
मशीन लर्निंग वर्गीकरण मॉडल का मूल्यांकन
 ब्राउज़ करें:221
ब्राउज़ करें:221
रूपरेखा
- मॉडल मूल्यांकन का लक्ष्य क्या है?
- मॉडल मूल्यांकन का उद्देश्य क्या है, और कुछ क्या हैं सामान्य मूल्यांकन प्रक्रियाएँ?
- वर्गीकरण सटीकता का उपयोग क्या है, और इसकी विशेषताएं क्या हैं सीमाएँ?
- भ्रम मैट्रिक्स किसी के प्रदर्शन का वर्णन कैसे करता है वर्गीकरणकर्ता?
- कन्फ्यूजन मैट्रिक्स से किन मैट्रिक्स की गणना की जा सकती है?
Tमॉडल मूल्यांकन का लक्ष्य प्रश्न का उत्तर देना है;
मैं विभिन्न मॉडलों के बीच चयन कैसे करूं?
मशीन लर्निंग के मूल्यांकन की प्रक्रिया यह निर्धारित करने में मदद करती है कि मॉडल अपने अनुप्रयोग के लिए कितना विश्वसनीय और प्रभावी है। इसमें विभिन्न कारकों का आकलन करना शामिल है जैसे कि इसके प्रदर्शन, मैट्रिक्स और भविष्यवाणियों या निर्णय लेने की सटीकता।
इससे कोई फर्क नहीं पड़ता कि आप किस मॉडल का उपयोग करना चुनते हैं, आपको मॉडलों के बीच चयन करने का एक तरीका चाहिए: विभिन्न मॉडल प्रकार, ट्यूनिंग पैरामीटर और सुविधाएं। इसके अलावा आपको यह अनुमान लगाने के लिए एक मॉडल मूल्यांकन प्रक्रिया की आवश्यकता है कि कोई मॉडल अनदेखे डेटा को कितनी अच्छी तरह सामान्यीकृत करेगा। अंततः आपको अपने मॉडल के प्रदर्शन को मापने के लिए अपनी प्रक्रिया के साथ जुड़ने के लिए एक मूल्यांकन प्रक्रिया की आवश्यकता है।
आगे बढ़ने से पहले, आइए कुछ अलग-अलग मॉडल मूल्यांकन प्रक्रियाओं की समीक्षा करें और वे कैसे काम करते हैं।
मॉडल मूल्यांकन प्रक्रियाएं और वे कैसे संचालित होती हैं।
-
एक ही डेटा पर प्रशिक्षण और परीक्षण
- अत्यधिक जटिल मॉडलों को पुरस्कृत करता है जो प्रशिक्षण डेटा को "ओवरफिट" करते हैं और आवश्यक रूप से सामान्यीकरण नहीं करेंगे
-
ट्रेन/परीक्षण विभाजन
- डेटासेट को दो टुकड़ों में विभाजित करें, ताकि मॉडल को विभिन्न डेटा पर प्रशिक्षित और परीक्षण किया जा सके
- आउट-ऑफ़-सैंपल प्रदर्शन का बेहतर अनुमान, लेकिन फिर भी एक "उच्च भिन्नता" अनुमान
- अपनी गति, सरलता और लचीलेपन के कारण उपयोगी
