
import streamlit as stimport numpy as npimport pandas as pdimport joblib
stremlit एक पायथन लाइब्रेरी है जो मशीन लर्निंग और डेटा साइंस प्रोजेक्ट्स के लिए कस्टम वेब एप्लिकेशन बनाना और साझा करना आसान बनाती है।
numpy संख्यात्मक कंप्यूटिंग के लिए एक मौलिक पायथन लाइब्रेरी है। यह इन सरणियों पर कुशलतापूर्वक संचालन करने के लिए गणितीय कार्यों के संग्रह के साथ-साथ बड़े, बहु-आयामी सरणियों और मैट्रिक्स के लिए समर्थन प्रदान करता है।
data = { \\\"island\\\": island, \\\"bill_length_mm\\\": bill_length_mm, \\\"bill_depth_mm\\\": bill_depth_mm, \\\"flipper_length_mm\\\": flipper_length_mm, \\\"body_mass_g\\\": body_mass_g, \\\"sex\\\": sex,}input_df = pd.DataFrame(data, index=[0])encode = [\\\"island\\\", \\\"sex\\\"]input_encoded_df = pd.get_dummies(input_df, prefix=encode)इनपुट मान स्ट्रेम्लिट द्वारा बनाए गए इनपुट फॉर्म से पुनर्प्राप्त किए जाते हैं, और श्रेणीगत चर को उन्हीं नियमों का उपयोग करके एन्कोड किया जाता है जैसे मॉडल बनाया गया था। ध्यान दें कि प्रत्येक डेटा का क्रम भी वही होना चाहिए जब मॉडल बनाया गया था। यदि क्रम भिन्न है, तो मॉडल का उपयोग करके पूर्वानुमान निष्पादित करते समय एक त्रुटि उत्पन्न होगी।
clf = joblib.load(\\\"penguin_classifier_model.pkl\\\")
\\\"penguin_classifier_model.pkl\\\" वह फ़ाइल है जहां पहले से सहेजा गया मॉडल संग्रहीत है। इस फ़ाइल में बाइनरी प्रारूप में एक प्रशिक्षित RandomForestClassifier शामिल है। इस कोड को चलाने से मॉडल सीएलएफ में लोड हो जाता है, जिससे आप इसे नए डेटा पर पूर्वानुमान और मूल्यांकन के लिए उपयोग कर सकते हैं।
prediction = clf.predict(input_encoded_df)prediction_proba = clf.predict_proba(input_encoded_df)
clf.predict(input_encoded_df): नए एन्कोडेड इनपुट डेटा के लिए वर्ग की भविष्यवाणी करने के लिए प्रशिक्षित मॉडल का उपयोग करता है, परिणाम को भविष्यवाणी में संग्रहीत करता है।
clf.predict_proba(input_encoded_df): प्रत्येक वर्ग के लिए संभाव्यता की गणना करता है, परिणामों को भविष्यवाणी_प्रोबा में संग्रहीत करता है।
आप स्ट्रेमलिट कम्युनिटी क्लाउड (https://streamlit.io/cloud) तक पहुंच कर और GitHub रिपॉजिटरी का URL निर्दिष्ट करके अपने विकसित एप्लिकेशन को इंटरनेट पर प्रकाशित कर सकते हैं।

