
मैंने एक हल्का मिनी स्प्रिंग विकल्प क्यों बनाया और यह कैसे किया
 ब्राउज़ करें:988
ब्राउज़ करें:988
इस छोटे से लेख में मैं यह समझाने की कोशिश करूंगा कि मैंने यह लाइब्रेरी क्यों बनाई? और इसे कैसे कार्यान्वित किया जाता है?
मैंने यह लाइब्रेरी क्यों बनाई?
मैंने कई परियोजनाओं पर जावा ईई फ्रेमवर्क के साथ काम किया और उनमें से अधिकांश में एप्लिकेशन को चलाने के लिए उपलब्ध संसाधनों पर कोई सीमा नहीं थी, लेकिन कुछ दुर्लभ मामलों में हमारे पास परिनियोजन सेवा पर एप्लिकेशन को तैनात करने के लिए सीमित संसाधन थे, विशेष रूप से मेमोरी। , इसलिए जब एप्लिकेशन सीमा से अधिक हो जाता है तो परिनियोजन सेवा पहले एप्लिकेशन को धीमा कर देगी, फिर यदि यह जारी रहता है तो सेवा इसे बंद कर देगी। हम स्प्रिंग बूट के बिना भी लीगेसी स्प्रिंग फ्रेमवर्क का उपयोग कर रहे थे, हमने विभिन्न लाइब्रेरी का उपयोग करने की कोशिश की लेकिन अंतर न्यूनतम और बेकार था, और यहीं से मेमोरी खपत को जितना संभव हो उतना कम करने पर ध्यान केंद्रित करते हुए हल्के स्प्रिंग विकल्प बनाने का विचार शुरू हुआ। .
जब मैंने लाइब्रेरी डिजाइन करना शुरू किया तो मेरे दिमाग में केवल दो लक्ष्य थे:
1 - मेमोरी खपत को यथासंभव कम करना
2 - सीखने के दृष्टिकोण से और स्वयं संक्रमण की जटिलता से लाइब्रेरी में संक्रमण को आसान बनाने के लिए मौजूदा जावा ईई एपीआई का यथासंभव उपयोग करने का प्रयास करें।
और इन 2 लक्ष्यों के साथ मैं अपने एक एप्लिकेशन की मेमोरी फ़ुटप्रिंट को लगभग 40% तक कम करने में कामयाब रहा और परिवर्तन को आसान और तेज़ बना दिया क्योंकि यह मौजूदा समाधानों के समान है।
मैंने यह लाइब्रेरी कैसे बनाई?
यहां GitHub रिपॉजिटरी है ताकि आप पढ़ते समय कोड की जांच कर सकें।