-
के-फ़ोल्ड क्रॉस-सत्यापन
- व्यवस्थित रूप से "K" ट्रेन/परीक्षण विभाजन बनाएं और परिणामों को एक साथ औसत करें
- आउट-ऑफ़-सैंपल प्रदर्शन का और भी बेहतर अनुमान
- ट्रेन/टेस्ट स्प्लिट की तुलना में "K" गुना धीमी गति से चलती है।
ऊपर से, हम यह निष्कर्ष निकाल सकते हैं:
एक ही डेटा पर प्रशिक्षण और परीक्षण ओवरफिटिंग का एक क्लासिक कारण है जिसमें आप एक अत्यधिक जटिल मॉडल बनाते हैं जो नए डेटा को सामान्यीकृत नहीं करेगा और जो वास्तव में उपयोगी नहीं है।
Train_Test_Split आउट-ऑफ़-सैंपल प्रदर्शन का बेहतर अनुमान प्रदान करता है।
के-फोल्ड क्रॉस-वैलिडेशन व्यवस्थित रूप से के ट्रेन परीक्षण विभाजन और परिणामों को एक साथ औसत करके बेहतर होता है।
संक्षेप में, ट्रेन_टेस्ट्स_स्प्लिट अपनी गति और सरलता के कारण सत्यापन को पार करने में अभी भी लाभदायक है, और यही हम इस ट्यूटोरियल गाइड में उपयोग करेंगे।
मॉडल मूल्यांकन मेट्रिक्स:
आपको अपनी चुनी हुई प्रक्रिया के साथ चलने के लिए हमेशा एक मूल्यांकन मीट्रिक की आवश्यकता होगी, और मीट्रिक की आपकी पसंद उस समस्या पर निर्भर करती है जिसे आप संबोधित कर रहे हैं। वर्गीकरण समस्याओं के लिए, आप वर्गीकरण सटीकता का उपयोग कर सकते हैं। लेकिन हम इस गाइड में अन्य महत्वपूर्ण वर्गीकरण मूल्यांकन मेट्रिक्स पर ध्यान केंद्रित करेंगे।
किसी भी नए मूल्यांकन मेट्रिक्स को सीखने से पहले आइए वर्गीकरण सटीकता की समीक्षा करें, और इसकी ताकत और कमजोरियों के बारे में बात करें।
वर्गीकरण सटीकता
हमने इस ट्यूटोरियल के लिए पिमा इंडियंस डायबिटीज डेटासेट को चुना है, जिसमें 768 रोगियों का स्वास्थ्य डेटा और मधुमेह की स्थिति शामिल है।
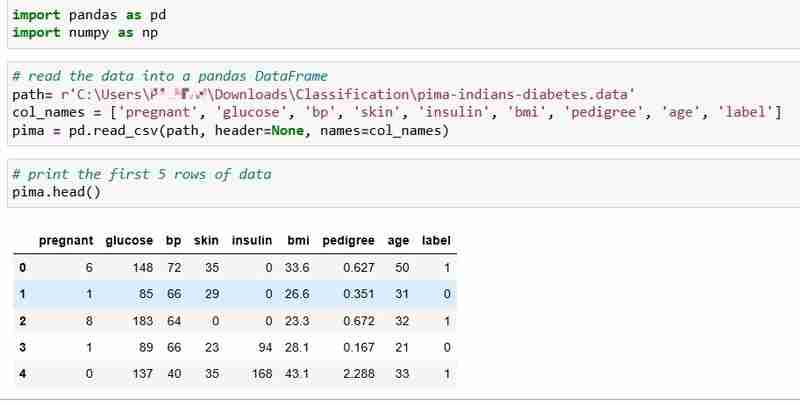
आइए डेटा पढ़ें और डेटा की पहली 5 पंक्तियाँ प्रिंट करें। यदि मरीज को मधुमेह है तो लेबल कॉलम 1 इंगित करता है और यदि रोगी को मधुमेह नहीं है तो 0 इंगित करता है, और हम इस प्रश्न का उत्तर देना चाहते हैं:
प्रश्न: क्या हम किसी मरीज के स्वास्थ्य माप को देखते हुए उसकी मधुमेह की स्थिति का अनुमान लगा सकते हैं?
