 मुखपृष्ठ > प्रोग्रामिंग > जावास्क्रिप्ट में इस फ़ंक्शन का उपयोग करके एक स्ट्रिंग को कैमलकेस में कनवर्ट करें।
मुखपृष्ठ > प्रोग्रामिंग > जावास्क्रिप्ट में इस फ़ंक्शन का उपयोग करके एक स्ट्रिंग को कैमलकेस में कनवर्ट करें।
जावास्क्रिप्ट में इस फ़ंक्शन का उपयोग करके एक स्ट्रिंग को कैमलकेस में कनवर्ट करें।
 ब्राउज़ करें:483
ब्राउज़ करें:483
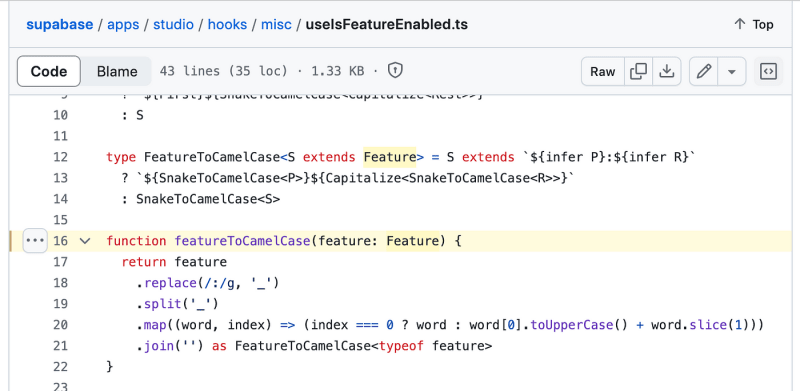
कभी किसी स्ट्रिंग को कैमलकेस में बदलने की आवश्यकता पड़ी? ओपन-सोर्स सुपाबेस रिपॉजिटरी की खोज के दौरान मुझे एक दिलचस्प कोड स्निपेट मिला। यहां वह विधि दी गई है जिसका वे उपयोग करते हैं:
function featureToCamelCase(feature: Feature) {
return feature
.replace(/:/g, '\_')
.split('\_')
.map((word, index) => (index === 0 ? word : word\[0\].toUpperCase() word.slice(1)))
.join('') as FeatureToCamelCase
}
यह फ़ंक्शन बहुत साफ-सुथरा है। यह कोलन को अंडरस्कोर से बदल देता है, स्ट्रिंग को शब्दों में विभाजित करता है, और फिर इसे कैमलकेस में बदलने के लिए प्रत्येक शब्द के माध्यम से मैप करता है। पहले शब्द को लोअरकेस में रखा जाता है, और बाद के शब्दों को एक साथ वापस जोड़ने से पहले उनके पहले अक्षर को बड़े अक्षरों में लिखा जाता है। सरल फिर भी प्रभावी!
मुझे स्टैक ओवरफ़्लो पर एक और दृष्टिकोण मिला जो नियमित अभिव्यक्तियों का उपयोग नहीं करता है। यहाँ विकल्प है:
function toCamelCase(str) {
return str.split(' ').map(function(word, index) {
// If it is the first word make sure to lowercase all the chars.
if (index == 0) {
return word.toLowerCase();
}
// If it is not the first word only upper case the first char and lowercase the rest.
