 Page de garde > La programmation > Pourquoi j'ai créé une alternative légère aux mini-ressorts et comment je l'ai fait
Page de garde > La programmation > Pourquoi j'ai créé une alternative légère aux mini-ressorts et comment je l'ai fait
Pourquoi j'ai créé une alternative légère aux mini-ressorts et comment je l'ai fait
 Parcourir:878
Parcourir:878
Dans ce petit article je vais essayer de vous expliquer pourquoi j'ai créé cette bibliothèque ? et comment est-il mis en œuvre ?
pourquoi j'ai créé cette bibliothèque ?
J'ai travaillé avec le framework Java EE sur de nombreux projets et dans la plupart d'entre eux, il n'y avait aucune limitation sur les ressources disponibles pour exécuter l'application, mais dans de rares cas, nous avions des ressources limitées, notamment la mémoire pour déployer l'application sur un service de déploiement. , ainsi, lorsque l'application dépasse la limite, le service de déploiement ralentira d'abord l'application, puis s'il continue, le service l'arrêtera. Nous utilisions l'ancien framework Spring sans même Spring Boot, nous avons essayé d'utiliser une bibliothèque différente mais la différence était minime et sans valeur, et c'est là que l'idée de créer une alternative Spring légère axée sur la réduction autant que possible de la consommation de mémoire a commencé. .
Je n'avais que deux objectifs en tête lorsque j'ai commencé à concevoir la bibliothèque :
1 - réduire au maximum la consommation de mémoire
2 - essayez d'utiliser autant que possible l'API Java EE existante pour faciliter la transition vers la bibliothèque du point de vue de l'apprentissage et de la complexité de la transition en elle-même.
et avec ces 2 objectifs j'ai réussi à réduire l'empreinte mémoire d'une de mes applications d'environ 40% et à rendre la transition facile et rapide puisqu'elle est similaire aux solutions existantes.
Comment j'ai créé cette bibliothèque ?
Voici le référentiel GitHub pour que vous puissiez vérifier le code pendant la lecture.
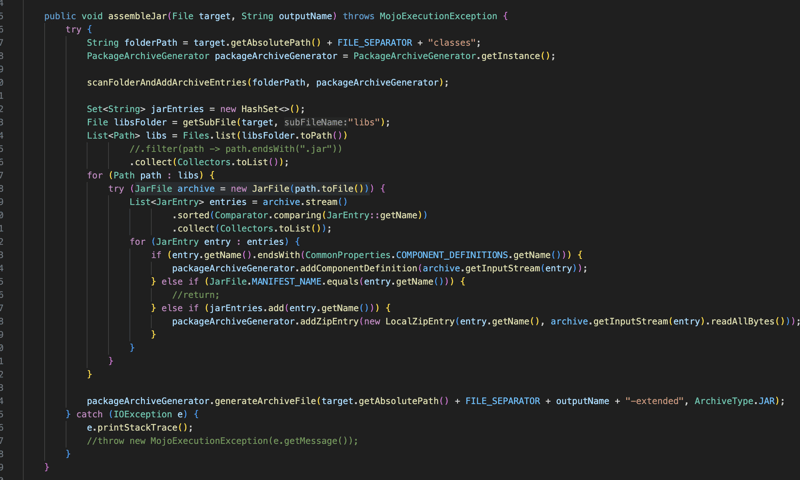
La bibliothèque dans son ensemble comporte de nombreuses parties (capture d'écran ci-dessous), la majeure partie de l'implémentation dans le module principal qui est également divisée en trois types de modules indépendants : Core, JPA, Web. Les modules App sont principalement destinés à l'intégration, le module Plugin est un plugin Maven pour aider à créer les fichiers nécessaires dans l'archive du package pour que la bibliothèque fonctionne correctement
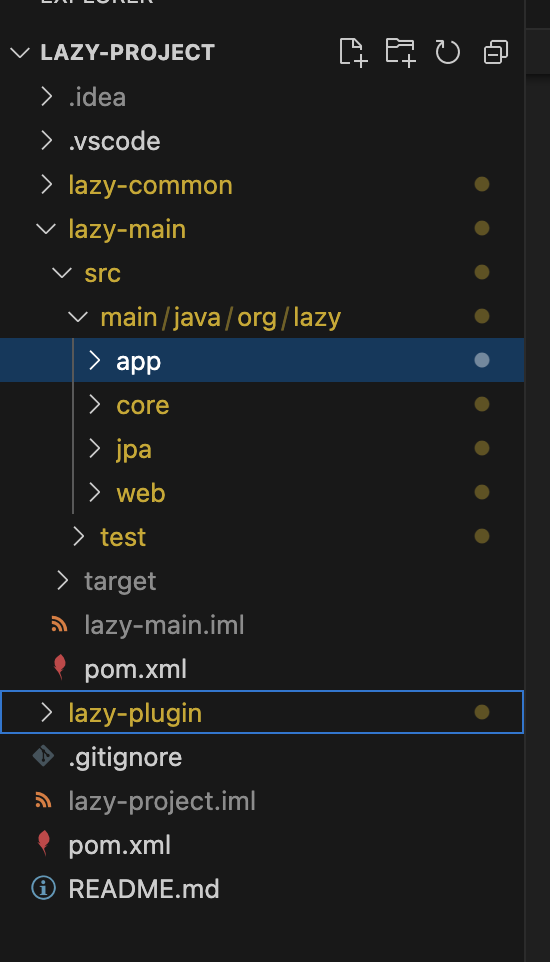
Module de base
Nous allons donc commencer par le module principal qui, comme son nom l'indique, contient la fonctionnalité principale de la bibliothèque qui est l'injection de dépendances ou l'inversion de contrôle.
