 Page de garde > La programmation > Suivi de la santé avec l'ingénierie des données - Optimisation des repas de chapitre
Page de garde > La programmation > Suivi de la santé avec l'ingénierie des données - Optimisation des repas de chapitre
Suivi de la santé avec l'ingénierie des données - Optimisation des repas de chapitre
 Parcourir:164
Parcourir:164
Introduction
Bonjour à tous! Ce sera mon premier message, alors soyez dur avec moi, critiquez-moi là où vous pensez que je peux m'améliorer et j'en tiendrai sûrement compte la prochaine fois.
Au cours des derniers mois, j'ai été profondément préoccupé par la santé, principalement en faisant de l'exercice et en surveillant ce que je mange, et maintenant que je pense en avoir une solide maîtrise, je voulais voir comment je peux optimiser davantage mon cas où il y a certaines choses que j'aurais pu manquer.
Objectifs
Pour ce chapitre, je souhaite étudier mes repas tout au long de mon parcours de santé et conclure avec un plan de repas pour la semaine prochaine qui (1) atteint mes besoins minimum en protéines, (2) ne dépasse pas ma limite calorique, (3) répond à mes besoins minimum en fibres et (4) minimise les coûts.
Base de données
Nous commençons par présenter l'ensemble de données, les aliments que nous avons suivis à l'aide de Cronometer. Cronometer a travaillé à mes côtés tout au long de mon parcours et maintenant, j'exporterai les données que j'ai saisies pour les analyser moi-même avec les objectifs que j'ai précédemment énumérés.
Heureusement pour moi, Cronometer me permet d'exporter facilement des données vers un fichier .csv sur leur site Web.
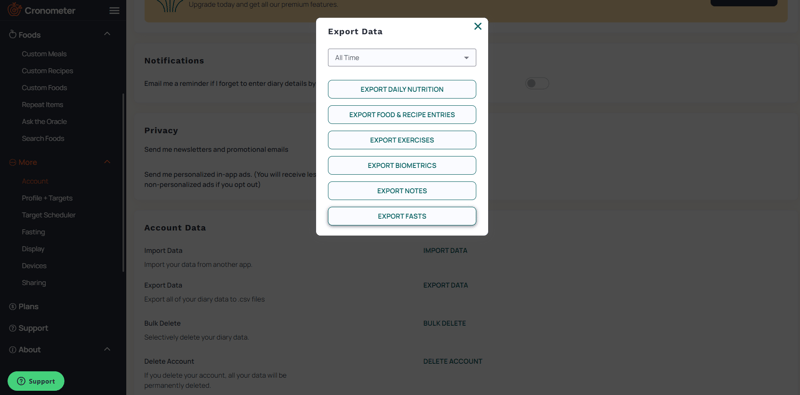
Pour ce chapitre, nous exporterons uniquement l'ensemble de données « Entrées d'aliments et de recettes ».
Nous commençons par examiner les données que nous avons obtenues des « Entrées d'aliments et de recettes ». L'ensemble de données est très complet, ce qui, j'en suis sûr, sera formidable pour les prochains chapitres ! Dans ce chapitre, nous souhaitons le limiter au nom de l'aliment, à sa quantité, à ses protéines, à ses calories et à ses fibres.
# Importing and checking out the dataset
df = pd.read_csv("servings.csv")
df.head()
Prétraitement des données
Nous avons déjà défini quelques colonnes pour nous, dans « Nom de l'aliment », « Quantité », « Énergie (kcal) », « Fibres (g) » et « Protéines (g) ». Parfait! Maintenant, la seule chose qui nous manque est d'obtenir le coût de chaque aliment en fonction d'une certaine quantité, car il n'était pas suivi dans l'ensemble de données. Heureusement pour moi, c'est moi qui ai saisi les données en premier lieu afin de pouvoir saisir les prix que je connais. Cependant, je ne saisirai pas les prix de tous les produits alimentaires. Au lieu de cela, nous demandons à notre bon vieil ami ChatGPT son estimation et remplissons les prix que nous connaissons en peaufinant le fichier .csv. Nous stockons le nouvel ensemble de données dans « cost.csv », que nous avons dérivé en prenant les colonnes « Nom de l'aliment » et « Quantité » de l'ensemble de données d'origine.