@allison_horst द्वारा कलाकृति (https://github.com/allisonhorst)
मॉडल को पामर पेंगुइन डेटासेट का उपयोग करके प्रशिक्षित किया जाता है, जो मशीन लर्निंग तकनीकों का अभ्यास करने के लिए व्यापक रूप से मान्यता प्राप्त डेटासेट है। यह डेटासेट अंटार्कटिका में पामर द्वीपसमूह से तीन पेंगुइन प्रजातियों (एडेली, चिनस्ट्रैप और जेंटू) के बारे में जानकारी प्रदान करता है। मुख्य विशेषताओं में शामिल हैं:
यह डेटासेट कागल से लिया गया है, और इसे यहां एक्सेस किया जा सकता है। विशेषताओं में विविधता इसे वर्गीकरण मॉडल बनाने और प्रजातियों की भविष्यवाणी में प्रत्येक विशेषता के महत्व को समझने के लिए एक उत्कृष्ट विकल्प बनाती है।
","image":"http://www.luping.net/uploads/20241006/17282217676702924713227.png","datePublished":"2024-11-02T21:56:21+08:00","dateModified":"2024-11-02T21:56:21+08:00","author":{"@type":"Person","name":"luping.net","url":"https://www.luping.net/articlelist/0_1.html"}} ब्राउज़ करें:730
ब्राउज़ करें:730
एक मशीन लर्निंग मॉडल अनिवार्य रूप से नियमों या तंत्रों का एक सेट है जिसका उपयोग भविष्यवाणियां करने या डेटा में पैटर्न खोजने के लिए किया जाता है। सरल शब्दों में कहें तो (और अतिसरलीकरण के डर के बिना), एक्सेल में न्यूनतम वर्ग विधि का उपयोग करके गणना की गई ट्रेंडलाइन भी एक मॉडल है। हालाँकि, वास्तविक अनुप्रयोगों में उपयोग किए जाने वाले मॉडल इतने सरल नहीं होते हैं - उनमें अक्सर सरल समीकरण नहीं, बल्कि अधिक जटिल समीकरण और एल्गोरिदम शामिल होते हैं।
इस पोस्ट में, मैं एक बहुत ही सरल मशीन लर्निंग मॉडल बनाकर शुरुआत करने जा रहा हूं और प्रक्रिया को समझने के लिए इसे एक बहुत ही सरल वेब ऐप के रूप में जारी कर रहा हूं।
यहां, मैं केवल प्रक्रिया पर ध्यान केंद्रित करूंगा, एमएल मॉडल पर नहीं। इसके अलावा मैं पायथन वेब एप्लिकेशन को आसानी से जारी करने के लिए स्ट्रीमलिट और स्ट्रीमलिट कम्युनिटी क्लाउड का उपयोग करूंगा।
मशीन लर्निंग के लिए एक लोकप्रिय पायथन लाइब्रेरी स्किकिट-लर्न का उपयोग करके, आप डेटा को जल्दी से प्रशिक्षित कर सकते हैं और सरल कार्यों के लिए कोड की कुछ पंक्तियों के साथ एक मॉडल बना सकते हैं। फिर मॉडल को जॉबलिब के साथ पुन: प्रयोज्य फ़ाइल के रूप में सहेजा जा सकता है। इस सहेजे गए मॉडल को वेब एप्लिकेशन में नियमित पायथन लाइब्रेरी की तरह आयात/लोड किया जा सकता है, जिससे ऐप प्रशिक्षित मॉडल का उपयोग करके भविष्यवाणियां कर सकता है!
