 मुखपृष्ठ > प्रोग्रामिंग > OpenVINO और Postgres का उपयोग करके एक तेज़ और कुशल सिमेंटिक खोज प्रणाली का निर्माण
मुखपृष्ठ > प्रोग्रामिंग > OpenVINO और Postgres का उपयोग करके एक तेज़ और कुशल सिमेंटिक खोज प्रणाली का निर्माण
OpenVINO और Postgres का उपयोग करके एक तेज़ और कुशल सिमेंटिक खोज प्रणाली का निर्माण
 ब्राउज़ करें:591
ब्राउज़ करें:591

पिक्साबे पर रियल-नैपस्टर द्वारा फोटो
मेरे हाल के एक प्रोजेक्ट में, मुझे एक सिमेंटिक सर्च सिस्टम बनाना था जो उच्च प्रदर्शन के साथ स्केल कर सके और रिपोर्ट खोजों के लिए वास्तविक समय में प्रतिक्रिया दे सके। हमने इसे प्राप्त करने के लिए AWS RDS पर pgvector के साथ PostgreSQL का उपयोग किया, जिसे AWS Lambda के साथ जोड़ा गया। चुनौती यह थी कि उपयोगकर्ताओं को कठोर कीवर्ड पर भरोसा करने के बजाय प्राकृतिक भाषा प्रश्नों का उपयोग करके खोज करने की अनुमति दी जाए, जबकि यह सुनिश्चित किया जाए कि प्रतिक्रियाएँ 1-2 सेकंड या उससे भी कम समय में हों और केवल सीपीयू संसाधनों का लाभ उठाया जा सके।
इस पोस्ट में, मैं इस खोज प्रणाली को बनाने के लिए उठाए गए कदमों के बारे में बताऊंगा, पुनर्प्राप्ति से लेकर पुन: रैंकिंग तक, और ओपनविनो और टोकननाइजेशन के लिए बुद्धिमान बैचिंग का उपयोग करके किए गए अनुकूलन।
सिमेंटिक सर्च का अवलोकन: पुनर्प्राप्ति और पुनर्रैंकिंग
आधुनिक अत्याधुनिक खोज प्रणालियों में आमतौर पर दो मुख्य चरण होते हैं: पुनर्प्राप्ति और पुनर्रैंकिंग।
1) पुनर्प्राप्ति: पहले चरण में उपयोगकर्ता क्वेरी के आधार पर प्रासंगिक दस्तावेजों का एक सबसेट पुनर्प्राप्त करना शामिल है। यह पूर्व-प्रशिक्षित एम्बेडिंग मॉडल का उपयोग करके किया जा सकता है, जैसे ओपनएआई के छोटे और बड़े एम्बेडिंग, कोहेयर के एम्बेड मॉडल, या मिक्सब्रेड के एमएक्सबाई एम्बेडिंग। पुनर्प्राप्ति क्वेरी के साथ उनकी समानता को मापकर दस्तावेज़ों के पूल को कम करने पर केंद्रित है।
पुनर्प्राप्ति के लिए हगिंगफेस की वाक्य-ट्रांसफॉर्मर लाइब्रेरी का उपयोग करके यहां एक सरल उदाहरण दिया गया है जो इसके लिए मेरी पसंदीदा लाइब्रेरी में से एक है:
from sentence_transformers import SentenceTransformer
import numpy as np
# Load a pre-trained sentence transformer model
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2")
# Sample query and documents (vectorize the query and the documents)
query = "How do I fix a broken landing gear?"
