 मुखपृष्ठ > प्रोग्रामिंग > फायरडक्स: शून्य शिक्षण लागत के साथ पांडा से भी बेहतर प्रदर्शन प्राप्त करें!
मुखपृष्ठ > प्रोग्रामिंग > फायरडक्स: शून्य शिक्षण लागत के साथ पांडा से भी बेहतर प्रदर्शन प्राप्त करें!
फायरडक्स: शून्य शिक्षण लागत के साथ पांडा से भी बेहतर प्रदर्शन प्राप्त करें!
 ब्राउज़ करें:593
ब्राउज़ करें:593
पांडास सबसे लोकप्रिय पुस्तकालयों में से एक है, जब मैं इसके प्रदर्शन को तेज करने का एक आसान तरीका ढूंढ रहा था, तो मैंने फायरडक्स की खोज की और इसमें रुचि हो गई!
पांडा के साथ तुलना: फायरडक्स क्यों?
एक पांडा कार्यक्रम को कैसे लिखा गया है इसके आधार पर एक गंभीर प्रदर्शन समस्या का सामना करना पड़ सकता है। हालाँकि, एक डेटा वैज्ञानिक होने के नाते, मैं अपने कोड प्रदर्शन में सुधार करने के बजाय डेटा का विश्लेषण करने में अधिक से अधिक समय व्यतीत करना चाहता हूँ। इसलिए, यह बहुत अच्छा होगा यदि यह प्रक्रियाओं के क्रम को बदलने और प्रोग्राम के प्रदर्शन को स्वचालित रूप से तेज़ करने जैसा कुछ कर सके। उदाहरण के लिए, प्रक्रिया ए => प्रक्रिया बी धीमी होगी, इसलिए हम इसे प्रक्रिया बी => प्रक्रिया ए के रूप में प्रतिस्थापित करेंगे। (बेशक, परिणाम समान होने की गारंटी है।) ऐसा कहा जाता है कि डेटा वैज्ञानिक लगभग 45% खर्च करते हैं अपना समय डेटा तैयार करने में बिताया, और जब मैं इस प्रक्रिया को तेज़ करने के लिए कुछ करने के बारे में सोच रहा था, तो मुझे फ़ायरडक्स नामक एक मॉड्यूल मिला।
फ़ायरडक्स दस्तावेज़ से, ऐसा लगता है कि यह केवल लिनक्स प्लेटफ़ॉर्म के लिए समर्थित है। चूँकि मैं अपनी मुख्य मशीन पर विंडोज़ का उपयोग करता हूँ, इसलिए मैं इसे WSL2 (लिनक्स के लिए विंडोज़ सबसिस्टम) से आज़माना चाहूँगा, एक ऐसा वातावरण जो विंडोज़ पर लिनक्स चला सकता है।
मैंने जिस वातावरण का प्रयास किया वह इस प्रकार है।
- ओएस माइक्रोसॉफ्ट विंडोज 11 प्रो
- संस्करण 10.0.22631 बिल्ड 22631
- सिस्टम मॉडल Z690 प्रो आरएस
- सिस्टम प्रकार x64-आधारित
- पीसी प्रोसेसर 12वीं पीढ़ी इंटेल (आर) कोर (टीएम) i3-12100, 3300 मेगाहर्ट्ज, 4 कोर, 8 लॉजिकल प्रोसेसर
- बेसबोर्ड उत्पाद Z690 प्रो आरएस
- प्लेटफ़ॉर्म रोल डेस्कटॉप
- स्थापित भौतिक मेमोरी (रैम)64.0 जीबी
फ़ायरडक्स को स्थापित और कॉन्फ़िगर करना
डब्लूएसएल स्थापित करें
WSL को निम्नलिखित Microsoft दस्तावेज़ की सहायता से स्थापित किया गया था; लिनक्स वितरण Ubuntu 22.04.1 LTS है।
फ़ायरडक्स स्थापित करें
फिर वास्तव में फायरडक्स स्थापित करें। हालाँकि, इसे स्थापित करना बहुत आसान है।
पिप इंस्टॉल फ़ायरडक्स
फायरडक्स को स्थापित करने में कुछ मिनट लगेंगे (पाइरो, पांडा और अन्य पुस्तकालयों के साथ)।