ऐप यूआरएल: https://yh-machine-learning.streamlit.app/
GitHub: https://github.com/yoshan0921/yh-machine-learning.git
यह ऐप आपको पामर पेंगुइन डेटासेट पर प्रशिक्षित यादृच्छिक वन मॉडल द्वारा की गई भविष्यवाणियों की जांच करने की अनुमति देता है। (प्रशिक्षण डेटा पर अधिक विवरण के लिए इस लेख का अंत देखें।)
विशेष रूप से, मॉडल विभिन्न विशेषताओं के आधार पर पेंगुइन प्रजातियों की भविष्यवाणी करता है, जिसमें प्रजाति, द्वीप, चोंच की लंबाई, फ्लिपर की लंबाई, शरीर का आकार और लिंग शामिल हैं। उपयोगकर्ता यह देखने के लिए ऐप पर नेविगेट कर सकते हैं कि विभिन्न सुविधाएं मॉडल की भविष्यवाणियों को कैसे प्रभावित करती हैं।
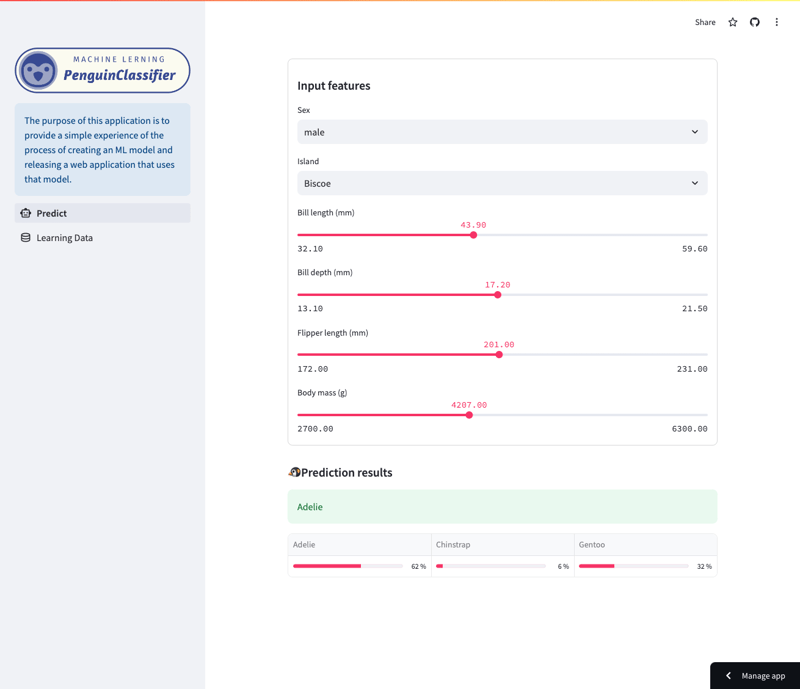
भविष्यवाणी स्क्रीन
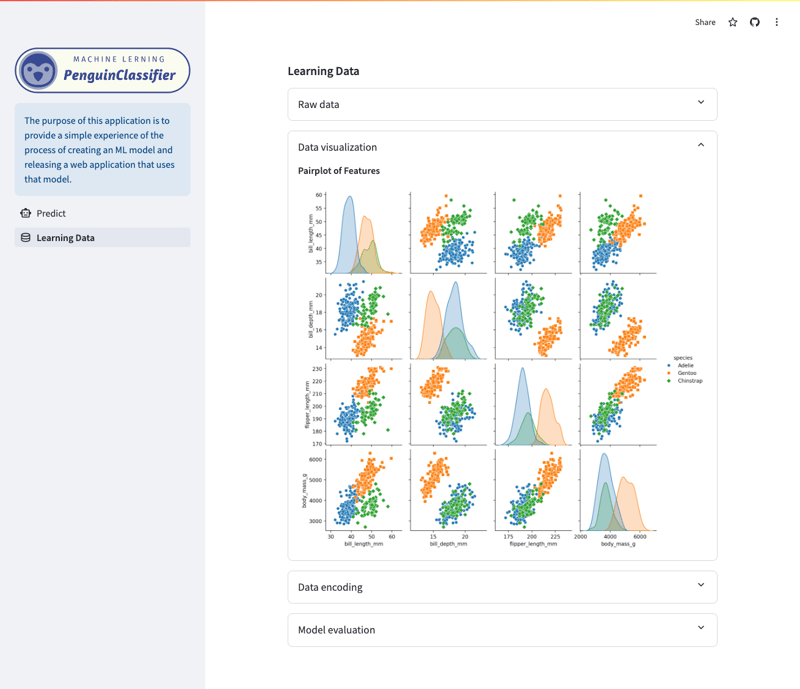
लर्निंग डेटा/विज़ुअलाइज़ेशन स्क्रीन
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score import joblib
pandas एक पायथन लाइब्रेरी है जो डेटा हेरफेर और विश्लेषण में विशेषज्ञता रखती है। यह डेटाफ्रेम का उपयोग करके डेटा लोडिंग, प्रीप्रोसेसिंग और संरचना का समर्थन करता है, मशीन लर्निंग मॉडल के लिए डेटा तैयार करता है।
sklearn मशीन लर्निंग के लिए एक व्यापक पायथन लाइब्रेरी है जो प्रशिक्षण और मूल्यांकन के लिए उपकरण प्रदान करती है। इस पोस्ट में, मैं रैंडम फ़ॉरेस्ट नामक शिक्षण पद्धति का उपयोग करके एक मॉडल बनाऊंगा।
joblib एक पायथन लाइब्रेरी है जो मशीन लर्निंग मॉडल जैसे पायथन ऑब्जेक्ट्स को बहुत ही कुशल तरीके से सहेजने और लोड करने में मदद करती है।
df = pd.read_csv("./dataset/penguins_cleaned.csv")
X_raw = df.drop("species", axis=1)
y_raw = df.species
डेटासेट (प्रशिक्षण डेटा) लोड करें और इसे सुविधाओं (एक्स) और लक्ष्य चर (वाई) में अलग करें।
encode = ["island", "sex"]
X_encoded = pd.get_dummies(X_raw, columns=encode)
target_mapper = {"Adelie": 0, "Chinstrap": 1, "Gentoo": 2}
y_encoded = y_raw.apply(lambda x: target_mapper[x])
श्रेणीबद्ध चर को एक-हॉट एन्कोडिंग (X_encoded) का उपयोग करके संख्यात्मक प्रारूप में परिवर्तित किया जाता है। उदाहरण के लिए, यदि "द्वीप" में "बिस्को", "ड्रीम" और "टॉर्गर्सन" श्रेणियां शामिल हैं, तो प्रत्येक के लिए एक नया कॉलम बनाया जाता है (द्वीप_बिस्को, द्वीप_ड्रीम, द्वीप_टॉर्गर्सन)। सेक्स के लिए भी ऐसा ही किया जाता है. यदि मूल डेटा "बिस्को" है, तो आइलैंड_बिस्को कॉलम को 1 और अन्य को 0 पर सेट किया जाएगा।