documents = ["Report 1 on landing gear failure", "Report 2 on engine problems"]
# Get embeddings for query and documents
query_embedding = model.encode(query)
document_embeddings = model.encode(documents)
# Calculate cosine similarity between query and documents
similarities = np.dot(document_embeddings, query_embedding)
# Retrieve top-k most relevant documents
top_k = np.argsort(similarities)[-5:]
print("Top 5 documents:", [documents[i] for i in top_k])
2) पुनर्रैंकिंग: एक बार सबसे प्रासंगिक दस्तावेज़ पुनर्प्राप्त हो जाने के बाद, हम क्रॉस-एनकोडर मॉडल का उपयोग करके इन दस्तावेज़ों की रैंकिंग में और सुधार करते हैं। यह चरण गहरी प्रासंगिक समझ पर ध्यान केंद्रित करते हुए, क्वेरी के संबंध में प्रत्येक दस्तावेज़ का अधिक सटीक रूप से पुनर्मूल्यांकन करता है।
पुनर्रैंकिंग फायदेमंद है क्योंकि यह प्रत्येक दस्तावेज़ की प्रासंगिकता को अधिक सटीक रूप से स्कोर करके परिशोधन की एक अतिरिक्त परत जोड़ता है।
क्रॉस-एनकोडर/एमएस-मार्को-टिनीबीईआरटी-एल-2-वी2, एक हल्के क्रॉस-एनकोडर का उपयोग करके पुन: रैंकिंग करने के लिए यहां एक कोड उदाहरण दिया गया है:
from sentence_transformers import CrossEncoder
# Load the cross-encoder model
cross_encoder = CrossEncoder("cross-encoder/ms-marco-TinyBERT-L-2-v2")
# Use the cross-encoder to rerank top-k retrieved documents
query_document_pairs = [(query, doc) for doc in documents]
scores = cross_encoder.predict(query_document_pairs)
# Rank documents based on the new scores
top_k_reranked = np.argsort(scores)[-5:]
print("Top 5 reranked documents:", [documents[i] for i in top_k_reranked])
बाधाओं की पहचान: टोकनाइजेशन और भविष्यवाणी की लागत
विकास के दौरान, मैंने पाया कि वाक्य-ट्रांसफॉर्मर के लिए डिफ़ॉल्ट सेटिंग्स के साथ 1,000 रिपोर्टों को संभालने में टोकनाइजेशन और भविष्यवाणी चरणों में काफी समय लग रहा था। इसने एक प्रदर्शन बाधा उत्पन्न की, खासकर जब से हमने वास्तविक समय की प्रतिक्रियाओं का लक्ष्य रखा।
नीचे मैंने प्रदर्शनों को देखने के लिए स्नेकविज़ का उपयोग करके अपना कोड प्रोफाइल किया है:
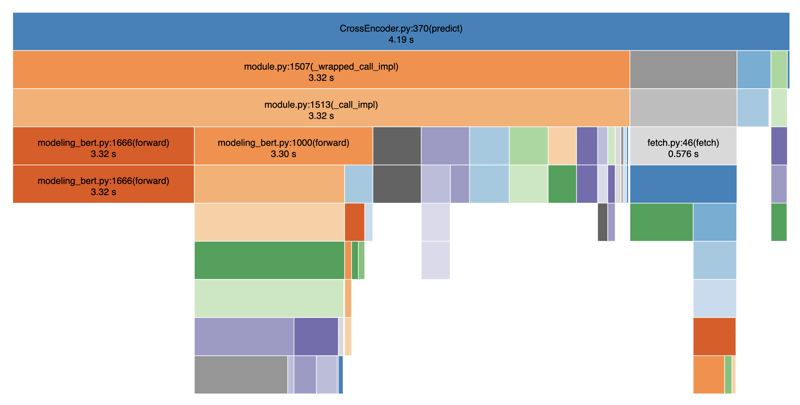
जैसा कि आप देख सकते हैं, टोकनाइजेशन और पूर्वानुमान के चरण बेहद धीमे हैं, जिससे खोज परिणाम प्रस्तुत करने में महत्वपूर्ण देरी हो रही है। कुल मिलाकर इसमें औसतन 4-5 सेकंड का समय लगा। यह इस तथ्य के कारण है कि टोकननाइजेशन और भविष्यवाणी चरणों के बीच अवरुद्ध संचालन होते हैं। यदि हम डेटाबेस कॉल, फ़िल्टरिंग आदि जैसे अन्य ऑपरेशन भी जोड़ते हैं, तो हम आसानी से कुल मिलाकर 8-9 सेकंड में समाप्त हो जाते हैं।
OpenVINO के साथ प्रदर्शन का अनुकूलन
मेरे सामने जो प्रश्न आया वह था: क्या हम इसे और तेज़ बना सकते हैं? इसका उत्तर हां है, OpenVINO का लाभ उठाकर, जो सीपीयू अनुमान के लिए एक अनुकूलित बैकएंड है। OpenVINO इंटेल हार्डवेयर पर गहन शिक्षण मॉडल अनुमान को तेज करने में मदद करता है, जिसका उपयोग हम AWS लैम्ब्डा पर करते हैं।
OpenVINO अनुकूलन के लिए कोड उदाहरण
यहां बताया गया है कि मैंने अनुमान को तेज करने के लिए ओपनविनो को खोज प्रणाली में कैसे एकीकृत किया:
import argparse
import numpy as np
import pandas as pd
from typing import Any
from openvino.runtime import Core
from transformers import AutoTokenizer
def load_openvino_model(model_path: str) -> Core:
core = Core()
model = core.read_model(model_path ".xml")
compiled_model = core.compile_model(model, "CPU")
return compiled_model
def rerank(
compiled_model: Core,
query: str,
results: list[str],
tokenizer: AutoTokenizer,
batch_size: int,
) -> np.ndarray[np.float32, Any]:
max_length = 512
all_logits = []
# Split results into batches
for i in range(0, len(results), batch_size):
batch_results = results[i : i batch_size]
inputs = tokenizer(
[(query, item) for item in batch_results],
padding=True,
truncation="longest_first",
