
किसी दिए गए स्टैक से डुप्लिकेट हटाने के लिए जावा प्रोग्राम
 ब्राउज़ करें:235
ब्राउज़ करें:235
इस लेख में, हम जावा में स्टैक से डुप्लिकेट तत्वों को हटाने के लिए दो तरीकों का पता लगाएंगे। हम एक सीधे दृष्टिकोण की तुलना नेस्टेड लूप्स और हैशसेट का उपयोग करके एक अधिक कुशल विधि से करेंगे। लक्ष्य यह प्रदर्शित करना है कि डुप्लिकेट निष्कासन को कैसे अनुकूलित किया जाए और प्रत्येक दृष्टिकोण के प्रदर्शन का मूल्यांकन किया जाए।
समस्या का विवरण
स्टैक से डुप्लिकेट तत्व को हटाने के लिए एक जावा प्रोग्राम लिखें।
इनपुट
Stackdata = initData(10L);
आउटपुट
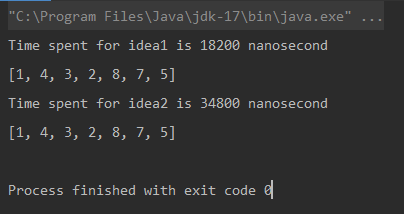
Unique elements using Naive Approach: [1, 4, 3, 2, 8, 7, 5] Time spent for Naive Approach: 18200 nanoseconds Unique elements using Optimized Approach: [1, 4, 3, 2, 8, 7, 5] Time spent for Optimized Approach: 34800 nanoseconds
किसी दिए गए स्टैक से डुप्लिकेट हटाने के लिए, हमारे पास 2 दृष्टिकोण हैं -
- निष्पक्ष दृष्टिकोण: यह देखने के लिए कि कौन से तत्व पहले से मौजूद हैं, दो नेस्टेड लूप्स बनाएं और उन्हें परिणाम स्टैक रिटर्न में जोड़ने से रोकें।
- हैशसेट दृष्टिकोण: अद्वितीय तत्वों को संग्रहीत करने के लिए एक सेट का उपयोग करें, और यह जांचने के लिए कि कोई तत्व मौजूद है या नहीं, इसकी O(1) जटिलता का लाभ उठाएं।
यादृच्छिक स्टैक उत्पन्न करना और क्लोन करना
नीचे बताया गया है कि जावा प्रोग्राम पहले एक यादृच्छिक स्टैक बनाता है और फिर आगे उपयोग के लिए इसका एक डुप्लिकेट बनाता है -
private static Stack initData(Long size) {
Stack stack = new Stack ();
Random random = new Random();
int bound = (int) Math.ceil(size * 0.75);
for (int i = 0; i manualCloneStack(Stack stack) {
Stack newStack = new Stack ();
for (Integer item: stack) {
newStack.push(item);
}
return newStack;
}
initData एक निर्दिष्ट आकार और 1 से 100 तक के यादृच्छिक तत्वों के साथ एक स्टैक बनाने में मदद करता है।
manualCloneStack दो विचारों के बीच प्रदर्शन तुलना के लिए इसका उपयोग करके दूसरे स्टैक से डेटा कॉपी करके डेटा उत्पन्न करने में मदद करता है।
Naive दृष्टिकोण का उपयोग करके दिए गए स्टैक से डुप्लिकेट हटाएं
Naive दृष्टिकोण का उपयोग करके किसी दिए गए स्टैक से डुप्लिकेट को हटाने का चरण निम्नलिखित है -
- टाइमर प्रारंभ करें।
- अद्वितीय तत्वों को संग्रहीत करने के लिए एक खाली स्टैक बनाएं।
- while लूप का उपयोग करके पुनरावृति करें और तब तक जारी रखें जब तक कि मूल स्टैक खाली न हो जाए, शीर्ष तत्व को पॉप करें।
- यह देखने के लिए कि क्या तत्व पहले से ही परिणाम स्टैक में है, resultStack.contains(element) का उपयोग करके डुप्लिकेट की जांच करें।
- यदि तत्व परिणाम स्टैक में नहीं है, तो उसे परिणाम स्टैक में जोड़ें।
- अंत समय रिकॉर्ड करें और बिताए गए कुल समय की गणना करें।
- वापसी परिणाम
उदाहरण
Naive दृष्टिकोण का उपयोग करके दिए गए स्टैक से डुप्लिकेट को हटाने के लिए नीचे जावा प्रोग्राम दिया गया है -
public static Stack idea1(Stack stack) {
long start = System.nanoTime();
Stack resultStack = new Stack ();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!resultStack.contains(element)) {
resultStack.add(element);
}
}
System.out.println("Time spent for idea1 is %d nanosecond".formatted(System.nanoTime() - start));
return resultStack;
}
नाइव दृष्टिकोण के लिए, हम उपयोग करते हैं
while (!stack.isEmpty())
