 Page de garde > La programmation > Utilisation des bibliothèques Python Faker et Pandas pour créer des données synthétiques à des fins de test
Page de garde > La programmation > Utilisation des bibliothèques Python Faker et Pandas pour créer des données synthétiques à des fins de test
Utilisation des bibliothèques Python Faker et Pandas pour créer des données synthétiques à des fins de test
 Parcourir:780
Parcourir:780
Introduction:
Des tests complets sont essentiels pour les applications basées sur les données, mais ils nécessitent souvent de disposer des bons ensembles de données, qui ne sont pas toujours disponibles. Que vous développiez des applications Web, des modèles d'apprentissage automatique ou des systèmes backend, des données réalistes et structurées sont essentielles pour une validation appropriée et garantir des performances robustes. L'acquisition de données réelles peut être limitée en raison de problèmes de confidentialité, de restrictions de licence ou simplement de l'indisponibilité des données pertinentes. C'est là que les données synthétiques deviennent précieuses.
Dans ce blog, nous explorerons comment Python peut être utilisé pour générer des données synthétiques pour différents scénarios, notamment :
- Tables interdépendantes : représentant des relations un-à-plusieurs.
- Données hiérarchiques : souvent utilisées dans les structures organisationnelles.
- Relations complexes : telles que les relations plusieurs-à-plusieurs dans les systèmes d'inscription.
Nous exploiterons les bibliothèques Faker et Pandas pour créer des ensembles de données réalistes pour ces cas d'utilisation.
Exemple 1 : Création de données synthétiques pour les clients et les commandes (relation un-à-plusieurs)
Dans de nombreuses applications, les données sont stockées dans plusieurs tables avec des relations de clé étrangère. Générons des données synthétiques pour les clients et leurs commandes. Un client peut passer plusieurs commandes, ce qui représente une relation un-à-plusieurs.
Génération de la table Clients
La table Clients contient des informations de base telles que l'ID client, le nom et l'adresse e-mail.
import pandas as pd
from faker import Faker
import random
fake = Faker()
def generate_customers(num_customers):
customers = []
for _ in range(num_customers):
customer_id = fake.uuid4()
name = fake.name()
email = fake.email()
customers.append({'CustomerID': customer_id, 'CustomerName': name, 'Email': email})
return pd.DataFrame(customers)
customers_df = generate_customers(10)
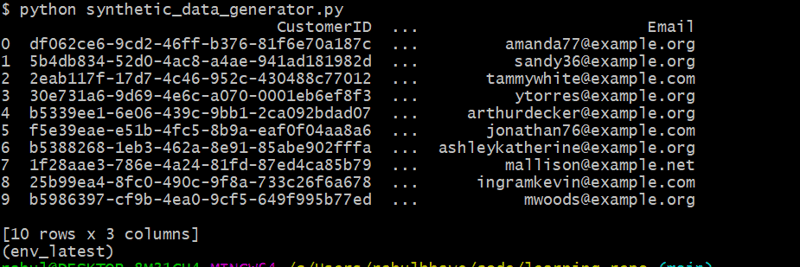
Ce code génère 10 clients aléatoires en utilisant Faker pour créer des noms et des adresses e-mail réalistes.
Génération du tableau des commandes
Maintenant, nous générons la table Commandes, où chaque commande est associée à un client via CustomerID.
