 Page de garde > La programmation > Qu'est-ce qui est plus rapide et moins cher pour convertir des fichiers dans AWS : Polar ou Pandas ?
Page de garde > La programmation > Qu'est-ce qui est plus rapide et moins cher pour convertir des fichiers dans AWS : Polar ou Pandas ?
Qu'est-ce qui est plus rapide et moins cher pour convertir des fichiers dans AWS : Polar ou Pandas ?
 Parcourir:457
Parcourir:457
Les deux offrent une large gamme d'outils et d'avantages qui peuvent nous faire douter lequel des deux choisir à un moment donné. Il ne s'agit pas de changer tous les processus de l'entreprise pour qu'elle commence à utiliser des Polars ou de « tuer » les Pandas (cela n'arrivera pas dans un avenir immédiat). Il s'agit de connaître d'autres outils qui peuvent nous aider à réduire les coûts et les délais des processus, en obtenant des résultats identiques ou meilleurs.
Lorsque nous utilisons des services cloud, nous donnons la priorité à certains facteurs, notamment leur coût. Les services que j'utilise pour ce processus sont AWS Lambda avec le runtime Python 3.10 et S3 pour stocker le fichier brut et le fichier parquet converti.
L'intention est d'obtenir un fichier CSV sous forme de données brutes et de le traiter avec pandas et polar avec l'intention de vérifier laquelle de ces deux bibliothèques nous offre la meilleure optimisation des ressources telles que la mémoire et le poids du fichier résultant.
Pandas
Il s'agit d'une bibliothèque Python spécialisée dans la manipulation et l'analyse de données, elle est écrite en C et sa sortie initiale date de 2008.
*Polaires *
Il s'agit d'une bibliothèque Python et Rust spécialisée dans la manipulation et l'analyse de données qui permet des processus parallèles. Elle est principalement écrite en Rust et a été publiée en 2022.
L'architecture du processus :
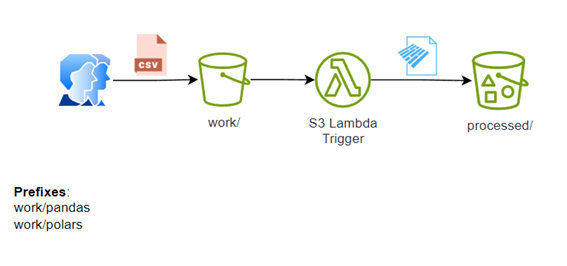
Le projet est assez simple comme le montre l'architecture : L'utilisateur dépose un fichier CSV dans work/pandas ou work/porlas et démarre automatiquement le déclencheur s3 pour traiter le fichier pour le convertir en parquet et le déposer en traitement.
Dans ce petit projet, utilisez deux lambdas avec la configuration suivante :
Mémoire : 2 Go
Mémoire éphémère : 2 Go
Durée de vie : 600 secondes
Exigences
Lambda avec des pandas : Pandas, Numpy et Pyarrow
Lambda avec polaires : Polaires
L'ensemble de données utilisé pour la comparaison est disponible sur Kaggle sous le nom « Rotten Tomatoes Movie Reviews – 1,44 M de lignes » ou peut être téléchargé à partir d'ici.
Le référentiel complet est disponible sur GitHub et peut être cloné ici.
Taille ou poids
Le lambda utilisé par Pandas nécessite deux plugins supplémentaires pour créer un fichier parquet, dans ce cas il s'agit de PyArrow et d'une version spécifique de numpy pour la version de Pandas que j'utilisais. En conséquence, nous avons obtenu un lambda avec un poids ou une taille de 74,4 Mo, quelque chose de très proche de la limite qu'AWS nous autorise pour le poids du lambda.
Le lambda avec Polars ne nécessite pas d'autre plugin comme PyArrow ce qui simplifie la vie et réduit la taille du lambda à moins de la moitié. En conséquence, notre lambda a un poids ou une taille de 30,6 Mo par rapport au premier, ce qui nous laisse de la place pour installer d'autres dépendances dont nous pourrions avoir besoin pour notre processus de transformation.
Performance
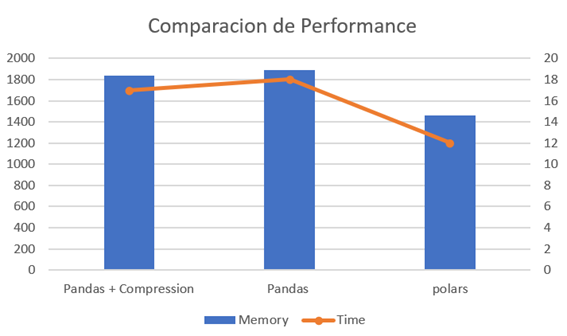
Le lambda avec Pandas a été optimisé pour utiliser la compression après la première version, cependant, son comportement a également été analysé.
