
एन्ट्रोपिक्स: अनुमान प्रदर्शन को अधिकतम करने के लिए नमूनाकरण तकनीकें
 ब्राउज़ करें:504
ब्राउज़ करें:504
एन्ट्रोपिक्स: अनुमान प्रदर्शन को अधिकतम करने के लिए नमूनाकरण तकनीकें
एंट्रोपिक्स रीडमी के अनुसार, एंट्रोपिक्स एक एन्ट्रॉपी-आधारित नमूनाकरण विधि का उपयोग करता है। यह आलेख एन्ट्रापी और वेरेंट्रोपी पर आधारित विशिष्ट नमूनाकरण तकनीकों की व्याख्या करता है।
एन्ट्रॉपी और वैरेंट्रोपी
आइए एन्ट्रॉपी और वेरेंट्रोपी की व्याख्या करके शुरुआत करें, क्योंकि ये नमूनाकरण रणनीति निर्धारित करने में प्रमुख कारक हैं।
एन्ट्रापी
सूचना सिद्धांत में, एन्ट्रापी एक यादृच्छिक चर की अनिश्चितता का एक माप है। एक यादृच्छिक चर X की एन्ट्रापी को निम्नलिखित समीकरण द्वारा परिभाषित किया गया है:
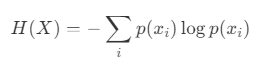
- एक्स: एक असतत यादृच्छिक चर।
- x_i: X की i-वीं संभावित स्थिति।
- p(x_i): स्थिति x_i की संभावना।
जब संभाव्यता वितरण एक समान होता है तो एन्ट्रॉपी अधिकतम होती है। इसके विपरीत, जब एक विशिष्ट स्थिति दूसरों की तुलना में बहुत अधिक होती है, तो एन्ट्रापी कम हो जाती है।
वैरेंट्रोपी
एन्ट्रॉपी से निकटता से संबंधित वैरेंट्रोपी, सूचना सामग्री में परिवर्तनशीलता का प्रतिनिधित्व करती है। सूचना सामग्री I(X), एन्ट्रॉपी H(X), और एक यादृच्छिक चर X के लिए विचरण को ध्यान में रखते हुए, varentropy V E(X) को इस प्रकार परिभाषित किया गया है:
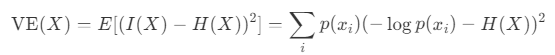
नमूना लेने के तरीके
अगला, आइए देखें कि एन्ट्रापी और वेरेंट्रोपी मूल्यों के आधार पर नमूनाकरण रणनीतियाँ कैसे बदलती हैं।
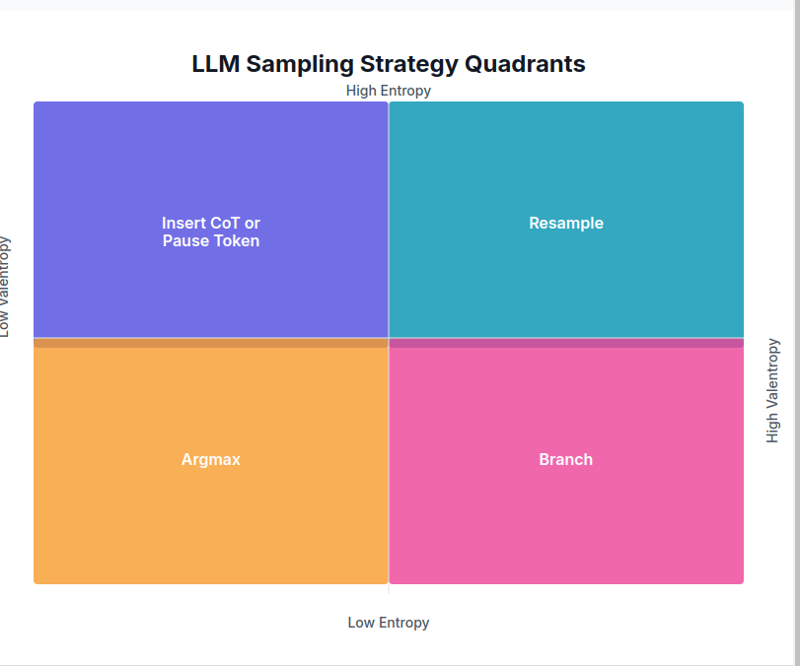
इस परिदृश्य में, एक विशेष टोकन में दूसरों की तुलना में बहुत अधिक भविष्यवाणी की संभावना होती है। चूँकि अगला टोकन लगभग निश्चित है,
Argmax का उपयोग किया जाता है।
2. निम्न एन्ट्रॉपी, उच्च वेरेंट्रोपी → शाखा
