
मैजिक मशरूम: मैज के साथ अशक्त डेटा की खोज और उपचार
 ब्राउज़ करें:916
ब्राउज़ करें:916
मेज ईटीएल कार्यों के लिए एक शक्तिशाली उपकरण है, जिसमें ऐसी विशेषताएं हैं जो डेटा अन्वेषण और खनन, ग्राफ टेम्पलेट्स के माध्यम से त्वरित विज़ुअलाइज़ेशन और कई अन्य सुविधाएं प्रदान करती हैं जो डेटा के साथ आपके काम को कुछ जादुई में बदल देती हैं।
डेटा प्रोसेसिंग में, ईटीएल प्रक्रिया के दौरान गायब डेटा ढूंढना आम बात है जो भविष्य में समस्याएं पैदा कर सकता है, डेटासेट के साथ हम जो गतिविधि करने जा रहे हैं उसके आधार पर, शून्य डेटा काफी विघटनकारी हो सकता है।
हमारे डेटासेट में डेटा की अनुपस्थिति की पहचान करने के लिए, हम शून्य मान प्रस्तुत करने वाले डेटा की जांच करने के लिए पायथन और पांडा लाइब्रेरी का उपयोग कर सकते हैं, इसके अलावा हम ग्राफ़ बना सकते हैं जो इन शून्य मानों के प्रभाव को और भी स्पष्ट रूप से दिखाते हैं हमारा डेटासेट।
हमारी पाइपलाइन में 4 चरण हैं: डेटा लोड करना शुरू करना, दो प्रसंस्करण चरण और डेटा निर्यात करना।
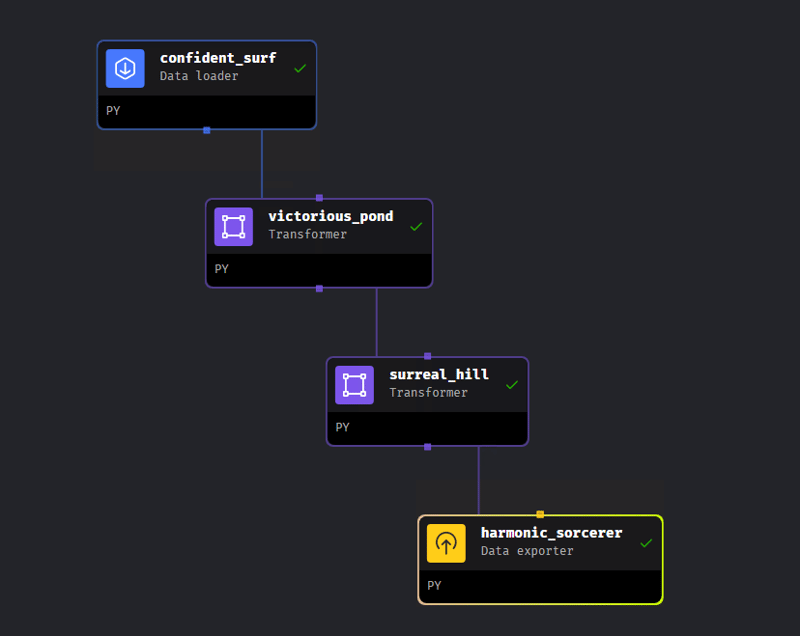
डेटा लोडर
इस लेख में हम डेटासेट का उपयोग करेंगे: ज़हरीले मशरूम की बाइनरी भविष्यवाणी जो एक प्रतियोगिता के भाग के रूप में कागल पर उपलब्ध है। आइए वेबसाइट पर उपलब्ध प्रशिक्षण डेटासेट का उपयोग करें।
आइए हम जिस डेटा का उपयोग करने जा रहे हैं उसे लोड करने में सक्षम होने के लिए पायथन का उपयोग करके एक डेटा लोडर चरण बनाएं। इस चरण से पहले, मैंने डेटा लोड करने में सक्षम होने के लिए पोस्टग्रेज डेटाबेस में एक तालिका बनाई, जो मेरी मशीन पर स्थानीय रूप से है। चूँकि डेटा पोस्टग्रेज़ में है, हम Mage के भीतर पहले से परिभाषित पोस्टग्रेज़ लोड टेम्पलेट का उपयोग करेंगे।
from mage_ai.settings.repo import get_repo_path from mage_ai.io.config import ConfigFileLoader from mage_ai.io.postgres import Postgres from os import path if 'data_loader' not in globals(): from mage_ai.data_preparation.decorators import data_loader if 'test' not in globals(): from mage_ai.data_preparation.decorators import test @data_loader def load_data_from_postgres(*args, **kwargs): """ Template for loading data from a PostgreSQL database. Specify your configuration settings in 'io_config.yaml'. Docs: https://docs.mage.ai/design/data-loading#postgresql """ query = 'SELECT * FROM mushroom' # Specify your SQL query here config_path = path.join(get_repo_path(), 'io_config.yaml') config_profile = 'default' with Postgres.with_config(ConfigFileLoader(config_path, config_profile)) as loader: return loader.load(query) @test def test_output(output, *args) -> None: """ Template code for testing the output of the block. """ assert output is not None, 'The output is undefined'
फ़ंक्शन के भीतर load_data_from_postgres() हम उस क्वेरी को परिभाषित करेंगे जिसका उपयोग हम डेटाबेस में तालिका को लोड करने के लिए करेंगे। मेरे मामले में, मैंने बैंक जानकारी को फ़ाइल io_config.yaml में कॉन्फ़िगर किया है, जहां इसे डिफ़ॉल्ट कॉन्फ़िगरेशन के रूप में परिभाषित किया गया है, इसलिए हमें केवल डिफ़ॉल्ट नाम को वेरिएबल config_profile में पास करने की आवश्यकता है।
ब्लॉक निष्पादित करने के बाद, हम चार्ट जोड़ें सुविधा का उपयोग करेंगे, जो पहले से परिभाषित टेम्पलेट्स के माध्यम से हमारे डेटा के बारे में जानकारी प्रदान करेगा। बस प्ले बटन के बगल वाले आइकन पर क्लिक करें, जो छवि में पीली रेखा से चिह्नित है।

हम अपने डेटासेट को और अधिक एक्सप्लोर करने के लिए दो विकल्पों का चयन करेंगे, summay_overview और फीचर_प्रोफाइल विकल्प। सारांश_अवलोकन के माध्यम से, हम डेटासेट में कॉलम और पंक्तियों की संख्या के बारे में जानकारी प्राप्त करते हैं। हम प्रकार के अनुसार कॉलम की कुल संख्या भी देख सकते हैं, उदाहरण के लिए श्रेणीबद्ध, संख्यात्मक और बूलियन कॉलम की कुल संख्या। दूसरी ओर, फ़ीचर_प्रोफ़ाइल्स, डेटा के बारे में अधिक वर्णनात्मक जानकारी प्रस्तुत करता है, जैसे: प्रकार, न्यूनतम मूल्य, अधिकतम मूल्य, अन्य जानकारी के अलावा, हम लापता मूल्यों की भी कल्पना कर सकते हैं, जो हमारे उपचार का फोकस हैं।
अनुपलब्ध डेटा पर अधिक ध्यान केंद्रित करने में सक्षम होने के लिए, आइए टेम्पलेट का उपयोग करें: गायब मानों का%, प्रत्येक कॉलम में गायब डेटा के प्रतिशत के साथ एक बार ग्राफ।
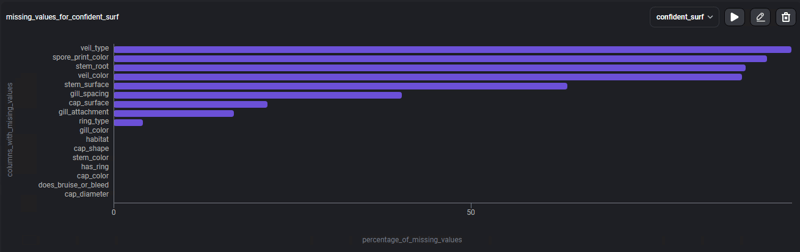
ग्राफ 4 कॉलम प्रस्तुत करता है जहां लापता मान इसकी सामग्री के 80% से अधिक के अनुरूप होते हैं, और अन्य कॉलम जो लापता मान प्रस्तुत करते हैं लेकिन कम मात्रा में, यह जानकारी अब हमें इससे निपटने के लिए विभिन्न रणनीतियों की तलाश करने की अनुमति देती है शून्य डेटा.