def generate_orders(customers_df, num_orders):
orders = []
for _ in range(num_orders):
order_id = fake.uuid4()
customer_id = random.choice(customers_df['CustomerID'].tolist())
product = fake.random_element(elements=('Laptop', 'Phone', 'Tablet', 'Headphones'))
price = round(random.uniform(100, 2000), 2)
orders.append({'OrderID': order_id, 'CustomerID': customer_id, 'Product': product, 'Price': price})
return pd.DataFrame(orders)
orders_df = generate_orders(customers_df, 30)
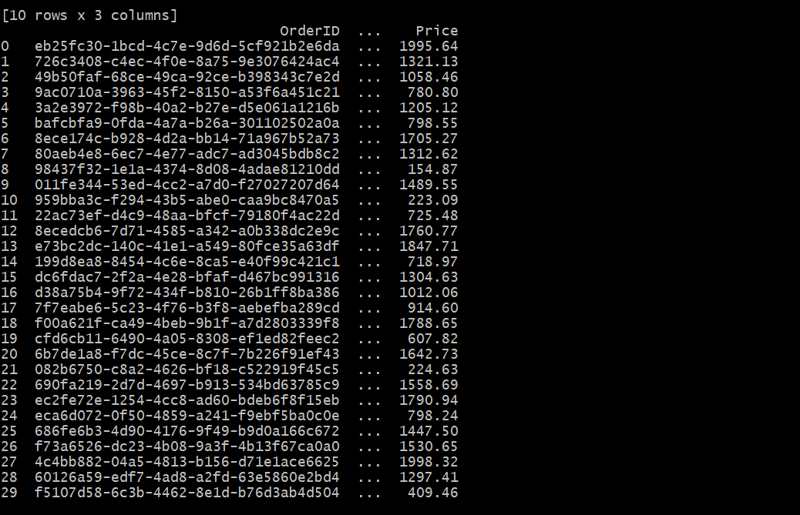
Dans ce cas, la table Commandes relie chaque commande à un client à l'aide du CustomerID. Chaque client peut passer plusieurs commandes, formant ainsi une relation un-à-plusieurs.
Exemple 2 : Génération de données hiérarchiques pour les départements et les employés
Les données hiérarchiques sont souvent utilisées dans les contextes organisationnels, où les départements comptent plusieurs employés. Simulons une organisation avec des départements, chacun comptant plusieurs employés.
Génération de la table des départements
La table Départements contient l'ID de service, le nom et le responsable uniques de chaque département.
def generate_departments(num_departments):
departments = []
for _ in range(num_departments):
department_id = fake.uuid4()
department_name = fake.company_suffix()
manager = fake.name()
departments.append({'DepartmentID': department_id, 'DepartmentName': department_name, 'Manager': manager})
return pd.DataFrame(departments)
departments_df = generate_departments(10)
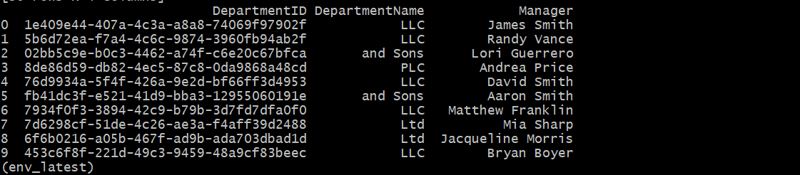
Génération de la table des employés
Ensuite, nous générons l'Employeestable, où chaque employé est associé à un service via DepartmentID.
def generate_employees(departments_df, num_employees):
employees = []
for _ in range(num_employees):
employee_id = fake.uuid4()
employee_name = fake.name()
email = fake.email()
department_id = random.choice(departments_df['DepartmentID'].tolist())
salary = round(random.uniform(40000, 120000), 2)
employees.append({
'EmployeeID': employee_id,
'EmployeeName': employee_name,
'Email': email,
'DepartmentID': department_id,
'Salary': salary
})
return pd.DataFrame(employees)
employees_df = generate_employees(departments_df, 100)
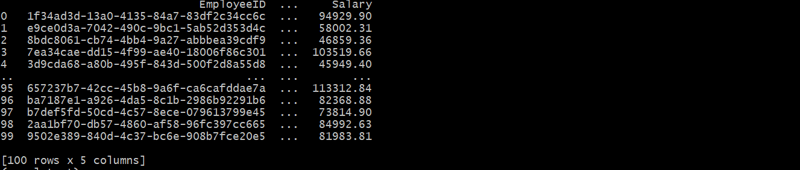
Cette structure hiérarchique relie chaque employé à un département via DepartmentID, formant une relation parent-enfant.
Exemple 3 : simulation de relations plusieurs-à-plusieurs pour les inscriptions à des cours
Dans certains scénarios, il existe des relations plusieurs-à-plusieurs, dans lesquelles une entité est liée à plusieurs autres. Simulons cela avec des étudiants s'inscrivant à plusieurs cours, où chaque cours compte plusieurs étudiants.
