
जावा में टाइप ट्रांसफर का ध्यान रखें
 ब्राउज़ करें:226
ब्राउज़ करें:226
जावा एक दृढ़ता से टाइप की जाने वाली भाषा है, लेकिन विभिन्न प्रकार के आदिम चर के बीच मूल्यों को स्थानांतरित करना अभी भी संभव है। उदाहरण के लिए, मैं किसी भी समस्या के बिना एक इंट के मान को डबल तक असाइन कर सकता हूं, जब तक कि मान प्राप्त करने वाले प्रकार की भंडारण क्षमता इसे संभाल सकती है।
प्रत्येक आदिम प्रकार का आकार नीचे देखें:
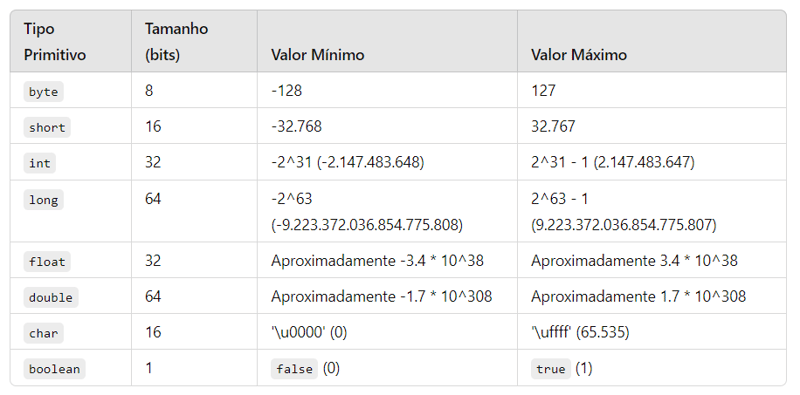
अधिक भंडारण क्षमता वाले प्रकार में मान स्थानांतरित करने का एक तकनीकी नाम है: "विस्तृत रूपांतरण"। पुर्तगाली में इस शब्द का अनुवाद आमतौर पर "विस्तार रूपांतरण" या "विस्तृत रूपांतरण" के रूप में किया जाता है। यह उस प्रक्रिया को संदर्भित करता है जिसमें जानकारी के नुकसान के बिना छोटे या अधिक प्रतिबंधित डेटा प्रकार से एक मान को बड़े या अधिक व्यापक प्रकार में परिवर्तित किया जाता है।
लेकिन क्या होगा यदि मैं मूल्य को कम भंडारण क्षमता वाले प्रकार में स्थानांतरित करना चाहता हूं? जावा कंपाइलर को यह पसंद नहीं है, लेकिन यदि आप इसे कास्ट करते हैं तो यह इसकी अनुमति देगा, जैसा कि नीचे दिए गए उदाहरण में है।
double decimal = 65.9; int i = (int) decimal; //aqui ele perde a casa decimal e vira 65 char c = (char) i; //aqui ele vira a letra A (que corresponde a 65)
यदि नए प्रकार में जाने वाले मूल्य का आकार उस प्रकार की सीमा से अधिक है, तो कुछ अधिक नाटकीय हो सकता है। एक int i = 10 एक बाइट वेरिएबल में फिट बैठता है, क्योंकि इसमें -128 से 127 तक की रेंज में 8 बिट्स होते हैं। हालाँकि, अगर मैं टाइप बाइट के एक वेरिएबल में एक int i = 128 डालना चाहता हूं तो क्या होगा...वहां होगा जानकारी का नुकसान .
public class Main
{
public static void main(String[] args) {
int i = 128;
byte b = (byte) i;
System.out.println(b); // o valor de b agora é -128 :S
}
}
ऑटोबॉक्सिंग
पिछली पोस्ट में [इसे यहां पढ़ें], मैंने रैपर कक्षाओं के बारे में थोड़ी बात की थी। उदाहरण के तौर पर, मैंने Integer.parse(i) लिखा था = कल्पना करें कि i एक प्रकार है
आदिम इंट.