ऐसा तब होता है जब कुछ आत्मविश्वास होता है, लेकिन कई व्यवहार्य विकल्प मौजूद होते हैं। इस मामले में,
शाखा रणनीति का उपयोग कई विकल्पों से नमूना लेने और सर्वोत्तम परिणाम का चयन करने के लिए किया जाता है।
if ent कोड लिंकहालांकि इस रणनीति को "ब्रांच" कहा जाता है, लेकिन वर्तमान कोड नमूना सीमा को समायोजित करने और एकल पथ का चयन करने के लिए प्रतीत होता है। (यदि किसी के पास अधिक जानकारी है, तो आगे के स्पष्टीकरण की सराहना की जाएगी।)
3. उच्च एन्ट्रॉपी, निम्न वेरेंट्रोपी → सीओटी या इन्सर्ट पॉज़ टोकन
जब अगले टोकन की भविष्यवाणी संभावनाएं काफी समान होती हैं, यह दर्शाता है कि अगला संदर्भ निश्चित नहीं है, तो अस्पष्टता को हल करने के लिए एक
स्पष्टीकरण टोकन डाला जाता है।
elif ent > 3.0 और वेंट if ent कोड लिंक
4. उच्च एन्ट्रॉपी, उच्च वेरेंट्रोपी → पुनः नमूना
इस मामले में, कई संदर्भ हैं, और अगले टोकन की भविष्यवाणी की संभावनाएं कम हैं। एक
रीसैंपलिंग रणनीति का उपयोग उच्च तापमान सेटिंग और निचले टॉप-पी के साथ किया जाता है।
elif ent > 5.0 और वेंट > 5.0: temp_adj = 2.0 0.5 * attn_vent शीर्ष_p_adj = अधिकतम(0.5, शीर्ष_पी - 0.2 * attn_ent) वापसी _नमूना(लॉगिट्स, तापमान=अधिकतम(2.0, तापमान * temp_adj), टॉप_पी=टॉप_पी_एडजे, टॉप_के=टॉप_के, न्यूनतम_पी=मिनट_पी, जेनरेटर=जनरेटर)
if ent कोड लिंकमध्यवर्ती मामले
यदि उपरोक्त में से कोई भी शर्त पूरी नहीं होती है, तो
अनुकूली नमूनाकरण किया जाता है। एकाधिक नमूने लिए जाते हैं, और सर्वोत्तम नमूना स्कोर की गणना एन्ट्रॉपी, वेरेंट्रोपी और ध्यान संबंधी जानकारी के आधार पर की जाती है।
अन्य: अनुकूली_नमूना लौटाएं( लॉगिट्स, मेट्रिक्स, जेन_टोकन, n_नमूने=5, बेस_टेम्प=तापमान, बेस_टॉप_पी=टॉप_पी, बेस_टॉप_के=टॉप_के, जेनरेटर=जनरेटर )
if ent कोड लिंक
संदर्भ
- एंट्रोपिक्स रिपॉजिटरी
- एंट्रोपिक्स क्या कर रहा है?