Afin d'obtenir cette fonctionnalité, il faut d'abord analyser le chemin de classe de l'application pendant la phase de compilation pour toutes les classes annotées que la bibliothèque doit gérer pour créer des définitions de composants pour les classes annotées.
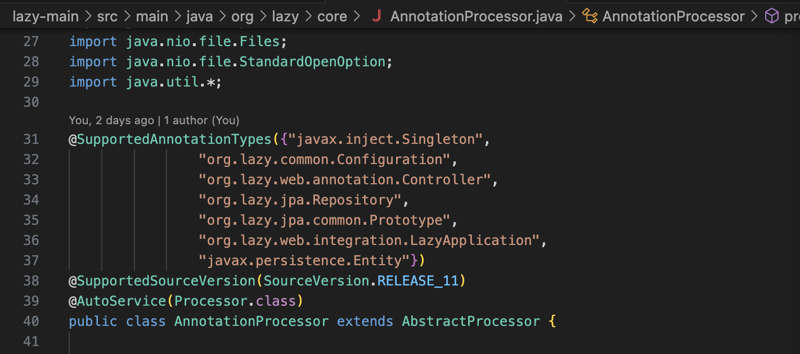
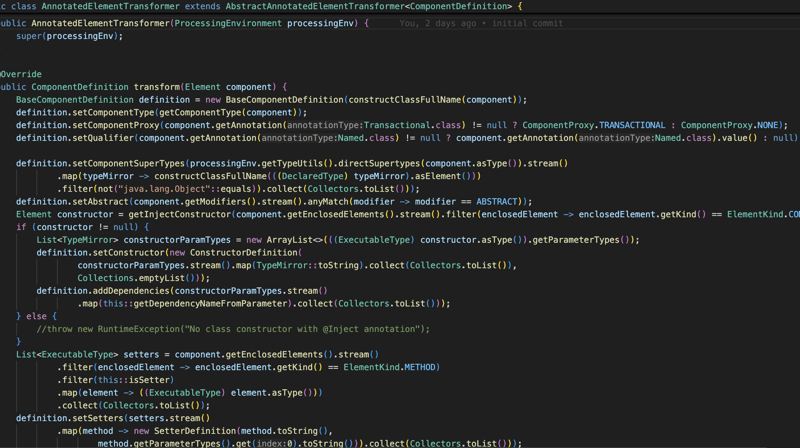
La définition du composant contient essentiellement toutes les informations dont nous aurons besoin pour instancier un objet de cette classe plus tard, comme les informations du constructeur, s'il existe des setters avec une annotation inject (seules les injections de constructeur et de setter sont prises en charge) si la classe a une interface ou étendre une autre classe, nous aurons toutes les informations dont nous avons besoin pour créer un objet à partir de cette classe (capture d'écran ci-dessous).
Et puis, après avoir analysé toutes les annotations du chemin de classe et créé toutes les définitions de composants dont nous avons besoin, nous les stockerons dans le chemin de classe en tant que fichier JSON.
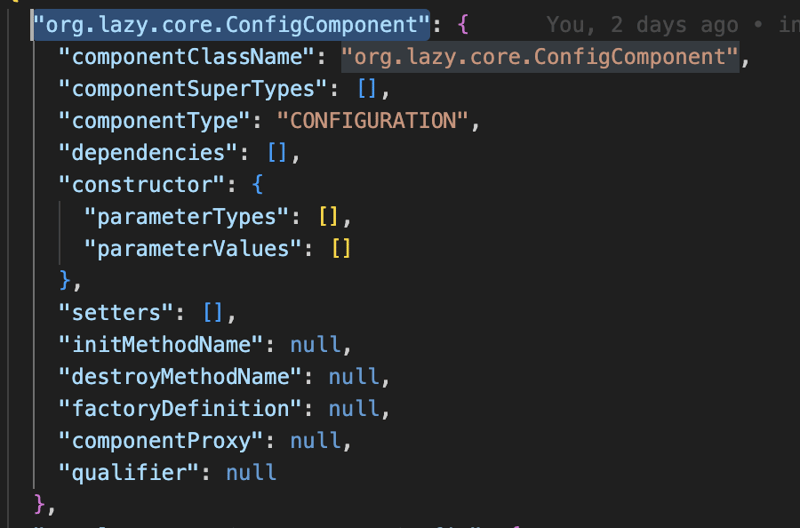
La deuxième et principale fonctionnalité du module principal est l'injection de dépendances et l'inversion du contrôle qui sont basées sur le modèle de conception d'usine. Nous avons donc l'interface ApplicationContext qui, en elle-même, étend automatiquement la ComponentFactory et la méthode principale de cette interface est la méthode getComponent qui renverra l'objet à partir du nom du composant.