# Group by 'Food Name' and collect unique 'Amount' for each group
grouped_df = df.groupby('Food Name')['Amount'].unique().reset_index()
# Expand the DataFrame so each unique 'Food Name' and 'Amount' is on a separate row
expanded_df = grouped_df.explode('Amount')
# Export the DataFrame to a CSV file
expanded_df.to_csv('grouped_food_names_amounts.csv')
# Read the added costs and save as a new DataFrame
df_cost = pd.read_csv("cost.csv").dropna()
df_cost.head()
Certains aliments ont été abandonnés simplement parce qu'ils étaient trop spécifiques et n'entraient pas dans le champ d'application des données relatives à leur faible teneur en calories, à leur valeur nutritive et/ou à leur bon marché (ou simplement parce que je ne voulais pas refaire la recette). ). Nous aurions alors besoin de fusionner deux blocs de données, l'ensemble de données d'origine et celui avec le coût, afin d'obtenir l'ensemble de données supposé « final ». Étant donné que l'ensemble de données d'origine contient les entrées pour chaque aliment, cela signifie que l'ensemble de données d'origine contient plusieurs entrées du même aliment, en particulier ceux que je mange à plusieurs reprises (c'est-à-dire les œufs, la poitrine de poulet, le riz). Nous souhaitons également remplir les colonnes sans valeurs avec « 0 », car la source la plus probable de problèmes ici serait les colonnes « Énergie », « Fibre », « Protéine » et « Prix ».
merged_df = pd.merge(df, df_cost, on=['Food Name', 'Amount'], how='inner') specified_columns = ['Food Name', 'Amount', 'Energy (kcal)', 'Fiber (g)', 'Protein (g)', 'Price'] final_df = merged_df[specified_columns].drop_duplicates() final_df.fillna(0, inplace=True) final_df.head()
Optimisation
Parfait! Notre jeu de données est terminé et maintenant, nous commençons par la deuxième partie, l'optimisation. Rappelant les objectifs de l'étude, nous souhaitons identifier le moindre coût étant donné une quantité minimale de protéines et de fibres, et une quantité maximale de calories. L'option ici est de forcer brutalement chaque combinaison, mais dans l'industrie, le terme approprié est « Programmation linéaire » ou « Optimisation linéaire », mais ne me citez pas là-dessus. Cette fois, nous utiliserons puLP, une bibliothèque Python destinée à faire exactement cela. Je ne sais pas grand-chose sur son utilisation à part suivre le modèle, alors parcourez leur documentation au lieu de lire mon explication non professionnelle sur son fonctionnement. Mais pour ceux qui veulent écouter mon explication informelle du sujet, nous résolvons essentiellement y = ax1 bx2 cx3 ... zxn.
Le modèle que nous suivrons est le modèle de l'étude de cas du problème de mélange, où nous suivons des objectifs similaires mais dans ce cas, nous souhaitons mélanger nos repas tout au long de la journée. Pour commencer, nous aurions besoin de convertir le DataFrame en dictionnaires, en particulier le « Nom de l'aliment » en tant que liste de variables indépendantes qui servent de série de x, puis l'Énergie, les Fibres, les Protéines et le Prix en tant que dictionnaire tel que « Nom de l'aliment » : valeur pour chacun. Notez que le montant sera supprimé à partir de maintenant et sera plutôt concaténé avec le « Nom de l'aliment » car nous ne l'utiliserons pas de manière quantitative.
# Concatenate Amount into Food Name
final_df['Food Name'] = final_df['Food Name'] ' ' final_df['Amount'].astype(str)
food_names = final_df['Food Name'].tolist()
# Create dictionaries for 'Energy', 'Fiber', 'Protein', and 'Price'
energy_dict = final_df.set_index('Food Name')['Energy (kcal)'].to_dict()
fiber_dict = final_df.set_index('Food Name')['Fiber (g)'].to_dict()
fiber_dict['Gardenia, High Fiber Wheat Raisin Loaf 1.00 Slice'] = 3
fiber_dict['Gardenia, High Fiber Wheat Raisin Loaf 2.00 Slice'] = 6
protein_dict = final_df.set_index('Food Name')['Protein (g)'].to_dict()
price_dict = final_df.set_index('Food Name')['Price'].to_dict()
# Display the results
print("Food Names Array:", food_names)
print("Energy Dictionary:", energy_dict)
print("Fiber Dictionary:", fiber_dict)
print("Protein Dictionary:", protein_dict)
print("Price Dictionary:", price_dict)
Pour ceux qui n'ont pas une bonne vue, continuez à faire défiler. Pour ceux qui ont remarqué les étranges 2 lignes de code, laissez-moi vous expliquer. J'ai vu cela pendant que je faisais mes courses, mais les informations nutritionnelles sur le pain de blé et de raisins riches en fibres de Gardenia ne contiennent pas réellement 1 tranche pour 9 grammes de fibres, mais 2 tranches pour 6 grammes. C'est un gros problème et cela m'a causé une douleur incommensurable, sachant que les valeurs peuvent être incorrectes en raison soit d'une mauvaise saisie des données, soit d'un changement d'ingrédients qui a rendu les données obsolètes. Quoi qu’il en soit, j’avais besoin que cette justice soit corrigée et je ne défendrai pas moins de fibre que ce que je mérite. Passons à autre chose.
