
अपने अनुकूली विश्लेषिकी समाधान के साथ एआई/एमएल को पाटें
 ब्राउज़ करें:474
ब्राउज़ करें:474
आज के डेटा परिदृश्य में, व्यवसायों को कई अलग-अलग चुनौतियों का सामना करना पड़ता है। उनमें से एक सभी उपभोक्ताओं के लिए उपलब्ध एकीकृत और सामंजस्यपूर्ण डेटा परत के शीर्ष पर विश्लेषण करना है। एक परत जो उपयोग की जा रही बोली या उपकरण से असंबंधित समान प्रश्नों के समान उत्तर दे सकती है।
इंटरसिस्टम्स आईआरआईएस डेटा प्लेटफ़ॉर्म इसका उत्तर देता है और एडेप्टिव एनालिटिक्स के ऐड-ऑन के साथ जो इस एकीकृत सिमेंटिक परत को वितरित कर सकता है। बीआई टूल्स के माध्यम से इसका उपयोग करने के बारे में डेवकम्युनिटी में बहुत सारे लेख हैं। यह आलेख इस भाग को कवर करेगा कि एआई के साथ इसका उपभोग कैसे किया जाए और साथ ही कुछ अंतर्दृष्टि कैसे वापस रखी जाए।
आइए कदम दर कदम आगे बढ़ें...
एडेप्टिव एनालिटिक्स क्या है?
आप डेवलपर समुदाय वेबसाइट में कुछ परिभाषा आसानी से पा सकते हैं
कुछ शब्दों में, यह आगे की खपत और विश्लेषण के लिए आपकी पसंद के विभिन्न उपकरणों को संरचित और सामंजस्यपूर्ण रूप में डेटा प्रदान कर सकता है। यह विभिन्न बीआई टूल्स को समान डेटा संरचनाएं प्रदान करता है। लेकिन... यह आपके एआई/एमएल टूल्स को भी समान डेटा संरचनाएं प्रदान कर सकता है!
एडेप्टिव एनालिटिक्स में एआई-लिंक नामक एक अतिरिक्त घटक है जो एआई से बीआई तक इस पुल का निर्माण करता है।
एआई-लिंक वास्तव में क्या है?
यह एक पायथन घटक है जिसे मशीन लर्निंग (एमएल) वर्कफ़्लो (उदाहरण के लिए, फीचर इंजीनियरिंग) के प्रमुख चरणों को सुव्यवस्थित करने के उद्देश्य से सिमेंटिक परत के साथ प्रोग्रामेटिक इंटरैक्शन को सक्षम करने के लिए डिज़ाइन किया गया है।
एआई-लिंक के साथ आप यह कर सकते हैं:
- आपके विश्लेषणात्मक डेटा मॉडल की सुविधाओं तक प्रोग्रामेटिक रूप से पहुंच;
- प्रश्न पूछें, आयामों और मापों का पता लगाएं;
- फ़ीड एमएल पाइपलाइन; ... और परिणामों को अपनी सिमेंटिक परत पर वापस लाएँ ताकि दूसरों द्वारा फिर से उपभोग किया जा सके (उदाहरण के लिए टेबलू या एक्सेल के माध्यम से)।