लक्ष्य चर प्रजाति को संख्यात्मक मानों (y_encoded) पर मैप किया जाता है।
x_train, x_test, y_train, y_test = train_test_split(
X_encoded, y_encoded, test_size=0.3, random_state=1
)
किसी मॉडल का मूल्यांकन करने के लिए, प्रशिक्षण के लिए उपयोग नहीं किए गए डेटा पर मॉडल के प्रदर्शन को मापना आवश्यक है। मशीन लर्निंग में सामान्य अभ्यास के रूप में 7:3 का व्यापक रूप से उपयोग किया जाता है।
clf = RandomForestClassifier() clf.fit(x_train, y_train)
मॉडल को प्रशिक्षित करने के लिए फिट विधि का उपयोग किया जाता है।
x_train व्याख्यात्मक चर के लिए प्रशिक्षण डेटा का प्रतिनिधित्व करता है, और y_train लक्ष्य चर का प्रतिनिधित्व करता है।
इस पद्धति को कॉल करके, प्रशिक्षण डेटा के आधार पर प्रशिक्षित मॉडल को सीएलएफ में संग्रहीत किया जाता है।
joblib.dump(clf, "penguin_classifier_model.pkl")
joblib.dump() पायथन ऑब्जेक्ट को बाइनरी प्रारूप में सहेजने के लिए एक फ़ंक्शन है। इस प्रारूप में मॉडल को सहेजकर, मॉडल को एक फ़ाइल से लोड किया जा सकता है और दोबारा प्रशिक्षित किए बिना उसी रूप में उपयोग किया जा सकता है।
import streamlit as st import numpy as np import pandas as pd import joblib
stremlit एक पायथन लाइब्रेरी है जो मशीन लर्निंग और डेटा साइंस प्रोजेक्ट्स के लिए कस्टम वेब एप्लिकेशन बनाना और साझा करना आसान बनाती है।
numpy संख्यात्मक कंप्यूटिंग के लिए एक मौलिक पायथन लाइब्रेरी है। यह इन सरणियों पर कुशलतापूर्वक संचालन करने के लिए गणितीय कार्यों के संग्रह के साथ-साथ बड़े, बहु-आयामी सरणियों और मैट्रिक्स के लिए समर्थन प्रदान करता है।
data = {
"island": island,
"bill_length_mm": bill_length_mm,
"bill_depth_mm": bill_depth_mm,
"flipper_length_mm": flipper_length_mm,
"body_mass_g": body_mass_g,
"sex": sex,
}
input_df = pd.DataFrame(data, index=[0])
encode = ["island", "sex"]
input_encoded_df = pd.get_dummies(input_df, prefix=encode)
इनपुट मान स्ट्रेम्लिट द्वारा बनाए गए इनपुट फॉर्म से पुनर्प्राप्त किए जाते हैं, और श्रेणीगत चर को उन्हीं नियमों का उपयोग करके एन्कोड किया जाता है जैसे मॉडल बनाया गया था। ध्यान दें कि प्रत्येक डेटा का क्रम भी वही होना चाहिए जब मॉडल बनाया गया था। यदि क्रम भिन्न है, तो मॉडल का उपयोग करके पूर्वानुमान निष्पादित करते समय एक त्रुटि उत्पन्न होगी।