वर्तमान में, रैपर पार्स विधि का उपयोग अब प्रोत्साहित नहीं किया जाता है क्योंकि इसे अस्वीकृत कर दिया गया है। किसी प्रिमिटिव को रैपर क्लास में बदलने के लिए और, इस तरह, अंतर्निहित तरीकों का उपयोग करने के लिए, "ऑटोबॉक्सिंग" करने की अनुशंसा की जाती है, जैसा कि उदाहरण में है:
Character ch = 'a'; Integer i = 10;
ध्यान दें कि यह अधिक सीधा दृष्टिकोण है। आप बस एक ही बार में सभी मान निर्दिष्ट कर देते हैं।
इसके विपरीत करने और डेटा को एक आदिम प्रकार के रूप में वापस करने के लिए, आप valueOf:
विधि का उपयोग करके "अनबॉक्सिंग" कर सकते हैं
Integer i = 10; int j = Integer.valueOf(i);
जैसा कि मैंने पिछली पोस्ट में कहा था, आदिम का रैपर बनाने से आपको क्लास के तरीकों का उपयोग करने की सुविधा मिलती है और डेटा के साथ काम करते समय जीवन आसान हो जाता है।
किसी प्रिमिटिव का रैपर संस्करण पहली नज़र में काफी हद तक उसके जैसा लग सकता है, लेकिन जेवीएम किसी ऑब्जेक्ट और प्रिमिटिव के साथ एक जैसा व्यवहार नहीं करता है, मत भूलिए। याद रखें कि आदिम लोग स्टैक पर जाते हैं और ऑब्जेक्ट ढेर पर जाते हैं [यहां याद रखें]।
प्रदर्शन के संदर्भ में, यह स्पष्ट है कि आदिम से डेटा पुनर्प्राप्त करना कंप्यूटर के लिए कम महंगा है, क्योंकि मूल्य सीधे संग्रहीत किया जाता है, संदर्भ द्वारा नहीं। टुकड़ों को मेमोरी में एक साथ रखने की तुलना में तैयार डेटा प्राप्त करना कहीं अधिक तेज़ है।
लेकिन ऐसे मामले भी हैं जहां रैपर का उपयोग करना आवश्यक होगा। उदाहरण के लिए, जब आप ArrayList क्लास के साथ काम करना चाहते हैं। यह केवल वस्तुओं को पैरामीटर के रूप में स्वीकार करता है, आदिम मानों के रूप में नहीं।
आदिम से वस्तु और इसके विपरीत में यह परिवर्तन भाषा के बारे में जो लचीलापन लाता है वह वास्तव में अच्छा है। लेकिन हमें यहां और कई अन्य चर्चाओं के बारे में जागरूक होने की जरूरत है।
बस समाज को चौंका देने के लिए (हंसना), मैं एक समस्याग्रस्त मामले का उदाहरण देने जा रहा हूं जिसमें ओवरलोडिंग के साथ काम करते समय एक कोड का अप्रत्याशित व्यवहार शामिल है (मैंने अभी तक ओवरलोडिंग के बारे में कोई पोस्ट नहीं किया है, लेकिन मैं बनाऊंगा। मूल रूप से, ओवरलोडिंग तब होती है जब किसी विधि में अलग-अलग हस्ताक्षर होते हैं)।
इस मामले का उल्लेख जोशुआ बलोच की पुस्तक "इफेक्टिव जावा" में किया गया था।
public class SetListTest {
public static void main(String[] args) {
Set set = new TreeSet();
List list = new ArrayList();
for (int i = -3; i
इस कार्यक्रम में, उद्देश्य एक सेट और एक सूची में -3 से 2 [-3, -2, -1, 0, 1, 2] तक पूर्णांक मान जोड़ना था। फिर सकारात्मक मान [0, 1 और 2] हटा दें। लेकिन, यदि आप इस कोड को चलाते हैं, तो आप देखेंगे कि सेट और सूची ने समान परिणाम प्रस्तुत नहीं किए। जैसा कि अपेक्षित था, सेट [-3, -2, -1] लौटाता है। सूची रिटर्न [-2, 0, 2]।
ऐसा इसलिए होता है क्योंकि लिस्ट क्लास की बिल्ट-इन रिमूव(i) पद्धति पर कॉल i को एक आदिम प्रकार int के रूप में मानता है, और कुछ नहीं। यह विधि, बदले में, i स्थिति से तत्वों को हटा देती है।