चूंकि यह एक पायथन लाइब्रेरी है, इसका उपयोग किसी भी पायथन वातावरण में किया जा सकता है। नोटबुक सहित।
और इस लेख में मैं एआई-लिंक की मदद से ज्यूपिटर नोटबुक से एडाप्टिव एनालिटिक्स समाधान तक पहुंचने का एक सरल उदाहरण दूंगा।
यहां गिट रिपॉजिटरी है जिसमें उदाहरण के तौर पर संपूर्ण नोटबुक होगी: https://github.com/v23ent/aa-hands-on
पूर्वावश्यकताएं
आगे के चरण मान लें कि आपने निम्नलिखित पूर्व-आवश्यकताएं पूरी कर ली हैं:
- अनुकूली एनालिटिक्स समाधान चालू है और चल रहा है (डेटा वेयरहाउस के रूप में आईआरआईएस डेटा प्लेटफ़ॉर्म के साथ)
- ज्यूपिटर नोटबुक चालू है
- 1. और 2. के बीच कनेक्शन स्थापित किया जा सकता है
चरण 1: सेटअप
सबसे पहले, आइए अपने वातावरण में आवश्यक घटकों को स्थापित करें। इससे काम करने के लिए आगे के चरणों के लिए आवश्यक कुछ पैकेज डाउनलोड हो जाएंगे।
'एटस्केल' - कनेक्ट करने के लिए यह हमारा मुख्य पैकेज है
'पैगंबर' - पैकेज जिसकी हमें भविष्यवाणियां करने के लिए आवश्यकता होगी
pip install atscale prophet
फिर हमें अपनी सिमेंटिक परत की कुछ प्रमुख अवधारणाओं का प्रतिनिधित्व करने वाले प्रमुख वर्गों को आयात करने की आवश्यकता होगी।
क्लाइंट - वह वर्ग जिसका उपयोग हम एडेप्टिव एनालिटिक्स से कनेक्शन स्थापित करने के लिए करेंगे;
प्रोजेक्ट - एडेप्टिव एनालिटिक्स के अंदर परियोजनाओं का प्रतिनिधित्व करने वाला वर्ग;
डेटामॉडल - वह वर्ग जो हमारे वर्चुअल क्यूब का प्रतिनिधित्व करेगा;
from atscale.client import Client from atscale.data_model import DataModel from atscale.project import Project from prophet import Prophet import pandas as pd
चरण 2: कनेक्शन
अब हमें अपने डेटा के स्रोत से कनेक्शन स्थापित करने के लिए पूरी तरह तैयार होना चाहिए।
client = Client(server='http://adaptive.analytics.server', username='sample') client.connect()
आगे बढ़ें और अपने एडाप्टिव एनालिटिक्स इंस्टेंस का कनेक्शन विवरण निर्दिष्ट करें। एक बार आपसे पूछा जाए कि संगठन संवाद बॉक्स में जवाब देता है और फिर कृपया एटस्केल उदाहरण से अपना पासवर्ड दर्ज करें।