संपूर्ण लाइब्रेरी में कई भाग होते हैं (नीचे स्क्रीनशॉट), अधिकांश कार्यान्वयन मुख्य मॉड्यूल में होता है जिसे तीन प्रकार के स्वतंत्र मॉड्यूल में भी विभाजित किया जाता है: कोर, जेपीए, वेब। ऐप मॉड्यूल मुख्य रूप से एकीकरण के लिए है, प्लगइन मॉड्यूल एक मेवेन प्लगइन है जो लाइब्रेरी को ठीक से काम करने के लिए पैकेज संग्रह के अंदर आवश्यक फाइलें बनाने में मदद करता है।
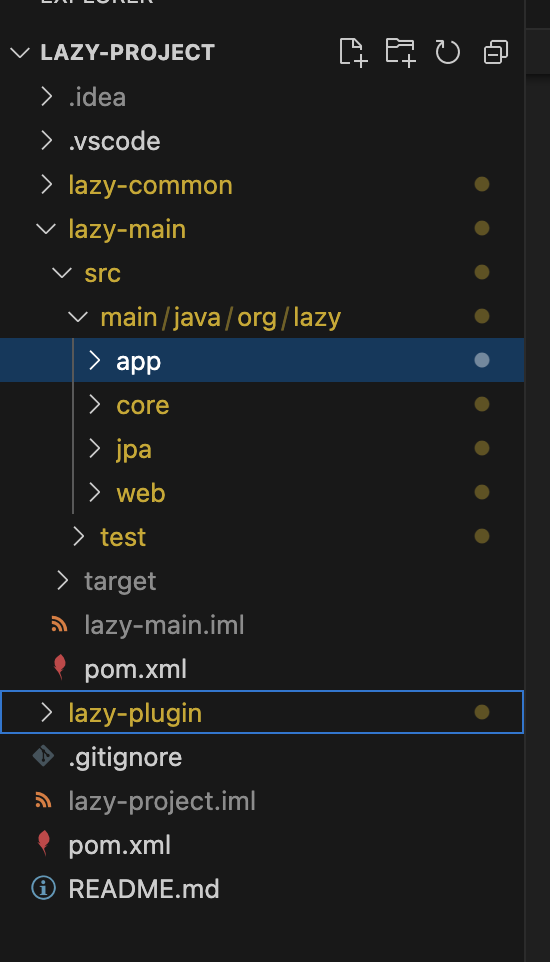
कोर मॉड्यूल
इसलिए हम कोर मॉड्यूल से शुरुआत करेंगे, जैसा कि नाम से पता चलता है, इसमें लाइब्रेरी की मुख्य कार्यक्षमता शामिल है जो निर्भरता इंजेक्शन या नियंत्रण का उलटा है।
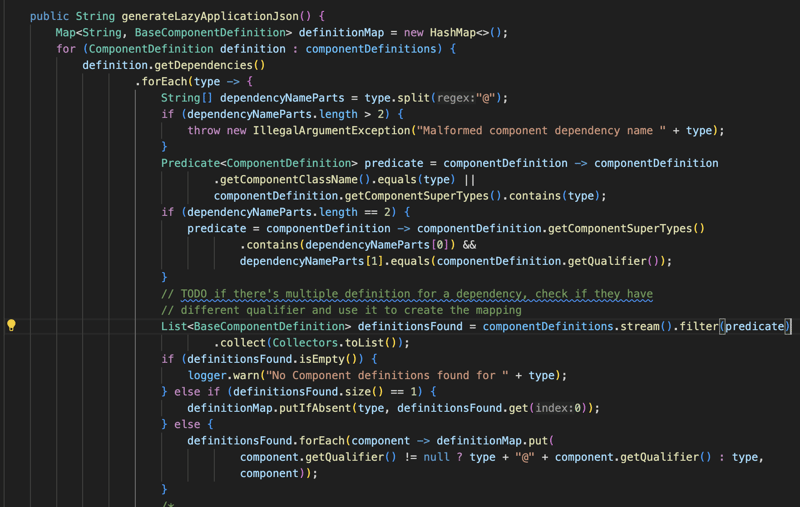
इस कार्यात्मकता को प्राप्त करने के लिए, सबसे पहले यह सभी एनोटेटेड क्लास के लिए संकलन चरण के दौरान एप्लिकेशन के क्लास पथ को स्कैन करके शुरू होता है, लाइब्रेरी को एनोटेटेड क्लास के लिए एक घटक परिभाषा बनाने का प्रबंधन करना चाहिए।
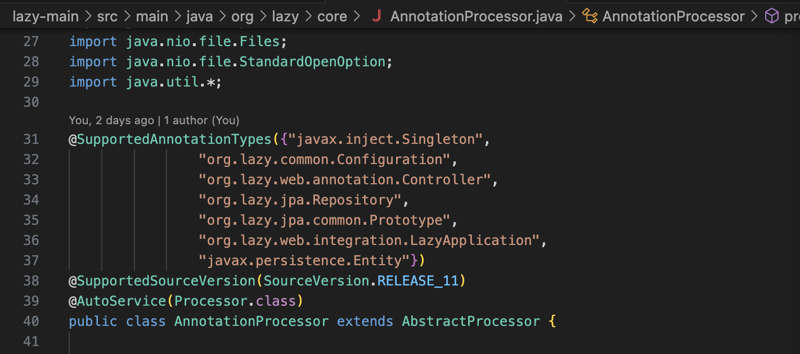
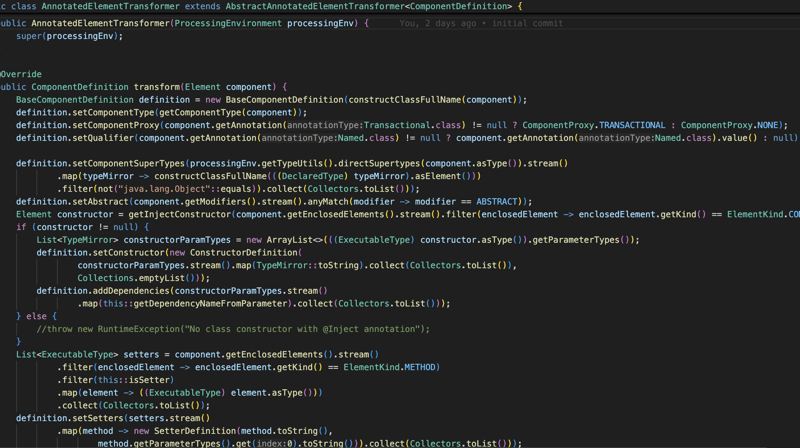
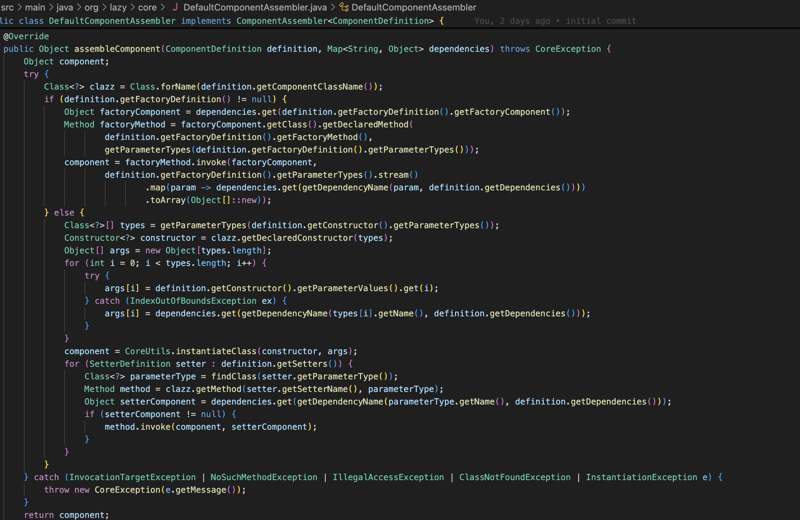
घटक परिभाषा में मूल रूप से वह सारी जानकारी होती है जिसकी हमें बाद में इस क्लास से किसी ऑब्जेक्ट को इंस्टेंट करने के लिए आवश्यकता होगी, जैसे कि कंस्ट्रक्टर जानकारी, यदि क्लास में इंजेक्ट एनोटेशन के साथ कुछ सेटर हैं (केवल कंस्ट्रक्टर और सेटर इंजेक्शन समर्थित हैं) कुछ इंटरफ़ेस या किसी अन्य वर्ग का विस्तार, हमारे पास इस वर्ग से एक ऑब्जेक्ट बनाने के लिए आवश्यक सभी जानकारी होगी (नीचे स्क्रीनशॉट)।
और फिर, जब हम सभी क्लास पथ एनोटेशन को स्कैन करते हैं और हम सभी घटक परिभाषा बनाते हैं जिनकी हमें आवश्यकता होती है तो हम उन्हें JSON फ़ाइल के रूप में क्लास पथ में संग्रहीत करेंगे।