Nous passons directement à nos valeurs en utilisant le modèle issu des données de l'étude de cas. Nous définissons des variables pour représenter les valeurs minimales que nous souhaitons en protéines et en fibres, ainsi que les calories maximales que nous sommes prêts à manger. Ensuite, nous laissons le code du modèle magique faire son travail et obtenons les résultats.
# Set variables
min_protein = 120
min_fiber = 40
max_energy = 1500
# Just read the case study at https://coin-or.github.io/pulp/CaseStudies/a_blending_problem.html. They explain it way better than I ever could.
prob = LpProblem("Meal Optimization", LpMinimize)
food_vars = LpVariable.dicts("Food", food_names, 0)
prob = (
lpSum([price_dict[i] * food_vars[i] for i in food_names]),
"Total Cost of Food daily",
)
prob = (
lpSum([energy_dict[i] * food_vars[i] for i in food_names]) = min_fiber,
"FiberRequirement",
)
prob = (
lpSum([protein_dict[i] * food_vars[i] for i in food_names]) >= min_protein,
"ProteinRequirement",
)
prob.writeLP("MealOptimization.lp")
prob.solve()
print("Status:", LpStatus[prob.status])
for v in prob.variables():
if v.varValue > 0:
print(v.name, "=", v.varValue)
print("Total Cost of Food per day = ", value(prob.objective))
Résultats

Pour obtenir 120 grammes de protéines et 40 grammes de fibres, il me faudrait dépenser 128 pesos philippins pour 269 grammes de filet de poitrine de poulet et 526 grammes de haricots mungo. Cela... ne semble pas mal du tout compte tenu de combien j'aime les deux ingrédients. Je vais certainement l'essayer, peut-être pendant une semaine ou un mois, juste pour voir combien d'argent j'économiserais malgré une alimentation juste assez.
C'était tout pour ce chapitre de Suivi de la santé avec l'ingénierie des données, si vous souhaitez voir les données sur lesquelles j'ai travaillé dans ce chapitre, visitez le référentiel ou visitez le bloc-notes de cette page. Laissez un commentaire si vous en avez et essayez de rester en bonne santé.
-
 Comment résoudre \ "Refusé de charger le script ... \" Erreurs dues à la stratégie de sécurité du contenu d'Android?dévoiler le mystère: contenu des erreurs de directive de stratégie de sécurité rencontrant l'erreur énigmatique "refusé de charger le...La programmation Publié le 2025-04-27
Comment résoudre \ "Refusé de charger le script ... \" Erreurs dues à la stratégie de sécurité du contenu d'Android?dévoiler le mystère: contenu des erreurs de directive de stratégie de sécurité rencontrant l'erreur énigmatique "refusé de charger le...La programmation Publié le 2025-04-27 -
Python Efficace Way de supprimer les balises HTML du texteDéroup des balises HTML en python pour une représentation textuelle vierge manipulant les réponses HTML à extraire le contenu de texte pertine...La programmation Publié le 2025-04-27
-
Comment combiner les données de trois tables MySQL dans un nouveau tableau?mysql: création d'un nouveau tableau à partir de données et de colonnes de trois tables Question: Comment puis-je créer un nouveau tab...La programmation Publié le 2025-04-27
-
Puis-je migrer mon cryptage de McRypt à OpenSSL et décrypter les données cryptées McRypt à l'aide d'OpenSSL?Mise à niveau de ma bibliothèque de chiffrement de McRypt à OpenSSL Puis-je mettre à niveau ma bibliothèque de cryptage à partir de McRypt à O...La programmation Publié le 2025-04-27
-
La différence entre le traitement de la surcharge de la fonction PHP et C ++PHP Fonction surcharge: démêler l'énigme d'une perspective C en tant que développeur C a chevronné s'aventurant dans le domaine de P...La programmation Publié le 2025-04-27
-