हम अपनी सुविधाओं मेट्रिक्स एक्स और प्रतिक्रिया वेक्टर वाई को परिभाषित करते हैं। हम एक्स और वाई को प्रशिक्षण और परीक्षण सेट में विभाजित करने के लिए ट्रेन_टेस्ट_स्प्लिट का उपयोग करते हैं।
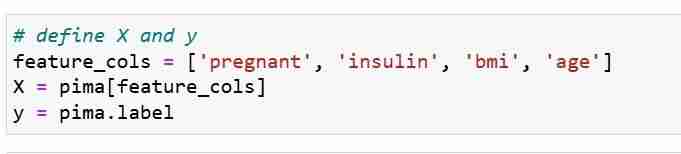
इसके बाद, हम प्रशिक्षण सेट पर एक लॉजिस्टिक रिग्रेशन मॉडल को प्रशिक्षित करते हैं। फ़िट चरण के दौरान, लॉगरेग मॉडल ऑब्जेक्ट X_train और Y_train के बीच संबंध सीख रहा है। अंत में हम परीक्षण सेटों के लिए एक वर्ग पूर्वानुमान बनाते हैं।
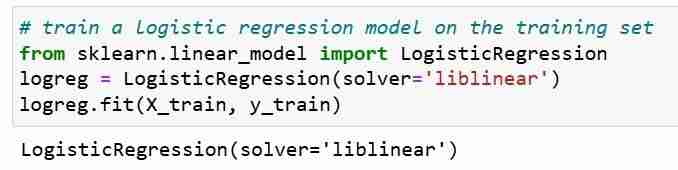

अब, हमने परीक्षण सेट के लिए भविष्यवाणी कर दी है, हम वर्गीकरण सटीकता की गणना कर सकते हैं, जो कि सही भविष्यवाणियों का प्रतिशत है।
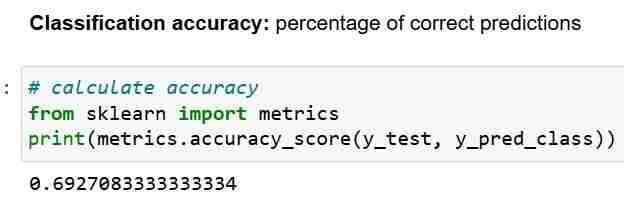
हालाँकि, जब भी आप अपने मूल्यांकन मेट्रिक्स के रूप में वर्गीकरण सटीकता का उपयोग करते हैं, तो इसकी तुलना शून्य सटीकता से करना महत्वपूर्ण है, जो वह सटीकता है जिसे हमेशा सबसे लगातार वर्ग की भविष्यवाणी करके प्राप्त किया जा सकता है।

शून्य सटीकता प्रश्न का उत्तर देता है; यदि मेरा मॉडल 100 प्रतिशत समय में प्रमुख वर्ग की भविष्यवाणी करता है, तो यह कितनी बार सही होगा? उपरोक्त परिदृश्य में, y_test के 32% 1 (एक) हैं। दूसरे शब्दों में, एक मूर्ख मॉडल जो भविष्यवाणी करता है कि रोगियों को मधुमेह है, वह सही होगा 68% समय (जो शून्य है)। यह एक आधार रेखा प्रदान करता है जिसके विरुद्ध हम अपने लॉजिस्टिक रिग्रेशन को मापना चाहते हैं नमूना।
जब हम 68% की शून्य सटीकता और 69% की मॉडल सटीकता की तुलना करते हैं, तो हमारा मॉडल बहुत अच्छा नहीं दिखता है। यह मॉडल मूल्यांकन मीट्रिक के रूप में वर्गीकरण सटीकता की एक कमजोरी को प्रदर्शित करता है। वर्गीकरण सटीकता हमें परीक्षण परीक्षण के अंतर्निहित वितरण के बारे में कुछ नहीं बताती है।
सारांश:
- वर्गीकरण सटीकता समझने में सबसे आसान वर्गीकरण मीट्रिक है
- लेकिन, यह आपको प्रतिक्रिया मूल्यों का अंतर्निहित वितरण नहीं बताता है
- और, यह आपको नहीं बताता कि आपका क्लासिफायरियर कौन सी "प्रकार" की त्रुटियां कर रहा है।
आइए अब भ्रम की स्थिति को देखें।
असमंजस का जाल
कन्फ्यूजन मैट्रिक्स एक तालिका है जो वर्गीकरण मॉडल के प्रदर्शन का वर्णन करती है।