clf = joblib.load("penguin_classifier_model.pkl")
"penguin_classifier_model.pkl" वह फ़ाइल है जहां पहले से सहेजा गया मॉडल संग्रहीत है। इस फ़ाइल में बाइनरी प्रारूप में एक प्रशिक्षित RandomForestClassifier शामिल है। इस कोड को चलाने से मॉडल सीएलएफ में लोड हो जाता है, जिससे आप इसे नए डेटा पर पूर्वानुमान और मूल्यांकन के लिए उपयोग कर सकते हैं।
prediction = clf.predict(input_encoded_df) prediction_proba = clf.predict_proba(input_encoded_df)
clf.predict(input_encoded_df): नए एन्कोडेड इनपुट डेटा के लिए वर्ग की भविष्यवाणी करने के लिए प्रशिक्षित मॉडल का उपयोग करता है, परिणाम को भविष्यवाणी में संग्रहीत करता है।
clf.predict_proba(input_encoded_df): प्रत्येक वर्ग के लिए संभाव्यता की गणना करता है, परिणामों को भविष्यवाणी_प्रोबा में संग्रहीत करता है।
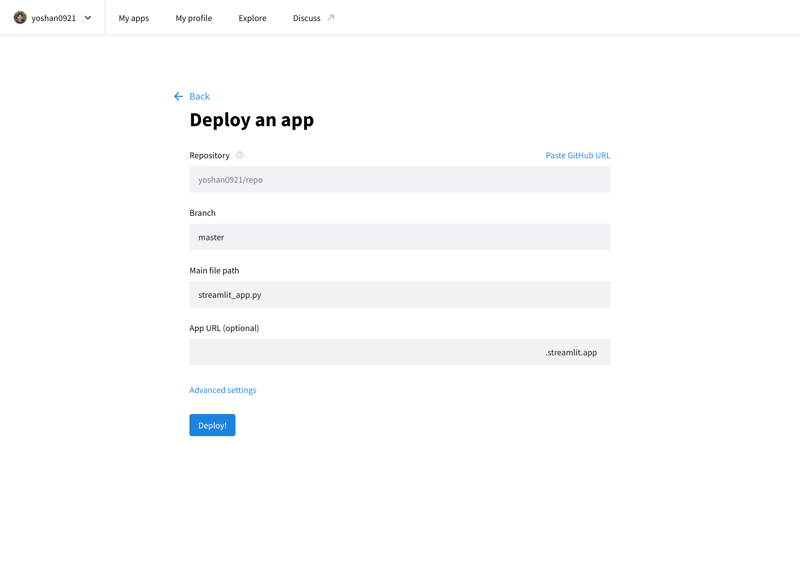
आप स्ट्रेमलिट कम्युनिटी क्लाउड (https://streamlit.io/cloud) तक पहुंच कर और GitHub रिपॉजिटरी का URL निर्दिष्ट करके अपने विकसित एप्लिकेशन को इंटरनेट पर प्रकाशित कर सकते हैं।

@allison_horst द्वारा कलाकृति (https://github.com/allisonhorst)
मॉडल को पामर पेंगुइन डेटासेट का उपयोग करके प्रशिक्षित किया जाता है, जो मशीन लर्निंग तकनीकों का अभ्यास करने के लिए व्यापक रूप से मान्यता प्राप्त डेटासेट है। यह डेटासेट अंटार्कटिका में पामर द्वीपसमूह से तीन पेंगुइन प्रजातियों (एडेली, चिनस्ट्रैप और जेंटू) के बारे में जानकारी प्रदान करता है। मुख्य विशेषताओं में शामिल हैं:
यह डेटासेट कागल से लिया गया है, और इसे यहां एक्सेस किया जा सकता है। विशेषताओं में विविधता इसे वर्गीकरण मॉडल बनाने और प्रजातियों की भविष्यवाणी में प्रत्येक विशेषता के महत्व को समझने के लिए एक उत्कृष्ट विकल्प बनाती है।















अस्वीकरण: उपलब्ध कराए गए सभी संसाधन आंशिक रूप से इंटरनेट से हैं। यदि आपके कॉपीराइट या अन्य अधिकारों और हितों का कोई उल्लंघन होता है, तो कृपया विस्तृत कारण बताएं और कॉपीराइट या अधिकारों और हितों का प्रमाण प्रदान करें और फिर इसे ईमेल पर भेजें: [email protected] हम इसे आपके लिए यथाशीघ्र संभालेंगे।
Copyright© 2022 湘ICP备2022001581号-3