return word.charAt(0).toUpperCase() word.slice(1).toLowerCase();
}).join('');
}
एसओ के इस कोड स्निपेट में टिप्पणियां हैं जो बताती हैं कि यह कोड क्या करता है, सिवाय इसके कि यह किसी भी प्रकार के रेगेक्स का उपयोग नहीं करता है। एक स्ट्रिंग को कैमलकेस में परिवर्तित करने के सुपाबेस के तरीके में पाया गया कोड इस SO उत्तर के समान है, टिप्पणियों और उपयोग किए गए रेगेक्स को छोड़कर।
.replace(/:/g, '\_')
यह विधि स्ट्रिंग को रिक्त स्थान से विभाजित करती है और फिर प्रत्येक शब्द पर मैप करती है। पहला शब्द पूरी तरह से लोअरकेस है, जबकि बाद के शब्दों को पहले अक्षर पर बड़े अक्षरों में लिखा गया है और बाकी के लिए लोअरकेस में रखा गया है। अंत में, कैमलकेस स्ट्रिंग बनाने के लिए शब्दों को वापस एक साथ जोड़ दिया जाता है।
स्टैक ओवरफ़्लो उपयोगकर्ता की एक दिलचस्प टिप्पणी में इस दृष्टिकोण के प्रदर्शन लाभ का उल्लेख किया गया है:
“ 1 रेगुलर एक्सप्रेशन का उपयोग न करने के लिए, भले ही प्रश्न में उनका उपयोग करके समाधान मांगा गया हो। यह एक अधिक स्पष्ट समाधान है, और प्रदर्शन के लिए एक स्पष्ट जीत भी है (क्योंकि जटिल नियमित अभिव्यक्तियों को संसाधित करना स्ट्रिंग के एक समूह पर पुनरावृत्ति करने और उनके बिट्स को एक साथ जोड़ने की तुलना में बहुत कठिन काम है)। देखें jsperf.com/camel-casing-regexp-or-character-manipulation/1 जहां मैंने इस उदाहरण के साथ यहां कुछ उदाहरण लिए हैं (और मेरा अपना मामूली उदाहरण भी प्रदर्शन के लिए इसमें सुधार किया गया है, हालांकि ज्यादातर मामलों में स्पष्टता के लिए मैं शायद इस संस्करण को प्राथमिकता दूंगा)।''
दोनों तरीकों की अपनी खूबियां हैं। सुपाबेस कोड में रेगेक्स दृष्टिकोण संक्षिप्त है और शक्तिशाली स्ट्रिंग हेरफेर तकनीकों का लाभ उठाता है। दूसरी ओर, गैर-रेगेक्स दृष्टिकोण की इसकी स्पष्टता और प्रदर्शन के लिए प्रशंसा की जाती है, क्योंकि यह नियमित अभिव्यक्तियों से जुड़े कम्प्यूटेशनल ओवरहेड से बचता है।
यहां बताया गया है कि आप उनके बीच कैसे चयन कर सकते हैं:
- रेगेक्स दृष्टिकोण का उपयोग करें यदि आपको एक कॉम्पैक्ट, वन-लाइनर समाधान की आवश्यकता है जो जावास्क्रिप्ट की शक्तिशाली रेगेक्स क्षमताओं का लाभ उठाता है। यह भी सुनिश्चित करें कि आपका रेगेक्स क्या करता है, यह बताने वाली टिप्पणियाँ जोड़ें, ताकि आपका भावी स्वयं या आपके कोड के साथ काम करने वाला अगला डेवलपर समझ सके।
- यदि आप पठनीयता और प्रदर्शन को प्राथमिकता देते हैं, तो गैर-रेगेक्स विधि का विकल्प चुनें, खासकर जब लंबी स्ट्रिंग से निपटते हैं या इस रूपांतरण को कई बार चलाते हैं।
मेरे बारे में:क्या आप सीखना चाहते हैं कि शुरुआत से shadcn-ui/ui कैसे बनाएं? जांचें बिल्ड-फ्रॉम-स्क्रैच
वेबसाइट: https://ramunarasinga.com/
लिंक्डइन: https://www.linkedin.com/in/ramu-narasinga-189361128/
जीथब: https://github.com/Ramu-Narasinga
ईमेल: [email protected]
स्क्रैच से shadcn-ui/ui बनाएं
सन्दर्भ:
- https://github.com/supabase/supabase/blob/master/apps/studio/hooks/misc/useIsFeatureEnabled.ts#L16
- https://stackoverflow.com/a/35976812
-
 क्या शुद्ध सीएसएस में एक दूसरे के ऊपर कई चिपचिपे तत्वों को स्टैक किया जा सकता है?] यहाँ देखा जा सकता है: https://webthemez.com/demo/sticky-multi-hroll/index.html केवल मैं शुद्ध cs का उपयोग करना पसंद करता हूं , एक जावास्क्रिप्ट...प्रोग्रामिंग 2025-02-07 को पोस्ट किया गया
क्या शुद्ध सीएसएस में एक दूसरे के ऊपर कई चिपचिपे तत्वों को स्टैक किया जा सकता है?] यहाँ देखा जा सकता है: https://webthemez.com/demo/sticky-multi-hroll/index.html केवल मैं शुद्ध cs का उपयोग करना पसंद करता हूं , एक जावास्क्रिप्ट...प्रोग्रामिंग 2025-02-07 को पोस्ट किया गया -
गतिशील रूप से आकार के मूल तत्व के भीतर एक तत्व की स्क्रॉलिंग रेंज को कैसे सीमित करें?] पहुंच। इस तरह के एक परिदृश्य में एक गतिशील रूप से आकार के मूल तत्व के भीतर एक तत्व की स्क्रॉलिंग रेंज को सीमित करना शामिल है। एक निश्चित साइडबार के ...प्रोग्रामिंग 2025-02-07 को पोस्ट किया गया
-
फ़ायरफ़ॉक्स बैक बटन का उपयोग करते समय जावास्क्रिप्ट निष्पादन क्यों बंद हो जाता है?] बैक बटन के माध्यम से पहले से देखे गए पृष्ठ पर लौटना। यह समस्या क्रोम और इंटरनेट एक्सप्लोरर जैसे अन्य ब्राउज़रों में नहीं होती है। इस समस्या को हल कर...प्रोग्रामिंग 2025-02-07 को पोस्ट किया गया
-
गुमनाम जावास्क्रिप्ट इवेंट हैंडलर को साफ -सुथरा कैसे निकालें?] स्वयं। / यहाँ काम करते हैं /}, गलत); जब तक हैंडलर का संदर्भ निर्माण में संग्रहीत नहीं किया गया था, तब तक एक अनाम घटना हैंडलर को साफ करने का कोई तरीक...प्रोग्रामिंग 2025-02-07 को पोस्ट किया गया
-
मुझे MySQL त्रुटि #1089 क्यों मिल रही है: गलत उपसर्ग कुंजी?] आइए इस त्रुटि और इसके रिज़ॉल्यूशन की बारीकियों में तल्लीन करें। एक तालिका में एक कॉलम पर उपसर्ग कुंजी। उपसर्ग कुंजियों को स्ट्रिंग कॉलम की एक विशिष्...प्रोग्रामिंग 2025-02-07 को पोस्ट किया गया
-
PHP का उपयोग करके MySQL में बूँदों (चित्र) को ठीक से कैसे डालें?मुद्दा। यह गाइड आपकी छवि डेटा को सफलतापूर्वक संग्रहीत करने के लिए समाधान प्रदान करेगा। ImageId, छवि) मान ('$ यह- & gt; image_id', '...प्रोग्रामिंग 2025-02-07 को पोस्ट किया गया
-
कैसे जांचें कि क्या किसी वस्तु की पायथन में एक विशिष्ट विशेषता है?] निम्नलिखित उदाहरण पर विचार करें जहां एक अपरिभाषित संपत्ति तक पहुंचने का प्रयास एक त्रुटि उठाता है: >>> a = someclass () >>> a.property ट्रेसबैक (स...प्रोग्रामिंग 2025-02-07 को पोस्ट किया गया
-
PostgreSQL में प्रत्येक अद्वितीय पहचानकर्ता के लिए अंतिम पंक्ति को कुशलता से कैसे पुनः प्राप्त करें?एक डेटासेट के भीतर प्रत्येक अलग पहचानकर्ता के साथ जुड़ी अंतिम पंक्ति। निम्नलिखित डेटा पर विचार करें: आईडी दिनांक एक और_info 1 2014-02-01 kjkj...प्रोग्रामिंग 2025-02-07 को पोस्ट किया गया
-