मैंने नीचे दिए गए कोड को निष्पादित करने का प्रयास किया, लोडिंग गति इतनी तेज़ थी, पांडा को 4 सेकंड लगे और फायरडक्स को केवल 74.5 एनएस लगे।
# 1. analysis based on time period and creative duration # convert timestamp to date/time object df['timestamp_converted'] = pd.to_datetime(df['timestamp'], unit='s ') # define time period def get_part_of_day(hour): if 5इन सभी डेटा प्रीप्रोसेसिंग और विश्लेषण में पांडा में लगभग 8 सेकंड का समय लगा, जबकि फायरडक्स का उपयोग करते समय इसे 4 सेकंड के भीतर पूरा किया जा सकता था। लगभग 2 गुना गति प्राप्त की जा सकती है।
बेहतर प्रदर्शन
पांडा का उपयोग करने के बारे में सबसे तनावपूर्ण चीजों में से एक बड़े डेटा सेट को लोड करते समय इंतजार करना है, और फिर मुझे ग्रुपबी जैसे जटिल ऑपरेशन के लिए इंतजार करना पड़ता है। दूसरी ओर, चूंकि फायरडक्स आलसी मूल्यांकन करता है, लोडिंग में बिल्कुल भी समय नहीं लगता है, इसलिए प्रसंस्करण वहीं किया जाता है जहां इसकी आवश्यकता होती है, और मुझे लगा कि कुल प्रतीक्षा समय में बड़ी कमी के साथ यह बहुत महत्वपूर्ण था।
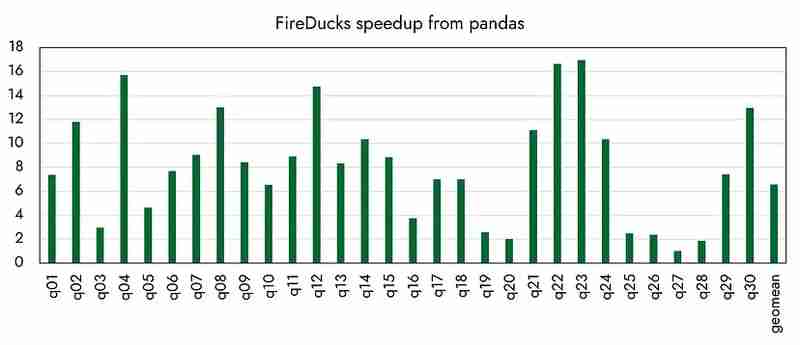
जहां तक अन्य प्रदर्शन का सवाल है, ऐसा लगता है कि पांडा की तुलना में 16 गुना अधिक तेजी से हासिल किया गया है, जैसा कि संगठन द्वारा आधिकारिक तौर पर घोषणा की गई है। (मैं अगली बार विभिन्न प्रतिस्पर्धी पुस्तकालयों के साथ प्रदर्शन की तुलना करूंगा।)
शून्य सीखने की लागत
बिना कुछ भी सोचे सटीक पांडा नोटेशन का पालन करने की क्षमता एक बहुत बड़ा लाभ है। फायरडक्स के अलावा, अन्य डेटा फ़्रेम एक्सेलेरेशन लाइब्रेरी भी हैं, लेकिन उन्हें सीखना बहुत महंगा है और भूलना बहुत आसान है।
उदाहरण के लिए, यदि आप ध्रुवों वाले कॉलम जोड़ना चाहते हैं, तो आपको कुछ इस तरह लिखना होगा।
# pandas df["new_col"] = df["A"] 1 # polars df = df.with_columns((pl.col("A") 1).alias("new_col"))मौजूदा कोड को बदलने की लगभग कोई आवश्यकता नहीं है
मेरे पास कई ईटीएल और अन्य परियोजनाएं हैं जो पांडा का उपयोग करती हैं, और आयात विवरण को फायरडक्स के साथ स्थापित और प्रतिस्थापित करके प्रदर्शन में सुधार देखना अच्छा होगा।
यदि आप इसे और जोड़ना चाहते हैं, तो बेझिझक नीचे टिप्पणी करें।
-
 Microsoft Visual C ++ दो-चरण टेम्पलेट तात्कालिकता को सही ढंग से लागू करने में विफल क्यों होता है?तंत्र के कौन से विशिष्ट पहलू अपेक्षित रूप से संचालित करने में विफल होते हैं? हालाँकि, इस बारे में संदेह उत्पन्न होता है कि क्या यह चेक सत्यापित करता ...प्रोग्रामिंग 2025-03-12 को पोस्ट किया गया