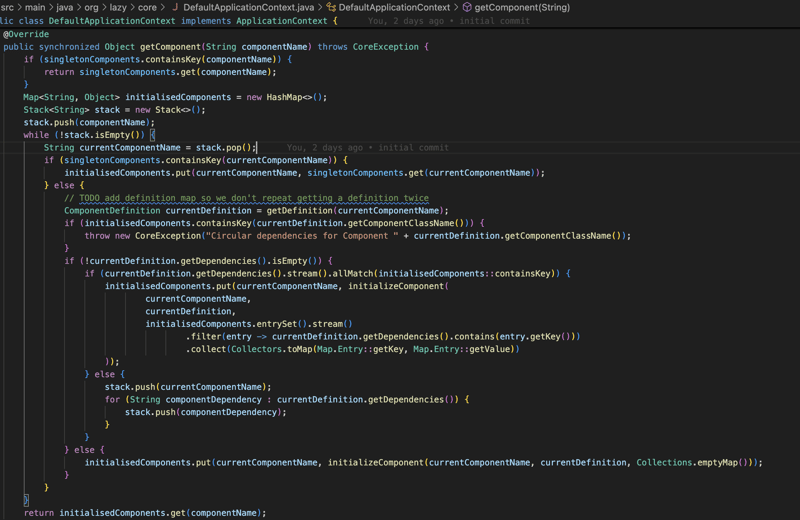
Comme vous pouvez le voir dans la capture d'écran ci-dessus, nous essayons d'abord de vérifier si le composant existe dans les composants Singleton déjà initialisés, si ce n'est pas le cas, nous commençons par obtenir la définition du composant à partir du fichier JSON puis nous démarrons la boucle while pour récupérez toutes les dépendances du composant avant de transmettre la définition du composant et ses dépendances à l'assembleur du composant pour obtenir un objet complet prêt à être injecté.
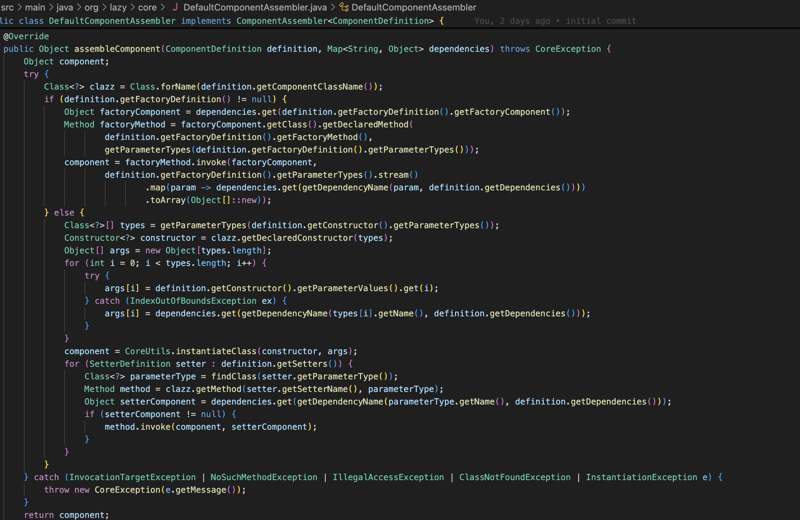
Module JPA
L'implémentation du module JPA est très similaire à Spring Data JPA mais très minime, la raison pour laquelle elle est très similaire parce que j'ai utilisé Spring Data dans de nombreux projets et je l'ai trouvé facile à utiliser et comme je l'ai dit avant, je voulais la transition vers le bibliothèque pour être fluide et nécessiter moins de travail autant que possible, donc implémenter ma propre version de données mini Spring était le meilleur choix.