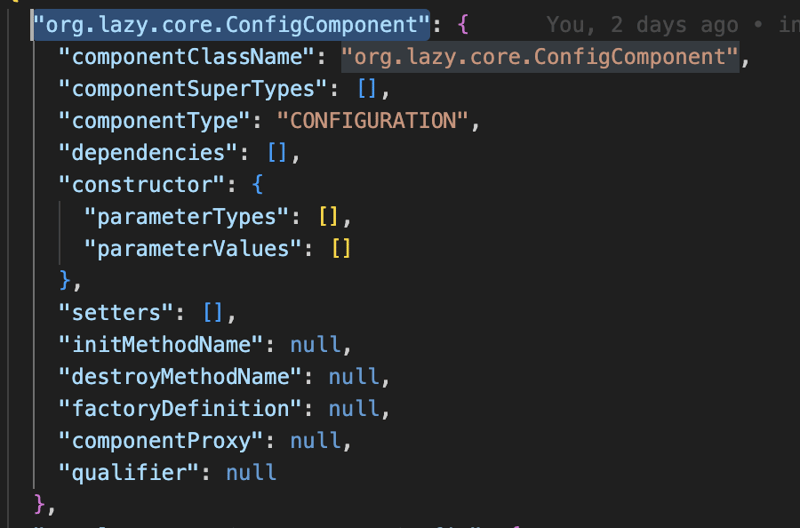
कोर मॉड्यूल की दूसरी और मुख्य कार्यक्षमता निर्भरता इंजेक्शन और नियंत्रण का उलटा है जो फ़ैक्टरी डिज़ाइन पैटर्न पर आधारित है, इसलिए हमारे पास ApplicationContext इंटरफ़ेस है जो स्वयं ComponentFactory इंटरफ़ेस और इस इंटरफ़ेस की मुख्य विधि getComponent विधि है जो घटक के नाम से ऑब्जेक्ट को वापस कर देगी।
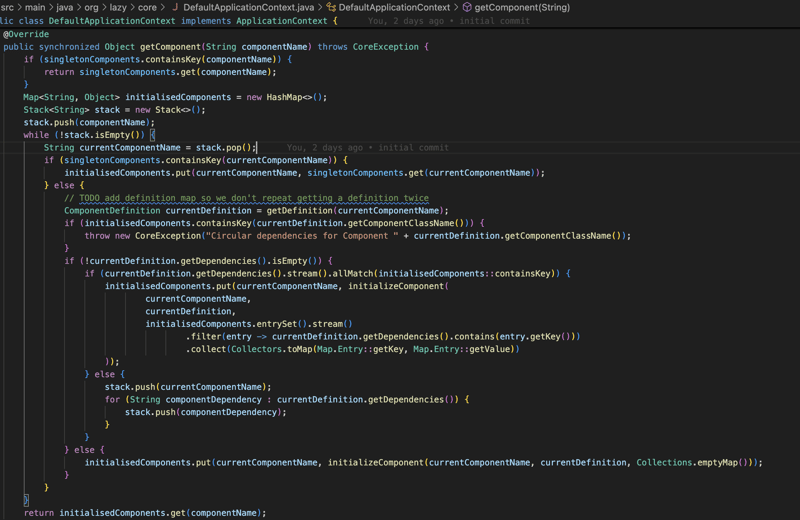
जैसा कि आप पहले ऊपर स्क्रीनशॉट में देख सकते हैं, हम यह जांचने का प्रयास करते हैं कि क्या घटक पहले से आरंभ किए गए सिंगलटन घटकों में मौजूद है, यदि ऐसा नहीं है तो हम JSON फ़ाइल से घटक परिभाषा प्राप्त करके शुरू करते हैं, फिर हम while लूप शुरू करते हैं एक पूर्ण ऑब्जेक्ट को इंजेक्ट करने के लिए तैयार करने के लिए घटक परिभाषा और उसकी निर्भरता को घटक असेंबलर को पास करने से पहले घटक की सभी निर्भरताएँ प्राप्त करें।
जेपीए मॉड्यूल
जेपीए मॉड्यूल का कार्यान्वयन स्प्रिंग डेटा जेपीए के समान है लेकिन बहुत कम है, इसका कारण यह बहुत समान है क्योंकि मैंने कई परियोजनाओं में स्प्रिंग डेटा का उपयोग किया है और मुझे इसका उपयोग करना आसान लगा और जैसा कि मैंने पहले कहा था कि मैं इसमें संक्रमण चाहता था लाइब्रेरी सुचारू होनी चाहिए और जितना संभव हो सके कम काम की आवश्यकता होती है, इसलिए मेरा अपना मिनी स्प्रिंग डेटा संस्करण लागू करना सबसे अच्छा विकल्प था।
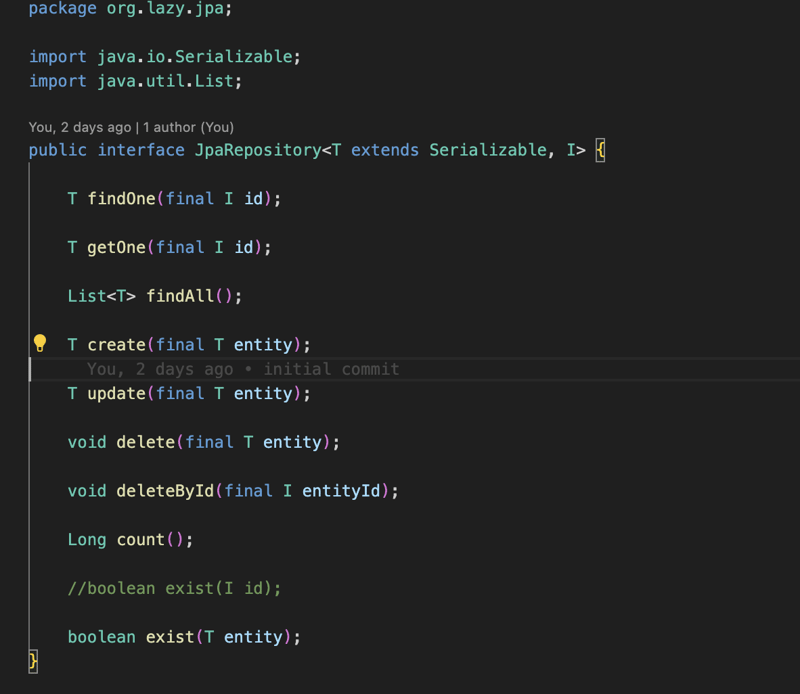
कार्यान्वयन JpaRepository इंटरफ़ेस के आसपास है जिसमें डेटाबेस के लिए सेव, डिलीट और फाइंडऑल जैसे सबसे सामान्य ऑपरेशन शामिल हैं... और JPA मॉड्यूल का उपयोग करने के लिए आपको इस इंटरफ़ेस को विस्तारित करने और इकाई प्रदान करने की आवश्यकता