
पायथन की तर्ज पर गूगल जेमिनी के साथ ट्रिकी पीडीएफ से डेटा निकालना
 ब्राउज़ करें:893
ब्राउज़ करें:893
इस गाइड में, मैं आपको दिखाऊंगा कि जेमिनी फ्लैश या जीपीटी-4ओ जैसे विज़न-लैंग्वेज मॉडल (वीएलएम) का उपयोग करके पीडीएफ से संरचित डेटा कैसे निकाला जाता है।
गूगल की दृष्टि-भाषा मॉडल की नवीनतम श्रृंखला जेमिनी ने पाठ और छवि समझ में अत्याधुनिक प्रदर्शन दिखाया है। यह बेहतर मल्टीमॉडल क्षमता और लंबी संदर्भ विंडो इसे दृश्य रूप से जटिल पीडीएफ डेटा को संसाधित करने के लिए विशेष रूप से उपयोगी बनाती है, जिसके साथ पारंपरिक निष्कर्षण मॉडल संघर्ष करते हैं, जैसे कि आंकड़े, चार्ट, टेबल और आरेख।
ऐसा करके, आप विज़ुअल फ़ाइल और वेब निष्कर्षण के लिए आसानी से अपना स्वयं का डेटा निष्कर्षण उपकरण बना सकते हैं। ऐसे:
मिथुन की लंबी संदर्भ विंडो और मल्टीमॉडल क्षमता इसे दृश्य रूप से जटिल पीडीएफ डेटा को संसाधित करने के लिए विशेष रूप से उपयोगी बनाती है जहां पारंपरिक निष्कर्षण मॉडल संघर्ष करते हैं।
अपना वातावरण स्थापित करना
निष्कर्षण में उतरने से पहले, आइए अपना विकास परिवेश स्थापित करें। यह मार्गदर्शिका मानती है कि आपके सिस्टम पर Python स्थापित है। यदि नहीं, तो इसे https://www.python.org/downloads/
से डाउनलोड और इंस्टॉल करें⚠️ ध्यान दें, यदि आप पायथन का उपयोग नहीं करना चाहते हैं, तो आप अपनी फ़ाइलें अपलोड करने और बिना कोई कोड लिखे सीएसवी के रूप में अपना परिणाम डाउनलोड करने के लिए thepi.pe पर क्लाउड प्लेटफ़ॉर्म का उपयोग कर सकते हैं।
आवश्यक पुस्तकालय स्थापित करें
अपना टर्मिनल या कमांड प्रॉम्प्ट खोलें और निम्नलिखित कमांड चलाएँ:
pip install git https://github.com/emcf/thepipe pip install pandas
पाइथॉन में नए लोगों के लिए, पाइप पायथन के लिए पैकेज इंस्टॉलर है, और ये कमांड आवश्यक लाइब्रेरी डाउनलोड और इंस्टॉल करेंगे।
अपनी एपीआई कुंजी सेट करें
पाइप का उपयोग करने के लिए, आपको एक एपीआई कुंजी की आवश्यकता है।
अस्वीकरण: जबकि thepi.pe एक मुफ़्त ओपन सोर्स टूल है, एपीआई की लागत लगभग $0.00002 प्रति टोकन है। यदि आप ऐसी लागतों से बचना चाहते हैं, तो GitHub पर स्थानीय सेटअप निर्देश देखें। ध्यान दें कि आपको अभी भी अपनी पसंद के एलएलएम प्रदाता को भुगतान करना होगा।
इसे कैसे प्राप्त करें और सेट अप करें, यहां बताया गया है:
- https://thepi.pe/platform/ पर जाएं
- एक खाता बनाएं या लॉग - इन करें
- सेटिंग्स पेज में अपनी एपीआई कुंजी ढूंढें