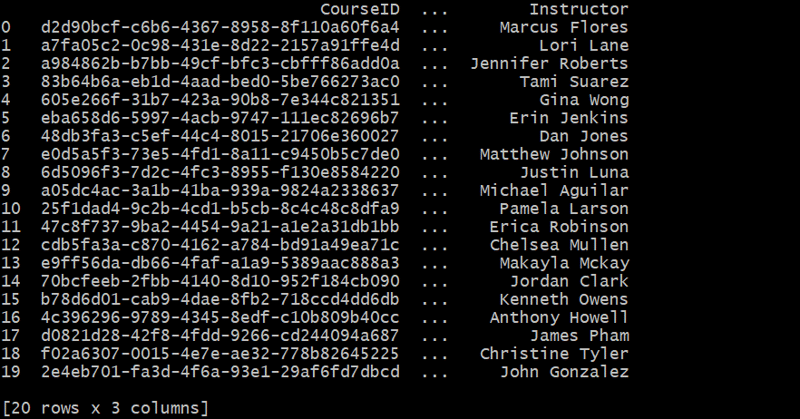
Génération du tableau des cours
def generate_courses(num_courses):
courses = []
for _ in range(num_courses):
course_id = fake.uuid4()
course_name = fake.bs().title()
instructor = fake.name()
courses.append({'CourseID': course_id, 'CourseName': course_name, 'Instructor': instructor})
return pd.DataFrame(courses)
courses_df = generate_courses(20)
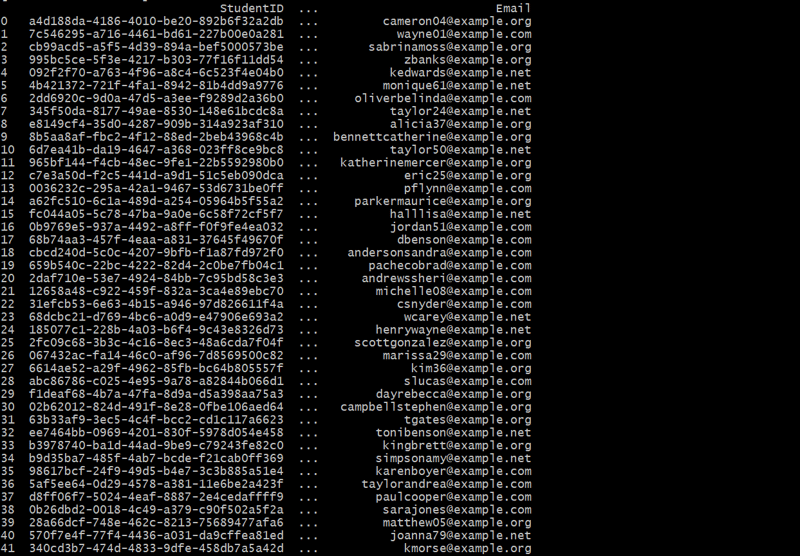
Génération de la table des étudiants
def generate_students(num_students):
students = []
for _ in range(num_students):
student_id = fake.uuid4()
student_name = fake.name()
email = fake.email()
students.append({'StudentID': student_id, 'StudentName': student_name, 'Email': email})
return pd.DataFrame(students)
students_df = generate_students(50)
print(students_df)
Génération du tableau des inscriptions aux cours
Le tableau CourseEnrollments capture la relation plusieurs-à-plusieurs entre les étudiants et les cours.
