
IAMB एल्गोरिथम के साथ फ़ीचर चयन: मशीन लर्निंग में एक आकस्मिक गोता
 ब्राउज़ करें:773
ब्राउज़ करें:773
तो, कहानी यह है—मैंने हाल ही में प्रोफेसर ज़ुआंग के एक स्कूल असाइनमेंट पर काम किया, जिसमें इंक्रीमेंटल एसोसिएशन मार्कोव ब्लैंकेट (आईएएमबी) नामक एक बहुत अच्छा एल्गोरिदम शामिल था। अब, मेरे पास डेटा विज्ञान या सांख्यिकी में कोई पृष्ठभूमि नहीं है, इसलिए यह मेरे लिए नया क्षेत्र है, लेकिन मुझे कुछ नया सीखना पसंद है। लक्ष्य? डेटासेट में सुविधाओं का चयन करने के लिए IAMB का उपयोग करें और देखें कि यह मशीन-लर्निंग मॉडल के प्रदर्शन को कैसे प्रभावित करता है।
हम IAMB एल्गोरिथम की बुनियादी बातों पर गौर करेंगे और इसे जेसन ब्राउनली के डेटासेट से पिमा इंडियंस डायबिटीज डेटासेट पर लागू करेंगे। यह डेटासेट महिलाओं के स्वास्थ्य डेटा को ट्रैक करता है और इसमें यह भी शामिल है कि उन्हें मधुमेह है या नहीं। हम यह पता लगाने के लिए IAMB का उपयोग करेंगे कि मधुमेह की भविष्यवाणी के लिए कौन सी विशेषताएं (जैसे बीएमआई या ग्लूकोज स्तर) सबसे अधिक मायने रखती हैं।
IAMB एल्गोरिथम क्या है, और इसका उपयोग क्यों करें?
आईएएमबी एल्गोरिथ्म एक मित्र की तरह है जो आपको किसी रहस्य में संदिग्धों की सूची को साफ करने में मदद करता है - यह एक सुविधा चयन विधि है जो केवल उन चर को चुनने के लिए डिज़ाइन की गई है जो वास्तव में आपके लक्ष्य की भविष्यवाणी करने के लिए महत्वपूर्ण हैं। इस मामले में, लक्ष्य यह है कि क्या किसी को मधुमेह है।
- आगे का चरण: ऐसे वेरिएबल जोड़ें जो लक्ष्य से दृढ़ता से संबंधित हों।
- पिछड़ा चरण: उन चरों को हटा दें जो वास्तव में मदद नहीं करते हैं, यह सुनिश्चित करते हुए कि केवल सबसे महत्वपूर्ण ही बचे हैं।
सरल शब्दों में, IAMB केवल सबसे प्रासंगिक सुविधाओं का चयन करके हमारे डेटासेट में अव्यवस्था से बचने में हमारी मदद करता है। यह विशेष रूप से तब उपयोगी होता है जब आप चीजों को सरल रखना चाहते हैं, मॉडल के प्रदर्शन को बढ़ावा देना चाहते हैं और प्रशिक्षण समय को तेज करना चाहते हैं।
स्रोत: बड़े पैमाने पर मार्कोव कंबल डिस्कवरी के लिए एल्गोरिदम
यह अल्फ़ा चीज़ क्या है, और यह क्यों मायने रखती है?
