 मुखपृष्ठ > प्रोग्रामिंग > परीक्षण के लिए सिंथेटिक डेटा बनाने के लिए फेकर और पांडा पायथन लाइब्रेरी का उपयोग करना
मुखपृष्ठ > प्रोग्रामिंग > परीक्षण के लिए सिंथेटिक डेटा बनाने के लिए फेकर और पांडा पायथन लाइब्रेरी का उपयोग करना
परीक्षण के लिए सिंथेटिक डेटा बनाने के लिए फेकर और पांडा पायथन लाइब्रेरी का उपयोग करना
 ब्राउज़ करें:547
ब्राउज़ करें:547
परिचय:
डेटा-संचालित अनुप्रयोगों के लिए व्यापक परीक्षण आवश्यक है, लेकिन यह अक्सर सही डेटासेट पर निर्भर करता है, जो हमेशा उपलब्ध नहीं हो सकता है। चाहे आप वेब एप्लिकेशन, मशीन लर्निंग मॉडल या बैकएंड सिस्टम विकसित कर रहे हों, उचित सत्यापन और मजबूत प्रदर्शन सुनिश्चित करने के लिए यथार्थवादी और संरचित डेटा महत्वपूर्ण है। गोपनीयता संबंधी चिंताओं, लाइसेंसिंग प्रतिबंधों, या बस प्रासंगिक डेटा की अनुपलब्धता के कारण वास्तविक दुनिया का डेटा प्राप्त करना सीमित हो सकता है। यहीं पर सिंथेटिक डेटा मूल्यवान हो जाता है।
इस ब्लॉग में, हम यह पता लगाएंगे कि विभिन्न परिदृश्यों के लिए सिंथेटिक डेटा उत्पन्न करने के लिए पायथन का उपयोग कैसे किया जा सकता है, जिसमें शामिल हैं:
- अंतरसंबंधित तालिकाएँ: एक-से-अनेक संबंधों का प्रतिनिधित्व करती हैं।
- पदानुक्रमित डेटा: अक्सर संगठनात्मक संरचनाओं में उपयोग किया जाता है।
- जटिल रिश्ते: जैसे कि नामांकन प्रणालियों में अनेक-से-अनेक संबंध।
हम इन उपयोग के मामलों के लिए यथार्थवादी डेटासेट बनाने के लिए फेकर और पांडा लाइब्रेरी का लाभ उठाएंगे।
उदाहरण 1: ग्राहकों और ऑर्डर के लिए सिंथेटिक डेटा बनाना (एक-से-अनेक संबंध)
कई अनुप्रयोगों में, डेटा को विदेशी कुंजी संबंधों के साथ कई तालिकाओं में संग्रहीत किया जाता है। आइए ग्राहकों और उनके ऑर्डर के लिए सिंथेटिक डेटा तैयार करें। एक ग्राहक अनेक ऑर्डर दे सकता है, जो एक-से-अनेक संबंध का प्रतिनिधित्व करता है।
ग्राहक तालिका तैयार करना
ग्राहक तालिका में ग्राहक आईडी, नाम और ईमेल पता जैसी बुनियादी जानकारी होती है।
import pandas as pd
from faker import Faker
import random
fake = Faker()
def generate_customers(num_customers):
customers = []
for _ in range(num_customers):
customer_id = fake.uuid4()
name = fake.name()
email = fake.email()
customers.append({'CustomerID': customer_id, 'CustomerName': name, 'Email': email})
return pd.DataFrame(customers)
customers_df = generate_customers(10)
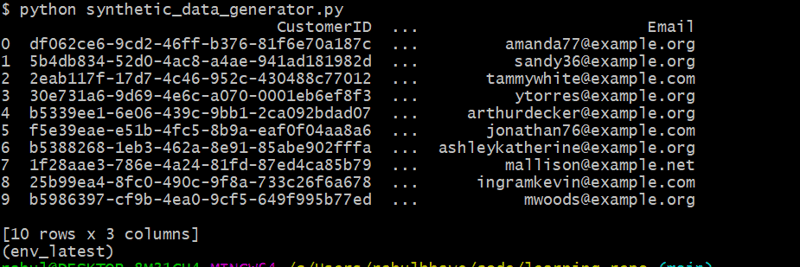
यह कोड यथार्थवादी नाम और ईमेल पते बनाने के लिए फ़ेकर का उपयोग करके 10 यादृच्छिक ग्राहक उत्पन्न करता है।