-
 गुमनाम जावास्क्रिप्ट इवेंट हैंडलर को साफ -सुथरा कैसे निकालें?] तत्व? तत्व। जब तक हैंडलर का संदर्भ निर्माण में संग्रहीत नहीं किया गया था, तब तक एक गुमनाम इवेंट हैंडलर को साफ करने का कोई तरीका नहीं है। यह आवश्...प्रोग्रामिंग 2025-03-10 को पोस्ट किया गया
गुमनाम जावास्क्रिप्ट इवेंट हैंडलर को साफ -सुथरा कैसे निकालें?] तत्व? तत्व। जब तक हैंडलर का संदर्भ निर्माण में संग्रहीत नहीं किया गया था, तब तक एक गुमनाम इवेंट हैंडलर को साफ करने का कोई तरीका नहीं है। यह आवश्...प्रोग्रामिंग 2025-03-10 को पोस्ट किया गया -
गतिशील रूप से आकार के मूल तत्व के भीतर एक तत्व की स्क्रॉलिंग रेंज को कैसे सीमित करें?] इस तरह के एक परिदृश्य में गतिशील रूप से आकार के मूल तत्व के भीतर एक तत्व की स्क्रॉलिंग रेंज को सीमित करना शामिल है। हालाँकि, नक्शे की स्क्रॉलिंग अनि...प्रोग्रामिंग 2025-03-10 को पोस्ट किया गया
-
ऑब्जेक्ट-फिट: कवर IE और एज में विफल रहता है, कैसे ठीक करें?] सीएसएस में लगातार छवि ऊंचाई बनाए रखने के लिए ब्राउज़रों में मूल रूप से काम करता है। हालांकि, IE और एज में, एक अजीबोगरीब मुद्दा उठता है। ब्राउज़र को ...प्रोग्रामिंग 2025-03-10 को पोस्ट किया गया
-
PYTZ शुरू में अप्रत्याशित समय क्षेत्र ऑफसेट क्यों दिखाता है?] उदाहरण के लिए, एशिया/hong_kong शुरू में एक सात घंटे और 37 मिनट की ऑफसेट दिखाता है: आयात pytz Std> विसंगति स्रोत समय क्षेत्र और ऑफसेट प...प्रोग्रामिंग 2025-03-10 को पोस्ट किया गया
-
मैं पूरे HTML दस्तावेज़ में एक विशिष्ट तत्व प्रकार के पहले उदाहरण को कैसे स्टाइल कर सकता हूं?] : प्रथम-प्रकार के छद्म-क्लास अपने मूल तत्व के भीतर एक प्रकार के पहले तत्व से मेल खाने तक सीमित है। एक प्रकार का पहला तत्व, एक जावास्क्रिप्ट सम...प्रोग्रामिंग 2025-03-10 को पोस्ट किया गया
-
HTML स्वरूपण टैगHTML स्वरूपण तत्व ] HTML हमें CSS का उपयोग किए बिना पाठ को प्रारूपित करने की क्षमता प्रदान करता है। HTML में कई स्वरूपण टैग हैं। इन टैगों ...प्रोग्रामिंग 2025-03-10 को पोस्ट किया गया
-
मैं PHP का उपयोग करके XML फ़ाइलों से विशेषता मानों को कैसे प्राप्त कर सकता हूं?] एक XML फ़ाइल के साथ काम करते समय, जिसमें प्रदान किए गए उदाहरण की विशेषताएं होती हैं: var [0]-> विशेषताएँ () () के रूप में $ atributename => $ a...प्रोग्रामिंग 2025-03-10 को पोस्ट किया गया
-
क्या शुद्ध सीएसएस में एक दूसरे के ऊपर कई चिपचिपे तत्वों को स्टैक किया जा सकता है?यहाँ: https://webthemez.com/demo/sticky-multi-hroll/index.html केवल मैं एक जावास्क्रिप्ट कार्यान्वयन के बजाय शुद्ध CSS का उपयोग करना पसंद करू...प्रोग्रामिंग 2025-03-10 को पोस्ट किया गया
-
PHP सरणी कुंजी-मूल्य विसंगतियाँ: 07 और 08 के जिज्ञासु मामले को समझना] PHP में, एक असामान्य मुद्दा तब उत्पन्न होता है जब कुंजियों में 07 या 08 जैसे संख्यात्मक मान होते हैं। Print_r ($ महीने) चलाना अप्रत्याशित परिणाम देत...प्रोग्रामिंग 2025-03-10 को पोस्ट किया गया