Pourquoi mon image d'arrière-plan CSS apparaît-elle?Troubleshoot: Image d'arrière-plan CSS n'apparaissant pas Vous avez rencontré un problème où votre image d'arrière-plan échoue mal...La programmation Publié le 2025-04-27
-
Pourquoi Pytz montre-t-il des décalages de fuseau horaire inattendus initialement?Dicontenance du fuseau horaire avec pytz Certains flammes de temps présentent des décalages particuliers lorsqu'ils sont initialement obte...La programmation Publié le 2025-04-27
-
Comment analyser les tableaux JSON en Go en utilisant le package «JSON»?analyser les tableaux json dans Go avec le package json Problème: Comment pouvez-vous analyser une chaîne JSON représentant un Array dans Go...La programmation Publié le 2025-04-27
-
Comment puis-je styliser la première instance d'un type d'élément spécifique sur un document HTML entier?correspondant au premier élément d'un certain type dans tout le document Styling Le premier élément d'un type spécifique à travers un...La programmation Publié le 2025-04-27
-
Comment ajouter la base de données MySQL à la boîte de dialogue DataSource dans Visual Studio 2012?Ajout de la base de données MySQL à la boîte de dialogue DataSource dans Visual Studio 2012 En travaillant avec Entity Framework et MySQL, l&#...La programmation Publié le 2025-04-27
-
Pourquoi ma configuration de GO à Homebrew provoque-t-elle des problèmes d'exécution de ligne de commande?Brew Go Configuration vs Exécution de la ligne de commande Vous avez initialement installé aller à l'aide de Homebrew, un gestionnaire de ...La programmation Publié le 2025-04-27
-
Comment ajouter des axes et des balises aux fichiers PNG en Java?Comment annoter un fichier PNG avec des axes et des étiquettes dans Java Ajouter des axes et des étiquettes à une image PNG existante peut êtr...La programmation Publié le 2025-04-27
-
Comment réparer « Erreur générale : le serveur MySQL 2006 a disparu » lors de l'insertion de données ?Comment résoudre « Erreur générale : le serveur MySQL 2006 a disparu » lors de l'insertion d'enregistrementsIntroduction :L'insertion de d...La programmation Publié le 2025-04-27
-
Pouvez-vous utiliser CSS pour colorer la sortie de la console dans Chrome et Firefox?Affichage des couleurs dans la console javascrip Messages? Réponse Oui, il est possible d'utiliser CSS pour ajouter des couleurs aux me...La programmation Publié le 2025-04-27
-
Quelle méthode pour déclarer plusieurs variables en JavaScript est plus maintenable?déclarant plusieurs variables dans javascript: explorant deux méthodes dans javascript, les développeurs rencontrent souvent la nécessité de d...La programmation Publié le 2025-04-27















Étudier le chinois
- 1 Comment dit-on « marcher » en chinois ? 走路 Prononciation chinoise, 走路 Apprentissage du chinois
- 2 Comment dit-on « prendre l’avion » en chinois ? 坐飞机 Prononciation chinoise, 坐飞机 Apprentissage du chinois
- 3 Comment dit-on « prendre un train » en chinois ? 坐火车 Prononciation chinoise, 坐火车 Apprentissage du chinois
- 4 Comment dit-on « prendre un bus » en chinois ? 坐车 Prononciation chinoise, 坐车 Apprentissage du chinois
- 5 Comment dire conduire en chinois? 开车 Prononciation chinoise, 开车 Apprentissage du chinois
- 6 Comment dit-on nager en chinois ? 游泳 Prononciation chinoise, 游泳 Apprentissage du chinois
- 7 Comment dit-on faire du vélo en chinois ? 骑自行车 Prononciation chinoise, 骑自行车 Apprentissage du chinois
- 8 Comment dit-on bonjour en chinois ? 你好Prononciation chinoise, 你好Apprentissage du chinois
- 9 Comment dit-on merci en chinois ? 谢谢Prononciation chinoise, 谢谢Apprentissage du chinois
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