resultStack.contains(element)
यह जांचने के लिए कि क्या तत्व पहले से मौजूद है। अनुकूलित दृष्टिकोण (हैशसेट) का उपयोग करके दिए गए स्टैक से डुप्लिकेट हटाएं
अनुकूलित दृष्टिकोण का उपयोग करके किसी दिए गए स्टैक से डुप्लिकेट को हटाने के चरण निम्नलिखित हैं -
- टाइमर प्रारंभ करें
- देखे गए तत्वों को ट्रैक करने के लिए एक सेट बनाएं (O(1) जटिलता जांच के लिए)।
- अद्वितीय तत्वों को संग्रहीत करने के लिए एक अस्थायी स्टैक बनाएं।
- while लूप का उपयोग करके पुनरावृति तब तक जारी रखें जब तक स्टैक खाली न हो जाए।
- स्टैक से शीर्ष तत्व को हटा दें।
- डुप्लिकेट की जांच करने के लिए हम यह जांचने के लिए seen.contains(element) का उपयोग करेंगे कि क्या तत्व पहले से ही सेट में है।
- यदि तत्व सेट में नहीं है, तो इसे दृश्य और अस्थायी स्टैक दोनों में जोड़ें।
- अंत समय रिकॉर्ड करें और बिताए गए कुल समय की गणना करें।
- परिणाम लौटाएं
उदाहरण
हैशसेट का उपयोग करके दिए गए स्टैक से डुप्लिकेट को हटाने के लिए नीचे जावा प्रोग्राम है -
public static Stackidea2(Stack stack) { long start = System.nanoTime(); Set seen = new HashSet(); Stack tempStack = new Stack(); while (!stack.isEmpty()) { int element = stack.pop(); if (!seen.contains(element)) { seen.add(element); tempStack.push(element); } } System.out.println("Time spent for idea2 is %d nanosecond".formatted(System.nanoTime() - start)); return tempStack; }
अनुकूलित दृष्टिकोण के लिए, हम
का उपयोग करते हैंSet seen दोनों दृष्टिकोणों का एक साथ उपयोग करना
ऊपर उल्लिखित दोनों तरीकों का उपयोग करके दिए गए स्टैक से डुप्लिकेट को हटाने का चरण नीचे दिया गया है -
- प्रारंभिक डेटा हम यादृच्छिक पूर्णांकों से भरा स्टैक बनाने के लिए initData(Long size) विधि का उपयोग कर रहे हैं।
- स्टैक को क्लोन करें हम मूल स्टैक की एक सटीक प्रतिलिपि बनाने के लिए cloneStack(स्टैक स्टैक) विधि का उपयोग कर रहे हैं।
- initData के साथ प्रारंभिक स्टैक जेनरेट करें।
- cloneStack का उपयोग करके इस स्टैक को क्लोन करें।
- मूल स्टैक से डुप्लिकेट हटाने के लिए निष्क्रिय दृष्टिकोण लागू करें।
- क्लोन किए गए स्टैक से डुप्लिकेट को हटाने के लिए अनुकूलित दृष्टिकोण लागू करें।
- प्रत्येक विधि के लिए लिया गया समय और दोनों दृष्टिकोणों द्वारा उत्पादित अद्वितीय तत्वों को प्रदर्शित करें
उदाहरण
नीचे जावा प्रोग्राम है जो ऊपर उल्लिखित दोनों तरीकों का उपयोग करके स्टैक से डुप्लिकेट तत्वों को हटा देता है -
import java.util.HashSet;
import java.util.Random;
import java.util.Set;
import java.util.Stack;
public class DuplicateStackElements {
private static Stack initData(Long size) {
Stack stack = new Stack();
Random random = new Random();
int bound = (int) Math.ceil(size * 0.75);
for (int i = 0; i cloneStack(Stack stack) {
Stack newStack = new Stack();
newStack.addAll(stack);
return newStack;
}
public static Stack idea1(Stack stack) {
long start = System.nanoTime();
Stack resultStack = new Stack();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!resultStack.contains(element)) {
resultStack.add(element);
}
}
System.out.printf("Time spent for idea1 is %d nanoseconds%n", System.nanoTime() - start);
return resultStack;
}
public static Stack idea2(Stack stack) {
long start = System.nanoTime();
Set seen = new HashSet();