ट्रांसफार्मर ड्रॉप कॉलम
उन कॉलमों के लिए जिनमें 80% से अधिक शून्य मान हैं, हम जिस रणनीति का पालन करेंगे वह डेटाफ़्रेम में ड्रॉप कॉलम निष्पादित करना होगा, उन कॉलमों का चयन करना जिन्हें हम डेटाफ़्रेम से बाहर करने जा रहे हैं। पायथन भाषा में ट्रांसफॉर्मर ब्लॉक का उपयोग करके, हम विकल्प Colum निष्कासन का चयन करेंगे।
from mage_ai.data_cleaner.transformer_actions.base import BaseAction from mage_ai.data_cleaner.transformer_actions.constants import ActionType, Axis from mage_ai.data_cleaner.transformer_actions.utils import build_transformer_action from pandas import DataFrame if 'transformer' not in globals(): from mage_ai.data_preparation.decorators import transformer if 'test' not in globals(): from mage_ai.data_preparation.decorators import test @transformer def execute_transformer_action(df: DataFrame, *args, **kwargs) -> DataFrame: """ Execute Transformer Action: ActionType.REMOVE Docs: https://docs.mage.ai/guides/transformer-blocks#remove-columns """ action = build_transformer_action( df, action_type=ActionType.REMOVE, arguments=['veil_type', 'spore_print_color', 'stem_root', 'veil_color'], axis=Axis.COLUMN, ) return BaseAction(action).execute(df) @test def test_output(output, *args) -> None: """ Template code for testing the output of the block. """ assert output is not None, 'The output is undefined'
फ़ंक्शन के भीतर execute_transformer_action() हम उन कॉलमों के नाम के साथ एक सूची डालेंगे जिन्हें हम डेटासेट से बाहर करना चाहते हैं, तर्क चर में, इस चरण के बाद, बस ब्लॉक निष्पादित करें।
ट्रांसफार्मर में लुप्त मान भरें
अब उन कॉलमों के लिए जिनमें 80% से कम शून्य मान हैं, हम रणनीति का उपयोग करेंगे गुम मानों को भरें, जैसा कि कुछ मामलों में गायब डेटा होने के बावजूद, इन्हें मानों के साथ प्रतिस्थापित किया जाता है जैसे कि औसत, या फैशन, यह आपके अंतिम उद्देश्य के आधार पर, डेटासेट में कई बदलाव किए बिना डेटा आवश्यकताओं को पूरा करने में सक्षम हो सकता है।
कुछ कार्य हैं, जैसे कि वर्गीकरण, जहां डेटासेट के लिए प्रासंगिक (मोड, माध्य, माध्य) मान के साथ लापता डेटा को बदलना, वर्गीकरण एल्गोरिदम में योगदान कर सकता है, जो डेटा हटाए जाने पर अन्य निष्कर्षों तक पहुंच सकता है जैसा कि हमने दूसरी रणनीति में इस्तेमाल किया था।
हम किस माप का उपयोग करेंगे, इसके बारे में निर्णय लेने के लिए, हम Mage की चार्ट जोड़ें कार्यक्षमता का फिर से उपयोग करेंगे। टेम्पलेट सबसे अधिक बार आने वाले मान का उपयोग करके हम प्रत्येक कॉलम में इस मान के मोड और आवृत्ति की कल्पना कर सकते हैं।
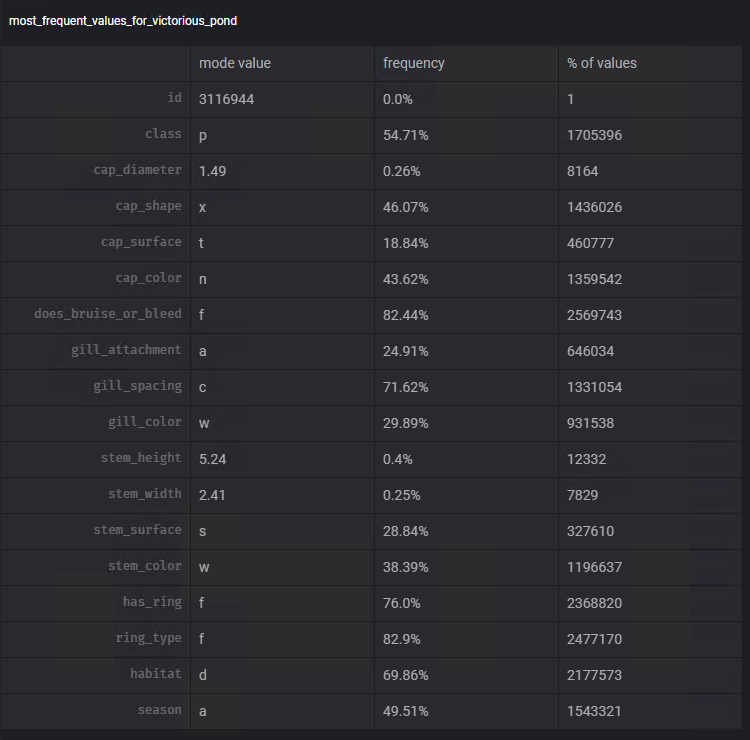
पिछले चरणों के समान चरणों का पालन करते हुए, हम प्रत्येक कॉलम के मोड का उपयोग करके लापता डेटा को घटाने का कार्य करने के लिए ट्रांसफार्मर लापता मान भरें का उपयोग करेंगे: स्टीम_सरफेस, गिल_स्पेसिंग, कैप_सरफेस , गिल_अटैचमेंट, रिंग_टाइप।
from mage_ai.data_cleaner.transformer_actions.constants import ImputationStrategy
