
एक क्लिक से निर्भरता ठीक हो जाती है
 ब्राउज़ करें:408
ब्राउज़ करें:408
Photo by Maxim Hopman on Unsplash
If you maintain a JVM1 or Android project, chances are you've heard of the Dependency Analysis Gradle Plugin (DAGP). With over 1800 stars, it's used by some of largest Gradle projects in the world, as well as by Gradle itself. It fills what would otherwise be a substantial hole in the Gradle ecosystem: without it, I know of no other way to eliminate unused dependencies and to correctly declare all your actually-used dependencies. In other words, when you use this plugin, your dependency declarations are exactly what you need to build your project: nothing more, nothing less.
That might sound like a small thing, but for industrial-scale projects, a healthy dependency graph is a superpower that prevents bugs, eases debugging (at build and runtime), keeps builds faster, and keeps artifacts smaller. If developer productivity work is the public health of the software engineering world, then a healthy dependency graph is a working sewer system. You don't know how much you rely on it till it stops working and you've got shit everywhere.
The problem is that, if your tool only tells you all the problems you have but doesn't also fix them, you might have a massive(ly annoying) problem on your hands. I mentioned this as an important consideration in my recent rant against code style formatters. This is why, since v1.11.0, DAGP has had a fixDependencies task, which takes the problem report and rewrites build scripts in-place. Even before that, in v0.46.0, the plugin had first-class support for registering a "post-processing task" to enable advanced users to consume the "build health" report in any manner of their choosing. Foundry (née The Slack Gradle Plugin), for example, has a feature called the "dependency rake", which predates and inspired fixDependencies.
fixDependencies hasn't always worked well, though. For one thing, there might be a bug in the analysis such that, if you "fix" all the issues, your build might break. (DAGP is under very active development, so if this ever happens to you, please file an issue!) In this case, it can take an expert to understand what broke and how to fix it, or you can fall back to manual changes and iteration.
For another thing, the build script rewriter has relied on a simplified grammar for parsing and rewriting Gradle Groovy and Kotlin DSL build scripts. That grammar can fail if your scripts are complex.2 This problem will soon be solved with the introduction of a Gradle Kotlin DSL parser built on the KotlinEditor grammar, which has full support for the Kotlin language. (Gradle Groovy DSL scripts will continue to use the old simplified grammar, for now.)
There have also been many recent bugfixes to (1) improve the correctness of the analysis and (2) make the rewriting process more robust in the face of various common idioms. DAGP now has much better support for version catalog accessors, for example (no support yet for experimental project accessors).
With these improvements (real and planned), it's become feasible to imagine automating large-scale dependency fixes across hundreds of repos containing millions of lines of code and have it all just work. Here's the situation:
- Over 500 repositories.
- Each with its own version catalog.
- Most of the entries in the version catalogs use the same names, but there's some incidental skew in the namespace (multiple keys pointing to the same dependency coordinates).
- Over 2000 Gradle modules.
- Close to 15 million lines of Kotlin and Java code spread out over more than 100 thousand files, along with over 150 thousand lines of "Gradle" code in more than 3 thousand build scripts. This last point isn't as relevant as the first four, but helps to demonstrate what I mean when I say "industrial scale."3
Additionally, the build code we want to write to manage all this should follow Gradle best practices: it should be cacheable to the extent possible, should work with the configuration cache, and for bonus points should not violate the isolated projects contract either (which is also good for maximal performance). The ultimate goal is for developers and build maintainers to be able to run a single task and have it (1) fix all dependency declarations, which might mean adding new declarations to build scripts; (2) all build script declarations should have a version catalog entry wherever possible; (3) and all version catalog entries should come from the same global namespace so that the entire set of 500 repositories are fully consistent with each other. This last part is an important requirement because we're migrating these repos into a single mono/mega repo for other reasons.
Here's the task they can now run, for the record:
gradle :fixAllDependencies
(nb: we use gradle and not ./gradlew because we manage gradle per-repo with hermit.)
So, how do we do it?
Pre-processing
The first step was creating the global version catalog namespace. We did not attempt to actually create a single published global version catalog because, until we finish our megarepo migration, an important contract is that each repo maintains its own dependencies (and their versions). So instead, we collected the full map of version catalog names to dependency identifiers (the dependency coordinates less the version string). We eliminated all the duplication using pre-existing large-scale change tools we have, and then populated the final global set (now with 1:1 mappings) into our convention plugin that is already applied everywhere.