max_length=max_length,
return_tensors="np",
)
# Extract input tensors (convert to NumPy arrays)
input_ids = inputs["input_ids"].astype(np.int32)
attention_mask = inputs["attention_mask"].astype(np.int32)
token_type_ids = inputs.get("token_type_ids", np.zeros_like(input_ids)).astype(
np.int32
)
infer_request = compiled_model.create_infer_request()
output = infer_request.infer(
{
"input_ids": input_ids,
"attention_mask": attention_mask,
"token_type_ids": token_type_ids,
}
)
logits = output["logits"]
all_logits.append(logits)
all_logits = np.concatenate(all_logits, axis=0)
return all_logits
def fetch_search_data(search_text: str) -> pd.DataFrame:
# Usually you would fetch the data from a database
df = pd.read_csv("cnbc_headlines.csv")
df = df[~df["Headlines"].isnull()]
texts = df["Headlines"].tolist()
# Load the model and rerank
openvino_model = load_openvino_model("cross-encoder-openvino-model/model")
tokenizer = AutoTokenizer.from_pretrained("cross-encoder/ms-marco-TinyBERT-L-2-v2")
rerank_scores = rerank(openvino_model, search_text, texts, tokenizer, batch_size=16)
# Add the rerank scores to the DataFrame and sort by the new scores
df["rerank_score"] = rerank_scores
df = df.sort_values(by="rerank_score", ascending=False)
return df
if __name__ == "__main__":
parser = argparse.ArgumentParser(
description="Fetch search results with reranking using OpenVINO"
)
parser.add_argument(
"--search_text",
type=str,
required=True,
help="The search text to use for reranking",
)
args = parser.parse_args()
df = fetch_search_data(args.search_text)
print(df)
इस दृष्टिकोण से हम मूल 4-5 सेकंड को घटाकर 1-2 सेकंड तक 2-3x स्पीडअप प्राप्त कर सकते हैं। संपूर्ण कार्य कोड Github पर है।
गति के लिए फाइन-ट्यूनिंग: बैच आकार और टोकनाइजेशन
प्रदर्शन को बेहतर बनाने में एक अन्य महत्वपूर्ण कारक टोकनीकरण प्रक्रिया को अनुकूलित करना और बैच आकार और टोकन लंबाई को समायोजित करना था। बैच का आकार (बैच_आकार=16) बढ़ाकर और टोकन की लंबाई (अधिकतम_लंबाई=512) कम करके, हम टोकननाइजेशन को समानांतर कर सकते हैं और दोहराए जाने वाले संचालन के ओवरहेड को कम कर सकते हैं। हमारे प्रयोगों में, हमने पाया कि 16 और 64 के बीच का बैच आकार किसी भी बड़े अपमानजनक प्रदर्शन के साथ अच्छा काम करता है। इसी प्रकार, हमने 128 की अधिकतम लंबाई तय की है, जो व्यवहार्य है यदि आपकी रिपोर्ट की औसत लंबाई अपेक्षाकृत कम है। इन परिवर्तनों के साथ, हमने समग्र रूप से 8 गुना गति प्राप्त की, जिससे सीपीयू पर भी पुन: रैंकिंग का समय 1 सेकंड से कम हो गया।
व्यवहार में, इसका मतलब आपके डेटा के लिए गति और सटीकता के बीच सही संतुलन खोजने के लिए विभिन्न बैच आकार और टोकन लंबाई के साथ प्रयोग करना है। ऐसा करने से, हमने प्रतिक्रिया समय में महत्वपूर्ण सुधार देखा, जिससे खोज प्रणाली 1,000 रिपोर्टों के साथ भी स्केलेबल हो गई।
निष्कर्ष
OpenVINO का उपयोग करके और टोकननाइजेशन और बैचिंग को अनुकूलित करके, हम एक उच्च-प्रदर्शन सिमेंटिक खोज प्रणाली बनाने में सक्षम थे जो केवल-सीपीयू सेटअप पर वास्तविक समय की आवश्यकताओं को पूरा करता है। वास्तव में, हमने कुल मिलाकर 8x स्पीडअप का अनुभव किया। वाक्य-ट्रांसफॉर्मर का उपयोग करके पुनर्प्राप्ति का संयोजन और क्रॉस-एनकोडर मॉडल के साथ पुन: रैंकिंग एक शक्तिशाली, उपयोगकर्ता-अनुकूल खोज अनुभव बनाता है।
यदि आप प्रतिक्रिया समय और कम्प्यूटेशनल संसाधनों पर बाधाओं के साथ समान सिस्टम का निर्माण कर रहे हैं, तो मैं बेहतर प्रदर्शन को अनलॉक करने के लिए ओपनविनो और बुद्धिमान बैचिंग की खोज करने की अत्यधिक अनुशंसा करता हूं।
उम्मीद है, आपको यह लेख पसंद आया होगा। यदि आपको यह लेख उपयोगी लगा, तो मुझे लाइक करें ताकि अन्य लोग भी इसे पा सकें, और इसे अपने दोस्तों के साथ साझा करें। मेरे काम से अपडेट रहने के लिए मुझे लिंक्डइन पर फॉलो करें। पढ़ने के लिए धन्यवाद!
