॉडल मूल्यांकन के लिए डेटासेट को प्रशिक्षण और परीक्षण सेट में विभाजित करता है।
4. बहुपद विशेषताएँ बनाएँ
degree = 3 # Change this value for different polynomial degrees poly = PolynomialFeatures(degree=degree) X_poly_train = poly.fit_transform(X_train) X_poly_test = poly.transform(X_test)
यह ब्लॉक प्रशिक्षण और परीक्षण डेटासेट से बहुपद विशेषताएं उत्पन्न करता है, जिससे मॉडल को गैर-रेखीय संबंधों को पकड़ने की अनुमति मिलती है।
5. के-एनएन रिग्रेशन मॉडल बनाएं और प्रशिक्षित करें
k = 5 # Number of neighbors knn_model = KNeighborsRegressor(n_neighbors=k) knn_model.fit(X_poly_train, y_train)
यह ब्लॉक k-NN प्रतिगमन मॉडल को आरंभ करता है और प्रशिक्षण डेटासेट से प्राप्त बहुपद सुविधाओं का उपयोग करके इसे प्रशिक्षित करता है।
6. भविष्यवाणी करें
y_pred = knn_model.predict(X_poly_test)
यह ब्लॉक परीक्षण सेट पर पूर्वानुमान लगाने के लिए प्रशिक्षित मॉडल का उपयोग करता है।
7. परिणाम प्लॉट करें
plt.figure(figsize=(10, 6))
plt.scatter(X, y, color='blue', alpha=0.5, label='Data Points')
X_grid = np.linspace(0, 10, 1000).reshape(-1, 1)
X_poly_grid = poly.transform(X_grid)
y_grid = knn_model.predict(X_poly_grid)
plt.plot(X_grid, y_grid, color='red', linewidth=2, label=f'k-NN Regression (k={k}, Degree {degree})')
plt.title(f'k-NN Regression (Polynomial Degree {degree})')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()
यह ब्लॉक फिट किए गए वक्र की कल्पना करते हुए, के-एनएन रिग्रेशन मॉडल से अनुमानित मूल्यों की तुलना में वास्तविक डेटा बिंदुओं का एक स्कैटर प्लॉट बनाता है।
के = 1 के साथ आउटपुट:
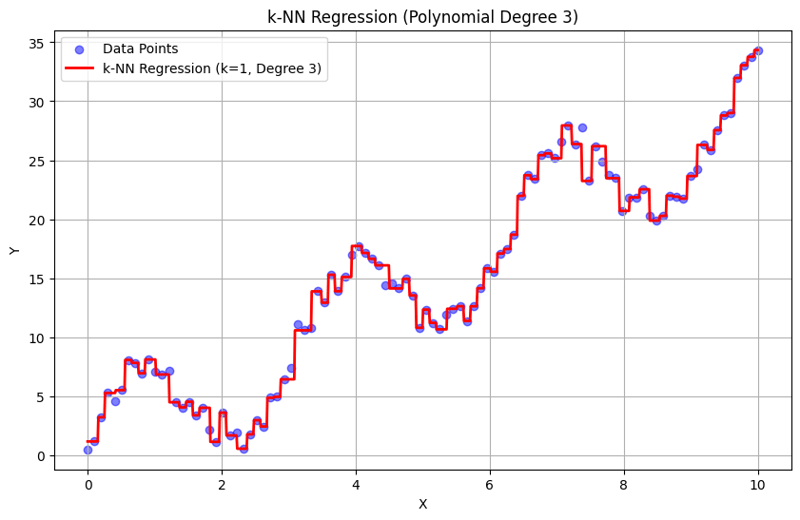
के = 10 के साथ आउटपुट:
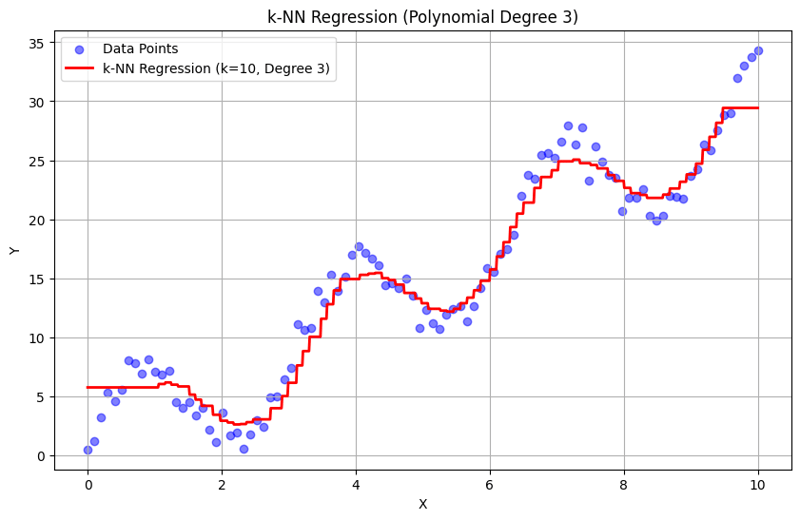
यह संरचित दृष्टिकोण दर्शाता है कि बहुपद विशेषताओं के साथ के-निकटतम पड़ोसी प्रतिगमन को कैसे कार्यान्वित और मूल्यांकन किया जाए। आस-पास के पड़ोसियों की प्रतिक्रियाओं के औसत के माध्यम से स्थानीय पैटर्न को कैप्चर करके, के-एनएन प्रतिगमन एक सीधा कार्यान्वयन प्रदान करते हुए डेटा में जटिल संबंधों को प्रभावी ढंग से मॉडल करता है। K और बहुपद डिग्री का चुनाव अंतर्निहित रुझानों को पकड़ने में मॉडल के प्रदर्शन और लचीलेपन को महत्वपूर्ण रूप से प्रभावित करता है।
-
 मैं एक MySQL तालिका में स्तंभ अस्तित्व के लिए मज़बूती से कैसे जांच कर सकता हूं?अन्य डेटाबेस सिस्टम। सामान्य रूप से प्रयास विधि: यदि मौजूद है (जानकारी से चयन करें * सूचना_ schema.columns से जहां table_name = 'उप...प्रोग्रामिंग 2025-02-07 को पोस्ट किया गया