Pandas
Il a fallu 18 secondes pour traiter l'ensemble de données et utilisé 1894 Mo de mémoire pour traiter le fichier CSV et générer un fichier Parquet par rapport aux autres versions, c'est celle qui a utilisé le plus de temps et de ressources.
Compression Pandas
L'ajout d'une ligne de code nous a permis de nous améliorer un peu par rapport à la version précédente (Pandas), il fallait 17 secondes pour traiter le jeu de données et utilisé 1837 Mo, ce qui ne représente pas une amélioration significative du temps de traitement et de calcul, mais de la taille. du fichier résultant.
Polaires
Il a fallu 12 secondes pour traiter le même ensemble de données et j'ai utilisé seulement 1462 Mo, par rapport aux deux précédents cela représente un gain de temps de 44,44% et une consommation de mémoire inférieure.
Taille du fichier de sortie
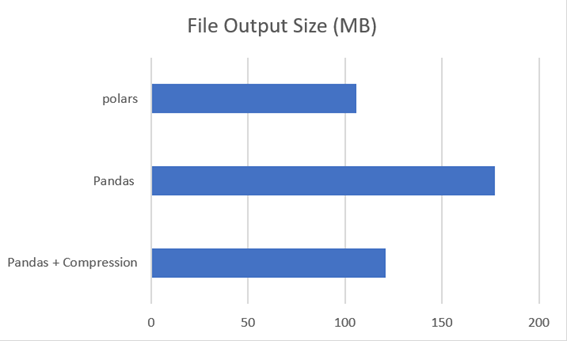
Pandas
Le lambda dans lequel aucun processus de compression n'a été établi a généré un fichier parquet de 177,4 Mo.
Compression Pandas
Lors de la configuration de la compression dans le lambda, je ne génère pas de fichier parquet de 121,1 Mo. Une petite ligne ou option nous a aidé à réduire la taille du fichier de 31,74 %. Étant donné qu’il ne s’agit pas d’un changement de code significatif, c’est une très bonne option.
Polaires
Polars a généré un fichier de 105,8 Mo qui, acheté avec la première version de Pandas, représente une économie de 40,36 % et 12,63 % par rapport à la version Pandas avec compression.
Conclusion
Il n'est pas nécessaire de modifier tous les processus internes qui utilisent Pandas pour qu'ils utilisent désormais Polars, cependant, il est important de considérer que si nous parlons de milliers ou de millions d'exécutions lambda, l'utilisation de Polars nous aidera non seulement dans le déploiement. temps, mais cela nous aidera également à réduire les coûts grâce à la facturation basée sur le temps qu'AWS effectue pour les services sans serveur tels que Lambda.
De même, lorsque nous traduisons ces 40,36 % en millions de fichiers, nous parlons de Go ou de To, ce qui aurait un impact significatif au sein d'un Datalake ou d'un Dataware House ou même dans un stockage de fichiers froid.
La réduction avec Polars ne se limiterait pas seulement à ces deux facteurs, car elle affecterait grandement la sortie de données et/ou d'objets d'AWS car il s'agit d'un service qui a un coût.