यह आपके क्लासिफायरियर के प्रदर्शन को समझने में आपकी मदद करने के लिए उपयोगी है, लेकिन यह एक मॉडल मूल्यांकन मीट्रिक नहीं है; इसलिए आप यह नहीं कह सकते कि सर्वोत्तम भ्रम मैट्रिक्स वाला मॉडल चुनना सीखें। हालाँकि, ऐसे कई मेट्रिक्स हैं जिनकी गणना कन्फ्यूजन मैट्रिक्स से की जा सकती है और उनका उपयोग सीधे मॉडलों के बीच चयन करने के लिए किया जा सकता है।
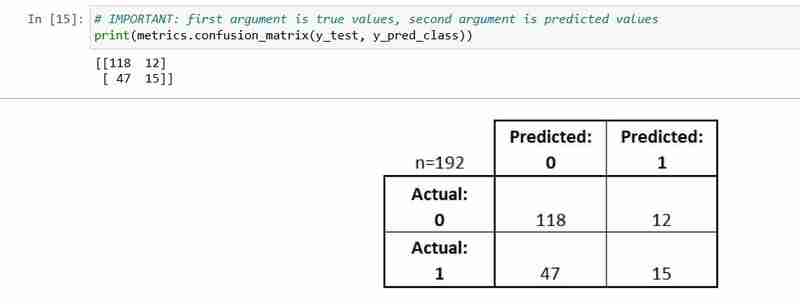
- परीक्षण सेट में प्रत्येक अवलोकन को बिल्कुल एक बॉक्स में दर्शाया गया है
- यह एक 2x2 मैट्रिक्स है क्योंकि इसमें 2 प्रतिक्रिया वर्ग हैं
- यहां दिखाया गया प्रारूप नहीं सार्वभौमिक है
आइए इसकी कुछ बुनियादी शब्दावली समझाएं।
- सच्चे सकारात्मक (टीपी): हमने सही भविष्यवाणी की थी कि उन्हें कर मधुमेह है
- सही नकारात्मक (TN): हमने सही भविष्यवाणी की है कि उन्हें नहीं मधुमेह है
- गलत सकारात्मक (एफपी): हमने गलत भविष्यवाणी की थी कि उन्हें मधुमेह है (एक "टाइप I त्रुटि")
- गलत नकारात्मक (एफएन): हमने गलत भविष्यवाणी की थी कि उन्हें नहीं मधुमेह है (एक "टाइप II त्रुटि")
आइए देखें कि हम मैट्रिक्स की गणना कैसे कर सकते हैं
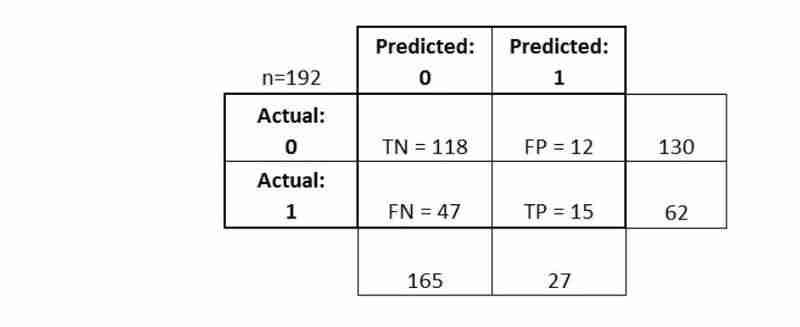


निष्कर्ष के तौर पर:
- कन्फ्यूजन मैट्रिक्स आपको एक अधिक संपूर्ण तस्वीर देता है कि आपका क्लासिफायरियर कैसा प्रदर्शन कर रहा है
- आपको विभिन्न वर्गीकरण मेट्रिक्स की गणना करने की भी अनुमति देता है, और ये मेट्रिक्स आपके मॉडल चयन का मार्गदर्शन कर सकते हैं
-
 क्या जावा में कलेक्शन ट्रैवर्सल के लिए एक-प्रत्येक लूप और एक पुनरावृत्ति का उपयोग करने के बीच एक प्रदर्शन अंतर है?के लिए यह लेख इन दो दृष्टिकोणों के बीच दक्षता के अंतर की पड़ताल करता है। यह आंतरिक रूप से iterator का उपयोग करता है: सूची a = new ArrayList ...प्रोग्रामिंग 2025-07-17 को पोस्ट किया गया
क्या जावा में कलेक्शन ट्रैवर्सल के लिए एक-प्रत्येक लूप और एक पुनरावृत्ति का उपयोग करने के बीच एक प्रदर्शन अंतर है?के लिए यह लेख इन दो दृष्टिकोणों के बीच दक्षता के अंतर की पड़ताल करता है। यह आंतरिक रूप से iterator का उपयोग करता है: सूची a = new ArrayList ...प्रोग्रामिंग 2025-07-17 को पोस्ट किया गया -
तीन MySQL तालिकाओं से डेटा को एक नई तालिका में कैसे संयोजित करें?] लोग, विवरण, और टैक्सोनॉमी टेबल? पी।*, उम्र के रूप में d.content का चयन करें पी के रूप में लोगों से D.Person_id = P.ID पर D के रूप में विवरण में शामि...प्रोग्रामिंग 2025-07-17 को पोस्ट किया गया
-