मैं एक MySQL तालिका में स्तंभ अस्तित्व के लिए मज़बूती से कैसे जांच कर सकता हूं?अन्य डेटाबेस सिस्टम। सामान्य रूप से प्रयास विधि: यदि मौजूद है (जानकारी से चयन करें * सूचना_ schema.columns से जहां table_name = 'उप...प्रोग्रामिंग 2025-02-07 को पोस्ट किया गया -
फ़ायरफ़ॉक्स बैक बटन का उपयोग करते समय जावास्क्रिप्ट निष्पादन क्यों बंद हो जाता है?] बैक बटन के माध्यम से पहले से देखे गए पृष्ठ पर लौटना। यह समस्या क्रोम और इंटरनेट एक्सप्लोरर जैसे अन्य ब्राउज़रों में नहीं होती है। इस समस्या को हल कर...प्रोग्रामिंग 2025-02-07 को पोस्ट किया गया
-
गुमनाम जावास्क्रिप्ट इवेंट हैंडलर को साफ -सुथरा कैसे निकालें?] स्वयं। / यहाँ काम करते हैं /}, गलत); जब तक हैंडलर का संदर्भ निर्माण में संग्रहीत नहीं किया गया था, तब तक एक अनाम घटना हैंडलर को साफ करने का कोई तरीक...प्रोग्रामिंग 2025-02-07 को पोस्ट किया गया
-
क्या मैं सीएसएस में छद्म-तत्व सामग्री के रूप में एसवीजी का उपयोग कर सकता हूं?] छद्म-तत्व जैसे :: पहले और :: के बाद। हालाँकि, इस पर प्रतिबंध लगा दिया गया है कि किस सामग्री को शामिल किया जा सकता है। छद्म-तत्वों के लिए सामग्री क...प्रोग्रामिंग 2025-02-07 को पोस्ट किया गया
-
मैं पूरे HTML दस्तावेज़ में एक विशिष्ट तत्व प्रकार के पहले उदाहरण को कैसे स्टाइल कर सकता हूं?संपूर्ण HTML दस्तावेज़ अकेले CSS का उपयोग करके एक चुनौती हो सकती है। : प्रथम-प्रकार के स्यूडो-क्लास अपने मूल तत्व के भीतर एक प्रकार के पहले तत्व स...प्रोग्रामिंग 2025-02-07 को पोस्ट किया गया
-
इसकी सामग्री को बरकरार रखते हुए मैं एक DIV तत्व को कैसे हटा सकता हूं?Viayports के आधार पर HTML और छिपाने वाले तत्वों को दोहराना प्रदर्शन का उपयोग है: सामग्री; । । इन जैसी स्थितियों में आदर्श है। यह एक तत्व के बच्चों क...प्रोग्रामिंग 2025-02-07 को पोस्ट किया गया
-
PYTZ शुरू में अप्रत्याशित समय क्षेत्र ऑफसेट क्यों दिखाता है?] उदाहरण के लिए, एशिया/hong_kong शुरू में सात घंटे और 37 मिनट की ऑफसेट दिखाता है: आयात pytz pytz.timezone ('एशिया/hong_kong') /Hong_kong ...प्रोग्रामिंग 2025-02-07 को पोस्ट किया गया
-
पायथन के लॉगिंग मॉड्यूल के साथ कस्टम अपवाद हैंडलिंग को कैसे लागू करें?] एक पायथन आवेदन। मैन्युअल रूप से पकड़ने और अपवादों को लॉग करना एक व्यवहार्य दृष्टिकोण है, यह थकाऊ और त्रुटि-प्रवण हो सकता है। यह विस्तृत अपवाद जानकार...प्रोग्रामिंग 2025-02-07 को पोस्ट किया गया
-
मैं जावा सूची में तत्व घटनाओं को कुशलता से कैसे गिन सकता हूं?] । इसे पूरा करने के लिए, संग्रह ढांचा उपकरणों का एक व्यापक सूट प्रदान करता है। यह स्थिर विधि एक सूची और एक तत्व को तर्क के रूप में स्वीकार करती है, त...प्रोग्रामिंग 2025-02-07 को पोस्ट किया गया
-