अब, आपको इसे एक पर्यावरण चर के रूप में सेट करने की आवश्यकता है। प्रक्रिया आपके ऑपरेटिंग सिस्टम के आधार पर भिन्न होती है:
- thepi.pe प्लेटफॉर्म पर सेटिंग मेनू से एपीआई कुंजी की प्रतिलिपि बनाएं
विंडोज के लिए:
- प्रारंभ मेनू में "पर्यावरण चर" खोजें
- "सिस्टम वातावरण चर संपादित करें" पर क्लिक करें
- "पर्यावरण चर" बटन पर क्लिक करें
- "उपयोगकर्ता चर" के अंतर्गत, "नया" पर क्लिक करें
- वैरिएबल नाम को THEPIPE_API_KEY और मान को अपनी API कुंजी के रूप में सेट करें
- सहेजने के लिए "ओके" पर क्लिक करें
MacOS और Linux के लिए:
अपना टर्मिनल खोलें और इस लाइन को अपनी शेल कॉन्फ़िगरेशन फ़ाइल में जोड़ें (उदाहरण के लिए, ~/.bashrc या ~/.zshrc):
export THEPIPE_API_KEY=your_api_key_here
फिर, अपना कॉन्फ़िगरेशन पुनः लोड करें:
source ~/.bashrc # or ~/.zshrc
आपकी निष्कर्षण स्कीमा को परिभाषित करना
सफल निष्कर्षण की कुंजी उस डेटा के लिए एक स्पष्ट स्कीमा को परिभाषित करना है जिसे आप निकालना चाहते हैं। मान लीजिए कि हम मात्रा दस्तावेज़ से डेटा निकाल रहे हैं:

मात्रा के बिल दस्तावेज़ के एक पृष्ठ का एक उदाहरण। प्रत्येक पृष्ठ का डेटा अन्य पृष्ठों से स्वतंत्र है, इसलिए हम अपना निष्कर्षण "प्रति पृष्ठ" करते हैं। प्रति पृष्ठ निकालने के लिए डेटा के कई टुकड़े होते हैं, इसलिए हम एकाधिक निष्कर्षण को सही पर सेट करते हैं
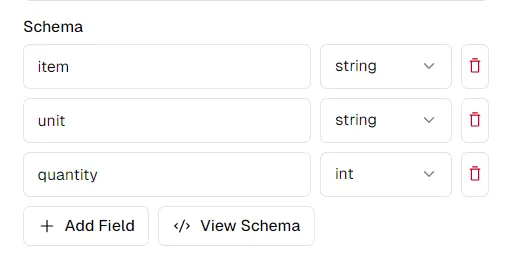
कॉलम नामों को देखते हुए, हम शायद इस तरह एक स्कीमा निकालना चाहेंगे:
schema = {
"item": "string",
"unit": "string",
"quantity": "int",
}
आप thepi.pe प्लेटफ़ॉर्म पर स्कीमा को अपनी पसंद के अनुसार संशोधित कर सकते हैं। "स्कीमा देखें" पर क्लिक करने से आपको एक स्कीमा मिलेगा जिसे आप पायथन एपीआई के साथ उपयोग के लिए कॉपी और पेस्ट कर सकते हैं
पीडीएफ़ से डेटा निकालना
अब, पीडीएफ से डेटा खींचने के लिए extract_from_file का उपयोग करें:
from thepipe.extract import extract_from_file results = extract_from_file( file_path = "bill_of_quantity.pdf", schema = schema, ai_model = "google/gemini-flash-1.5b", chunking_method = "chunk_by_page" )
यहां, हमारे पास chunking_method = "chunk_by_page" है क्योंकि हम प्रत्येक पृष्ठ को एआई मॉडल पर व्यक्तिगत रूप से भेजना चाहते हैं (पीडीएफ सभी को एक साथ फीड करने के लिए बहुत बड़ा है)। हमने multiple_extractions=True भी सेट किया है क्योंकि प्रत्येक पीडीएफ पेज में डेटा की कई पंक्तियाँ होती हैं। पीडीएफ का एक पृष्ठ इस प्रकार दिखता है:
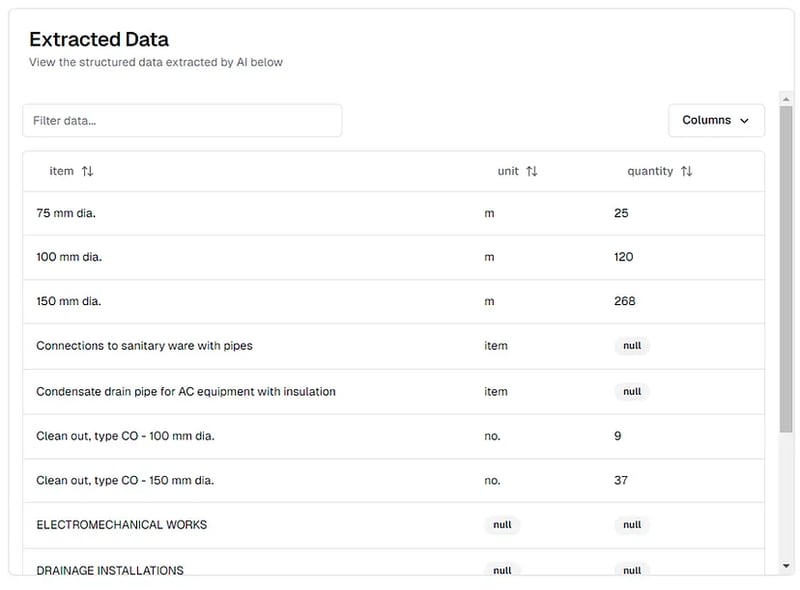