है जिसे इस इंटरफ़ेस को प्रबंधित करना चाहिए और यह आईडी है, फिर इंटरफ़ेस का विस्तार करने और रिपॉजिटरी एनोटेशन के साथ एनोटेट करने के बाद आप अपने तरीकों को परिभाषित कर सकते हैं और उन्हें क्वेरी एनोटेशन के साथ एनोटेट कर सकते हैं और जेपीक्यूएल क्वेरी प्रदान कर सकते हैं, और फिर संकलन चरण में लाइब्रेरी एक पूरी तरह कार्यात्मक क्लास बनाएगी जो इस इंटरफ़ेस को लागू करेगी।
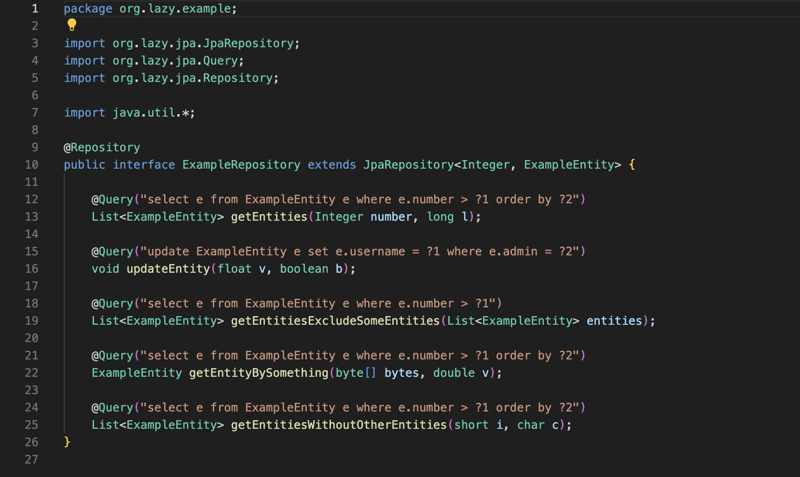
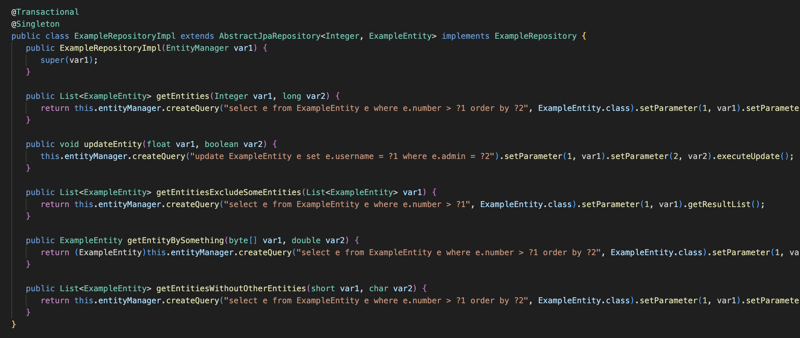
लाइब्रेरी एप्लिकेशन के लेन-देन वाले हिस्से को भी प्रबंधित करेगी, इसलिए सभी रिपॉजिटरी इंटरफ़ेस और लेन-देन के साथ एनोटेटेड किसी भी वर्ग को लेन-देन के दृष्टिकोण से लाइब्रेरी द्वारा प्रबंधित किया जाएगा। इसलिए किसी भी लेन-देन संबंधी घटक के लिए लाइब्रेरी Transactional एनोटेशन के आधार पर लेनदेन को प्रबंधित करने के लिए प्रॉक्सी बनाएगी और इकाई प्रबंधक जीवन-चक्र का प्रबंधन भी करेगी।
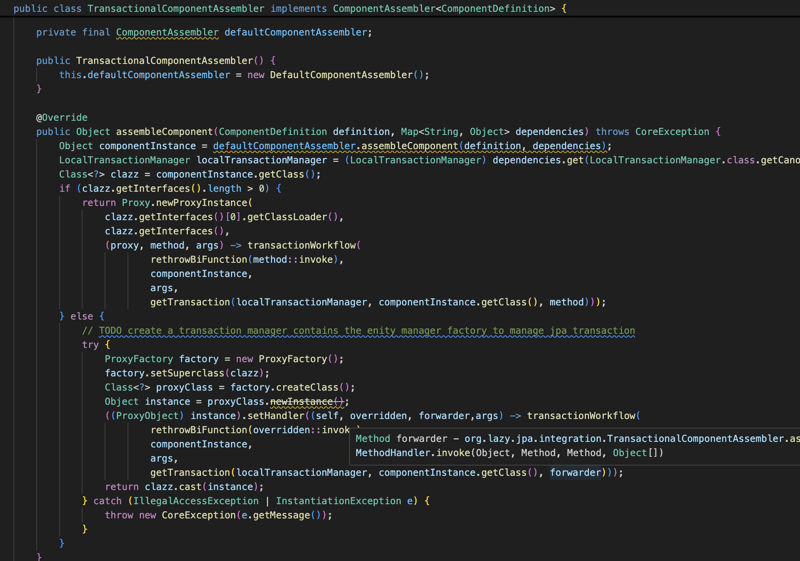
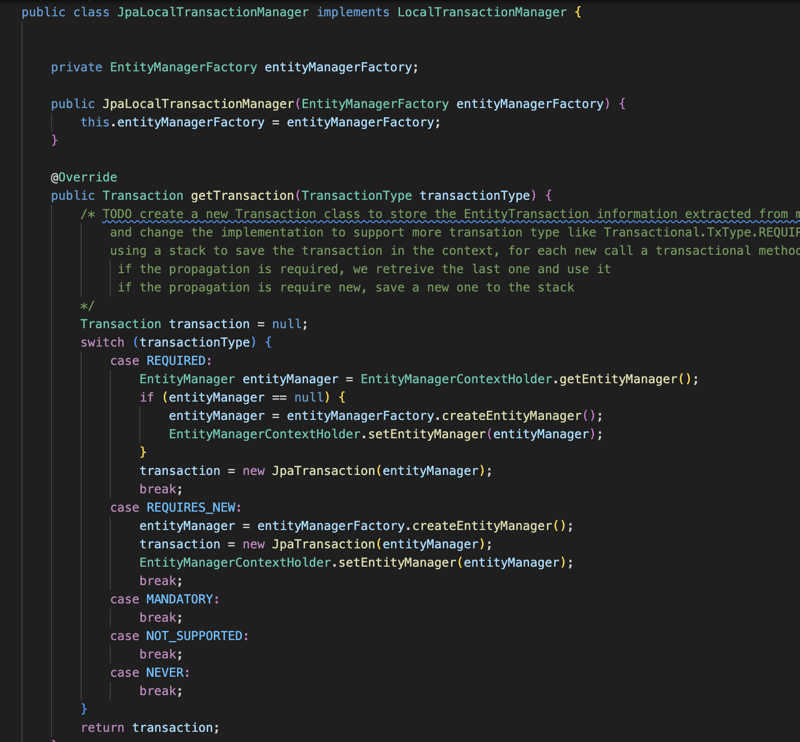
वेब मॉड्यूल
वेब मॉडल एप्लिकेशन के सभी वेब भाग को प्रबंधित करने के लिए ज़िम्मेदार है और डिज़ाइन के अनुसार यह एक स्वतंत्र मॉड्यूल है जिसका अर्थ है कि इसे लाइब्रेरी में बाकी मॉड्यूल से स्वतंत्र रूप से उपयोग किया जा सकता है, हमेशा की तरह यह कुछ के उपयोग के समान है स्प्रिंग वेब या जैक्स-आरएस जैसी परिचित जावा ईई लाइब्रेरी।
कार्यान्वयन एनोटेशन पर आधारित है, आपके पास Controller एनोटेशन के साथ एनोटेटेड कक्षाएं हैं और इस नियंत्रक के अंदर आपको PathMapping के साथ एनोटेटेड विधि मिलेगी और ये विधियां विशिष्ट पथ या विशिष्ट को संभालेंगी अनुरोध का प्रकार, सामग्री प्रकार जैसे कुछ मानदंडों के आधार पर अनुरोध...