-
 मैं PHP के फाइलसिस्टम फ़ंक्शंस में UTF-8 फ़ाइल नाम कैसे संभाल सकता हूं?असंगतता। mkdir ($ dir_name); मूल UTF-8 फ़ाइल नाम को पुनः प्राप्त करने के लिए, urldecode का उपयोग करें। केवल) विंडोज पर, आप UTF-8 फ़ाइल नाम ...प्रोग्रामिंग 2025-04-11 को पोस्ट किया गया
मैं PHP के फाइलसिस्टम फ़ंक्शंस में UTF-8 फ़ाइल नाम कैसे संभाल सकता हूं?असंगतता। mkdir ($ dir_name); मूल UTF-8 फ़ाइल नाम को पुनः प्राप्त करने के लिए, urldecode का उपयोग करें। केवल) विंडोज पर, आप UTF-8 फ़ाइल नाम ...प्रोग्रामिंग 2025-04-11 को पोस्ट किया गया -
गतिशील रूप से आकार के मूल तत्व के भीतर एक तत्व की स्क्रॉलिंग रेंज को कैसे सीमित करें?] इस तरह के एक परिदृश्य में गतिशील रूप से आकार के मूल तत्व के भीतर एक तत्व की स्क्रॉलिंग रेंज को सीमित करना शामिल है। हालाँकि, मानचित्र की स्क्रॉलिंग ...प्रोग्रामिंग 2025-04-11 को पोस्ट किया गया
-
मैं माउस क्लिक पर एक DIV के भीतर सभी पाठ का चयन कैसे कर सकता हूं?] This allows users to easily drag and drop the selected text or copy it directly.SolutionTo select the text within a DIV element on a single mouse cl...प्रोग्रामिंग 2025-04-11 को पोस्ट किया गया
-
मैं पांडा डेटाफ्रेम में कुशलता से कॉलम का चयन कैसे करूं?] पंडों में, कॉलम का चयन करने के लिए विभिन्न विकल्प हैं। संख्यात्मक सूचकांक यदि कॉलम सूचकांक ज्ञात हैं, तो उन्हें चुनने के लिए ILOC फ़ंक्शन का ...प्रोग्रामिंग 2025-04-11 को पोस्ट किया गया
-
Visual Studio 2012 में DataSource संवाद में MySQL डेटाबेस कैसे जोड़ें?] यह लेख इस मुद्दे को संबोधित करता है और एक समाधान प्रदान करता है। इसे हल करने के लिए, यह समझना महत्वपूर्ण है कि MySQL के लिए आधिकारिक विजुअल स्टूडियो...प्रोग्रामिंग 2025-04-11 को पोस्ट किया गया
-
PHP में टाइमज़ोन को कुशलता से कैसे परिवर्तित करें?] यह गाइड अलग-अलग टाइमज़ोन के बीच तारीखों और समय को परिवर्तित करने के लिए एक आसान-से-प्रभाव विधि प्रदान करेगा। उदाहरण के लिए: // उपयोगकर्ता के Timez...प्रोग्रामिंग 2025-04-11 को पोस्ट किया गया
-
पायथन पढ़ें CSV फ़ाइल Unicodedecodeerror अल्टीमेट सॉल्यूशनडिकोड बाइट्स स्थिति 2-3 में: truncated \ uxxxxxxxxx escape यह त्रुटि तब होती है जब CSV फ़ाइल के पथ में विशेष वर्ण होते हैं या यूनिकोड होता है कि पा...प्रोग्रामिंग 2025-04-11 को पोस्ट किया गया
-
तीन MySQL तालिकाओं से डेटा को एक नई तालिका में कैसे संयोजित करें?] लोग, विवरण, और टैक्सोनॉमी टेबल? पी।*, उम्र के रूप में d.content का चयन करें पी के रूप में लोगों से D.Person_id = P.ID पर D के रूप में विवरण में शामि...प्रोग्रामिंग 2025-04-11 को पोस्ट किया गया
-
मैं नोड-MYSQL का उपयोग करके एक ही क्वेरी में कई SQL स्टेटमेंट को कैसे निष्पादित कर सकता हूं?बयानों को अलग करने के लिए अर्ध-उपनिवेश (;)। हालाँकि, यह एक त्रुटि है कि SQL सिंटैक्स में कोई त्रुटि है। इस सुविधा को सक्षम करने के लिए, आपको एक कनेक्...प्रोग्रामिंग 2025-04-11 को पोस्ट किया गया