Conceptual framework
The Gradle framework, in general, takes the Project as the most important point of reference.4 A Project instance is what backs all your build.gradle[.kts] scripts, for example, and most plugins implement the Plugin
If Tasks have well-defined inputs and outputs (literally annotated @Input
With that in mind, we can decide that if two projects need to talk to each other, they should do so via their well-defined inputs and outputs. We define relationships between projects via dependencies (A -> B means A depends on B, so B is an input to A), and we can flavor that connection such that we tell Gradle which of B's outputs A cares about. The default is the primary artifact (usually class files for classpath purposes), but it can also be anything (that can be written to disk). It can, for example, be some metadata about B. It can also be both! (You can declare multiple dependencies between the same two projects, with each edge having a different "flavor," that is, representing a different variant.) This may make more sense in a bit when we get to a concrete example.
Implementation: :fixAllDependencies
The rest of this post will focus on implementation, but at a relatively high level of detail. Some of the code will essentially be pseudocode. My goal is to demonstrate the full flow at a conceptual level, such that a (highly) motivated reader could implement something similar in their own workflow or, more likely, simply learn about how to do something Cool™️ with Gradle.
Here's a sketch of the simplified task graph with Excalidraw:
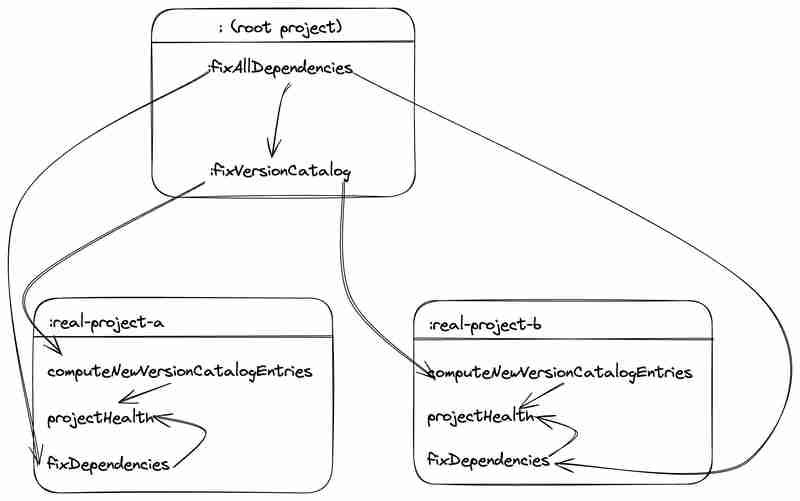
Note how each project is independent of the other. Well-defined Gradle builds maximize concurrency by respecting project boundaries.
Step 1: The global namespace
As mentioned in the pre-processing section, we need a global namespace. We want all dependency declarations to refer to version catalog entries, i.e., libs.amazingMagic, rather than "com.amazing:magic:1.0". Since DAGP already supports version catalog references in its analysis, this will Just Work if your version catalog already has an entry for amazingMagic = "com.amazing:magic:1.0". However, if you don't, DAGP defaults to the "raw string" declaration. If we want, we can tell DAGP about other mappings that it can't detect by default:
// root build script
dependencyAnalysis {
structure {
map.putAll(
"com.amazing:magic" to "libs.amazingMagic",
// more entries
)
}
}
where dependencyAnalysis.structure.map is a MapProperty
Step 2: Update the version catalog, part 1
With Step 1, DAGP will rewrite build scripts via the built-in fixDependencies task to match your desired schema, but your next build will fail because you'll have dependencies referencing things like libs.amazingMagic which aren't actually present in your version catalog. So now we have to update the version catalog to ensure it has all of these new entries. This will be a multi-step process.
First, we have to calculate the possibly-missing entries. We write a new task, ComputeNewVersionCatalogEntriesTask, and have it extend AbstractPostProcessingTask, which comes from DAGP itself. This exposes a function, projectAdvice(), which gives subclasses access to the "project advice" that DAGP emits to the console, but in a form amenable to computer processing. We'll take that output, filter it for "add advice", and then write those values out to disk via our task's output. We only care about the add advice because that's the only type that might represent a dependency not in a version catalog.
