 Page de garde > La programmation > K Régression des voisins les plus proches, régression : apprentissage automatique supervisé
Page de garde > La programmation > K Régression des voisins les plus proches, régression : apprentissage automatique supervisé
K Régression des voisins les plus proches, régression : apprentissage automatique supervisé
 Parcourir:548
Parcourir:548
Régression des k-voisins les plus proches
La régressionk-Nearest Neighbours (k-NN) est une méthode non paramétrique qui prédit la valeur de sortie en fonction de la moyenne (ou moyenne pondérée) des k points de données d'entraînement les plus proches dans l'espace des fonctionnalités. Cette approche peut modéliser efficacement des relations complexes dans les données sans assumer une forme fonctionnelle spécifique.
La méthode de régression k-NN peut être résumée comme suit :
- Metrique de distance : l'algorithme utilise une métrique de distance (généralement la distance euclidienne) pour déterminer la « proximité » des points de données.
- k Voisins : le paramètre k spécifie le nombre de voisins les plus proches à prendre en compte lors de la réalisation de prédictions.
- Prédiction : la valeur prédite pour un nouveau point de données est la moyenne des valeurs de ses k voisins les plus proches.
Concepts clés
Non paramétrique : contrairement aux modèles paramétriques, k-NN ne prend pas de forme spécifique pour la relation sous-jacente entre les caractéristiques d'entrée et la variable cible. Cela le rend flexible dans la capture de modèles complexes.
Calcul de distance : le choix de la métrique de distance peut affecter considérablement les performances du modèle. Les mesures courantes incluent les distances euclidiennes, Manhattan et Minkowski.
Choix de k : le nombre de voisins (k) peut être choisi en fonction d'une validation croisée. Un petit k peut conduire à un surajustement, tandis qu'un grand k peut trop lisser la prédiction, voire un sous-ajustement.
Exemple de régression des k-voisins les plus proches
Cet exemple montre comment utiliser la régression k-NN avec des caractéristiques polynomiales pour modéliser des relations complexes tout en tirant parti de la nature non paramétrique de k-NN.
Exemple de code Python
1. Importer des bibliothèques
import numpy as np import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.preprocessing import PolynomialFeatures from sklearn.neighbors import KNeighborsRegressor from sklearn.metrics import mean_squared_error, r2_score
Ce bloc importe les bibliothèques nécessaires à la manipulation des données, au traçage et à l'apprentissage automatique.
2. Générer des exemples de données
np.random.seed(42) # For reproducibility X = np.linspace(0, 10, 100).reshape(-1, 1) y = 3 * X.ravel() np.sin(2 * X.ravel()) * 5 np.random.normal(0, 1, 100)
Ce bloc génère des exemples de données représentant une relation avec certains bruits, simulant les variations des données du monde réel.
3. Diviser l'ensemble de données
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Ce bloc divise l'ensemble de données en ensembles de formation et de test pour l'évaluation du modèle.
4. Créer des entités polynomiales
degree = 3 # Change this value for different polynomial degrees poly = PolynomialFeatures(degree=degree) X_poly_train = poly.fit_transform(X_train) X_poly_test = poly.transform(X_test)
Ce bloc génère des caractéristiques polynomiales à partir des ensembles de données de formation et de test, permettant au modèle de capturer des relations non linéaires.
5. Créer et entraîner le modèle de régression k-NN
k = 5 # Number of neighbors knn_model = KNeighborsRegressor(n_neighbors=k) knn_model.fit(X_poly_train, y_train)
Ce bloc initialise le modèle de régression k-NN et l'entraîne à l'aide des caractéristiques polynomiales dérivées de l'ensemble de données d'entraînement.
6. Faire des prédictions
y_pred = knn_model.predict(X_poly_test)
Ce bloc utilise le modèle entraîné pour faire des prédictions sur l'ensemble de test.
7. Tracer les résultats
plt.figure(figsize=(10, 6))
plt.scatter(X, y, color='blue', alpha=0.5, label='Data Points')
X_grid = np.linspace(0, 10, 1000).reshape(-1, 1)
X_poly_grid = poly.transform(X_grid)
y_grid = knn_model.predict(X_poly_grid)
plt.plot(X_grid, y_grid, color='red', linewidth=2, label=f'k-NN Regression (k={k}, Degree {degree})')
plt.title(f'k-NN Regression (Polynomial Degree {degree})')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()
Ce bloc crée un nuage de points des points de données réels par rapport aux valeurs prédites du modèle de régression k-NN, visualisant la courbe ajustée.