ऑर्डर तालिका तैयार करना
अब, हम ऑर्डर तालिका तैयार करते हैं, जहां प्रत्येक ऑर्डर ग्राहकआईडी के माध्यम से एक ग्राहक से जुड़ा होता है।
def generate_orders(customers_df, num_orders):
orders = []
for _ in range(num_orders):
order_id = fake.uuid4()
customer_id = random.choice(customers_df['CustomerID'].tolist())
product = fake.random_element(elements=('Laptop', 'Phone', 'Tablet', 'Headphones'))
price = round(random.uniform(100, 2000), 2)
orders.append({'OrderID': order_id, 'CustomerID': customer_id, 'Product': product, 'Price': price})
return pd.DataFrame(orders)
orders_df = generate_orders(customers_df, 30)
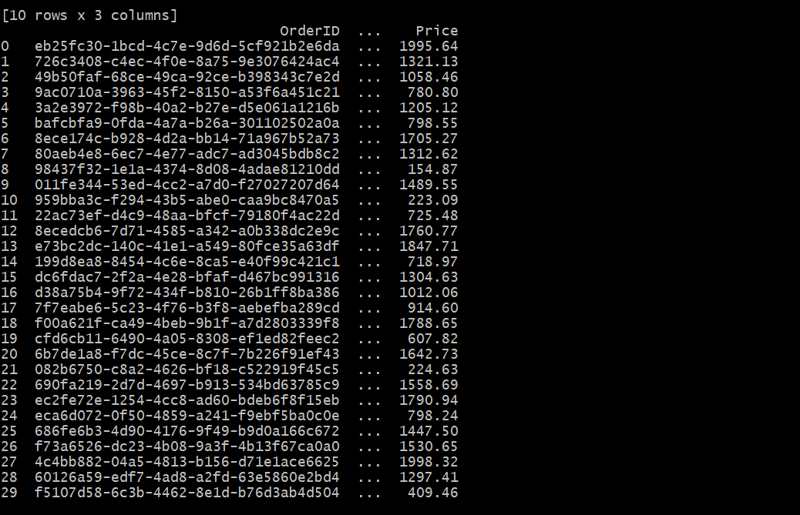
इस मामले में, ऑर्डर तालिका प्रत्येक ऑर्डर को CustomerID का उपयोग करके ग्राहक से लिंक करती है। प्रत्येक ग्राहक एक-से-अनेक संबंध बनाते हुए अनेक ऑर्डर दे सकता है।
उदाहरण 2: विभागों और कर्मचारियों के लिए पदानुक्रमित डेटा उत्पन्न करना
पदानुक्रमित डेटा का उपयोग अक्सर संगठनात्मक सेटिंग्स में किया जाता है, जहां विभागों में कई कर्मचारी होते हैं। आइए विभागों वाले एक संगठन का अनुकरण करें, जिनमें से प्रत्येक में कई कर्मचारी हैं।
विभाग तालिका तैयार करना
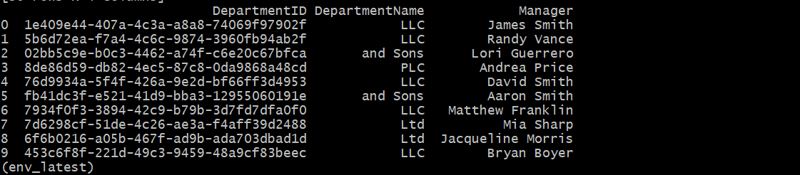
विभाग तालिका में प्रत्येक विभाग की विशिष्ट विभागआईडी, नाम और प्रबंधक शामिल हैं।
def generate_departments(num_departments):
departments = []
for _ in range(num_departments):
department_id = fake.uuid4()
department_name = fake.company_suffix()
manager = fake.name()
departments.append({'DepartmentID': department_id, 'DepartmentName': department_name, 'Manager': manager})
return pd.DataFrame(departments)
departments_df = generate_departments(10)
कर्मचारी तालिका बनाना
इसके बाद, हम कर्मचारी तालिका तैयार करते हैं, जहां प्रत्येक कर्मचारी DepartmentID के माध्यम से एक विभाग से जुड़ा होता है।
def generate_employees(departments_df, num_employees):
employees = []
for _ in range(num_employees):
employee_id = fake.uuid4()
employee_name = fake.name()
email = fake.email()
department_id = random.choice(departments_df['DepartmentID'].tolist())
salary = round(random.uniform(40000, 120000), 2)
employees.append({
'EmployeeID': employee_id,
'EmployeeName': employee_name,
'Email': email,
'DepartmentID': department_id,
'Salary': salary