Microsoft Visual C ++ दो-चरण टेम्पलेट तात्कालिकता को सही ढंग से लागू करने में विफल क्यों होता है?तंत्र के कौन से विशिष्ट पहलू अपेक्षित रूप से संचालित करने में विफल होते हैं? हालाँकि, इस बारे में संदेह उत्पन्न होता है कि क्या यह चेक सत्यापित करता ...प्रोग्रामिंग 2025-03-12 को पोस्ट किया गया -
UTF-8 बनाम लैटिन -1: द सीक्रेट ऑफ कैरेक्टर एन्कोडिंग!] उनके अनुप्रयोगों के बीच, एक मौलिक प्रश्न उठता है: क्या समझदार विशेषताएं इन दो एन्कोडिंग को अलग करती हैं? जबकि लैटिन 1 विशेष रूप से लैटिन पात्रों को ...प्रोग्रामिंग 2025-03-12 को पोस्ट किया गया
-
सरणी] एरेज़ ऑब्जेक्ट हैं, इसलिए उनके पास जेएस में भी तरीके हैं। स्लाइस (शुरुआत): मूल सरणी को म्यूट किए बिना, एक नए सरणी में सरणी का हिस्सा निकाले...प्रोग्रामिंग 2025-03-12 को पोस्ट किया गया
-
मैं जावा स्ट्रिंग में कई सब्सट्रेट्स को कुशलता से कैसे बदल सकता हूं?] हालाँकि, यह बड़े तार के लिए अक्षम हो सकता है या जब कई तार के साथ काम कर रहा है। नियमित अभिव्यक्तियाँ आपको जटिल खोज पैटर्न को परिभाषित करने और एकल ऑप...प्रोग्रामिंग 2025-03-12 को पोस्ट किया गया
-
भाग SQL इंजेक्शन श्रृंखला: उन्नत SQL इंजेक्शन तकनीकों की विस्तृत व्याख्यावेमैप पेंटिंग टूल: यहां क्लिक करें TrixSec github: यहाँ क्लिक करें TRIXSEC टेलीग्राम: यहां क्लिक करें ] हमारी SQL इंजेक्शन श्रृंखला के...प्रोग्रामिंग 2025-03-12 को पोस्ट किया गया
-
PYTZ शुरू में अप्रत्याशित समय क्षेत्र ऑफसेट क्यों दिखाता है?] उदाहरण के लिए, एशिया/hong_kong शुरू में एक सात घंटे और 37 मिनट की ऑफसेट दिखाता है: आयात pytz Std> विसंगति स्रोत समय क्षेत्र और ऑफसेट प...प्रोग्रामिंग 2025-03-12 को पोस्ट किया गया
-
कैसे ठीक करें "सामान्य त्रुटि: 2006 MySQL सर्वर डेटा डालते समय दूर चला गया है?] यह त्रुटि तब होती है जब सर्वर का कनेक्शन खो जाता है, आमतौर पर MySQL कॉन्फ़िगरेशन में दो चर में से एक के कारण। ये चर उस अधिकतम समय को नियंत्रित करते ...प्रोग्रामिंग 2025-03-12 को पोस्ट किया गया
-
हम दुर्भावनापूर्ण सामग्री के खिलाफ फ़ाइल अपलोड को कैसे सुरक्षित कर सकते हैं?] इन खतरों को समझना और प्रभावी शमन रणनीतियों को लागू करना आपके आवेदन की सुरक्षा को बनाए रखने के लिए महत्वपूर्ण है। इसलिए, अपलोड की गई फ़ाइल के हर पहलू...प्रोग्रामिंग 2025-03-12 को पोस्ट किया गया
-
जावास्क्रिप्ट में नियमित अभिव्यक्तियों का उपयोग करके स्ट्रिंग्स से लाइन ब्रेक कैसे निकालें?] सवाल उठता है: .replace विधि के भीतर एक नियमित अभिव्यक्ति में लाइन ब्रेक का प्रतिनिधित्व कैसे किया जा सकता है? विंडोज "\ r \ n" अनुक्रम का ...प्रोग्रामिंग 2025-03-12 को पोस्ट किया गया
-