from mage_ai.data_cleaner.transformer_actions.base import BaseAction
from mage_ai.data_cleaner.transformer_actions.constants import ActionType, Axis
from mage_ai.data_cleaner.transformer_actions.utils import build_transformer_action
from pandas import DataFrame
if 'transformer' not in globals():
from mage_ai.data_preparation.decorators import transformer
if 'test' not in globals():
from mage_ai.data_preparation.decorators import test
@transformer
def execute_transformer_action(df: DataFrame, *args, **kwargs) -> DataFrame:
"""
Execute Transformer Action: ActionType.IMPUTE
Docs: https://docs.mage.ai/guides/transformer-blocks#fill-in-missing-values
"""
action = build_transformer_action(
df,
action_type=ActionType.IMPUTE,
arguments=df.columns, # Specify columns to impute
axis=Axis.COLUMN,
options={'strategy': ImputationStrategy.MODE}, # Specify imputation strategy
)
return BaseAction(action).execute(df)
@test
def test_output(output, *args) -> None:
"""
Template code for testing the output of the block.
"""
assert output is not None, 'The output is undefined'
फ़ंक्शन में execute_transformer_action(), हम पायथन डिक्शनरी में डेटा को बदलने की रणनीति को परिभाषित करते हैं। अधिक प्रतिस्थापन विकल्पों के लिए, बस ट्रांसफार्मर दस्तावेज़ तक पहुंचें: https://docs.mage.ai/guides/transformer-blocks#fill-in-missing-values।
डेटा निर्यातक
सभी परिवर्तन करते समय, हम अपने अब संसाधित डेटासेट को उसी पोस्टग्रेज डेटाबेस में सहेजेंगे, लेकिन अब एक अलग नाम से ताकि हम अंतर कर सकें। डेटा एक्सपोर्टर ब्लॉक का उपयोग करके और पोस्टग्रेज़ का चयन करके, हम शेमा और तालिका को परिभाषित करेंगे जहां हम सहेजना चाहते हैं, यह याद रखते हुए कि डेटाबेस कॉन्फ़िगरेशन पहले फ़ाइल io_config.yaml में सहेजे गए हैं।
from mage_ai.settings.repo import get_repo_path from mage_ai.io.config import ConfigFileLoader from mage_ai.io.postgres import Postgres from pandas import DataFrame from os import path if 'data_exporter' not in globals(): from mage_ai.data_preparation.decorators import data_exporter @data_exporter def export_data_to_postgres(df: DataFrame, **kwargs) -> None: """ Template for exporting data to a PostgreSQL database. Specify your configuration settings in 'io_config.yaml'. Docs: https://docs.mage.ai/design/data-loading#postgresql """ schema_name = 'public' # Specify the name of the schema to export data to table_name = 'mushroom_clean' # Specify the name of the table to export data to config_path = path.join(get_repo_path(), 'io_config.yaml') config_profile = 'default' with Postgres.with_config(ConfigFileLoader(config_path, config_profile)) as loader: loader.export( df, schema_name, table_name, index=False, # Specifies whether to include index in exported table if_exists='replace', #Specify resolution policy if table name already exists )
धन्यवाद और अगली बार मिलेंगे?