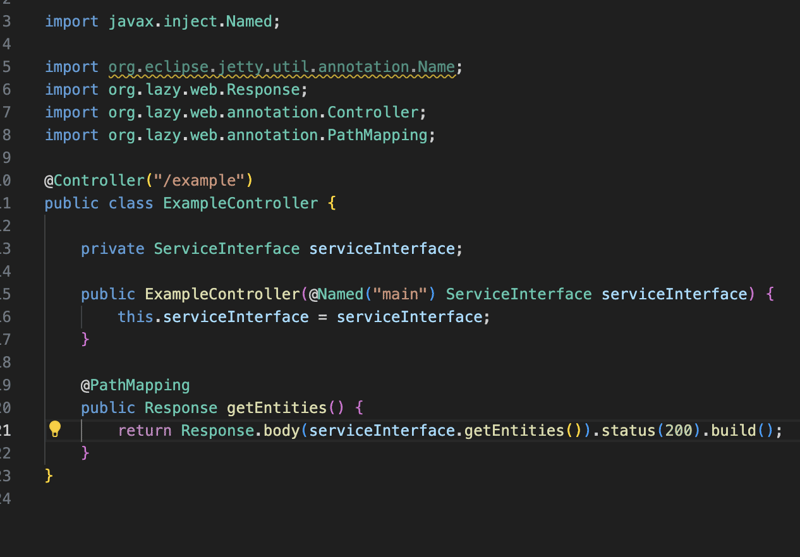
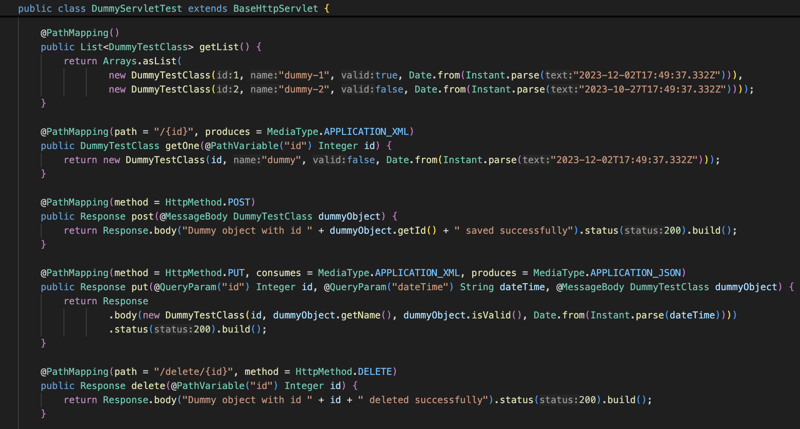
बाहर से यह अन्य लाइब्रेरी के समान ही दिखाई देगा लेकिन अंदर से यह अलग है क्योंकि लाइब्रेरी इन नियंत्रक कक्षाओं को रन टाइम में बदल देगी ताकि ये सभी BaseHttpServlet का विस्तार कर सकें , जो HttpServlet का भी विस्तार करता है और वे एक नियमित सर्वलेट के रूप में काम करेंगे।
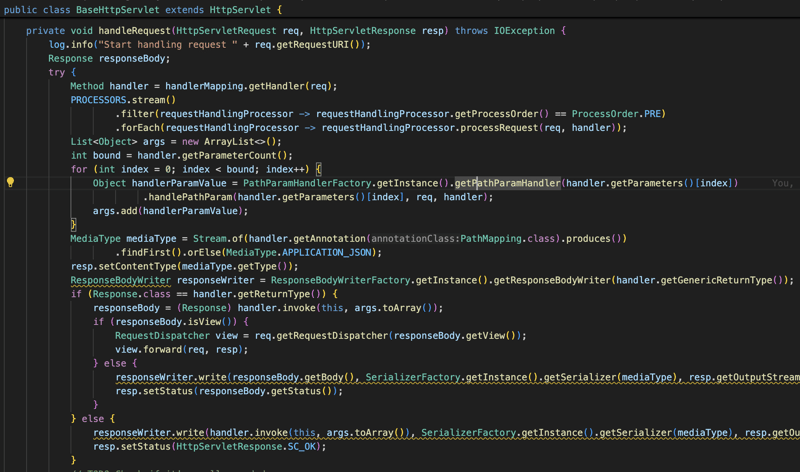
जैसा कि आप ऊपर स्क्रीनशॉट में देख सकते हैं, पहले हम WebApplicationContext का उपयोग करके सभी निर्भरता को इंजेक्ट करने के लिए init विधि में घटक को प्रारंभ करते हैं, और फिर हम सभी अनुरोधों को संभाल लेंगे। handleRequest विधि का उपयोग करके इस नियंत्रक पर आ रहा है, इस दृष्टिकोण के साथ हम नियंत्रकों को प्रबंधित करने के लिए मौजूदा सर्वलेट एपीआई का उपयोग करेंगे, इससे मेमोरी फ़ुटप्रिंट को कम रखने में मदद मिलेगी और ओवरहेड भी कम होगा क्योंकि लाइब्रेरी एक प्लगइन के रूप में कार्य करती है सर्वलेट एपीआई कार्य को पूरक करने के लिए।
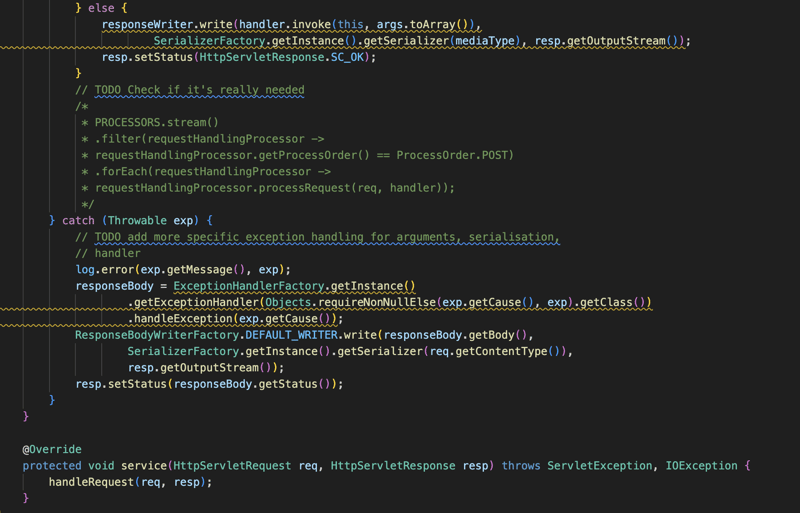
सबसे पहले, हम अनुरोध को सही विधि में मैप करने का प्रयास करते हैं और उसके बाद, हम अनुरोध की तरह संदर्भ या HttpServletRequest से जानकारी प्राप्त करके विधि के अंदर सभी अनुरोधित जानकारी को इंजेक्ट करने का प्रयास करते हैं। पैरामीटर या हेडर या पथ चर या अनुरोध का मुख्य भाग...