यहां वह जगह है जहां alpha आता है। आंकड़ों में, अल्फा (α) वह सीमा है जिसे हम यह तय करने के लिए निर्धारित करते हैं कि "सांख्यिकीय रूप से महत्वपूर्ण" के रूप में क्या गिना जाता है। प्रोफेसर द्वारा दिए गए निर्देशों के भाग के रूप में, मैंने 0.05 के अल्फा का उपयोग किया, जिसका अर्थ है कि मैं केवल उन विशेषताओं को रखना चाहता हूं जिनके लक्ष्य चर के साथ यादृच्छिक रूप से जुड़े होने की 5% से कम संभावना है। इसलिए, यदि किसी फीचर का पी-वैल्यू 0.05 से कम है, तो इसका मतलब है कि हमारे लक्ष्य के साथ एक मजबूत, सांख्यिकीय रूप से महत्वपूर्ण जुड़ाव है।
इस अल्फ़ा थ्रेशोल्ड का उपयोग करके, हम केवल सबसे सार्थक चर पर ध्यान केंद्रित कर रहे हैं, उन सभी को अनदेखा कर रहे हैं जो हमारे "महत्व" परीक्षण को पास नहीं करते हैं। यह एक फ़िल्टर की तरह है जो सबसे अधिक प्रासंगिक सुविधाओं को बनाए रखता है और शोर को दूर करता है।
व्यावहारिक जानकारी प्राप्त करना: पीमा इंडियंस मधुमेह डेटासेट पर IAMB का उपयोग करना
यहां सेटअप है: पीमा इंडियंस डायबिटीज डेटासेट में स्वास्थ्य विशेषताएं (रक्तचाप, आयु, इंसुलिन स्तर, आदि) और हमारा लक्ष्य, परिणाम (चाहे किसी को मधुमेह हो)।
सबसे पहले, हम डेटा लोड करते हैं और उसकी जांच करते हैं:
import pandas as pd # Load and preview the dataset url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv' column_names = ['Pregnancies', 'Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'DiabetesPedigreeFunction', 'Age', 'Outcome'] data = pd.read_csv(url, names=column_names) print(data.head())
IAMB को अल्फा = 0.05 के साथ लागू करना
यहां IAMB एल्गोरिथम का हमारा अद्यतन संस्करण है। हम यह तय करने के लिए पी-वैल्यू का उपयोग कर रहे हैं कि कौन सी सुविधाएं रखनी हैं, इसलिए केवल हमारे अल्फा (0.05) से कम पी-वैल्यू वाले लोगों का चयन किया जाता है।
import pingouin as pg
def iamb(target, data, alpha=0.05):
markov_blanket = set()
# Forward Phase: Add features with a p-value alpha
for feature in list(markov_blanket):
reduced_mb = markov_blanket - {feature}
result = pg.partial_corr(data=data, x=feature, y=target, covar=reduced_mb)
p_value = result.at[0, 'p-val']
if p_value > alpha:
markov_blanket.remove(feature)
return list(markov_blanket)
# Apply the updated IAMB function on the Pima dataset
selected_features = iamb('Outcome', data, alpha=0.05)
print("Selected Features:", selected_features)
जब मैंने इसे चलाया, तो इसने मुझे उन विशेषताओं की एक परिष्कृत सूची दी जो IAMB के अनुसार मधुमेह के परिणामों से सबसे अधिक निकटता से संबंधित थीं। यह सूची हमारे मॉडल के निर्माण के लिए आवश्यक वेरिएबल्स को कम करने में मदद करती है।
Selected Features: ['BMI', 'DiabetesPedigreeFunction', 'Pregnancies', 'Glucose']
मॉडल प्रदर्शन पर IAMB-चयनित सुविधाओं के प्रभाव का परीक्षण