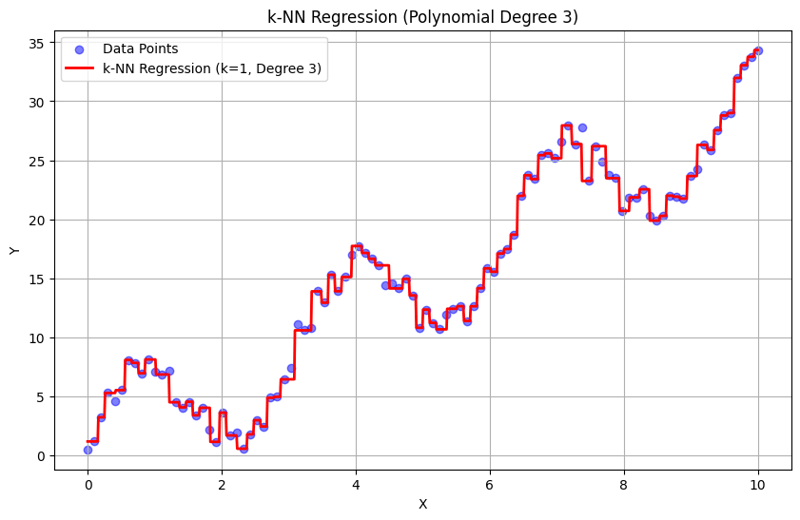
Sortie avec k = 1 :
Sortie avec k = 10 :
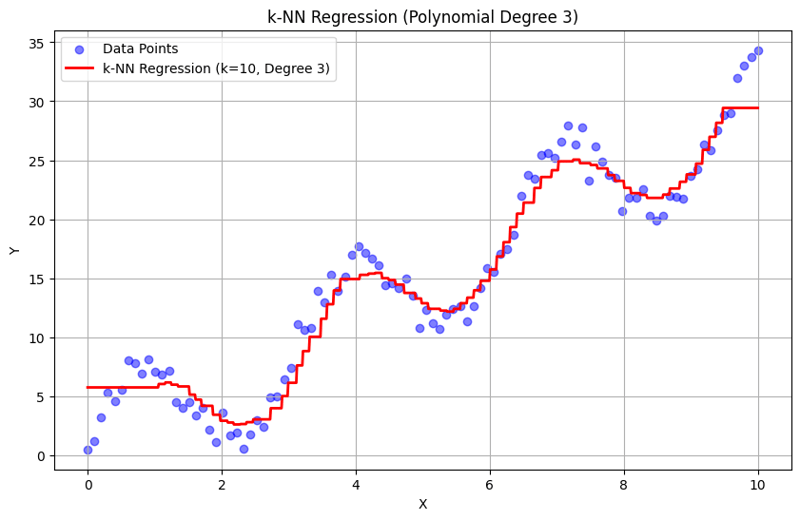
Cette approche structurée montre comment implémenter et évaluer la régression des k-plus proches voisins avec des caractéristiques polynomiales. En capturant des modèles locaux en faisant la moyenne des réponses des voisins proches, la régression k-NN modélise efficacement les relations complexes dans les données tout en fournissant une mise en œuvre simple. Le choix du k et du degré polynomial influence considérablement les performances et la flexibilité du modèle dans la capture des tendances sous-jacentes.