स्थापित कनेक्शन के साथ आपको सर्वर पर प्रकाशित परियोजनाओं की सूची से अपना प्रोजेक्ट चुनना होगा। आपको परियोजनाओं की सूची एक इंटरैक्टिव प्रॉम्प्ट के रूप में मिलेगी और उत्तर परियोजना की पूर्णांक आईडी होनी चाहिए। और फिर डेटा मॉडल स्वचालित रूप से चुना जाता है यदि यह एकमात्र है।
project = client.select_project() data_model = project.select_data_model()
चरण 3: अपने डेटासेट का अन्वेषण करें
एआई-लिंक घटक लाइब्रेरी में एटस्केल द्वारा कई विधियां तैयार की गई हैं। वे आपके पास मौजूद डेटा कैटलॉग का पता लगाने, डेटा क्वेरी करने और यहां तक कि कुछ डेटा वापस लेने की अनुमति देते हैं। एटस्केल दस्तावेज़ में व्यापक एपीआई संदर्भ है जो उपलब्ध हर चीज़ का वर्णन करता है।
आइए सबसे पहले data_model के कुछ तरीकों को कॉल करके देखें कि हमारा डेटासेट क्या है:
data_model.get_features() data_model.get_all_categorical_feature_names() data_model.get_all_numeric_feature_names()
आउटपुट कुछ इस तरह दिखना चाहिए
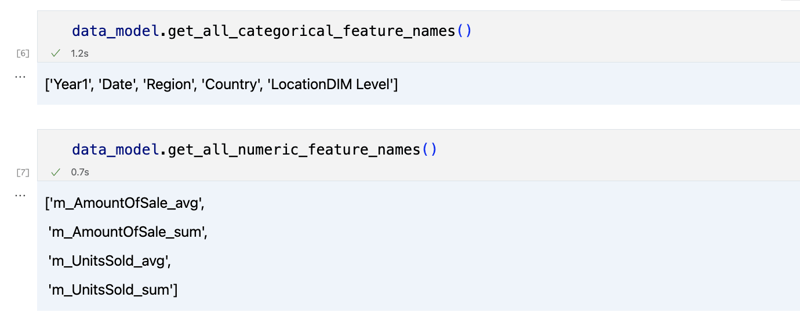
एक बार जब हम चारों ओर देख लेते हैं, तो हम 'get_data' विधि का उपयोग करके उस वास्तविक डेटा के बारे में पूछ सकते हैं जिसमें हम रुचि रखते हैं। यह क्वेरी परिणामों वाला एक पांडा डेटाफ़्रेम वापस लौटाएगा।
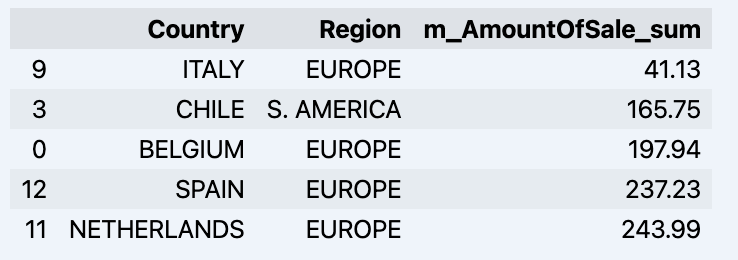
df = data_model.get_data(feature_list = ['Country','Region','m_AmountOfSale_sum']) df = df.sort_values(by='m_AmountOfSale_sum') df.head()
जो आपका डेटाड्रम दिखाएगा:
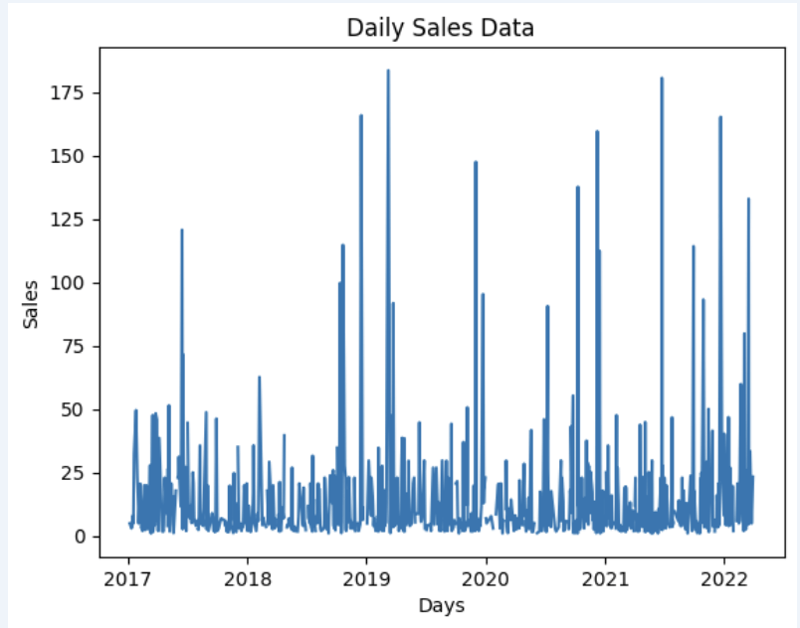
आइए कुछ डेटासेट तैयार करें और जल्दी से इसे ग्राफ़ पर दिखाएं
import matplotlib.pyplot as plt
# We're taking sales for each date
dataframe = data_model.get_data(feature_list = ['Date','m_AmountOfSale_sum'])
# Create a line chart
plt.plot(dataframe['Date'], dataframe['m_AmountOfSale_sum'])
# Add labels and a title
plt.xlabel('Days')
plt.ylabel('Sales')
plt.title('Daily Sales Data')
# Display the chart
plt.show()
आउटपुट:
चरण 4: भविष्यवाणी
अगला कदम वास्तव में एआई-लिंक ब्रिज से कुछ मूल्य प्राप्त करना होगा - आइए कुछ सरल भविष्यवाणी करें!