एक बार जब हमारे पास हमारी चयनित विशेषताएं होती हैं, तो वास्तविक परीक्षण मॉडल के प्रदर्शन की तुलना सभी सुविधाओं बनाम आईएएमबी-चयनित सुविधाओं से करता है। इसके लिए, मैंने एक सरल गॉसियन नाइव बेयस मॉडल अपनाया क्योंकि यह सीधा है और संभावनाओं के साथ अच्छा प्रदर्शन करता है (जो पूरे बायेसियन वाइब के साथ जुड़ा हुआ है)।
मॉडल को प्रशिक्षित और परीक्षण करने के लिए यहां कोड है:
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score, f1_score, roc_auc_score
# Split data
X = data.drop('Outcome', axis=1)
y = data['Outcome']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Model with All Features
model_all = GaussianNB()
model_all.fit(X_train, y_train)
y_pred_all = model_all.predict(X_test)
# Model with IAMB-Selected Features
X_train_selected = X_train[selected_features]
X_test_selected = X_test[selected_features]
model_iamb = GaussianNB()
model_iamb.fit(X_train_selected, y_train)
y_pred_iamb = model_iamb.predict(X_test_selected)
# Evaluate models
results = {
'Model': ['All Features', 'IAMB-Selected Features'],
'Accuracy': [accuracy_score(y_test, y_pred_all), accuracy_score(y_test, y_pred_iamb)],
'F1 Score': [f1_score(y_test, y_pred_all, average='weighted'), f1_score(y_test, y_pred_iamb, average='weighted')],
'AUC-ROC': [roc_auc_score(y_test, y_pred_all), roc_auc_score(y_test, y_pred_iamb)]
}
results_df = pd.DataFrame(results)
display(results_df)
परिणाम
तुलना इस प्रकार दिखती है:
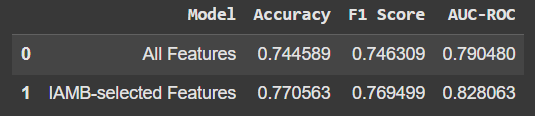
केवल IAMB-चयनित सुविधाओं का उपयोग करने से सटीकता और अन्य मेट्रिक्स में थोड़ी वृद्धि हुई। यह कोई बहुत बड़ी छलांग नहीं है, लेकिन यह तथ्य कि हमें कम सुविधाओं के साथ बेहतर प्रदर्शन मिल रहा है, आशाजनक है। साथ ही, इसका मतलब है कि हमारा मॉडल "शोर" या अप्रासंगिक डेटा पर निर्भर नहीं है।
चाबी छीनना
- आईएएमबी फीचर चयन के लिए बहुत अच्छा है: यह केवल हमारे लक्ष्य की भविष्यवाणी के लिए वास्तव में जो मायने रखता है उस पर ध्यान केंद्रित करके हमारे डेटासेट को साफ करने में मदद करता है।
- कम अक्सर अधिक होता है: कभी-कभी, कम सुविधाएं हमें बेहतर परिणाम देती हैं, जैसा कि हमने यहां मॉडल सटीकता में मामूली वृद्धि के साथ देखा।
- सीखना और प्रयोग करना मज़ेदार हिस्सा है: डेटा विज्ञान में गहरी पृष्ठभूमि के बिना भी, इस तरह की परियोजनाओं में गोता लगाने से डेटा और मशीन लर्निंग को समझने के नए तरीके खुलते हैं।
मुझे आशा है कि यह IAMB को एक मैत्रीपूर्ण परिचय देगा! यदि आप उत्सुक हैं, तो इसे आज़माएं—यह मशीन लर्निंग टूलबॉक्स में एक उपयोगी उपकरण है, और आप अपनी परियोजनाओं में कुछ अच्छे सुधार देख सकते हैं।
स्रोत: बड़े पैमाने पर मार्कोव कंबल डिस्कवरी के लिए एल्गोरिदम
-