})
return pd.DataFrame(employees)
employees_df = generate_employees(departments_df, 100)
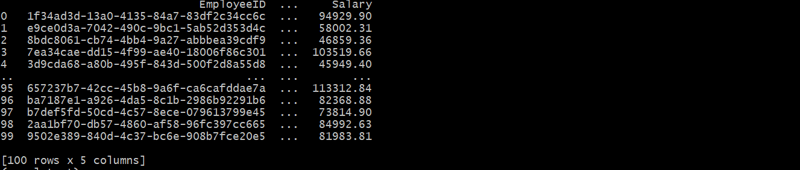
यह पदानुक्रमित संरचना प्रत्येक कर्मचारी को डिपार्टमेंटआईडी के माध्यम से एक विभाग से जोड़ती है, जिससे माता-पिता-बच्चे का संबंध बनता है।
उदाहरण 3: पाठ्यक्रम नामांकन के लिए अनेक-से-अनेक संबंधों का अनुकरण
कुछ परिदृश्यों में, अनेक-से-अनेक संबंध मौजूद होते हैं, जहां एक इकाई कई अन्य से संबंधित होती है। आइए इसे कई पाठ्यक्रमों में दाखिला लेने वाले छात्रों के साथ अनुकरण करें, जहां प्रत्येक पाठ्यक्रम में कई छात्र हैं।
पाठ्यक्रम तालिका तैयार करना
def generate_courses(num_courses):
courses = []
for _ in range(num_courses):
course_id = fake.uuid4()
course_name = fake.bs().title()
instructor = fake.name()
courses.append({'CourseID': course_id, 'CourseName': course_name, 'Instructor': instructor})
return pd.DataFrame(courses)
courses_df = generate_courses(20)
छात्र तालिका तैयार करना
def generate_students(num_students):
students = []
for _ in range(num_students):
student_id = fake.uuid4()
student_name = fake.name()
email = fake.email()
students.append({'StudentID': student_id, 'StudentName': student_name, 'Email': email})
return pd.DataFrame(students)
students_df = generate_students(50)
print(students_df)
पाठ्यक्रम नामांकन तालिका तैयार करना
पाठ्यक्रम नामांकन तालिका छात्रों और पाठ्यक्रमों के बीच अनेक-से-अनेक संबंधों को दर्शाती है।
def generate_course_enrollments(students_df, courses_df, num_enrollments):
enrollments = []
for _ in range(num_enrollments):
enrollment_id = fake.uuid4()
student_id = random.choice(students_df['StudentID'].tolist())
course_id = random.choice(courses_df['CourseID'].tolist())
enrollment_date = fake.date_this_year()
enrollments.append({
'EnrollmentID': enrollment_id,
'StudentID': student_id,
'CourseID': course_id,
'EnrollmentDate': enrollment_date
})
return pd.DataFrame(enrollments)
enrollments_df = generate_course_enrollments(students_df, courses_df, 200)
इस उदाहरण में, हम छात्रों और पाठ्यक्रमों के बीच अनेक-से-अनेक संबंधों को दर्शाने के लिए एक लिंकिंग तालिका बनाते हैं।
निष्कर्ष:
पायथन और फ़ेकर और पांडा जैसे पुस्तकालयों का उपयोग करके, आप विभिन्न परीक्षण आवश्यकताओं को पूरा करने के लिए यथार्थवादी और विविध सिंथेटिक डेटासेट उत्पन्न कर सकते हैं। इस ब्लॉग में, हमने कवर किया:
- अंतरसंबंधित तालिकाएँ: ग्राहकों और ऑर्डर के बीच एक-से-अनेक संबंध प्रदर्शित करना।
- पदानुक्रमित डेटा: विभागों और कर्मचारियों के बीच माता-पिता के रिश्ते को दर्शाता है।
- जटिल रिश्ते: छात्रों और पाठ्यक्रमों के बीच अनेक-से-अनेक संबंधों का अनुकरण।
ये उदाहरण आपकी आवश्यकताओं के अनुरूप सिंथेटिक डेटा तैयार करने की नींव रखते हैं। आगे के संवर्द्धन, जैसे कि अधिक जटिल संबंध बनाना, विशिष्ट डेटाबेस के लिए डेटा को अनुकूलित करना, या प्रदर्शन परीक्षण के लिए डेटासेट को स्केल करना, सिंथेटिक डेटा पीढ़ी को अगले स्तर पर ले जा सकता है।
ये उदाहरण सिंथेटिक डेटा उत्पन्न करने के लिए एक ठोस आधार प्रदान करते हैं। हालाँकि, जटिलता और विशिष्टता को बढ़ाने के लिए और सुधार किए जा सकते हैं, जैसे:
- डेटाबेस-विशिष्ट डेटा: विभिन्न डेटाबेस सिस्टम (उदाहरण के लिए, SQL बनाम NoSQL) के लिए डेटा पीढ़ी को अनुकूलित करना।
- अधिक जटिल रिश्ते: अतिरिक्त अंतरनिर्भरताएं बनाना, जैसे अस्थायी रिश्ते, बहु-स्तरीय पदानुक्रम, या अद्वितीय बाधाएं।
- स्केलिंग डेटा: प्रदर्शन परीक्षण या तनाव परीक्षण के लिए बड़े डेटासेट तैयार करना, यह सुनिश्चित करना कि सिस्टम वास्तविक दुनिया की स्थितियों को बड़े पैमाने पर संभाल सकता है। अपनी आवश्यकताओं के अनुरूप सिंथेटिक डेटा उत्पन्न करके, आप संवेदनशील या कठिन-से-प्राप्त डेटासेट पर भरोसा किए बिना अनुप्रयोगों के विकास, परीक्षण और अनुकूलन के लिए यथार्थवादी स्थितियों का अनुकरण कर सकते हैं।
अगर आपको लेख पसंद आया, तो कृपया इसे अपने दोस्तों और सहकर्मियों के साथ साझा करें। किसी भी अन्य विचार पर चर्चा करने के लिए आप मुझसे लिंक्डइन पर जुड़ सकते हैं।
-
 कैसे एक जावास्क्रिप्ट ऑब्जेक्ट की कुंजी को वर्णानुक्रम में सॉर्ट करने के लिए?] यह निम्नलिखित चरणों का उपयोग करके प्राप्त किया जा सकता है: object की कुंजियों को एक सरणी में const unordered = { 'b': 'foo', 'c': 'bar', ...प्रोग्रामिंग 2025-04-27 को पोस्ट किया गया
कैसे एक जावास्क्रिप्ट ऑब्जेक्ट की कुंजी को वर्णानुक्रम में सॉर्ट करने के लिए?] यह निम्नलिखित चरणों का उपयोग करके प्राप्त किया जा सकता है: object की कुंजियों को एक सरणी में const unordered = { 'b': 'foo', 'c': 'bar', ...प्रोग्रामिंग 2025-04-27 को पोस्ट किया गया -
पायथन में नेस्टेड कार्यों और बंद होने के बीच क्या अंतर है] गैर-क्लोज़र्स पायथन में नेस्टेड फ़ंक्शंस को क्लोजर नहीं माना जाता है क्योंकि वे निम्नलिखित आवश्यकता को पूरा नहीं करते हैं: वे उन चर को एक्सेस...प्रोग्रामिंग 2025-04-27 को पोस्ट किया गया