रेपो -> https://github.com/DeadPunnk/Mushrooms/tree/main
-
 पायथन में स्ट्रिंग्स से इमोजी को कैसे निकालें: आम त्रुटियों को ठीक करने के लिए एक शुरुआत का मार्गदर्शिका?] पायथन 2 पर U '' उपसर्ग का उपयोग करके यूनिकोड स्ट्रिंग्स को नामित किया जाना चाहिए। इसके अलावा, re.unicode ध्वज को नियमित अभिव्यक्ति में पारित...प्रोग्रामिंग 2025-04-17 को पोस्ट किया गया
पायथन में स्ट्रिंग्स से इमोजी को कैसे निकालें: आम त्रुटियों को ठीक करने के लिए एक शुरुआत का मार्गदर्शिका?] पायथन 2 पर U '' उपसर्ग का उपयोग करके यूनिकोड स्ट्रिंग्स को नामित किया जाना चाहिए। इसके अलावा, re.unicode ध्वज को नियमित अभिव्यक्ति में पारित...प्रोग्रामिंग 2025-04-17 को पोस्ट किया गया -
जावा के पूर्ण-स्क्रीन अनन्य मोड में उपयोगकर्ता इनपुट को कैसे संभालें?java में पूर्ण स्क्रीन अनन्य मोड में उपयोगकर्ता इनपुट को संभालना, जब पूर्ण स्क्रीन अनन्य मोड में एक जावा एप्लिकेशन चलाना अपेक्षित नहीं हो ...प्रोग्रामिंग 2025-04-17 को पोस्ट किया गया
-
जावा में "dd/mm/yyyy hh: mm: ssss" प्रारूप में वर्तमान तिथि और समय को सही ढंग से कैसे प्रदर्शित करें?] अलग -अलग स्वरूपण पैटर्न के साथ अलग -अलग SimpleDateFormat इंस्टेंस का उपयोग। आयात java.util.calendar; आयात java.util.date; सार्वजनिक वर्ग DateAndt...प्रोग्रामिंग 2025-04-17 को पोस्ट किया गया
-
PHP का DateTime :: संशोधित ('+1 महीने') अप्रत्याशित परिणाम उत्पन्न करता है?] जैसा कि प्रलेखन में कहा गया है, इन कार्यों के "सावधान", क्योंकि वे उतने सहज नहीं हैं जितना वे प्रतीत हो सकते हैं। $ दिनांक-> संशोधित करें ...प्रोग्रामिंग 2025-04-17 को पोस्ट किया गया
-
क्यों HTML पेज नंबर और समाधान प्रिंट नहीं कर सकता] उपयोग: @पृष्ठ { मार्जिन: 10%; @टॉप-सेंटर { फ़ॉन्ट-फैमिली: सैंस-सेरिफ़; फ़ॉन्ट-वेट: बोल्ड; फ़ॉन्ट-आकार: 2EM; सामग्री: काउंटर (प...प्रोग्रामिंग 2025-04-17 को पोस्ट किया गया
-
फायरबेस ऐप में अपनी संबंधित गतिविधियों के लिए कई उपयोगकर्ता प्रकारों (छात्रों, शिक्षकों और प्रशंसा) को कैसे पुनर्निर्देशित करें?] लॉग इन करें। वर्तमान कोड सफलतापूर्वक दो उपयोगकर्ता प्रकारों के लिए पुनर्निर्देशन का प्रबंधन करता है, लेकिन तीसरे प्रकार (व्यवस्थापक) को शामिल करने क...प्रोग्रामिंग 2025-04-17 को पोस्ट किया गया
-
आप PHP में एक सरणी से एक यादृच्छिक तत्व कैसे निकालते हैं?] निम्नलिखित सरणी पर विचार करें: $ आइटम = [५२३, ३४५२, ३३४, ३१, ५३४६]; Array_rand () फ़ंक्शन सरणी से एक यादृच्छिक कुंजी देता है। इस कुंजी के साथ $ आइ...प्रोग्रामिंग 2025-04-17 को पोस्ट किया गया
-
मैं पांडा डेटाफ्रेम में कुशलता से कॉलम का चयन कैसे करूं?] पंडों में, कॉलम का चयन करने के लिए विभिन्न विकल्प हैं। संख्यात्मक सूचकांक यदि कॉलम सूचकांक ज्ञात हैं, तो उन्हें चुनने के लिए ILOC फ़ंक्शन का ...प्रोग्रामिंग 2025-04-17 को पोस्ट किया गया
-