 जावास्क्रिप्ट ऑब्जेक्ट्स में कुंजी को गतिशील रूप से कैसे सेट करें?जावास्क्रिप्ट ऑब्जेक्ट वेरिएबल के लिए डायनामिक कुंजी कैसे बनाएंजावास्क्रिप्ट ऑब्जेक्ट के लिए डायनामिक कुंजी बनाने का प्रयास करते समय, इस सिंटैक्स का उ...प्रोग्रामिंग 2024-11-18 को प्रकाशित
जावास्क्रिप्ट ऑब्जेक्ट्स में कुंजी को गतिशील रूप से कैसे सेट करें?जावास्क्रिप्ट ऑब्जेक्ट वेरिएबल के लिए डायनामिक कुंजी कैसे बनाएंजावास्क्रिप्ट ऑब्जेक्ट के लिए डायनामिक कुंजी बनाने का प्रयास करते समय, इस सिंटैक्स का उ...प्रोग्रामिंग 2024-11-18 को प्रकाशित -
क्या आपके पास एक ही जावा फ़ाइल में एकाधिक कक्षाएं हो सकती हैं?एक जावा फ़ाइल में एकाधिक कक्षाएंजावा में, एक ही .java फ़ाइल के भीतर कई कक्षाएं होना संभव है। हालाँकि, केवल एक सार्वजनिक शीर्ष-स्तरीय वर्ग हो सकता है, ...प्रोग्रामिंग 2024-11-18 को प्रकाशित
-
मैं अद्वितीय आईडी को संरक्षित करते हुए और डुप्लिकेट नामों को संभालते हुए PHP में दो सहयोगी सरणियों को कैसे जोड़ूं?PHP में एसोसिएटिव एरेज़ का संयोजनPHP में, दो एसोसिएटिव एरेज़ को एक ही एरे में संयोजित करना एक सामान्य कार्य है। निम्नलिखित अनुरोध पर विचार करें:समस्या...प्रोग्रामिंग 2024-11-18 को प्रकाशित
-
पीडीओ डेटाबेस कनेक्शन का परीक्षण कैसे करें और त्रुटियों को प्रभावी ढंग से कैसे संभालें?PDO डेटाबेस कनेक्शन का परीक्षणडेटाबेस इंस्टॉलेशन विकसित करते समय, डेटाबेस कनेक्शन की वैधता सुनिश्चित करना महत्वपूर्ण है। डिफ़ॉल्ट सेटिंग्स स्थापित करन...प्रोग्रामिंग 2024-11-18 को प्रकाशित
-
क्या MySQL अद्यतन क्वेरीज़ मौजूदा मानों को अधिलेखित कर देती हैं जबकि वे समान हैं?MySQL अपडेट क्वेरीज़: मौजूदा मानों को ओवरराइट करनाMySQL में, एक तालिका को अपडेट करते समय, एक ऐसे परिदृश्य का सामना करना संभव है जहां कॉलम के लिए आपके ...प्रोग्रामिंग 2024-11-18 को प्रकाशित
-
`std::atomic`\ का स्टोर x86 पर अनुक्रमिक स्थिरता के लिए XCHG का उपयोग क्यों करता है?क्यों std::atomic का स्टोर अनुक्रमिक स्थिरता के लिए XCHG को नियोजित करता हैx86 और x86_64 आर्किटेक्चर के लिए std::atomic के संदर्भ में, a अनुक्रमिक स्थ...प्रोग्रामिंग 2024-11-18 को प्रकाशित
-
सरणीतरीके एफएनएस हैं जिन्हें ऑब्जेक्ट पर कॉल किया जा सकता है ऐरे ऑब्जेक्ट हैं, इसलिए जेएस में उनके तरीके भी हैं। स्लाइस (शुरू): मूल सरणी को बदले ब...प्रोग्रामिंग 2024-11-18 को प्रकाशित
-
C++ फ़ंक्शंस से रिटर्निंग ऐरे का सीधे समर्थन क्यों नहीं करता?सी ऐरे-रिटर्निंग फ़ंक्शंस को क्यों अस्वीकार करता हैसी लैंडस्केपजावा जैसी भाषाओं के विपरीत, सी नहीं करता है 'ऐरे लौटाने वाले फ़ंक्शंस के लिए प्रत्य...प्रोग्रामिंग 2024-11-18 को प्रकाशित
-
ठीक है, यहां कुछ शीर्षक दिए गए हैं जो लेख की सामग्री में फिट होंगे: * क्यूटी में \"-एलजीएल: नहीं मिला\" त्रुटि को कैसे ठीक करें * क्यूटी संकलन त्रुटि: \"-एलजीएल: नहीं मिला\" - क्या करें * क्यूटी प्रोजेक्ट्स में समस्या निवारण ''"-एलजीएल: नहीं मिला" का समाधान Qt में त्रुटिQtCreator में एक नव निर्मित प्रोजेक्ट को संकलित करने का प्रयास करते समय, कुछ उपयोगकर्ताओं को साम...प्रोग्रामिंग 2024-11-18 को प्रकाशित