-
दशमलव का उपयोग करके घातीय संकेतन में संख्या को कैसे पार्स करें।] ऐसा इसलिए है क्योंकि डिफ़ॉल्ट पार्सिंग विधि घातीय संकेतन को पहचान नहींती है। इस तरह के स्ट्रिंग को सफलतापूर्वक पार्स करने के लिए, आपको स्पष्ट रूप ...प्रोग्रामिंग 2025-04-27 को पोस्ट किया गया
-
अजगर में गतिशील चर कैसे बनाएं?] पायथन इसे प्राप्त करने के लिए कई रचनात्मक तरीके प्रदान करता है। शब्दकोश आपको गतिशील रूप से कुंजियाँ बनाने और संबंधित मानों को असाइन करने की अनुमति द...प्रोग्रामिंग 2025-04-27 को पोस्ट किया गया
-
\ "जबकि (1) बनाम के लिए (;;): क्या संकलक अनुकूलन प्रदर्शन अंतर को समाप्त करता है?] लूप? संकलक: perl: दोनों जबकि (1) और (;; 1 दर्ज करें -> 2 2 नेक्स्टस्टेट (मुख्य 2 -e: 1) v -> 3 9 लेवेलूप वीके/2 -> ए 3 9 4 नेक्स्टस्टेट ...प्रोग्रामिंग 2025-04-27 को पोस्ट किया गया
-
कैसे अतुल्यकालिक संचालन को समवर्ती रूप से चलाएं और जावास्क्रिप्ट में सही ढंग से त्रुटियों को संभालें?getValue2Async (); समवर्ती निष्पादन को सक्षम करने के लिए, एक संशोधित दृष्टिकोण की आवश्यकता होती है। getValue2Async (); यह दूसरे को शुरू करने से प...प्रोग्रामिंग 2025-04-27 को पोस्ट किया गया
-
PHP SIMPLEXML पार्सिंग XML विधि नेमस्पेस कोलन के साथ] यह समस्या उत्पन्न होती है क्योंकि SIMPLEXML XML संरचनाओं को संभालने में असमर्थ है जो डिफ़ॉल्ट नामशास्त्र से विचलित हो जाती है। उदाहरण के लिए: $ xm...प्रोग्रामिंग 2025-04-27 को पोस्ट किया गया
-
फायरबेस ऐप में अपनी संबंधित गतिविधियों के लिए कई उपयोगकर्ता प्रकारों (छात्रों, शिक्षकों और प्रशंसा) को कैसे पुनर्निर्देशित करें?] लॉग इन करें। वर्तमान कोड सफलतापूर्वक दो उपयोगकर्ता प्रकारों के लिए पुनर्निर्देशन का प्रबंधन करता है, लेकिन तीसरे प्रकार (व्यवस्थापक) को शामिल करने क...प्रोग्रामिंग 2025-04-27 को पोस्ट किया गया
-
जब MySQL इमोजी सम्मिलित करता है तो \\ "स्ट्रिंग मान त्रुटि \\" अपवाद को हल करें] '\ xf0 \ x9f \ x91 \ xbd \ xf0 \ x9f ...' यह त्रुटि उत्पन्न होती है क्योंकि MySQL का डिफ़ॉल्ट UTF8 वर्ण सेट केवल मूल बहुभाषी विमान के भीतर...प्रोग्रामिंग 2025-04-27 को पोस्ट किया गया
-
क्या मैं McRypt से OpenSSL में अपने एन्क्रिप्शन को माइग्रेट कर सकता हूं, और OpenSSL का उपयोग करके McRypt-encrypted डेटा को डिक्रिप्ट कर सकता हूं?] OpenSSL में, क्या McRypt के साथ एन्क्रिप्ट किए गए डेटा को डिक्रिप्ट करना संभव है? दो अलग -अलग पोस्ट परस्पर विरोधी जानकारी प्रदान करते हैं। यदि ऐसा ह...प्रोग्रामिंग 2025-04-27 को पोस्ट किया गया