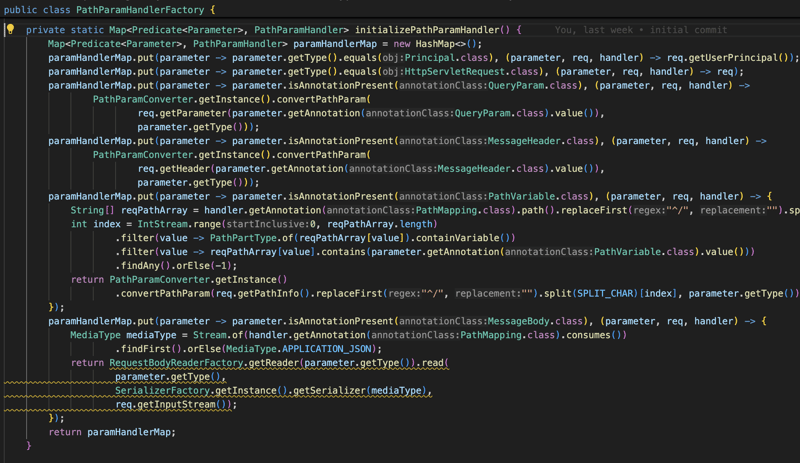
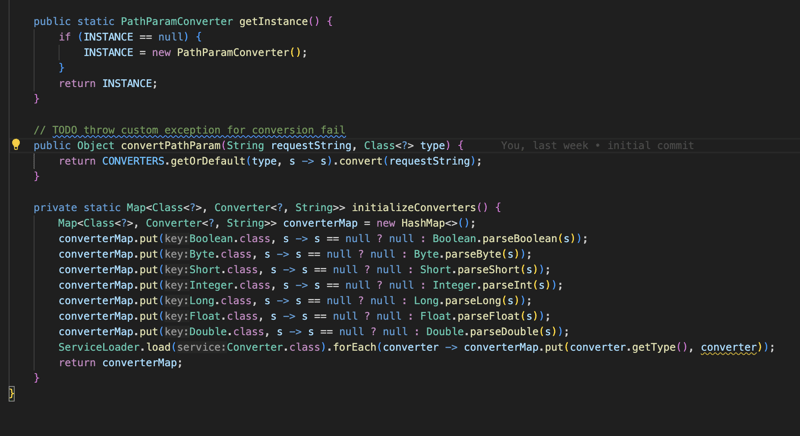
हम इन सभी सूचनाओं को परिवर्तित करते हैं और फिर अनुरोध किए जाने पर उन्हें विधि में एक पैरामीटर के रूप में इंजेक्ट करते हैं और फिर हम विधि को निष्पादित करते हैं और परिणाम या परिणाम को PathMapping उत्पादन या सामग्री प्रकार के आधार पर परिवर्तित करते हैं (द्वारा) डिफ़ॉल्ट यह एप्लिकेशन/Json है) और फिर हम सामग्री को HttpServletResponse पर लिखते हैं।
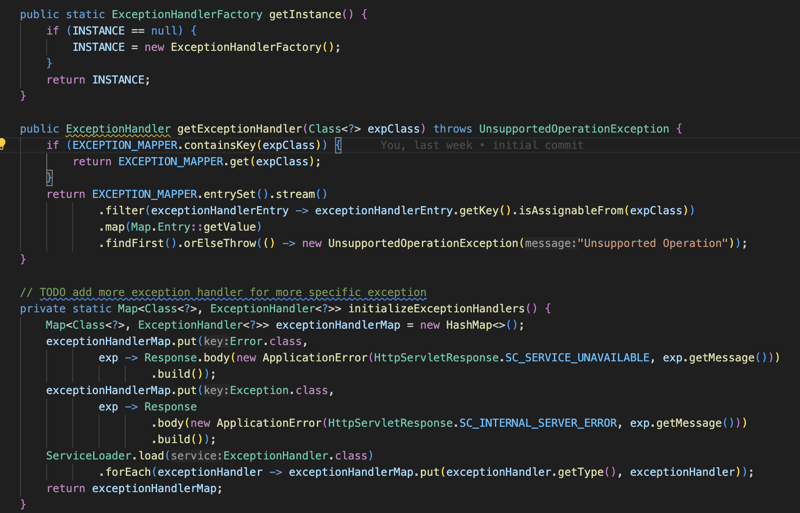
अंत में यदि प्रक्रिया में कुछ गलत हो जाता है और कोई त्रुटि उत्पन्न हो जाती है, तो हम इस त्रुटि या अपवाद को पकड़ लेते हैं और हम अपवाद के प्रकार के आधार पर इसे संभालने का प्रयास करते हैं, हमारे पास विभिन्न प्रकार के अपवादों को संभालने के लिए अपवाद हैंडलर होता है और उपयोगकर्ता अपनी इच्छानुसार किसी भी अपवाद को संभालने के लिए अधिक हैंडलर भी प्रदान कर सकता है।
मावेन प्लगइन
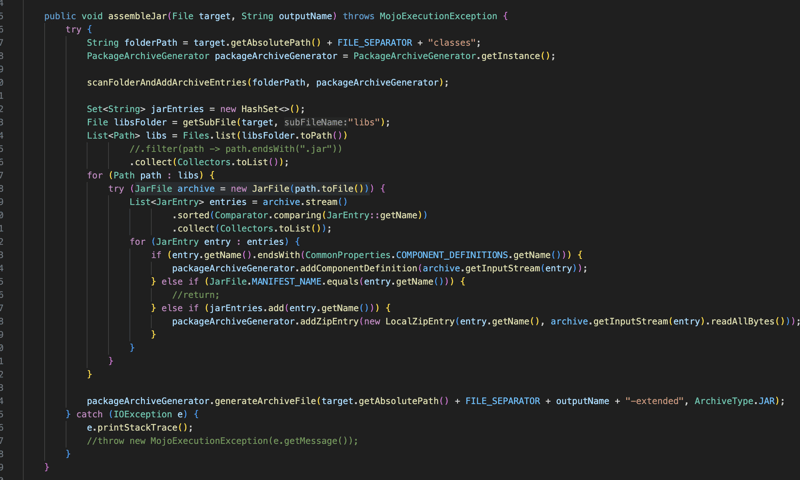
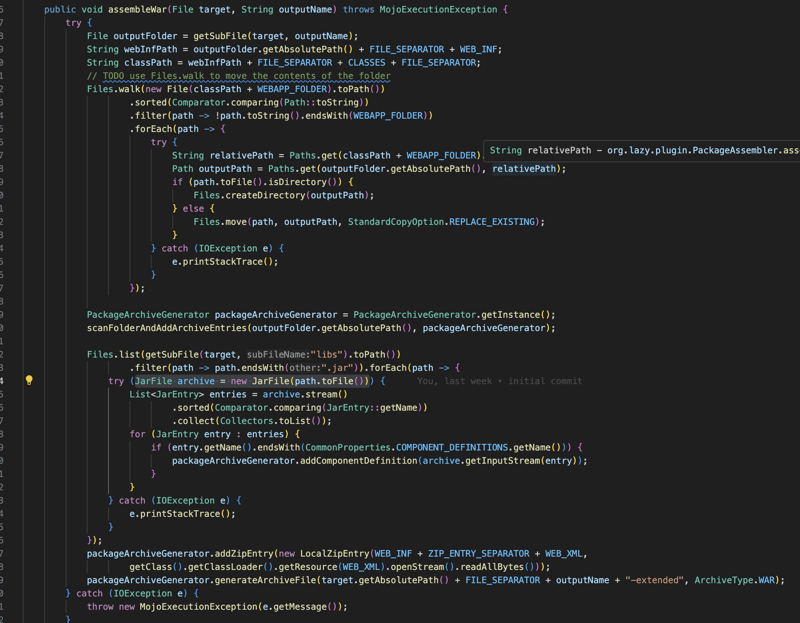