सेट क्लास की रिमूव (i) विधि के लिए कॉल एक ओवरलोड को कॉल करता है जो पैरामीटर के रूप में एक इंटीजर ऑब्जेक्ट प्राप्त करता है, स्वचालित रूप से i, जो मूल रूप से एक इंट था, को इंटीजर में परिवर्तित करता है। इस पद्धति का व्यवहार, बदले में, उन सेट तत्वों को बाहर कर देता है जिनका मान i के बराबर है (और i के बराबर सूचकांक नहीं) - ध्यान दें कि सेट और सूची दोनों के लिए अपेक्षित प्रकार पूर्णांक था। (सेट सेट / सूची सूची)। इसीलिए सेट क्लास की रिमूव विधि के लिए चुनी गई ओवरलोडिंग ने इसे इंटीजर में बदल दिया।
जबकि सूची में हटाने का व्यवहार सूचकांक द्वारा हटाना है, सेट में हटाने का व्यवहार मूल्य के अनुसार हटाना है। यह सब इंटीजर प्राप्त करने वाले रिमूव के ओवरलोडिंग के कारण है।
-
 Visual Studio 2012 में DataSource संवाद में MySQL डेटाबेस कैसे जोड़ें?] यह लेख इस मुद्दे को संबोधित करता है और एक समाधान प्रदान करता है। इसे हल करने के लिए, यह समझना महत्वपूर्ण है कि MySQL के लिए आधिकारिक विजुअल स्टूडियो...प्रोग्रामिंग 2025-04-07 पर पोस्ट किया गया
Visual Studio 2012 में DataSource संवाद में MySQL डेटाबेस कैसे जोड़ें?] यह लेख इस मुद्दे को संबोधित करता है और एक समाधान प्रदान करता है। इसे हल करने के लिए, यह समझना महत्वपूर्ण है कि MySQL के लिए आधिकारिक विजुअल स्टूडियो...प्रोग्रामिंग 2025-04-07 पर पोस्ट किया गया -
कैसे ठीक करें "सामान्य त्रुटि: 2006 MySQL सर्वर डेटा डालते समय दूर चला गया है?] यह त्रुटि तब होती है जब सर्वर का कनेक्शन खो जाता है, आमतौर पर MySQL कॉन्फ़िगरेशन में दो चर में से एक के कारण। ये चर उस अधिकतम समय को नियंत्रित करते ...प्रोग्रामिंग 2025-04-07 पर पोस्ट किया गया
-
मान्य कोड के बावजूद PHP में इनपुट कैप्चरिंग इनपुट क्यों है?] $ _Server ['php_self']?> हालांकि, आउटपुट खाली रहता है। जबकि विधि = "प्राप्त करें" मूल रूप से काम करती है, विधि = "पोस्ट"...प्रोग्रामिंग 2025-04-07 पर पोस्ट किया गया
-
Eval () बनाम ast.literal_eval (): उपयोगकर्ता इनपुट के लिए कौन सा पायथन फ़ंक्शन सुरक्षित है?] eval (), एक शक्तिशाली पायथन फ़ंक्शन, अक्सर एक संभावित समाधान के रूप में उत्पन्न होता है, लेकिन चिंताएं इसके संभावित जोखिमों को घेरती हैं। यह लेख eva...प्रोग्रामिंग 2025-04-07 पर पोस्ट किया गया
-
मेरी रैखिक ढाल पृष्ठभूमि में धारियां क्यों हैं, और मैं उन्हें कैसे ठीक कर सकता हूं?] इन भद्दे कलाकृतियों को एक जटिल पृष्ठभूमि प्रसार घटना के लिए जिम्मेदार ठहराया जा सकता है। इसके बाद, रैखिक-ग्रेडिएंट इस पूरी ऊंचाई पर फैलता है, दोहराए...प्रोग्रामिंग 2025-04-07 पर पोस्ट किया गया
-
मैं जावा स्ट्रिंग में कई सब्सट्रेट्स को कुशलता से कैसे बदल सकता हूं?] हालाँकि, यह बड़े तार के लिए अक्षम हो सकता है या जब कई तार के साथ काम कर रहा है। नियमित अभिव्यक्तियाँ आपको जटिल खोज पैटर्न को परिभाषित करने और एकल ऑप...प्रोग्रामिंग 2025-04-07 पर पोस्ट किया गया
-
तीन MySQL तालिकाओं से डेटा को एक नई तालिका में कैसे संयोजित करें?] लोग, विवरण, और टैक्सोनॉमी टेबल? पी।*, उम्र के रूप में d.content का चयन करें पी के रूप में लोगों से D.Person_id = P.ID पर D के रूप में विवरण में शामि...प्रोग्रामिंग 2025-04-07 पर पोस्ट किया गया
-