-
RPC विधि अन्वेषण के लिए GO इंटरफ़ेस का चिंतनशील गतिशील कार्यान्वयन] एक प्रश्न जो उठाया गया है, क्या यह एक नया फ़ंक्शन बनाने के लिए प्रतिबिंब का उपयोग करना संभव है जो एक विशिष्ट इंटरफ़ेस को लागू करता है। उदाहरण के लिए...प्रोग्रामिंग 2025-04-27 को पोस्ट किया गया
-
`कंसोल.लॉग` संशोधित ऑब्जेक्ट मान अपवाद का कारण दिखाता हैइस कोड स्निपेट का विश्लेषण करके इस रहस्य को उजागर करें: foo = [{id: 1}, {id: 2}, {id: 3}, {id: 4}, {id: 5},]; कंसोल.लॉग ('foo1', foo, ...प्रोग्रामिंग 2025-04-27 को पोस्ट किया गया
-
कारण क्यों पायथन हाइपरस्कोप सबस्ट्रिंग के स्लाइसिंग को त्रुटियों की रिपोर्ट नहीं करता है] 'उदाहरण' [9] का उपयोग करके व्यक्तिगत तत्वों को अनुक्रमित करने के विपरीत, जो एक त्रुटि उठाता है, एक अनुक्रम की सीमा के बाहर स्लाइस करना नहीं ...प्रोग्रामिंग 2025-04-27 को पोस्ट किया गया
-
बहु-आयामी सरणियों के लिए PHP में JSON पार्सिंग को सरल कैसे करें?] To simplify the process, it's recommended to parse the JSON as an array rather than an object.To do this, use the json_decode function with the ...प्रोग्रामिंग 2025-04-27 को पोस्ट किया गया
-
एक पांडस डेटाफ्रेम कॉलम को डेटटाइम प्रारूप में कैसे परिवर्तित करें और तिथि तक फ़िल्टर करें?] अस्थायी डेटा के साथ काम करते समय, टाइमस्टैम्प शुरू में तार के रूप में दिखाई दे सकते हैं, लेकिन सटीक विश्लेषण के लिए एक डेटाइम प्रारूप में परिवर्तित ...प्रोग्रामिंग 2025-04-27 को पोस्ट किया गया















चीनी भाषा का अध्ययन करें
- 1 आप चीनी भाषा में "चलना" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 2 आप चीनी भाषा में "विमान ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 3 आप चीनी भाषा में "ट्रेन ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 4 आप चीनी भाषा में "बस ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 5 चीनी भाषा में ड्राइव को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 6 तैराकी को चीनी भाषा में क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 7 आप चीनी भाषा में साइकिल चलाने को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 8 आप चीनी भाषा में नमस्ते कैसे कहते हैं? 你好चीनी उच्चारण, 你好चीनी सीखना
- 9 आप चीनी भाषा में धन्यवाद कैसे कहते हैं? 谢谢चीनी उच्चारण, 谢谢चीनी सीखना
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