def generate_course_enrollments(students_df, courses_df, num_enrollments):
enrollments = []
for _ in range(num_enrollments):
enrollment_id = fake.uuid4()
student_id = random.choice(students_df['StudentID'].tolist())
course_id = random.choice(courses_df['CourseID'].tolist())
enrollment_date = fake.date_this_year()
enrollments.append({
'EnrollmentID': enrollment_id,
'StudentID': student_id,
'CourseID': course_id,
'EnrollmentDate': enrollment_date
})
return pd.DataFrame(enrollments)
enrollments_df = generate_course_enrollments(students_df, courses_df, 200)
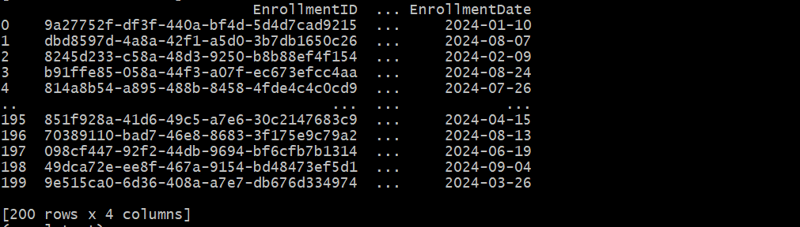
Dans cet exemple, nous créons une table de liaison pour représenter les relations plusieurs-à-plusieurs entre les étudiants et les cours.
Conclusion:
En utilisant Python et des bibliothèques comme Faker et Pandas, vous pouvez générer des ensembles de données synthétiques réalistes et diversifiés pour répondre à une variété de besoins de tests. Dans ce blog, nous avons couvert :
- Tableaux interdépendants : démontrant une relation un-à-plusieurs entre les clients et les commandes.
- Données hiérarchiques : illustrant une relation parent-enfant entre les départements et les employés.
- Relations complexes : simulation de relations plusieurs-à-plusieurs entre les étudiants et les cours.
Ces exemples jettent les bases de la génération de données synthétiques adaptées à vos besoins. D'autres améliorations, telles que la création de relations plus complexes, la personnalisation des données pour des bases de données spécifiques ou la mise à l'échelle d'ensembles de données pour les tests de performances, peuvent faire passer la génération de données synthétiques à un niveau supérieur.
Ces exemples fournissent une base solide pour générer des données synthétiques. Cependant, d'autres améliorations peuvent être apportées pour accroître la complexité et la spécificité, telles que :
- Données spécifiques à la base de données : personnalisation de la génération de données pour différents systèmes de bases de données (par exemple, SQL ou NoSQL).
- Relations plus complexes : création d'interdépendances supplémentaires, telles que des relations temporelles, des hiérarchies à plusieurs niveaux ou des contraintes uniques.
- Mise à l'échelle des données : génération d'ensembles de données plus volumineux pour les tests de performances ou les tests de résistance, garantissant que le système peut gérer les conditions du monde réel à grande échelle. En générant des données synthétiques adaptées à vos besoins, vous pouvez simuler des conditions réalistes pour développer, tester et optimiser des applications sans avoir recours à des ensembles de données sensibles ou difficiles à acquérir.
Si vous aimez l'article, partagez-le avec vos amis et collègues. Vous pouvez me contacter sur LinkedIn pour discuter d'autres idées.
-
 Les paramètres de modèle dans la fonction consévale C ++ 20 peuvent-ils dépendre des paramètres de fonction?Fonctions et paramètres de modèle constitutifs dépendants des arguments de fonction En C Compile-Time. C 20 Fonctions Consévales C 20 in...La programmation Publié le 2025-07-02
Les paramètres de modèle dans la fonction consévale C ++ 20 peuvent-ils dépendre des paramètres de fonction?Fonctions et paramètres de modèle constitutifs dépendants des arguments de fonction En C Compile-Time. C 20 Fonctions Consévales C 20 in...La programmation Publié le 2025-07-02 -
Comment puis-je maintenir le rendu de cellules JTable personnalisé après l'édition de cellules?En maintenant le rendu de cellules JTable après la modification de cellule dans un JTable, implémentant les capacités de rendu et d'éditio...La programmation Publié le 2025-07-02
-
Pourquoi mon image d'arrière-plan CSS apparaît-elle?Troubleshoot: Image d'arrière-plan CSS n'apparaissant pas Vous avez rencontré un problème où votre image d'arrière-plan échoue mal...La programmation Publié le 2025-07-02
-
Comment pouvez-vous utiliser des données de groupe par pour pivoter dans MySQL?Pivoting des résultats de la requête en utilisant le groupe mysql par Dans une base de données relationnelle, les données pivotant se réfèrent...La programmation Publié le 2025-07-02