// in a custom task action
val newEntries = projectAdvice()
.dependencyAdvice
.filter { it.isAnyAdd() }
.filter { it.coordinates is ModuleCoordinates }
.map { it.coordinates.gav() }
.toSortedSet()
outputFile.writeText(newEntries.joinToString(separator = "\n")
Note that with Gradle task outputs, it's best practice to always sort outputs for stability and to enable use of the remote build cache.
Next we tell DAGP about this post-processing task (which is how it can access projectAdvice():
// subproject's build script
computeNewVersionCatalogEntries = tasks.register(...)
dependencyAnalysis {
registerPostProcessingTask(computeNewVersionCatalogEntries)
}
And finally we also have to register our new task's output as an artifact of this project!
val publisher = interProjectPublisher(
project,
MyArtifacts.Kind.VERSION_CATALOG_ENTRIES
)
publisher.publish(
computeNewVersionCatalogEntries.flatMap {
it.newVersionCatalogEntries
}
)
where the interProjectPublisher and related code is heavily inspired by DAGP's artifacts package, because I wrote both. The tl;dr is that this is what teaches Gradle about a project's secondary artifacts. I wish Gradle had a first-class API for this, alas.
Step 3: Update the version catalog, part 2
Back in the root project, we need to declare our dependencies to each subproject, flavoring that declaration to say we want the VERSION_CATALOG_ENTRIES artifact:
// root project
val resolver = interProjectResolver(
project,
MyArtifacts.Kind.VERSION_CATALOG_ENTRIES
)
// Yes, this CAN BE OK, but you must only access
// IMMUTABLE PROPERTIES of each project p.
// This sets up the dependencies from the root to
// each "real" subproject, where "real" filters
// out intermediate directories that don't have
// any code
allprojects.forEach { p ->
// implementation left to reader
if (isRealProject(p)) {
dependencies.add(
resolver.declarable.name,
// p.path is an immutable property, so we're
// good
dependencies.project(mapOf("path" to p.path))
)
}
}
val fixVersionCatalog = tasks.register(
"fixVersionCatalog",
UpdateVersionCatalogTask::class.java
) { t ->
t.newEntries.setFrom(resolver.internal)
t.globalNamespace.putAll(...)
t.versionCatalog.set(layout.projectDirectory.file("gradle/libs.versions.toml"))
}
The root project is the correct place to register this task, because the version catalog will typically live in the root at gradle/libs.versions.toml.
With this setup, a user could now run gradle :fixVersionCatalog, and it would essentially run
This updates the version catalog to contain every necessary reference to resolve all the potential libs.
Step 4: Fix all the dependency declarations
This step leverages DAGP's fixDependencies task, and is really just about wrapping everything up in a neat package.
We want a single task registered on the root. Let's call it :fixAllDependencies. This will be a lifecycle task, and invoking it will trigger :fixVersionCatalog as well as all the
// root project val fixDependencies = mutableListOf() allprojects.forEach { p -> if (isRealProject(p)) { // ...as before... // do not use something like `p.tasks.findByName()`, // that violates Isolated Projects as well as // lazy task configuration. fixDependencies.add("${p.path}:fixDependencies") } } tasks.register("fixAllDependencies") { t -> t.dependsOn(fixVersionCatalog) t.dependsOn(fixDependencies) }
And we're done.6
(Optional) Step 5: Sort dependency blocks
If you do all the preceding, you should have a successful build with a minimal dependency graph. ? But your dependency blocks will be horribly out-of-order, which can make them hard to visually scan. DAGP makes no effort to keep the declarations sorted because that is an orthogonal concern and different teams might have different ordering preferences. This is why I've also authored and published the Gradle Dependencies Sorter CLI and plugin, which applies what I consider to be a reasonable default. If you apply this to your builds (which we do to all of our builds via our convention plugins), you can follow-up :fixAllDependencies with
gradle sortDependencies
and this will usually Just Work. This plugin is in fact already using the enhanced Kotlin grammar from KotlinEditor, so Gradle Kotlin DSL build scripts shouldn't pose a problem for it.
And now we're really done.