मात्रा के बिल पीडीएफ के लिए निष्कर्षण के परिणाम जैसा कि thepi.pe प्लेटफॉर्म पर देखा गया है
परिणामों का प्रसंस्करण
निष्कर्षण परिणाम शब्दकोशों की सूची के रूप में लौटाए जाते हैं। हम पांडा डेटाफ़्रेम बनाने के लिए इन परिणामों को संसाधित कर सकते हैं:
import pandas as pd df = pd.DataFrame(results) # Display the first few rows of the DataFrame print(df.head())
यह सभी निकाली गई जानकारी के साथ एक डेटाफ़्रेम बनाता है, जिसमें पाठ्य सामग्री और आंकड़े और तालिकाओं जैसे दृश्य तत्वों का विवरण शामिल है।
विभिन्न प्रारूपों में निर्यात करना
अब जब हमारा डेटा डेटाफ़्रेम में है, तो हम इसे आसानी से विभिन्न प्रारूपों में निर्यात कर सकते हैं। यहां कुछ विकल्प दिए गए हैं:
एक्सेल में निर्यात किया जा रहा है
df.to_excel("extracted_research_data.xlsx", index=False, sheet_name="Research Data")
यह "Research Data" नामक शीट के साथ "extracted_research_data.xlsx" नामक एक एक्सेल फ़ाइल बनाता है। इंडेक्स=गलत पैरामीटर डेटाफ़्रेम इंडेक्स को एक अलग कॉलम के रूप में शामिल होने से रोकता है।
सीएसवी को निर्यात किया जा रहा है
यदि आप सरल प्रारूप पसंद करते हैं, तो आप CSV पर निर्यात कर सकते हैं:
df.to_csv("extracted_research_data.csv", index=False)
यह एक CSV फ़ाइल बनाता है जिसे एक्सेल या किसी टेक्स्ट एडिटर में खोला जा सकता है।
समापन नोट्स
सफल निष्कर्षण की कुंजी एक स्पष्ट स्कीमा को परिभाषित करने और एआई मॉडल की मल्टीमॉडल क्षमताओं का उपयोग करने में निहित है। जैसे-जैसे आप इन तकनीकों के साथ अधिक सहज हो जाते हैं, आप कस्टम चंकिंग विधियों, कस्टम निष्कर्षण संकेतों और निष्कर्षण प्रक्रिया को बड़ी डेटा पाइपलाइनों में एकीकृत करने जैसी अधिक उन्नत सुविधाओं का पता लगा सकते हैं।
-
 उपयोगकर्ता स्थानीय समय प्रारूप और समय क्षेत्र ऑफसेट प्रदर्शन गाइड] यह विभिन्न भौगोलिक स्थानों पर स्पष्टता और सहज उपयोगकर्ता अनुभव सुनिश्चित करता है। यहाँ जावास्क्रिप्ट का उपयोग करके इसे कैसे प्राप्त किया जाए। यह सर्...प्रोग्रामिंग 2025-07-05 पर पोस्ट किया गया
उपयोगकर्ता स्थानीय समय प्रारूप और समय क्षेत्र ऑफसेट प्रदर्शन गाइड] यह विभिन्न भौगोलिक स्थानों पर स्पष्टता और सहज उपयोगकर्ता अनुभव सुनिश्चित करता है। यहाँ जावास्क्रिप्ट का उपयोग करके इसे कैसे प्राप्त किया जाए। यह सर्...प्रोग्रामिंग 2025-07-05 पर पोस्ट किया गया -