अंतिम और महत्वपूर्ण हिस्सा मेवेन प्लगइन है जो एप्लिकेशन को ठीक से काम करने और जार या वॉर पैकेज बनाने के लिए सभी आवश्यक फाइलें बनाएगा।
सबसे पहले प्लगइन component-definitions-json फ़ाइलों को खोजने के लिए क्लास पथ और निर्भरता को स्कैन करेगा, इस फ़ाइलों से यह उत्पन्न होगा:
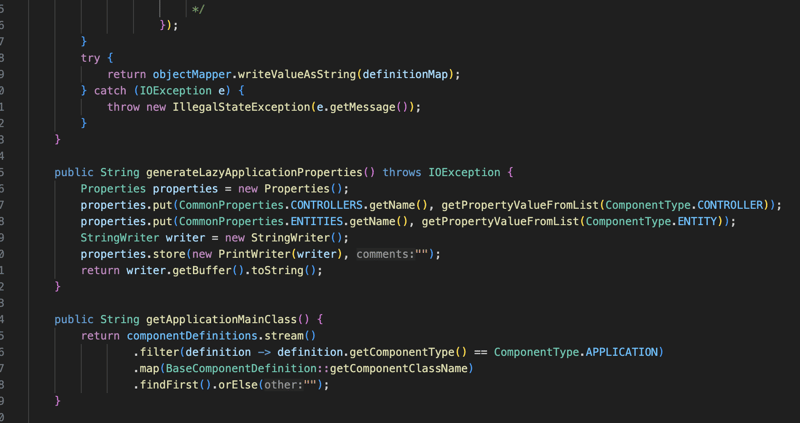
lazy-application.json: इसमें एप्लिकेशन के लिए सभी घटक और उनकी निर्भरताएं शामिल हैं
lazy-application.properties: इसमें नियंत्रकों और संस्थाओं की सूची शामिल है, इसलिए हमें रन टाइम पर क्लास पथ को स्कैन करने की आवश्यकता नहीं है।
और अंत में यदि पैकेजिंग जार है तो हमें मुख्य वर्ग मिलेगा।
और अंत में हम पैकेज आर्काइव फ़ाइल बनाते हैं जिसमें एप्लिकेशन कोड के साथ उसकी निर्भरताएँ और वे फ़ाइलें शामिल होंगी जो हमने पहले चरण में बनाई थीं।
मैंने लेखों को छोटा रखने और समझने में इतना जटिल नहीं रखने के लिए विवरणों में जाने की कोशिश नहीं की, बेशक कोड GitHub पर उपलब्ध है, इसलिए आप इसके साथ भी खेल सकते हैं। यदि आपके कोई प्रश्न हैं तो उन्हें नीचे छोड़ दें और मैं कोशिश करूंगा उन्हें उत्तर देने के लिए.