मैं PHP में यूनिकोड स्ट्रिंग्स से URL के अनुकूल स्लग कैसे कुशलता से उत्पन्न कर सकता हूं?] यह लेख स्लगों को कुशलता से उत्पन्न करने के लिए एक संक्षिप्त समाधान प्रस्तुत करता है, विशेष वर्णों और गैर-एएससीआईआई वर्णों को URL- अनुकूल स्वरूपों मे...प्रोग्रामिंग 2025-04-07 पर पोस्ट किया गया
-
मैं गो कंपाइलर में संकलन अनुकूलन को कैसे अनुकूलित कर सकता हूं?] हालाँकि, उपयोगकर्ताओं को विशिष्ट आवश्यकताओं के लिए इन अनुकूलन को समायोजित करने की आवश्यकता हो सकती है। इसका मतलब यह है कि कंपाइलर स्वचालित रूप से पू...प्रोग्रामिंग 2025-04-07 पर पोस्ट किया गया
-
गतिशील रूप से आकार के मूल तत्व के भीतर एक तत्व की स्क्रॉलिंग रेंज को कैसे सीमित करें?] इस तरह के एक परिदृश्य में गतिशील रूप से आकार के मूल तत्व के भीतर एक तत्व की स्क्रॉलिंग रेंज को सीमित करना शामिल है। हालाँकि, मानचित्र की स्क्रॉलिंग ...प्रोग्रामिंग 2025-04-07 पर पोस्ट किया गया
-
पायथन के अनुरोधों और नकली उपयोगकर्ता एजेंटों के साथ वेबसाइट ब्लॉक को कैसे बायपास करें?] ऐसा इसलिए है क्योंकि वेबसाइटें एंटी-बॉट उपायों को लागू कर सकती हैं जो वास्तविक ब्राउज़रों और स्वचालित स्क्रिप्ट के बीच अंतर करते हैं। इन ब्लॉकों को ...प्रोग्रामिंग 2025-04-07 पर पोस्ट किया गया
-
होमब्रे से मेरा गो सेटअप क्यों कमांड लाइन निष्पादन मुद्दों का कारण बनता है?] जबकि HomeBrew स्थापना प्रक्रिया को सरल करता है, यह कमांड लाइन निष्पादन और अपेक्षित व्यवहार के बीच एक संभावित विसंगति का परिचय देता है। आपके द्वारा...प्रोग्रामिंग 2025-04-07 पर पोस्ट किया गया
-
HTML स्वरूपण टैगHTML स्वरूपण तत्व ] HTML हमें CSS का उपयोग किए बिना पाठ को प्रारूपित करने की क्षमता प्रदान करता है। HTML में कई स्वरूपण टैग हैं। इन टैगों ...प्रोग्रामिंग 2025-04-07 पर पोस्ट किया गया
-
\ "जबकि (1) बनाम के लिए (;;): क्या संकलक अनुकूलन प्रदर्शन अंतर को समाप्त करता है?] लूप? संकलक: perl: दोनों जबकि (1) और (;; 1 दर्ज करें -> 2 2 नेक्स्टस्टेट (मुख्य 2 -e: 1) v -> 3 9 लेवेलूप वीके/2 -> ए 3 9 4 नेक्स्टस्टेट ...प्रोग्रामिंग 2025-04-07 पर पोस्ट किया गया
-
Google API से नवीनतम JQuery लाइब्रेरी कैसे पुनः प्राप्त करें?] नवीनतम संस्करण को पुनर्प्राप्त करने के लिए, पहले एक विशिष्ट संस्करण संख्या का उपयोग करने का एक विकल्प था, जो निम्न सिंटैक्स का उपयोग करना था: htt...प्रोग्रामिंग 2025-04-07 पर पोस्ट किया गया















चीनी भाषा का अध्ययन करें
- 1 आप चीनी भाषा में "चलना" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 2 आप चीनी भाषा में "विमान ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 3 आप चीनी भाषा में "ट्रेन ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 4 आप चीनी भाषा में "बस ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 5 चीनी भाषा में ड्राइव को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 6 तैराकी को चीनी भाषा में क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 7 आप चीनी भाषा में साइकिल चलाने को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 8 आप चीनी भाषा में नमस्ते कैसे कहते हैं? 你好चीनी उच्चारण, 你好चीनी सीखना
- 9 आप चीनी भाषा में धन्यवाद कैसे कहते हैं? 谢谢चीनी उच्चारण, 谢谢चीनी सीखना
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