-
FIT OBJET: la couverture échoue dans IE et Edge, comment réparer?objet-fit: la couverture échoue dans IE et Edge, comment corriger? Utilisation d'objet-fit: couverture; Dans CSS pour maintenir la hauteur...La programmation Publié le 2025-07-02
-
Comment empêcher les soumissions en double après la rafraîchissement du formulaire?Empêcher les soumissions en double avec une manipulation de rafraîchissement dans le développement Web, il est courant d'informer le probl...La programmation Publié le 2025-07-02
-
Méthode pour convertir correctement les caractères Latin1 en UTF8 dans UTF8 MySQL TableConvertir les caractères latins1 dans une table utf8 en utf8 Vous avez rencontré un problème où les caractères avec diacritique (par exemple, ...La programmation Publié le 2025-07-02
-
Conseils pour trouver la position d'élément dans Java ArrayRécupération de la position de l'élément dans les tableaux java dans la classe des tableaux de Java, il n'y a pas de méthode directe &...La programmation Publié le 2025-07-02
-
Pourquoi les images affichent-elles des images à l'aide de la propriété CSS «Content»?Affichage des images avec URL de contenu dans Firefox Un problème a été rencontré lorsque certains navigateurs, spécifiquement Firefox, n'...La programmation Publié le 2025-07-02
-
Comment rediriger plusieurs types d'utilisateurs (étudiants, enseignants et administrateurs) vers leurs activités respectives dans une application Firebase?Red: comment rediriger plusieurs types d'utilisateurs vers des activités respectives Comprendre le problème dans une application de vo...La programmation Publié le 2025-07-02
-
Async void vs tâche asynchrone dans ASP.NET: Pourquoi la méthode asynchrone void lance-t-elle parfois des exceptions?Comprendre la distinction entre la tâche asynchrone void et asynchrone dans asp.net dans les applications ASP.net, le programme asynchronique ...La programmation Publié le 2025-07-02
-
Comment éviter les fuites de mémoire lors de la tranchage du langage GO?la fuite de la mémoire dans les tranches go Comprendre les fuites de mémoire dans les tranches de go peut être un défi. Cet article vise à app...La programmation Publié le 2025-07-02
-
Comment implémenter une fonction de hachage générique pour les tuples dans les collections non ordonnées?Fonction de hachage générique pour les tuples dans les collections non ordonnées Le std :: non ordonné_map et std :: non ordonné les conteneur...La programmation Publié le 2025-07-02
-
Comment Java's Map.Entry et SimpleEntry simplifient la gestion des paires de valeurs clés?Une collection complète pour les paires de valeur: introduisant la carte de Java.Entry et SimpleEntry dans Java, lors de la définition d'u...La programmation Publié le 2025-07-02
-
Comment puis-je styliser la première instance d'un type d'élément spécifique sur un document HTML entier?correspondant au premier élément d'un certain type dans tout le document Styling Le premier élément d'un type spécifique à travers un...La programmation Publié le 2025-07-02















Étudier le chinois
- 1 Comment dit-on « marcher » en chinois ? 走路 Prononciation chinoise, 走路 Apprentissage du chinois
- 2 Comment dit-on « prendre l’avion » en chinois ? 坐飞机 Prononciation chinoise, 坐飞机 Apprentissage du chinois
- 3 Comment dit-on « prendre un train » en chinois ? 坐火车 Prononciation chinoise, 坐火车 Apprentissage du chinois
- 4 Comment dit-on « prendre un bus » en chinois ? 坐车 Prononciation chinoise, 坐车 Apprentissage du chinois
- 5 Comment dire conduire en chinois? 开车 Prononciation chinoise, 开车 Apprentissage du chinois
- 6 Comment dit-on nager en chinois ? 游泳 Prononciation chinoise, 游泳 Apprentissage du chinois
- 7 Comment dit-on faire du vélo en chinois ? 骑自行车 Prononciation chinoise, 骑自行车 Apprentissage du chinois
- 8 Comment dit-on bonjour en chinois ? 你好Prononciation chinoise, 你好Apprentissage du chinois
- 9 Comment dit-on merci en chinois ? 谢谢Prononciation chinoise, 谢谢Apprentissage du chinois
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