Endnotes
1 Currently supported languages: Groovy, Java, Kotlin, and Scala. up
2 This is one reason why I think it's important to keep scripts simple and declarative. up
3 Measured with the cloc tool. up
4 Gradle's biggest footgun, in my opinion, is that the API doesn't enforce this conceptual boundary. up
5 This paragraph is an oversimplification for discussion purposes. up
6 Well, except for automated testing and blog-post writing. up
-
 `if` कथनों से परे: स्पष्ट `bool` रूपांतरण वाले प्रकार को कास्टिंग के बिना और कहाँ उपयोग किया जा सकता है?बूल में प्रासंगिक रूपांतरण बिना कास्ट के स्वीकृतआपकी कक्षा बूल में एक स्पष्ट रूपांतरण को परिभाषित करती है, जिससे आप सीधे सशर्त बयानों में इसके उदाहरण ...प्रोग्रामिंग 2024-12-26 को प्रकाशित
`if` कथनों से परे: स्पष्ट `bool` रूपांतरण वाले प्रकार को कास्टिंग के बिना और कहाँ उपयोग किया जा सकता है?बूल में प्रासंगिक रूपांतरण बिना कास्ट के स्वीकृतआपकी कक्षा बूल में एक स्पष्ट रूपांतरण को परिभाषित करती है, जिससे आप सीधे सशर्त बयानों में इसके उदाहरण ...प्रोग्रामिंग 2024-12-26 को प्रकाशित -
मैं अद्वितीय आईडी को संरक्षित करते हुए और डुप्लिकेट नामों को संभालते हुए PHP में दो सहयोगी सरणियों को कैसे जोड़ूं?PHP में एसोसिएटिव एरेज़ का संयोजनPHP में, दो एसोसिएटिव एरेज़ को एक ही एरे में संयोजित करना एक सामान्य कार्य है। निम्नलिखित अनुरोध पर विचार करें:समस्या...प्रोग्रामिंग 2024-12-26 को प्रकाशित
-
वैध कोड के बावजूद पोस्ट अनुरोध PHP में इनपुट कैप्चर क्यों नहीं कर रहा है?PHP में POST अनुरोध की खराबी को संबोधित करनाप्रस्तुत कोड स्निपेट में:action=''इरादा टेक्स्ट बॉक्स से इनपुट कैप्चर करना और सबमिट बटन पर क्लिक करने पर इ...प्रोग्रामिंग 2024-12-26 को प्रकाशित
-
क्या मैं अपने एन्क्रिप्शन को एमक्रिप्ट से ओपनएसएसएल में स्थानांतरित कर सकता हूं, और ओपनएसएसएल का उपयोग करके एमक्रिप्ट-एन्क्रिप्टेड डेटा को डिक्रिप्ट कर सकता हूं?मेरी एन्क्रिप्शन लाइब्रेरी को Mcrypt से OpenSSL में अपग्रेड करनाक्या मैं अपनी एन्क्रिप्शन लाइब्रेरी को Mcrypt से OpenSSL में अपग्रेड कर सकता हूं? ओपनए...प्रोग्रामिंग 2024-12-26 को प्रकाशित
-
PHP के फ़ंक्शन पुनर्परिभाषा प्रतिबंधों पर कैसे काबू पाएं?PHP की फ़ंक्शन पुनर्परिभाषा सीमाओं पर काबू पानाPHP में, एक ही नाम के साथ एक फ़ंक्शन को कई बार परिभाषित करना एक नो-नो है। ऐसा करने का प्रयास करने पर, ज...प्रोग्रामिंग 2024-12-26 को प्रकाशित
-
जेएस और मूल बातेंजावास्क्रिप्ट और प्रोग्रामिंग फंडामेंटल के लिए एक शुरुआती मार्गदर्शिका जावास्क्रिप्ट (जेएस) एक शक्तिशाली और बहुमुखी प्रोग्रामिंग भाषा है जिसका उपयोग म...प्रोग्रामिंग 2024-12-26 को प्रकाशित
-
डेटा डालते समय ''सामान्य त्रुटि: 2006 MySQL सर्वर चला गया है'' को कैसे ठीक करें?रिकॉर्ड सम्मिलित करते समय "सामान्य त्रुटि: 2006 MySQL सर्वर चला गया है" को कैसे हल करेंपरिचय:MySQL डेटाबेस में डेटा डालने से कभी-कभी त्रुटि ...प्रोग्रामिंग 2024-12-26 को प्रकाशित
-