# Load the historical data to train the model
data_train = data_model.get_data(
feature_list = ['Date','m_AmountOfSale_sum'],
filter_less = {'Date':'2021-01-01'}
)
data_test = data_model.get_data(
feature_list = ['Date','m_AmountOfSale_sum'],
filter_greater = {'Date':'2021-01-01'}
)
हमें यहां 2 अलग-अलग डेटासेट मिलते हैं: हमारे मॉडल को प्रशिक्षित करने और उसका परीक्षण करने के लिए।
# For the tool we've chosen to do the prediction 'Prophet', we'll need to specify 2 columns: 'ds' and 'y'
data_train['ds'] = pd.to_datetime(data_train['Date'])
data_train.rename(columns={'m_AmountOfSale_sum': 'y'}, inplace=True)
data_test['ds'] = pd.to_datetime(data_test['Date'])
data_test.rename(columns={'m_AmountOfSale_sum': 'y'}, inplace=True)
# Initialize and fit the Prophet model
model = Prophet()
model.fit(data_train)
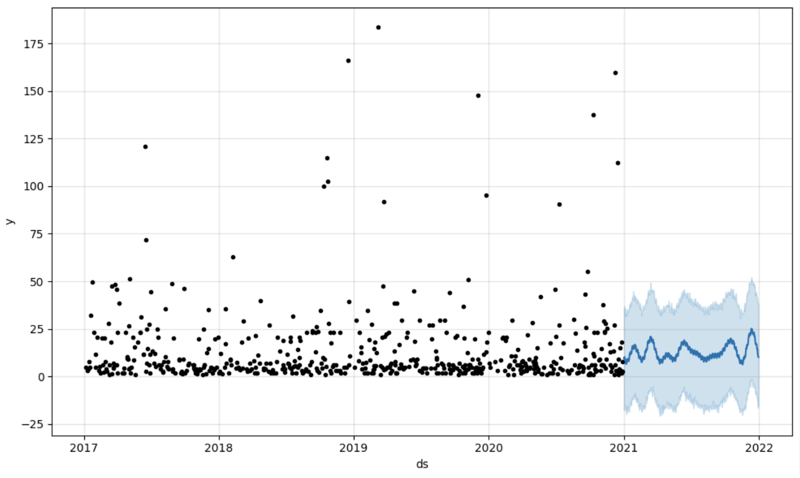
और फिर हम अपनी भविष्यवाणी को समायोजित करने और इसे ग्राफ़ पर प्रदर्शित करने के लिए एक और डेटाफ़्रेम बनाते हैं
# Create a future dataframe for forecasting future = pd.DataFrame() future['ds'] = pd.date_range(start='2021-01-01', end='2021-12-31', freq='D') # Make predictions forecast = model.predict(future) fig = model.plot(forecast) fig.show()
आउटपुट:
चरण 5: राइटबैक
एक बार जब हमें अपनी भविष्यवाणी मिल जाती है तो हम उसे डेटा वेयरहाउस में वापस रख सकते हैं और अन्य उपभोक्ताओं के लिए इसे प्रतिबिंबित करने के लिए अपने सिमेंटिक मॉडल में एक समुच्चय जोड़ सकते हैं। भविष्यवाणी बीआई विश्लेषकों और व्यावसायिक उपयोगकर्ताओं के लिए किसी अन्य बीआई उपकरण के माध्यम से उपलब्ध होगी।
भविष्यवाणी को हमारे डेटा वेयरहाउस में रखा जाएगा और वहां संग्रहीत किया जाएगा।
from atscale.db.connections import Iris
db = Iris(
username,
host,
namespace,
driver,
schema,
port=1972,
password=None,
warehouse_id=None
)data_model.writeback(dbconn=db,
table_name= 'SalesPrediction',
DataFrame = forecast)data_model.create_aggregate_feature(dataset_name='SalesPrediction',
column_name='SalesForecasted',
name='sum_sales_forecasted',
aggregation_type='SUM')
फिन
यही वह है!
आपकी भविष्यवाणियों के लिए शुभकामनाएँ!