-
 FIT OBJET: la couverture échoue dans IE et Edge, comment réparer?objet-fit: la couverture échoue dans IE et Edge, comment corriger? Utilisation d'objet-fit: couverture; Dans CSS pour maintenir la hauteur...La programmation Publié le 2025-02-07
FIT OBJET: la couverture échoue dans IE et Edge, comment réparer?objet-fit: la couverture échoue dans IE et Edge, comment corriger? Utilisation d'objet-fit: couverture; Dans CSS pour maintenir la hauteur...La programmation Publié le 2025-02-07 -
Pourquoi l'exécution de JavaScript cesse-t-elle lors de l'utilisation du bouton Firefox Retour?Problème d'histoire de la navigation: JavaScript cesse d'exécuter après avoir utilisé le bouton de retour de Firefox Les utilisateurs ...La programmation Publié le 2025-02-07
-
Comment pouvez-vous utiliser des données de groupe par pour pivoter dans MySQL?Pivoting des résultats de la requête en utilisant le groupe mysql par Dans une base de données relationnelle, les données pivotantes se réfère...La programmation Publié le 2025-02-07
-
Puis-je utiliser les SVG comme contenu pseudo-élémentaire dans CSS?Utilisation des SVGS comme contenu pseudo-élément La propriété de contenu CSS permet d'insérer divers types de contenu avant ou après un é...La programmation Publié le 2025-02-07
-
Comment puis-je syndicrer des tables de base de données avec différents nombres de colonnes?Tables combinées avec différentes colonnes ] peut rencontrer des défis lorsque vous essayez de fusionner les tables de base de données avec dif...La programmation Publié le 2025-02-07
-
Comment puis-je vérifier de manière fiable l'existence des colonnes dans une table MySQL?Déterminer l'existence de la colonne dans une table mysql dans mysql, la vérification de la présence d'une colonne dans une table peut...La programmation Publié le 2025-02-07
-
Comment puis-je récupérer efficacement les valeurs d'attribut à partir de fichiers XML à l'aide de PHP?Récupération des valeurs d'attribut à partir de fichiers xml dans php Chaque développeur rencontre la nécessité de analyser les fichiers X...La programmation Publié le 2025-02-07
-
Comment puis-je styliser la première instance d'un type d'élément spécifique sur un document HTML entier?correspondant au premier élément d'un certain type dans tout le document Stylisant le premier élément d'un type spécifique à travers ...La programmation Publié le 2025-02-07
-
Pourquoi une grille avec des colonnes 100% grid-template s'étend-elle au-delà du corps lors de l'utilisation du positionnement fixe?La grille dépasse le corps avec 100% grid-template-columnd Au-delà du corps, lorsque la position est définie sur fixe? Problème: Considérez...La programmation Publié le 2025-02-07
-
Comment vérifier si un objet a un attribut spécifique dans Python?Méthode pour déterminer l'existence de l'attribut d'objet Cette enquête cherche une méthode pour vérifier la présence d'un att...La programmation Publié le 2025-02-07
-
Comment supprimer les emojis des chaînes dans Python: un guide pour débutant pour fixer les erreurs courantes?Suppression des emojis des chaînes dans python Le code python fourni pour supprimer les emojis échoue car il contient des erreurs de syntax. L...La programmation Publié le 2025-02-07
-
Comment puis-je installer MySQL sur Ubuntu sans invite de mot de passe?Installation non interactive de mysql sur ubuntu La méthode standard d'installation du serveur mysql sur ubuntu à l'aide de sudo apt-g...La programmation Publié le 2025-02-07
-
Comment réparer « Erreur générale : le serveur MySQL 2006 a disparu » lors de l'insertion de données ?Comment résoudre « Erreur générale : le serveur MySQL 2006 a disparu » lors de l'insertion d'enregistrementsIntroduction :L'insertion de d...La programmation Publié le 2025-02-07
-
Comment s'assurer que Hibernate conserve les valeurs d'énumération lors du mappage d'une colonne MySQL Enum?Préserver les valeurs d'énum dans HiberNate: dépannage de la mauvaise colonne dans le domaine de la persistance de données, en assurant la...La programmation Publié le 2025-02-07
-
Comment extraire du texte entre parenthèses efficacement en PHP en utilisant Regexphp: extraire du texte dans les parenthèses de manière optimale lors de l'extraction de texte enfermé entre parenthèses, il est essentiel ...La programmation Publié le 2025-02-07















Étudier le chinois
- 1 Comment dit-on « marcher » en chinois ? 走路 Prononciation chinoise, 走路 Apprentissage du chinois
- 2 Comment dit-on « prendre l’avion » en chinois ? 坐飞机 Prononciation chinoise, 坐飞机 Apprentissage du chinois
- 3 Comment dit-on « prendre un train » en chinois ? 坐火车 Prononciation chinoise, 坐火车 Apprentissage du chinois
- 4 Comment dit-on « prendre un bus » en chinois ? 坐车 Prononciation chinoise, 坐车 Apprentissage du chinois
- 5 Comment dire conduire en chinois? 开车 Prononciation chinoise, 开车 Apprentissage du chinois
- 6 Comment dit-on nager en chinois ? 游泳 Prononciation chinoise, 游泳 Apprentissage du chinois
- 7 Comment dit-on faire du vélo en chinois ? 骑自行车 Prononciation chinoise, 骑自行车 Apprentissage du chinois
- 8 Comment dit-on bonjour en chinois ? 你好Prononciation chinoise, 你好Apprentissage du chinois
- 9 Comment dit-on merci en chinois ? 谢谢Prononciation chinoise, 谢谢Apprentissage du chinois
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