-
आप PHP में एक सरणी से एक यादृच्छिक तत्व कैसे निकालते हैं?] निम्नलिखित सरणी पर विचार करें: $ आइटम = [५२३, ३४५२, ३३४, ३१, ५३४६]; Array_rand () फ़ंक्शन सरणी से एक यादृच्छिक कुंजी देता है। इस कुंजी के साथ $ आइ...प्रोग्रामिंग 2025-03-10 को पोस्ट किया गया
-
क्यों isn \ 't मेरी css पृष्ठभूमि छवि दिखाई दे रही है?] छवि और स्टाइल शीट एक ही निर्देशिका में निवास कर रही है, फिर भी पृष्ठभूमि एक खाली सफेद कैनवास बनी हुई है। छवि को संलग्न करने वाले उद्धरण फ़ाइल नाम: ...प्रोग्रामिंग 2025-03-10 को पोस्ट किया गया
-
मान्य कोड के बावजूद PHP में इनपुट कैप्चरिंग इनपुट क्यों है?] $ _Server ['php_self']?> हालांकि, आउटपुट खाली रहता है। जबकि विधि = "प्राप्त करें" मूल रूप से काम करती है, विधि = "पोस्ट"...प्रोग्रामिंग 2025-03-10 को पोस्ट किया गया
-
CSS `सामग्री` प्रॉपर्टी का उपयोग करके फ़ायरफ़ॉक्स चित्र क्यों नहीं है?] यह प्रदान किए गए CSS वर्ग में देखा जा सकता है: । Googlepipic { सामग्री: url ('../../ img/googleplusicon.png'); मार्जिन -टॉप: -6.5%;...प्रोग्रामिंग 2025-03-10 को पोस्ट किया गया
-
कैसे जांचें कि क्या किसी वस्तु की पायथन में एक विशिष्ट विशेषता है?] निम्नलिखित उदाहरण पर विचार करें जहां एक अपरिभाषित संपत्ति तक पहुंचने का प्रयास एक त्रुटि उठाता है: >>> a = someclass () >>> a.property ट्रेसबैक (स...प्रोग्रामिंग 2025-03-10 को पोस्ट किया गया
-
क्या जावा में कलेक्शन ट्रैवर्सल के लिए एक-प्रत्येक लूप और एक पुनरावृत्ति का उपयोग करने के बीच एक प्रदर्शन अंतर है?के लिए यह लेख इन दो दृष्टिकोणों के बीच दक्षता के अंतर की पड़ताल करता है। यह आंतरिक रूप से iterator का उपयोग करता है: सूची a = new ArrayList ...प्रोग्रामिंग 2025-03-10 को पोस्ट किया गया















चीनी भाषा का अध्ययन करें
- 1 आप चीनी भाषा में "चलना" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 2 आप चीनी भाषा में "विमान ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 3 आप चीनी भाषा में "ट्रेन ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 4 आप चीनी भाषा में "बस ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 5 चीनी भाषा में ड्राइव को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 6 तैराकी को चीनी भाषा में क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 7 आप चीनी भाषा में साइकिल चलाने को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 8 आप चीनी भाषा में नमस्ते कैसे कहते हैं? 你好चीनी उच्चारण, 你好चीनी सीखना
- 9 आप चीनी भाषा में धन्यवाद कैसे कहते हैं? 谢谢चीनी उच्चारण, 谢谢चीनी सीखना
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