-
मैक्स काउंट को ढूंढते समय MySQL में समूह फ़ंक्शन \ "त्रुटि के \" अमान्य उपयोग को कैसे हल करें?नाम से EMP1 समूह से अधिकतम (गिनती (*)) का चयन करें; त्रुटि 1111 (Hy000): समूह फ़ंक्शन का अमान्य उपयोग त्रुटि को समझना त्रुटि उत्पन्न होती है ...प्रोग्रामिंग 2025-04-11 को पोस्ट किया गया
-
बहु-आयामी सरणियों के लिए PHP में JSON पार्सिंग को सरल कैसे करें?] To simplify the process, it's recommended to parse the JSON as an array rather than an object.To do this, use the json_decode function with the ...प्रोग्रामिंग 2025-04-11 को पोस्ट किया गया
-
PHP का उपयोग करके MySQL में बूँदों (चित्र) को ठीक से कैसे डालें?] यह गाइड आपके छवि डेटा को सफलतापूर्वक संग्रहीत करने के लिए समाधान प्रदान करेगा। ImageStore (ImageId, Image) मान ('$ यह- & gt; image_id', ...प्रोग्रामिंग 2025-04-11 को पोस्ट किया गया
-
PHP में कर्ल के साथ एक कच्ची पोस्ट अनुरोध कैसे भेजें?] यह लेख एक कच्चे पोस्ट अनुरोध करने के लिए कर्ल का उपयोग करने का तरीका प्रदर्शित करेगा, जहां डेटा को अनएन्कोडेड फॉर्म में भेजा जाता है। फिर, निम्न विक...प्रोग्रामिंग 2025-04-11 को पोस्ट किया गया
-
क्या मुझे कार्यक्रम से बाहर निकलने से पहले C ++ में स्पष्ट रूप से ढेर आवंटन को हटाने की आवश्यकता है?] यह लेख इस विषय में देरी करता है। C मुख्य फ़ंक्शन में, एक गतिशील रूप से आवंटित चर (हीप मेमोरी) के लिए एक सूचक का उपयोग किया जाता है। जैसा कि एप्लिक...प्रोग्रामिंग 2025-04-11 को पोस्ट किया गया
-
होमब्रे से मेरा गो सेटअप क्यों कमांड लाइन निष्पादन मुद्दों का कारण बनता है?] जबकि HomeBrew स्थापना प्रक्रिया को सरल करता है, यह कमांड लाइन निष्पादन और अपेक्षित व्यवहार के बीच एक संभावित विसंगति का परिचय देता है। आपके द्वारा...प्रोग्रामिंग 2025-04-11 को पोस्ट किया गया















चीनी भाषा का अध्ययन करें
- 1 आप चीनी भाषा में "चलना" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 2 आप चीनी भाषा में "विमान ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 3 आप चीनी भाषा में "ट्रेन ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 4 आप चीनी भाषा में "बस ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 5 चीनी भाषा में ड्राइव को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 6 तैराकी को चीनी भाषा में क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 7 आप चीनी भाषा में साइकिल चलाने को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 8 आप चीनी भाषा में नमस्ते कैसे कहते हैं? 你好चीनी उच्चारण, 你好चीनी सीखना
- 9 आप चीनी भाषा में धन्यवाद कैसे कहते हैं? 谢谢चीनी उच्चारण, 谢谢चीनी सीखना
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