-
क्या PHP का `eval` फ़ंक्शन उपयोग करने के लिए हमेशा सुरक्षित है?कब (यदि कभी) eval बुरा नहीं है?हालांकि PHP के eval फ़ंक्शन को अक्सर हतोत्साहित किया गया है, PHP 5.3 में इसकी उपयोगिता बहस का विषय है . एलएसबी के उद्भव...प्रोग्रामिंग 2024-11-18 को प्रकाशित
-
MacOS पर Django में \"अनुचित कॉन्फ़िगर: MySQLdb मॉड्यूल लोड करने में त्रुटि\" को कैसे ठीक करें?MySQL अनुचित तरीके से कॉन्फ़िगर किया गया: सापेक्ष पथों के साथ समस्याDjango में Python मैनेज.py runserver चलाते समय, आपको निम्न त्रुटि का सामना करना पड...प्रोग्रामिंग 2024-11-18 को प्रकाशित
-
गो में डायनामिक विशेषताओं के साथ एक्सएमएल को अनमर्शल कैसे करें?गोलंग: डायनामिक विशेषताओं के साथ एक्सएमएल को अनमर्शलिंग करनापरिचय:गो में, एन्कोडिंग/एक्सएमएल एक प्रदान करता है XML डेटा को संभालने का कुशल और बहुमुखी ...प्रोग्रामिंग 2024-11-18 को प्रकाशित
-
मैं MySQL का उपयोग करके आज के जन्मदिन वाले उपयोगकर्ताओं को कैसे ढूँढ सकता हूँ?MySQL का उपयोग करके आज के जन्मदिन वाले उपयोगकर्ताओं की पहचान कैसे करेंMySQL का उपयोग करके यह निर्धारित करना कि आज उपयोगकर्ता का जन्मदिन है या नहीं, इस...प्रोग्रामिंग 2024-11-18 को प्रकाशित
-
क्या क्लास डेटा सदस्यों को सीधे C++ में प्रारंभ किया जा सकता है?क्या क्लास डेटा सदस्यों को सीधे इनिशियलाइज़ किया जा सकता है?सी में, क्लास डेटा सदस्यों को डायरेक्ट इनिशियलाइज़ेशन सिंटैक्स का उपयोग करके इनिशियलाइज़ न...प्रोग्रामिंग 2024-11-18 को प्रकाशित
-
`std::cout क्यों करता हैएफ का जिज्ञासु मामला; यह हमेशा आउटपुट में 1 क्यों प्रिंट करता है?एक अजीब व्यवहार का सामना करना जहां किसी फ़ंक्शन को कोष्ठक (f;) के बिना कॉल करना और st...प्रोग्रामिंग 2024-11-18 को प्रकाशित















चीनी भाषा का अध्ययन करें
- 1 आप चीनी भाषा में "चलना" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 2 आप चीनी भाषा में "विमान ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 3 आप चीनी भाषा में "ट्रेन ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 4 आप चीनी भाषा में "बस ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 5 चीनी भाषा में ड्राइव को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 6 तैराकी को चीनी भाषा में क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 7 आप चीनी भाषा में साइकिल चलाने को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 8 आप चीनी भाषा में नमस्ते कैसे कहते हैं? 你好चीनी उच्चारण, 你好चीनी सीखना
- 9 आप चीनी भाषा में धन्यवाद कैसे कहते हैं? 谢谢चीनी उच्चारण, 谢谢चीनी सीखना
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