-
 फिक्स्ड पोजिशनिंग का उपयोग करते समय 100% ग्रिड-टेम्प्लेट-कॉलम के साथ ग्रिड शरीर से परे क्यों फैलता है?] फिक्स्ड; class = "स्निपेट-कोड"> । माता-पिता { स्थिति: फिक्स्ड; चौड़ाई: 100%; 6fr; lang-html atrayprint-override ">प्रोग्रामिंग 2025-04-26 को पोस्ट किया गया
फिक्स्ड पोजिशनिंग का उपयोग करते समय 100% ग्रिड-टेम्प्लेट-कॉलम के साथ ग्रिड शरीर से परे क्यों फैलता है?] फिक्स्ड; class = "स्निपेट-कोड"> । माता-पिता { स्थिति: फिक्स्ड; चौड़ाई: 100%; 6fr; lang-html atrayprint-override ">प्रोग्रामिंग 2025-04-26 को पोस्ट किया गया -
RPC विधि अन्वेषण के लिए GO इंटरफ़ेस का चिंतनशील गतिशील कार्यान्वयन] एक प्रश्न जो उठाया गया है, क्या यह एक नया फ़ंक्शन बनाने के लिए प्रतिबिंब का उपयोग करना संभव है जो एक विशिष्ट इंटरफ़ेस को लागू करता है। उदाहरण के लिए...प्रोग्रामिंग 2025-04-26 को पोस्ट किया गया
-
Python कुशल तरीका HTML टैग को पाठ से हटाने का] यह HTML टैग को प्रभावी ढंग से स्ट्रिपिंग करके प्राप्त किया जा सकता है, जो आपको वांछित सादे पाठ के साथ छोड़ देता है। MlStripper HTML इनपुट लेता है और...प्रोग्रामिंग 2025-04-26 को पोस्ट किया गया
-
मुझे अपनी सिल्वरलाइट LINQ क्वेरी में "क्वेरी पैटर्न का कार्यान्वयन" त्रुटि क्यों नहीं मिल रही है?] यह त्रुटि आम तौर पर तब होती है जब या तो Linq नेमस्पेस को छोड़ दिया जाता है या queried प्रकार में ienumerable कार्यान्वयन का अभाव होता है। इस विशिष्...प्रोग्रामिंग 2025-04-26 को पोस्ट किया गया
-
क्या C ++ 20 Consteval फ़ंक्शन में टेम्पलेट पैरामीटर फ़ंक्शन मापदंडों पर निर्भर कर सकते हैं?] संकलन-समय। हालाँकि, यह सवाल बना हुआ है: क्या इसका मतलब है कि टेम्पलेट पैरामीटर अब फ़ंक्शन तर्कों पर निर्भर कर सकते हैं? पेपर स्वीकार करता है कि मापद...प्रोग्रामिंग 2025-04-26 को पोस्ट किया गया
-
जावास्क्रिप्ट ऑब्जेक्ट्स में गतिशील रूप से चाबियां कैसे सेट करें?] सही दृष्टिकोण वर्ग कोष्ठक को नियोजित करता है: jsobj ['कुंजी' i] = 'उदाहरण' 1; जावास्क्रिप्ट में, सरणियाँ एक विशेष प्रकार का ऑ...प्रोग्रामिंग 2025-04-26 को पोस्ट किया गया
-
Android PHP सर्वर पर पोस्ट डेटा कैसे भेजता है?] सर्वर-साइड संचार से निपटने के दौरान यह एक सामान्य परिदृश्य है। Apache httpclient (defforated) httpclient httpclient = new defaulthttpclient (); ...प्रोग्रामिंग 2025-04-26 को पोस्ट किया गया
-
क्या मुझे कार्यक्रम से बाहर निकलने से पहले C ++ में स्पष्ट रूप से ढेर आवंटन को हटाने की आवश्यकता है?] यह लेख इस विषय में देरी करता है। C मुख्य फ़ंक्शन में, एक गतिशील रूप से आवंटित चर (हीप मेमोरी) के लिए एक सूचक का उपयोग किया जाता है। जैसा कि एप्लिक...प्रोग्रामिंग 2025-04-26 को पोस्ट किया गया
-
`कंसोल.लॉग` संशोधित ऑब्जेक्ट मान अपवाद का कारण दिखाता हैइस कोड स्निपेट का विश्लेषण करके इस रहस्य को उजागर करें: foo = [{id: 1}, {id: 2}, {id: 3}, {id: 4}, {id: 5},]; कंसोल.लॉग ('foo1', foo, ...प्रोग्रामिंग 2025-04-26 को पोस्ट किया गया
-
मैं PHP में यूनिकोड स्ट्रिंग्स से URL के अनुकूल स्लग कैसे कुशलता से उत्पन्न कर सकता हूं?] यह लेख स्लगों को कुशलता से उत्पन्न करने के लिए एक संक्षिप्त समाधान प्रस्तुत करता है, विशेष वर्णों और गैर-एएससीआईआई वर्णों को URL- अनुकूल स्वरूपों मे...प्रोग्रामिंग 2025-04-26 को पोस्ट किया गया
-
संस्करण 5.6.5 से पहले MySQL में टाइमस्टैम्प कॉलम के साथ current_timestamp का उपयोग करने पर क्या प्रतिबंध थे?] Current_timestamp क्लॉज। यह सीमा INT, BigInt, और SmallInt पूर्णांक को वापस बढ़ाती है जब उन्हें शुरू में 2008 में पेश किया गया था। यह सीमा विरासत क...प्रोग्रामिंग 2025-04-26 को पोस्ट किया गया
-
बहु-आयामी सरणियों के लिए PHP में JSON पार्सिंग को सरल कैसे करें?] To simplify the process, it's recommended to parse the JSON as an array rather than an object.To do this, use the json_decode function with the ...प्रोग्रामिंग 2025-04-26 को पोस्ट किया गया
-
मेरी रैखिक ढाल पृष्ठभूमि में धारियां क्यों हैं, और मैं उन्हें कैसे ठीक कर सकता हूं?] इन भद्दे कलाकृतियों को एक जटिल पृष्ठभूमि प्रसार घटना के लिए जिम्मेदार ठहराया जा सकता है। इसके बाद, रैखिक-ग्रेडिएंट इस पूरी ऊंचाई पर फैलता है, दोहराए...प्रोग्रामिंग 2025-04-26 को पोस्ट किया गया
-
MySQLI पर स्विच करने के बाद MySQL डेटाबेस से कनेक्ट करने के लिए CodeIgniter के कारण] यह त्रुटि गलत PHP कॉन्फ़िगरेशन से उत्पन्न हो सकती है। समस्या को डिबग करने के लिए, यह फ़ाइल के अंत में निम्न कोड जोड़ने के लिए अनुशंसित है ।/config...प्रोग्रामिंग 2025-04-26 को पोस्ट किया गया
-
पायथन मेटाक्लास कार्य सिद्धांत और वर्ग निर्माण और अनुकूलन] जिस तरह कक्षाएं उदाहरण बनाती हैं, मेटाक्लास कक्षाएं बनाते हैं। वे वर्ग निर्माण प्रक्रिया पर नियंत्रण की एक परत प्रदान करते हैं, जो वर्ग व्यवहार और व...प्रोग्रामिंग 2025-04-26 को पोस्ट किया गया















चीनी भाषा का अध्ययन करें
- 1 आप चीनी भाषा में "चलना" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 2 आप चीनी भाषा में "विमान ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 3 आप चीनी भाषा में "ट्रेन ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 4 आप चीनी भाषा में "बस ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 5 चीनी भाषा में ड्राइव को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 6 तैराकी को चीनी भाषा में क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 7 आप चीनी भाषा में साइकिल चलाने को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 8 आप चीनी भाषा में नमस्ते कैसे कहते हैं? 你好चीनी उच्चारण, 你好चीनी सीखना
- 9 आप चीनी भाषा में धन्यवाद कैसे कहते हैं? 谢谢चीनी उच्चारण, 谢谢चीनी सीखना
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