HTML फ़ॉर्मेटिंग टैगHTML फ़ॉर्मेटिंग तत्व **HTML Formatting is a process of formatting text for better look and feel. HTML provides us ability to format text...प्रोग्रामिंग 2024-12-26 को प्रकाशित
-
मैं MySQL का उपयोग करके आज के जन्मदिन वाले उपयोगकर्ताओं को कैसे ढूँढ सकता हूँ?MySQL का उपयोग करके आज के जन्मदिन वाले उपयोगकर्ताओं की पहचान कैसे करेंMySQL का उपयोग करके यह निर्धारित करना कि आज उपयोगकर्ता का जन्मदिन है या नहीं, इस...प्रोग्रामिंग 2024-12-26 को प्रकाशित
-
मैं जावा स्ट्रिंग में एकाधिक सबस्ट्रिंग को कुशलतापूर्वक कैसे बदल सकता हूं?जावा में एक स्ट्रिंग में एकाधिक सबस्ट्रिंग को कुशलतापूर्वक बदलनाजब एक स्ट्रिंग के भीतर कई सबस्ट्रिंग को बदलने की आवश्यकता का सामना करना पड़ता है, तो य...प्रोग्रामिंग 2024-12-26 को प्रकाशित
-
MacOS पर Django में \"अनुचित कॉन्फ़िगर: MySQLdb मॉड्यूल लोड करने में त्रुटि\" को कैसे ठीक करें?MySQL अनुचित रूप से कॉन्फ़िगर किया गया: सापेक्ष पथों के साथ समस्याDjango में Python मैनेज.py runserver चलाते समय, आपको निम्न त्रुटि का सामना करना पड़ ...प्रोग्रामिंग 2024-12-26 को प्रकाशित
-
सरणीतरीके एफएनएस हैं जिन्हें ऑब्जेक्ट पर कॉल किया जा सकता है ऐरे ऑब्जेक्ट हैं, इसलिए जेएस में उनके तरीके भी हैं। स्लाइस (शुरू): मूल सरणी को बदले ब...प्रोग्रामिंग 2024-12-26 को प्रकाशित
-
मैं एचटीएमएल तालिकाओं में प्रतिशत-आधारित कॉलम के साथ कैल्क () का प्रभावी ढंग से उपयोग कैसे कर सकता हूं?तालिकाओं के साथ कैल्क() का उपयोग करना: प्रतिशत दुविधा पर काबू पानानिश्चित और परिवर्तनीय-चौड़ाई वाले दोनों कॉलमों के साथ तालिकाएं बनाना चुनौतीपूर्ण हो ...प्रोग्रामिंग 2024-12-26 को प्रकाशित
-
जावास्क्रिप्ट ऑब्जेक्ट्स में कुंजी को गतिशील रूप से कैसे सेट करें?जावास्क्रिप्ट ऑब्जेक्ट वेरिएबल के लिए डायनामिक कुंजी कैसे बनाएंजावास्क्रिप्ट ऑब्जेक्ट के लिए डायनामिक कुंजी बनाने का प्रयास करते समय, इस सिंटैक्स का उ...प्रोग्रामिंग 2024-12-26 को प्रकाशित
-
PHP में POST के माध्यम से बहुआयामी सारणी कैसे सबमिट और प्रोसेस करें?PHP में POST के माध्यम से बहुआयामी सारणी सबमिट करेंPHP फॉर्म के साथ काम करते समय जिसमें कई कॉलम और परिवर्तनीय लंबाई की पंक्तियां होती हैं, कनवर्ट करना...प्रोग्रामिंग 2024-12-26 को प्रकाशित















चीनी भाषा का अध्ययन करें
- 1 आप चीनी भाषा में "चलना" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 2 आप चीनी भाषा में "विमान ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 3 आप चीनी भाषा में "ट्रेन ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 4 आप चीनी भाषा में "बस ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 5 चीनी भाषा में ड्राइव को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 6 तैराकी को चीनी भाषा में क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 7 आप चीनी भाषा में साइकिल चलाने को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 8 आप चीनी भाषा में नमस्ते कैसे कहते हैं? 你好चीनी उच्चारण, 你好चीनी सीखना
- 9 आप चीनी भाषा में धन्यवाद कैसे कहते हैं? 谢谢चीनी उच्चारण, 谢谢चीनी सीखना
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