-
 फिक्स्ड पोजिशनिंग का उपयोग करते समय 100% ग्रिड-टेम्प्लेट-कॉलम के साथ ग्रिड शरीर से परे क्यों फैलता है?] फिक्स्ड; class = "स्निपेट-कोड"> । माता-पिता { स्थिति: फिक्स्ड; चौड़ाई: 100%; 6fr; lang-html atrayprint-override ">प्रोग्रामिंग 2025-04-26 को पोस्ट किया गया
फिक्स्ड पोजिशनिंग का उपयोग करते समय 100% ग्रिड-टेम्प्लेट-कॉलम के साथ ग्रिड शरीर से परे क्यों फैलता है?] फिक्स्ड; class = "स्निपेट-कोड"> । माता-पिता { स्थिति: फिक्स्ड; चौड़ाई: 100%; 6fr; lang-html atrayprint-override ">प्रोग्रामिंग 2025-04-26 को पोस्ट किया गया -
RPC विधि अन्वेषण के लिए GO इंटरफ़ेस का चिंतनशील गतिशील कार्यान्वयन] एक प्रश्न जो उठाया गया है, क्या यह एक नया फ़ंक्शन बनाने के लिए प्रतिबिंब का उपयोग करना संभव है जो एक विशिष्ट इंटरफ़ेस को लागू करता है। उदाहरण के लिए...प्रोग्रामिंग 2025-04-26 को पोस्ट किया गया
-
Python कुशल तरीका HTML टैग को पाठ से हटाने का] यह HTML टैग को प्रभावी ढंग से स्ट्रिपिंग करके प्राप्त किया जा सकता है, जो आपको वांछित सादे पाठ के साथ छोड़ देता है। MlStripper HTML इनपुट लेता है और...प्रोग्रामिंग 2025-04-26 को पोस्ट किया गया
-
मुझे अपनी सिल्वरलाइट LINQ क्वेरी में "क्वेरी पैटर्न का कार्यान्वयन" त्रुटि क्यों नहीं मिल रही है?] यह त्रुटि आम तौर पर तब होती है जब या तो Linq नेमस्पेस को छोड़ दिया जाता है या queried प्रकार में ienumerable कार्यान्वयन का अभाव होता है। इस विशिष्...प्रोग्रामिंग 2025-04-26 को पोस्ट किया गया
-
क्या C ++ 20 Consteval फ़ंक्शन में टेम्पलेट पैरामीटर फ़ंक्शन मापदंडों पर निर्भर कर सकते हैं?] संकलन-समय। हालाँकि, यह सवाल बना हुआ है: क्या इसका मतलब है कि टेम्पलेट पैरामीटर अब फ़ंक्शन तर्कों पर निर्भर कर सकते हैं? पेपर स्वीकार करता है कि मापद...प्रोग्रामिंग 2025-04-26 को पोस्ट किया गया
-
जावास्क्रिप्ट ऑब्जेक्ट्स में गतिशील रूप से चाबियां कैसे सेट करें?] सही दृष्टिकोण वर्ग कोष्ठक को नियोजित करता है: jsobj ['कुंजी' i] = 'उदाहरण' 1; जावास्क्रिप्ट में, सरणियाँ एक विशेष प्रकार का ऑ...प्रोग्रामिंग 2025-04-26 को पोस्ट किया गया
-
Android PHP सर्वर पर पोस्ट डेटा कैसे भेजता है?] सर्वर-साइड संचार से निपटने के दौरान यह एक सामान्य परिदृश्य है। Apache httpclient (defforated) httpclient httpclient = new defaulthttpclient (); ...प्रोग्रामिंग 2025-04-26 को पोस्ट किया गया
-
क्या मुझे कार्यक्रम से बाहर निकलने से पहले C ++ में स्पष्ट रूप से ढेर आवंटन को हटाने की आवश्यकता है?] यह लेख इस विषय में देरी करता है। C मुख्य फ़ंक्शन में, एक गतिशील रूप से आवंटित चर (हीप मेमोरी) के लिए एक सूचक का उपयोग किया जाता है। जैसा कि एप्लिक...प्रोग्रामिंग 2025-04-26 को पोस्ट किया गया
-
`कंसोल.लॉग` संशोधित ऑब्जेक्ट मान अपवाद का कारण दिखाता हैइस कोड स्निपेट का विश्लेषण करके इस रहस्य को उजागर करें: foo = [{id: 1}, {id: 2}, {id: 3}, {id: 4}, {id: 5},]; कंसोल.लॉग ('foo1', foo, ...प्रोग्रामिंग 2025-04-26 को पोस्ट किया गया