मैं फॉर्मडाटा () के साथ कई फ़ाइल अपलोड को कैसे संभाल सकता हूं?] इस उद्देश्य के लिए formData () विधि का उपयोग किया जा सकता है, जिससे आप एक ही अनुरोध में कई फ़ाइलें भेज सकते हैं। ] जावास्क्रिप्ट में, एक सामान्य द...प्रोग्रामिंग 2025-02-07 को पोस्ट किया गया
-
कैसे regex का उपयोग करके PHP में कुशलता से कोष्ठक के भीतर पाठ निकालें] एक दृष्टिकोण PHP के स्ट्रिंग हेरफेर कार्यों का उपयोग करना है, जैसा कि नीचे प्रदर्शित किया गया है: $ फुलस्ट्रिंग = "इस (पाठ) को छोड़कर सब कु...प्रोग्रामिंग 2025-02-07 को पोस्ट किया गया
-
मैं पासवर्ड प्रॉम्प्ट के बिना Ubuntu पर MySQL कैसे स्थापित कर सकता हूं?कंसोल में एक पासवर्ड, जो स्वचालित प्रतिष्ठानों के लिए स्क्रिप्ट लिखते समय असुविधाजनक हो सकता है। MySQL रूट उपयोगकर्ता के लिए पासवर्ड को पूर्वनिर्मित ...प्रोग्रामिंग 2025-02-07 को पोस्ट किया गया
-
Php \ के फ़ंक्शन पुनर्वितरण प्रतिबंधों को कैसे दूर करें?] ऐसा करने का प्रयास, जैसा कि प्रदान किए गए कोड स्निपेट में देखा गया है, परिणामस्वरूप एक खूंखार "redeclare" त्रुटि हो सकती है। ] ] हालांक...प्रोग्रामिंग 2025-02-07 को पोस्ट किया गया
-
पायथन में स्ट्रिंग्स से इमोजी को कैसे निकालें: आम त्रुटियों को ठीक करने के लिए एक शुरुआत का मार्गदर्शिका?] पायथन 2 पर U '' उपसर्ग का उपयोग करके यूनिकोड स्ट्रिंग्स को नामित किया जाना चाहिए। इसके अलावा, re.unicode ध्वज को नियमित अभिव्यक्ति में पारित...प्रोग्रामिंग 2025-02-07 को पोस्ट किया गया
-
क्या जावा कई प्रकार के रिटर्न प्रकार की अनुमति देता है: जेनेरिक तरीकों पर एक करीब से नज़र डालें?] : सार्वजनिक सूची getResult (string s); जहां फू एक कस्टम वर्ग है। विधि की घोषणा दो रिटर्न प्रकारों को समेटे हुए है: सूची और ई। लेकिन क्या ...प्रोग्रामिंग 2025-02-07 को पोस्ट किया गया















चीनी भाषा का अध्ययन करें
- 1 आप चीनी भाषा में "चलना" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 2 आप चीनी भाषा में "विमान ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 3 आप चीनी भाषा में "ट्रेन ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 4 आप चीनी भाषा में "बस ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 5 चीनी भाषा में ड्राइव को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 6 तैराकी को चीनी भाषा में क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 7 आप चीनी भाषा में साइकिल चलाने को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 8 आप चीनी भाषा में नमस्ते कैसे कहते हैं? 你好चीनी उच्चारण, 你好चीनी सीखना
- 9 आप चीनी भाषा में धन्यवाद कैसे कहते हैं? 谢谢चीनी उच्चारण, 谢谢चीनी सीखना
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