C#में इंडेंटेशन के लिए स्ट्रिंग वर्णों को कुशलता से कैसे दोहराएं?] कंस्ट्रक्टर यदि आप केवल एक ही वर्ण को दोहराने का इरादा रखते हैं, स्ट्रिंग ('-', 5); यह स्ट्रिंग को वापस कर देगा "-----"। स्ट्...प्रोग्रामिंग 2025-07-05 पर पोस्ट किया गया
-
मैं गो कंपाइलर में संकलन अनुकूलन को कैसे अनुकूलित कर सकता हूं?] हालाँकि, उपयोगकर्ताओं को विशिष्ट आवश्यकताओं के लिए इन अनुकूलन को समायोजित करने की आवश्यकता हो सकती है। इसका मतलब यह है कि कंपाइलर स्वचालित रूप से पू...प्रोग्रामिंग 2025-07-05 पर पोस्ट किया गया
-
क्या शुद्ध सीएसएस में एक दूसरे के ऊपर कई चिपचिपे तत्वों को स्टैक किया जा सकता है?यहाँ: https://webthemez.com/demo/sticky-multi-hroll/index.html केवल मैं एक जावास्क्रिप्ट कार्यान्वयन के बजाय शुद्ध CSS का उपयोग करना पसंद करू...प्रोग्रामिंग 2025-07-05 पर पोस्ट किया गया
-
त्रुटि को कैसे हल करें "फ़ाइल प्रकार का अनुमान नहीं लगा सकते, एप्लिकेशन/ऑक्टेट-स्ट्रीम ..." Appengine में?] एप्लिकेशन/ऑक्टेट-स्ट्रीम ... " समस्या रिज़ॉल्यूशन /etc/mime.types फ़ाइल। AppEngine, हालांकि, इस परिभाषा तक पहुंच नहीं हो सकती है। उदाहरण...प्रोग्रामिंग 2025-07-05 पर पोस्ट किया गया
-
PHP भविष्य: अनुकूलन और नवाचार] 2) प्रदर्शन और डेटा प्रोसेसिंग दक्षता में सुधार करने के लिए JIT संकलक और गणना प्रकारों का परिचय; 3) लगातार प्रदर्शन का अनुकूलन करें और सर्वोत्तम प्र...प्रोग्रामिंग 2025-07-05 पर पोस्ट किया गया
-
UTF8 MySQL तालिका में UTF8 में Latin1 वर्णों को सही ढंग से परिवर्तित करने की विधि] "mysql_set_charset ('utf8')" कॉल करें। हालाँकि, ये विधियां पहले "अवैध" चरित्र से परे पात्रों को पकड़ने में विफल हो रही ह...प्रोग्रामिंग 2025-07-05 पर पोस्ट किया गया
-
क्या CSS किसी भी विशेषता मान के आधार पर HTML तत्वों का पता लगा सकता है?CSS में किसी भी विशेषता मान के साथ HTML तत्वों को लक्षित करना input[type=text] { font-family: Consolas; } हालांकि, एक सामान्य सवाल उठता ...प्रोग्रामिंग 2025-07-05 पर पोस्ट किया गया
-
पायथन के अनुरोधों और नकली उपयोगकर्ता एजेंटों के साथ वेबसाइट ब्लॉक को कैसे बायपास करें?] ऐसा इसलिए है क्योंकि वेबसाइटें एंटी-बॉट उपायों को लागू कर सकती हैं जो वास्तविक ब्राउज़रों और स्वचालित स्क्रिप्ट के बीच अंतर करते हैं। इन ब्लॉकों को ...प्रोग्रामिंग 2025-07-05 पर पोस्ट किया गया
-
Google API से नवीनतम JQuery लाइब्रेरी कैसे पुनः प्राप्त करें?] नवीनतम संस्करण को पुनर्प्राप्त करने के लिए, पहले एक विशिष्ट संस्करण संख्या का उपयोग करने का एक विकल्प था, जो निम्न सिंटैक्स का उपयोग करना था: htt...प्रोग्रामिंग 2025-07-05 पर पोस्ट किया गया