सी ++ डेटा संरचना और एल्गोरिथ्म व्यावहारिक मार्गदर्शिका在C 中实现数据结构和算法可以分为以下步骤:1. 回顾基础知识,理解数据结构和算法的基本概念。2. 实现基本数据结构,如数组和链表。3. 实现复杂数据结构,如二叉搜索树。4. 编写常见算法,如快速排序和二分查找。5. 应用调试技巧,避免常见错误。6. 进行性能优化,选择合适的数据结构和算法。通过这...प्रोग्रामिंग 2025-04-17 को पोस्ट किया गया
-
अपने कंटेनर के भीतर एक DIV के लिए एक चिकनी बाएं-दाएं CSS एनीमेशन कैसे बनाएं?] इस एनीमेशन को किसी भी डिव को पूर्ण स्थिति के साथ लागू किया जा सकता है, चाहे इसकी अज्ञात लंबाई की परवाह किए बिना। ऐसा इसलिए है क्योंकि 100%पर, DIV की...प्रोग्रामिंग 2025-04-17 को पोस्ट किया गया
-
जावा का मानचित्र कैसे है। एंट्री और सिंपलेंट्री कुंजी-मूल्य जोड़ी प्रबंधन को सरल बनाते हैं?] हालांकि, परिदृश्यों के लिए जहां तत्वों के क्रम को बनाए रखना महत्वपूर्ण है और विशिष्टता एक चिंता का विषय नहीं है, वहाँ एक मूल्यवान विकल्प है: जावा का...प्रोग्रामिंग 2025-04-17 को पोस्ट किया गया
-
HTML स्वरूपण टैगHTML स्वरूपण तत्व ] HTML हमें CSS का उपयोग किए बिना पाठ को प्रारूपित करने की क्षमता प्रदान करता है। HTML में कई स्वरूपण टैग हैं। इन टैगों ...प्रोग्रामिंग 2025-04-17 को पोस्ट किया गया
-
Python कुशल तरीका HTML टैग को पाठ से हटाने का] यह HTML टैग को प्रभावी ढंग से स्ट्रिपिंग करके प्राप्त किया जा सकता है, जो आपको वांछित सादे पाठ के साथ छोड़ देता है। MlStripper HTML इनपुट लेता है और...प्रोग्रामिंग 2025-04-17 को पोस्ट किया गया
-
Ubuntu/linux पर mysql-python स्थापित करते समय \ "mysql_config को कैसे नहीं मिला \" त्रुटि नहीं मिली?] यह त्रुटि एक लापता MySQL विकास पुस्तकालय के कारण उत्पन्न होती है। निम्नलिखित कमांड का उपयोग करके पायथन-mysqldb स्थापित करें: sudo apt-get python-...प्रोग्रामिंग 2025-04-17 को पोस्ट किया गया
-
C#में इंडेंटेशन के लिए स्ट्रिंग वर्णों को कुशलता से कैसे दोहराएं?] कंस्ट्रक्टर यदि आप केवल एक ही वर्ण को दोहराने का इरादा रखते हैं, स्ट्रिंग ('-', 5); यह स्ट्रिंग को वापस कर देगा "-----"। स्ट्...प्रोग्रामिंग 2025-04-17 को पोस्ट किया गया















चीनी भाषा का अध्ययन करें
- 1 आप चीनी भाषा में "चलना" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 2 आप चीनी भाषा में "विमान ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 3 आप चीनी भाषा में "ट्रेन ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 4 आप चीनी भाषा में "बस ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 5 चीनी भाषा में ड्राइव को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 6 तैराकी को चीनी भाषा में क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 7 आप चीनी भाषा में साइकिल चलाने को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 8 आप चीनी भाषा में नमस्ते कैसे कहते हैं? 你好चीनी उच्चारण, 你好चीनी सीखना
- 9 आप चीनी भाषा में धन्यवाद कैसे कहते हैं? 谢谢चीनी उच्चारण, 谢谢चीनी सीखना
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