क्या मुझे कार्यक्रम से बाहर निकलने से पहले C ++ में स्पष्ट रूप से ढेर आवंटन को हटाने की आवश्यकता है?] यह लेख इस विषय में देरी करता है। C मुख्य फ़ंक्शन में, एक गतिशील रूप से आवंटित चर (हीप मेमोरी) के लिए एक सूचक का उपयोग किया जाता है। जैसा कि एप्लिक...प्रोग्रामिंग 2025-07-17 को पोस्ट किया गया
-
RPC विधि अन्वेषण के लिए GO इंटरफ़ेस का चिंतनशील गतिशील कार्यान्वयन] एक प्रश्न जो उठाया गया है, क्या यह एक नया फ़ंक्शन बनाने के लिए प्रतिबिंब का उपयोग करना संभव है जो एक विशिष्ट इंटरफ़ेस को लागू करता है। उदाहरण के लिए...प्रोग्रामिंग 2025-07-17 को पोस्ट किया गया
-
जावा में पर्यवेक्षक पैटर्न का उपयोग करके कस्टम घटनाओं को कैसे लागू करें?] इस लेख का उद्देश्य निम्नलिखित को संबोधित करना है: समस्या विवरण हम विशिष्ट घटनाओं के आधार पर वस्तुओं के बीच बातचीत की सुविधा के लिए जावा में ...प्रोग्रामिंग 2025-07-17 को पोस्ट किया गया
-
पायथन में स्ट्रिंग्स से इमोजी को कैसे निकालें: आम त्रुटियों को ठीक करने के लिए एक शुरुआत का मार्गदर्शिका?] पायथन 2 पर U '' उपसर्ग का उपयोग करके यूनिकोड स्ट्रिंग्स को नामित किया जाना चाहिए। इसके अलावा, re.unicode ध्वज को नियमित अभिव्यक्ति में पारित...प्रोग्रामिंग 2025-07-17 को पोस्ट किया गया
-
गो वेब एप्लिकेशन कब डेटाबेस कनेक्शन को बंद करता है?] यहाँ एक गहरी गोता है कि कब और कैसे इसे अनिश्चित काल तक चलने वाले अनुप्रयोगों में संभालना है। func मुख्य () { var इर त्रुटि DB, ERR = SQL.OPE...प्रोग्रामिंग 2025-07-17 को पोस्ट किया गया
-
`JSON` पैकेज का उपयोग करके जाने में JSON सरणियों को कैसे पार्स करें?उदाहरण: निम्नलिखित गो कोड पर विचार करें: सरणी [] स्ट्रिंग } func मुख्य () { datajson: = `[" 1 "," 2 "," 3 "...प्रोग्रामिंग 2025-07-17 को पोस्ट किया गया
-
क्या CSS किसी भी विशेषता मान के आधार पर HTML तत्वों का पता लगा सकता है?CSS में किसी भी विशेषता मान के साथ HTML तत्वों को लक्षित करना input[type=text] { font-family: Consolas; } हालांकि, एक सामान्य सवाल उठता ...प्रोग्रामिंग 2025-07-17 को पोस्ट किया गया
-
सरणी] एरेज़ ऑब्जेक्ट हैं, इसलिए उनके पास जेएस में भी तरीके हैं। स्लाइस (शुरुआत): मूल सरणी को म्यूट किए बिना, एक नए सरणी में सरणी का हिस्सा निकाले...प्रोग्रामिंग 2025-07-17 को पोस्ट किया गया
-