-
 ## Pouvez-vous créer des segments de graphique à secteurs en CSS sans JavaScript ?Segments dans un cercle à l'aide de CSSCréer des cercles en CSS à l'aide de border-radius est une pratique courante. Cependant, pouvons-nous o...La programmation Publié le 2024-11-06
## Pouvez-vous créer des segments de graphique à secteurs en CSS sans JavaScript ?Segments dans un cercle à l'aide de CSSCréer des cercles en CSS à l'aide de border-radius est une pratique courante. Cependant, pouvons-nous o...La programmation Publié le 2024-11-06 -
Construire un petit magasin de vecteurs à partir de zéroWith the evolving landscape of generative AI, vector databases are playing crucial role in powering generative AI applications. There are so many vect...La programmation Publié le 2024-11-06
-
Comment utiliser l'API expérimentale AI dans ChromePour utiliser l'API IA expérimentale dans Chrome, procédez comme suit : Exigences matérielles 4 Go de RAM GPU disponible 22 Go d'espac...La programmation Publié le 2024-11-06
-
Critique : Boostez votre Django DX par Adam JohnsonLes critiques de livres sont délicates. Vous ne voulez pas le gâcher, mais vous voulez également donner aux lecteurs potentiels un avant-goût de ce à ...La programmation Publié le 2024-11-06
-
Comment regrouper des éléments d'un tableau et combiner les valeurs d'une autre colonne dans un tableau multidimensionnel ?Regrouper les éléments du tableau par colonne et combiner les valeurs d'une autre colonneÉtant donné un tableau contenant des tableaux imbriqués a...La programmation Publié le 2024-11-06
-
Trois fonctionnalités d'exceptions nouvellement ajoutéesÀ partir du JDK 7, la gestion des exceptions a été étendue avec trois nouvelles fonctionnalités : la gestion automatique des ressources, le multi-cat...La programmation Publié le 2024-11-06
-
Comment corriger l'erreur « Exportation inattendue de jeton » lors de l'exécution du code ES6 ?"Dépannage d'une erreur inattendue d'exportation de jeton"Lors de la tentative d'exécution du code ES6 dans un projet, une erreu...La programmation Publié le 2024-11-06
-
Les extensions VSCode ne sont pas supprimées du système de fichiers même après la désinstallation, j'ai créé une solution !C'est donc un problème avec les éditeurs basés sur vscode. Même après avoir désinstallé une extension, elle restera dans le système de fichiers et...La programmation Publié le 2024-11-06
-
Mise à jour du contenu du site Web dans les délais via GitHub ActionsJ'aimerais partager mon parcours dans la création d'un système de gestion de contenu autonome qui ne nécessite pas de base de données de conte...La programmation Publié le 2024-11-06
-
Comment vider le cache dans un environnement d'hébergement partagé pour une application Laravel 5 ?Comment vider le cache du serveur d'hébergement partagé dans Laravel 5Vider le cache peut être essentiel pour maintenir les performances et l'...La programmation Publié le 2024-11-06
-
Comment accélérer le traçage Matplotlib pour améliorer les performances ?Pourquoi Matplotlib est-il si lent ?Lors de l'évaluation des bibliothèques de traçage Python, il est important de prendre en compte les performanc...La programmation Publié le 2024-11-06
-
Comment surmonter les bords irréguliers et les résultats flous lors du redimensionnement des images avec Canvas ?Résoudre les problèmes de lissage lors du redimensionnement d'images à l'aide de Canvas en JavaScriptLe redimensionnement d'images à l'...La programmation Publié le 2024-11-06
-
Comment résoudre les problèmes d’encodage de texte dans MySQL C# ?Résolution des problèmes d'encodage de texte dans MySQL C#Lorsqu'ils travaillent avec des bases de données MySQL en C# à l'aide d'Enti...La programmation Publié le 2024-11-06
-
Comment intégrer Meilisearch avec Node.jsEn tant que développeur Node.js, il est important de créer des applications qui fournissent des résultats de recherche rapides et précis. Les utilisat...La programmation Publié le 2024-11-06
-
Machine JavaScript parallèleAuteur : Vladas Saulis, PE Prodata, Klaipėda, Lituanie 18 mai 2024 Abstrait Cet article présente un nouveau modèle de programmation capable d'util...La programmation Publié le 2024-11-06















Étudier le chinois
- 1 Comment dit-on « marcher » en chinois ? 走路 Prononciation chinoise, 走路 Apprentissage du chinois
- 2 Comment dit-on « prendre l’avion » en chinois ? 坐飞机 Prononciation chinoise, 坐飞机 Apprentissage du chinois
- 3 Comment dit-on « prendre un train » en chinois ? 坐火车 Prononciation chinoise, 坐火车 Apprentissage du chinois
- 4 Comment dit-on « prendre un bus » en chinois ? 坐车 Prononciation chinoise, 坐车 Apprentissage du chinois
- 5 Comment dire conduire en chinois? 开车 Prononciation chinoise, 开车 Apprentissage du chinois
- 6 Comment dit-on nager en chinois ? 游泳 Prononciation chinoise, 游泳 Apprentissage du chinois
- 7 Comment dit-on faire du vélo en chinois ? 骑自行车 Prononciation chinoise, 骑自行车 Apprentissage du chinois
- 8 Comment dit-on bonjour en chinois ? 你好Prononciation chinoise, 你好Apprentissage du chinois
- 9 Comment dit-on merci en chinois ? 谢谢Prononciation chinoise, 谢谢Apprentissage du chinois
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