फ़ायरफ़ॉक्स बैक बटन का उपयोग करते समय जावास्क्रिप्ट निष्पादन क्यों बंद हो जाता है?] यह समस्या क्रोम और इंटरनेट एक्सप्लोरर जैसे अन्य ब्राउज़रों में नहीं होती है। इस समस्या को हल करने के लिए और बाद के पृष्ठ के दौरे पर स्क्रिप्ट निष्पा...प्रोग्रामिंग 2025-03-12 को पोस्ट किया गया
-
PHP का उपयोग करके MySQL में बूँदों (चित्र) को ठीक से कैसे डालें?] यह गाइड आपके छवि डेटा को सफलतापूर्वक संग्रहीत करने के लिए समाधान प्रदान करेगा। ImageStore (ImageId, Image) मान ('$ यह- & gt; image_id', ...प्रोग्रामिंग 2025-03-12 को पोस्ट किया गया
-
क्या मैं McRypt से OpenSSL में अपने एन्क्रिप्शन को माइग्रेट कर सकता हूं, और OpenSSL का उपयोग करके McRypt-encrypted डेटा को डिक्रिप्ट कर सकता हूं?] OpenSSL में, क्या McRypt के साथ एन्क्रिप्ट किए गए डेटा को डिक्रिप्ट करना संभव है? दो अलग -अलग पोस्ट परस्पर विरोधी जानकारी प्रदान करते हैं। यदि ऐसा ह...प्रोग्रामिंग 2025-03-12 को पोस्ट किया गया
-
जेएस और मूल बातें] ] जेएस और कोर प्रोग्रामिंग अवधारणाओं की मूल बातें समझना किसी को भी वेब विकास या सामान्य सॉफ्टवेयर प्रोग्रामिंग में गोता लगाने के लिए आवश्यक है। यह म...प्रोग्रामिंग 2025-03-12 को पोस्ट किया गया
-
क्या जावा में कलेक्शन ट्रैवर्सल के लिए एक-प्रत्येक लूप और एक पुनरावृत्ति का उपयोग करने के बीच एक प्रदर्शन अंतर है?के लिए यह लेख इन दो दृष्टिकोणों के बीच दक्षता के अंतर की पड़ताल करता है। यह आंतरिक रूप से iterator का उपयोग करता है: सूची a = new ArrayList ...प्रोग्रामिंग 2025-03-12 को पोस्ट किया गया
-
कैसे जांचें कि क्या किसी वस्तु की पायथन में एक विशिष्ट विशेषता है?] निम्नलिखित उदाहरण पर विचार करें जहां एक अपरिभाषित संपत्ति तक पहुंचने का प्रयास एक त्रुटि उठाता है: >>> a = someclass () >>> a.property ट्रेसबैक (स...प्रोग्रामिंग 2025-03-12 को पोस्ट किया गया















चीनी भाषा का अध्ययन करें
- 1 आप चीनी भाषा में "चलना" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 2 आप चीनी भाषा में "विमान ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 3 आप चीनी भाषा में "ट्रेन ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 4 आप चीनी भाषा में "बस ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 5 चीनी भाषा में ड्राइव को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 6 तैराकी को चीनी भाषा में क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 7 आप चीनी भाषा में साइकिल चलाने को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 8 आप चीनी भाषा में नमस्ते कैसे कहते हैं? 你好चीनी उच्चारण, 你好चीनी सीखना
- 9 आप चीनी भाषा में धन्यवाद कैसे कहते हैं? 谢谢चीनी उच्चारण, 谢谢चीनी सीखना
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