HTML स्वरूपण टैगHTML स्वरूपण तत्व ] HTML हमें CSS का उपयोग किए बिना पाठ को प्रारूपित करने की क्षमता प्रदान करता है। HTML में कई स्वरूपण टैग हैं। इन टैगों ...प्रोग्रामिंग 2025-02-07 को पोस्ट किया गया
-
क्या मैं सीएसएस में छद्म-तत्व सामग्री के रूप में एसवीजी का उपयोग कर सकता हूं?] छद्म-तत्व जैसे :: पहले और :: के बाद। हालाँकि, इस पर प्रतिबंध लगा दिया गया है कि किस सामग्री को शामिल किया जा सकता है। छद्म-तत्वों के लिए सामग्री क...प्रोग्रामिंग 2025-02-07 को पोस्ट किया गया
-
Sqlalchemy फ़िल्टर क्लॉज़ में `Flake8` फ्लैगिंग बूलियन तुलना क्यों है?] "==" के उपयोग के बारे में Flake8। हालांकि यह आम तौर पर "यदि कंडे गलत है:" या "अगर कंडे नहीं:" का उपयोग करने की सिफारिश...प्रोग्रामिंग 2025-02-07 को पोस्ट किया गया
-
क्या जावा कई प्रकार के रिटर्न प्रकार की अनुमति देता है: जेनेरिक तरीकों पर एक करीब से नज़र डालें?] : सार्वजनिक सूची getResult (string s); जहां फू एक कस्टम वर्ग है। विधि की घोषणा दो रिटर्न प्रकारों को समेटे हुए है: सूची और ई। लेकिन क्या ...प्रोग्रामिंग 2025-02-07 को पोस्ट किया गया
-
मैं जावा सूची में तत्व घटनाओं को कुशलता से कैसे गिन सकता हूं?] । इसे पूरा करने के लिए, संग्रह ढांचा उपकरणों का एक व्यापक सूट प्रदान करता है। यह स्थिर विधि एक सूची और एक तत्व को तर्क के रूप में स्वीकार करती है, त...प्रोग्रामिंग 2025-02-07 को पोस्ट किया गया
-
मैं रनटाइम में एक वर्ग से विशेषता मानों को कैसे पुनः प्राप्त कर सकता हूं?रनटाइम खोज विशेषताएँ ] विशेष विधि का उपयोग करें एक सामान्य विधि को परिभाषित करें जो प्रकार के मापदंडों को स्वीकार करता है: ] विधि के अंदर: ...प्रोग्रामिंग 2025-02-07 को पोस्ट किया गया
-
मैं PHP का उपयोग करके XML फ़ाइलों से विशेषता मानों को कैसे प्राप्त कर सकता हूं?] एक XML फ़ाइल के साथ काम करते समय जिसमें प्रदान किए गए उदाहरण जैसे विशेषताएं होती हैं: Var> आपका उद्देश्य "varnum" विशेषता मान को पुन...प्रोग्रामिंग 2025-02-07 को पोस्ट किया गया















चीनी भाषा का अध्ययन करें
- 1 आप चीनी भाषा में "चलना" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 2 आप चीनी भाषा में "विमान ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 3 आप चीनी भाषा में "ट्रेन ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 4 आप चीनी भाषा में "बस ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 5 चीनी भाषा में ड्राइव को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 6 तैराकी को चीनी भाषा में क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 7 आप चीनी भाषा में साइकिल चलाने को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 8 आप चीनी भाषा में नमस्ते कैसे कहते हैं? 你好चीनी उच्चारण, 你好चीनी सीखना
- 9 आप चीनी भाषा में धन्यवाद कैसे कहते हैं? 谢谢चीनी उच्चारण, 谢谢चीनी सीखना
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