Stack tempStack = new Stack();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!seen.contains(element)) {
seen.add(element);
tempStack.push(element);
}
}
System.out.printf("Time spent for idea2 is %d nanoseconds%n", System.nanoTime() - start);
return tempStack;
}
public static void main(String[] args) {
Stack data1 = initData(10L);
Stack data2 = cloneStack(data1);
System.out.println("Unique elements using idea1: " idea1(data1));
System.out.println("Unique elements using idea2: " idea2(data2));
}
}
आउटपुट
तुलना
* माप की इकाई नैनोसेकंड है।
public static void main(String[] args) {
Stack data1 = initData();
Stack data2 = manualCloneStack(data1);
idea1(data1);
idea2(data2);
}
| तरीका | 100 तत्व | 1000 तत्व | 10000 तत्व |
100000 तत्व |
1000000 तत्व |
| विचार 1 | 693100 |
4051600 |
19026900 |
114201800 |
1157256000 |
| आइडिया 2 | 135800 |
681400 |
2717800 |
11489400 |
36456100 |
जैसा कि देखा गया है, आइडिया 2 के लिए चलने का समय आइडिया 1 की तुलना में कम है क्योंकि आइडिया 1 की जटिलता O(n²) है, जबकि आइडिया 2 की जटिलता O(n) है। इसलिए, जब ढेरों की संख्या बढ़ती है, तो उसके आधार पर गणना पर लगने वाला समय भी बढ़ जाता है।
-
 मैं MySQL का उपयोग करके आज के जन्मदिन वाले उपयोगकर्ताओं को कैसे ढूँढ सकता हूँ?MySQL का उपयोग करके आज के जन्मदिन वाले उपयोगकर्ताओं की पहचान कैसे करेंMySQL का उपयोग करके यह निर्धारित करना कि आज उपयोगकर्ता का जन्मदिन है या नहीं, इस...प्रोग्रामिंग 2025-01-05 को प्रकाशित
मैं MySQL का उपयोग करके आज के जन्मदिन वाले उपयोगकर्ताओं को कैसे ढूँढ सकता हूँ?MySQL का उपयोग करके आज के जन्मदिन वाले उपयोगकर्ताओं की पहचान कैसे करेंMySQL का उपयोग करके यह निर्धारित करना कि आज उपयोगकर्ता का जन्मदिन है या नहीं, इस...प्रोग्रामिंग 2025-01-05 को प्रकाशित -
`if` कथनों से परे: स्पष्ट `bool` रूपांतरण वाले प्रकार को कास्टिंग के बिना और कहाँ उपयोग किया जा सकता है?बूल में प्रासंगिक रूपांतरण बिना किसी कास्ट के स्वीकृतआपकी कक्षा बूल में एक स्पष्ट रूपांतरण को परिभाषित करती है, जिससे आप सीधे सशर्त बयानों में इसके उद...प्रोग्रामिंग 2025-01-05 को प्रकाशित
-
सरणीतरीके एफएनएस हैं जिन्हें ऑब्जेक्ट पर कॉल किया जा सकता है ऐरे ऑब्जेक्ट हैं, इसलिए जेएस में उनके तरीके भी हैं। स्लाइस (शुरू): मूल सरणी को बदले ब...प्रोग्रामिंग 2025-01-05 को प्रकाशित
-
जावास्क्रिप्ट ऑब्जेक्ट्स में कुंजी को गतिशील रूप से कैसे सेट करें?जावास्क्रिप्ट ऑब्जेक्ट वेरिएबल के लिए डायनामिक कुंजी कैसे बनाएंजावास्क्रिप्ट ऑब्जेक्ट के लिए डायनामिक कुंजी बनाने का प्रयास करते समय, इस सिंटैक्स का उ...प्रोग्रामिंग 2025-01-05 को प्रकाशित
-
मैं जावा स्ट्रिंग में एकाधिक सबस्ट्रिंग को कुशलतापूर्वक कैसे बदल सकता हूं?जावा में एक स्ट्रिंग में एकाधिक सबस्ट्रिंग को कुशलतापूर्वक बदलनाजब एक स्ट्रिंग के भीतर कई सबस्ट्रिंग को बदलने की आवश्यकता का सामना करना पड़ता है, तो य...प्रोग्रामिंग 2025-01-05 को प्रकाशित
-
जेएस और मूल बातेंजावास्क्रिप्ट और प्रोग्रामिंग फंडामेंटल के लिए एक शुरुआती मार्गदर्शिका जावास्क्रिप्ट (जेएस) एक शक्तिशाली और बहुमुखी प्रोग्रामिंग भाषा है जिसका उपयोग म...प्रोग्रामिंग 2025-01-05 को प्रकाशित
-
PHP के फ़ंक्शन पुनर्परिभाषा प्रतिबंधों पर कैसे काबू पाएं?PHP की फ़ंक्शन पुनर्परिभाषा सीमाओं पर काबू पानाPHP में, एक ही नाम के साथ एक फ़ंक्शन को कई बार परिभाषित करना एक नो-नो है। ऐसा करने का प्रयास करने पर, ज...प्रोग्रामिंग 2025-01-05 को प्रकाशित