-
PHP में खाली सरणियों का कुशलता से कैसे पता लगाएं?] यदि आवश्यकता किसी भी सरणी तत्व की उपस्थिति को सत्यापित करने की है, तो PHP की ढीली टाइपिंग सरणी के प्रत्यक्ष मूल्यांकन के लिए ही अनुमति देती है: अग...प्रोग्रामिंग 2025-07-05 पर पोस्ट किया गया
-
मैं PHP में दो समान-आकार के सरणियों से पुनरावृति और प्रिंट मान कैसे कर सकता हूं?] arrays: foreach ($ कोड के रूप में $ कोड और $ नाम के रूप में $ नाम) { ... } यह दृष्टिकोण अमान्य है। इसके बजाय, = का उपयोग पुनरावृत्ति को सिंक...प्रोग्रामिंग 2025-07-05 पर पोस्ट किया गया
-
सरणी] एरेज़ ऑब्जेक्ट हैं, इसलिए उनके पास जेएस में भी तरीके हैं। स्लाइस (शुरुआत): मूल सरणी को म्यूट किए बिना, एक नए सरणी में सरणी का हिस्सा निकाले...प्रोग्रामिंग 2025-07-05 पर पोस्ट किया गया
-
Ubuntu 12.04 MySQL स्थानीय कनेक्शन त्रुटि फिक्स गाइड] निराशाजनक अनुभव। यह समस्या तब उत्पन्न होती है जब MySQL सर्वर को निर्दिष्ट सॉकेट के माध्यम से ठीक से कॉन्फ़िगर या सुलभ नहीं किया जाता है। यदि यह स्था...प्रोग्रामिंग 2025-07-05 पर पोस्ट किया गया
-
JQuery का उपयोग करते हुए "छद्म-तत्व" के बाद ": के बाद" के CSS विशेषता को प्रभावी ढंग से कैसे संशोधित करें?] हालाँकि, JQuery का उपयोग करके इन तत्वों तक पहुंचना और हेरफेर करना चुनौतियां पेश कर सकता है। ऐसा इसलिए है क्योंकि छद्म-तत्व DOM (दस्तावेज़ ऑब्जेक्ट म...प्रोग्रामिंग 2025-07-05 पर पोस्ट किया गया















चीनी भाषा का अध्ययन करें
- 1 आप चीनी भाषा में "चलना" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 2 आप चीनी भाषा में "विमान ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 3 आप चीनी भाषा में "ट्रेन ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 4 आप चीनी भाषा में "बस ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 5 चीनी भाषा में ड्राइव को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 6 तैराकी को चीनी भाषा में क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 7 आप चीनी भाषा में साइकिल चलाने को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 8 आप चीनी भाषा में नमस्ते कैसे कहते हैं? 你好चीनी उच्चारण, 你好चीनी सीखना
- 9 आप चीनी भाषा में धन्यवाद कैसे कहते हैं? 谢谢चीनी उच्चारण, 谢谢चीनी सीखना
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