MySQL में दो स्थितियों के आधार पर पंक्तियों को कुशलता से कैसे डालें या अपडेट करें?] मौजूदा पंक्ति यदि कोई मैच पाया जाता है। यह शक्तिशाली सुविधा एक नई पंक्ति सम्मिलित करके कुशल डेटा हेरफेर के लिए अनुमति देती है यदि कोई मिलान पंक्ति म...प्रोग्रामिंग 2025-07-17 को पोस्ट किया गया
-
मैं पायथन की समझ का उपयोग करके कुशलता से शब्दकोश कैसे बना सकता हूं?] हालांकि वे सूची की समझ के समान हैं, कुछ उल्लेखनीय अंतर हैं। आपको स्पष्ट रूप से कुंजी और मूल्यों को निर्दिष्ट करना होगा। उदाहरण के लिए: d = {n: n *...प्रोग्रामिंग 2025-07-17 को पोस्ट किया गया
-
PHP और C ++ फ़ंक्शन अधिभार प्रसंस्करण के बीच का अंतर] यह अवधारणा, जबकि C में आम, PHP में एक अनूठी चुनौती है। चलो PHP फ़ंक्शन ओवरलोडिंग की पेचीदगियों में तल्लीन करें और यह प्रदान करने वाली संभावनाओं का प...प्रोग्रामिंग 2025-07-17 को पोस्ट किया गया
-
आप MySQL में डेटा को पिवट करने के लिए समूह का उपयोग कैसे कर सकते हैं?] यहाँ, हम एक सामान्य चुनौती से संपर्क करते हैं: पंक्ति-आधारित से स्तंभ-आधारित डेटा को बदलना समूह द्वारा समूह का उपयोग करके। आइए निम्न क्वेरी पर विचार...प्रोग्रामिंग 2025-07-17 को पोस्ट किया गया
-
गुमनाम जावास्क्रिप्ट इवेंट हैंडलर को साफ -सुथरा कैसे निकालें?] तत्व? तत्व। जब तक हैंडलर का संदर्भ निर्माण में संग्रहीत नहीं किया गया था, तब तक एक गुमनाम इवेंट हैंडलर को साफ करने का कोई तरीका नहीं है। यह आवश्...प्रोग्रामिंग 2025-07-17 को पोस्ट किया गया















चीनी भाषा का अध्ययन करें
- 1 आप चीनी भाषा में "चलना" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 2 आप चीनी भाषा में "विमान ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 3 आप चीनी भाषा में "ट्रेन ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 4 आप चीनी भाषा में "बस ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 5 चीनी भाषा में ड्राइव को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 6 तैराकी को चीनी भाषा में क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 7 आप चीनी भाषा में साइकिल चलाने को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 8 आप चीनी भाषा में नमस्ते कैसे कहते हैं? 你好चीनी उच्चारण, 你好चीनी सीखना
- 9 आप चीनी भाषा में धन्यवाद कैसे कहते हैं? 谢谢चीनी उच्चारण, 谢谢चीनी सीखना
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