-
MacOS पर Django में \"अनुचित कॉन्फ़िगर: MySQLdb मॉड्यूल लोड करने में त्रुटि\" को कैसे ठीक करें?MySQL अनुचित रूप से कॉन्फ़िगर किया गया: सापेक्ष पथों के साथ समस्याDjango में Python मैनेज.py runserver चलाते समय, आपको निम्न त्रुटि का सामना करना पड़ ...प्रोग्रामिंग 2025-01-05 को प्रकाशित
-
क्या मैं अपने एन्क्रिप्शन को एमक्रिप्ट से ओपनएसएसएल में स्थानांतरित कर सकता हूं, और ओपनएसएसएल का उपयोग करके एमक्रिप्ट-एन्क्रिप्टेड डेटा को डिक्रिप्ट कर सकता हूं?मेरी एन्क्रिप्शन लाइब्रेरी को Mcrypt से OpenSSL में अपग्रेड करनाक्या मैं अपनी एन्क्रिप्शन लाइब्रेरी को Mcrypt से OpenSSL में अपग्रेड कर सकता हूं? ओपनए...प्रोग्रामिंग 2025-01-05 को प्रकाशित
-
HTML फ़ॉर्मेटिंग टैगHTML फ़ॉर्मेटिंग तत्व **HTML Formatting is a process of formatting text for better look and feel. HTML provides us ability to format text...प्रोग्रामिंग 2025-01-05 को प्रकाशित
-
मैं अद्वितीय आईडी को संरक्षित करते हुए और डुप्लिकेट नामों को संभालते हुए PHP में दो सहयोगी सरणियों को कैसे जोड़ूं?PHP में एसोसिएटिव एरेज़ का संयोजनPHP में, दो एसोसिएटिव एरेज़ को एक ही एरे में संयोजित करना एक सामान्य कार्य है। निम्नलिखित अनुरोध पर विचार करें:समस्या...प्रोग्रामिंग 2025-01-05 को प्रकाशित
-
डेटा डालते समय ''सामान्य त्रुटि: 2006 MySQL सर्वर चला गया है'' को कैसे ठीक करें?रिकॉर्ड सम्मिलित करते समय "सामान्य त्रुटि: 2006 MySQL सर्वर चला गया है" को कैसे हल करेंपरिचय:MySQL डेटाबेस में डेटा डालने से कभी-कभी त्रुटि ...प्रोग्रामिंग 2025-01-05 को प्रकाशित
-
वैध कोड के बावजूद पोस्ट अनुरोध PHP में इनपुट कैप्चर क्यों नहीं कर रहा है?PHP में POST अनुरोध की खराबी को संबोधित करनाप्रस्तुत कोड स्निपेट में:action=''इरादा टेक्स्ट बॉक्स से इनपुट कैप्चर करना और सबमिट बटन पर क्लिक करने पर इ...प्रोग्रामिंग 2025-01-05 को प्रकाशित
-
पांडास डेटाफ़्रेम कॉलम से शून्य मान वाली पंक्तियाँ कैसे निकालें?पांडा डेटाफ़्रेम कॉलम से शून्य मान हटानाकिसी विशिष्ट कॉलम में शून्य मान के आधार पर पांडा डेटाफ़्रेम से पंक्तियों को हटाने के लिए, इनका पालन करें चरण:1...प्रोग्रामिंग 2025-01-01 को प्रकाशित
-
मैं गो में इंटरफ़ेस मानों के एक स्लाइस को सही ढंग से कैसे टाइप कर सकता हूँ?इंटरफ़ेस मानों के एक स्लाइस को टाइप करनाप्रोग्रामिंग में, ऐसी स्थितियों का सामना करना आम है जहां आपको इंटरफ़ेस मानों के एक स्लाइस को टाइप करने की आवश्...प्रोग्रामिंग 2025-01-01 को प्रकाशित















चीनी भाषा का अध्ययन करें
- 1 आप चीनी भाषा में "चलना" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 2 आप चीनी भाषा में "विमान ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 3 आप चीनी भाषा में "ट्रेन ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 4 आप चीनी भाषा में "बस ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 5 चीनी भाषा में ड्राइव को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 6 तैराकी को चीनी भाषा में क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 7 आप चीनी भाषा में साइकिल चलाने को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 8 आप चीनी भाषा में नमस्ते कैसे कहते हैं? 你好चीनी उच्चारण, 你好चीनी सीखना
- 9 आप चीनी भाषा में धन्यवाद कैसे कहते हैं? 谢谢चीनी उच्चारण, 谢谢चीनी सीखना
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