-
मैं PHP में यूनिकोड स्ट्रिंग्स से URL के अनुकूल स्लग कैसे कुशलता से उत्पन्न कर सकता हूं?] यह लेख स्लगों को कुशलता से उत्पन्न करने के लिए एक संक्षिप्त समाधान प्रस्तुत करता है, विशेष वर्णों और गैर-एएससीआईआई वर्णों को URL- अनुकूल स्वरूपों मे...प्रोग्रामिंग 2025-04-26 को पोस्ट किया गया
-
संस्करण 5.6.5 से पहले MySQL में टाइमस्टैम्प कॉलम के साथ current_timestamp का उपयोग करने पर क्या प्रतिबंध थे?] Current_timestamp क्लॉज। यह सीमा INT, BigInt, और SmallInt पूर्णांक को वापस बढ़ाती है जब उन्हें शुरू में 2008 में पेश किया गया था। यह सीमा विरासत क...प्रोग्रामिंग 2025-04-26 को पोस्ट किया गया
-
बहु-आयामी सरणियों के लिए PHP में JSON पार्सिंग को सरल कैसे करें?] To simplify the process, it's recommended to parse the JSON as an array rather than an object.To do this, use the json_decode function with the ...प्रोग्रामिंग 2025-04-26 को पोस्ट किया गया
-
मेरी रैखिक ढाल पृष्ठभूमि में धारियां क्यों हैं, और मैं उन्हें कैसे ठीक कर सकता हूं?] इन भद्दे कलाकृतियों को एक जटिल पृष्ठभूमि प्रसार घटना के लिए जिम्मेदार ठहराया जा सकता है। इसके बाद, रैखिक-ग्रेडिएंट इस पूरी ऊंचाई पर फैलता है, दोहराए...प्रोग्रामिंग 2025-04-26 को पोस्ट किया गया
-
MySQLI पर स्विच करने के बाद MySQL डेटाबेस से कनेक्ट करने के लिए CodeIgniter के कारण] यह त्रुटि गलत PHP कॉन्फ़िगरेशन से उत्पन्न हो सकती है। समस्या को डिबग करने के लिए, यह फ़ाइल के अंत में निम्न कोड जोड़ने के लिए अनुशंसित है ।/config...प्रोग्रामिंग 2025-04-26 को पोस्ट किया गया
-
पायथन मेटाक्लास कार्य सिद्धांत और वर्ग निर्माण और अनुकूलन] जिस तरह कक्षाएं उदाहरण बनाती हैं, मेटाक्लास कक्षाएं बनाते हैं। वे वर्ग निर्माण प्रक्रिया पर नियंत्रण की एक परत प्रदान करते हैं, जो वर्ग व्यवहार और व...प्रोग्रामिंग 2025-04-26 को पोस्ट किया गया















चीनी भाषा का अध्ययन करें
- 1 आप चीनी भाषा में "चलना" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 2 आप चीनी भाषा में "विमान ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 3 आप चीनी भाषा में "ट्रेन ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 4 आप चीनी भाषा में "बस ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 5 चीनी भाषा में ड्राइव को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 6 तैराकी को चीनी भाषा में क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 7 आप चीनी भाषा में साइकिल चलाने को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 8 आप चीनी भाषा में नमस्ते कैसे कहते हैं? 你好चीनी उच्चारण, 你好चीनी सीखना
- 9 आप चीनी भाषा में धन्यवाद कैसे कहते हैं? 谢谢चीनी उच्चारण, 谢谢चीनी सीखना
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