L'implémentation concerne l'interface JpaRepository qui contient les opérations les plus courantes pour la base de données comme sauvegarder, supprimer et trouverTout... et pour utiliser le module JPA, vous devez étendre cette interface et fournir l'entité que cette interface doit gérer et c'est l'identifiant, puis après avoir étendu l'interface et annoté avec l'annotation Repository, vous pouvez définir vos méthodes et les annoter avec l'annotation Query et fournir la requête JPQL, puis la bibliothèque lors de la phase de compilation créera une classe entièrement fonctionnelle qui implémentera cette interface.
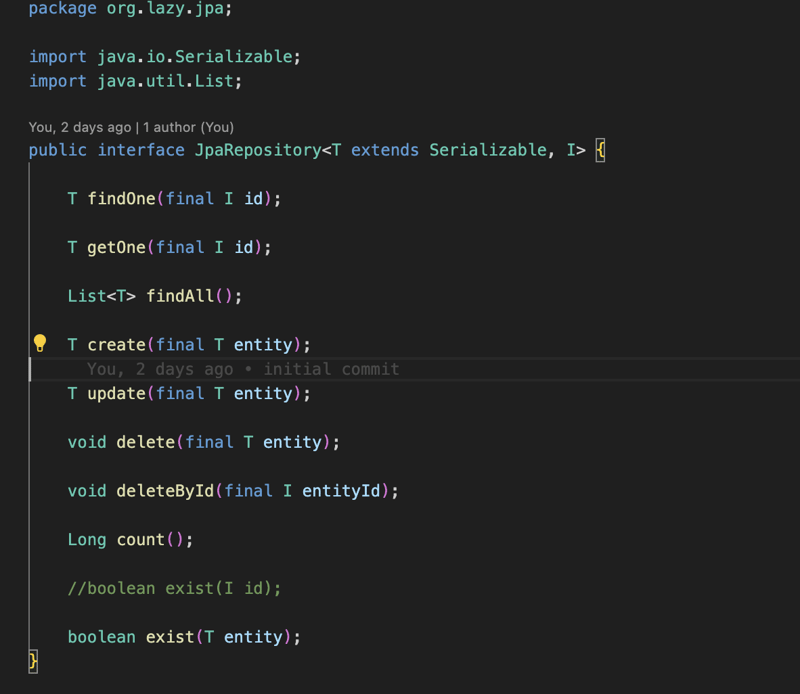
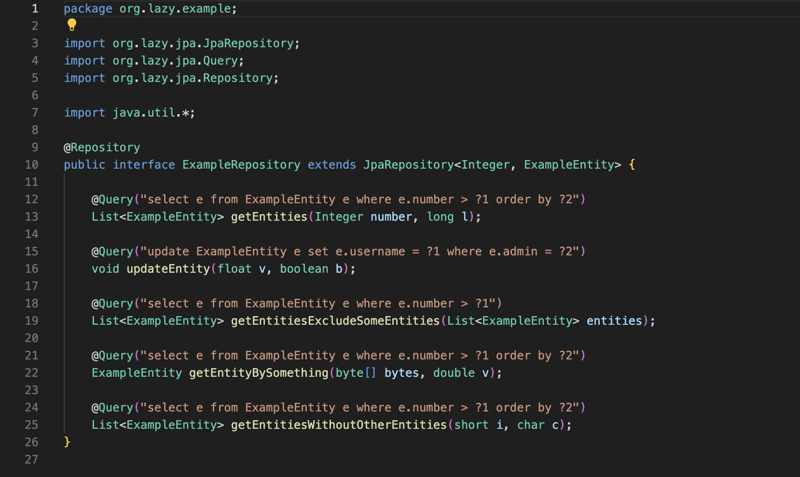
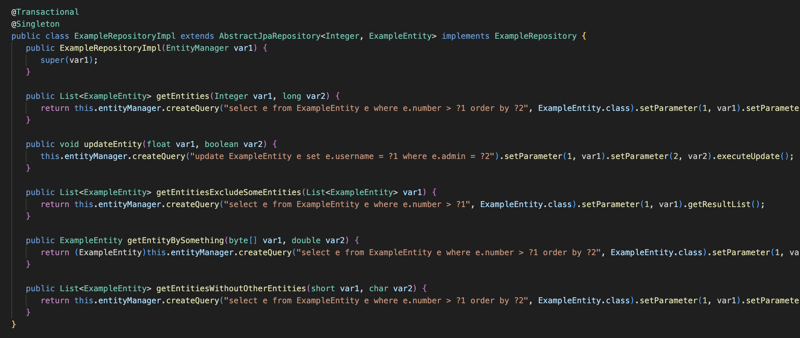
La bibliothèque gérera également la partie transactionnelle de l'application, donc toute l'interface du référentiel et toute classe annotée avec transactionnel seront gérées par la bibliothèque du point de vue des transactions. ainsi, pour tout composant transactionnel, la bibliothèque créera un proxy pour gérer la transaction en fonction de l'annotation Transactional et gérera également le cycle de vie du gestionnaire d'entités.
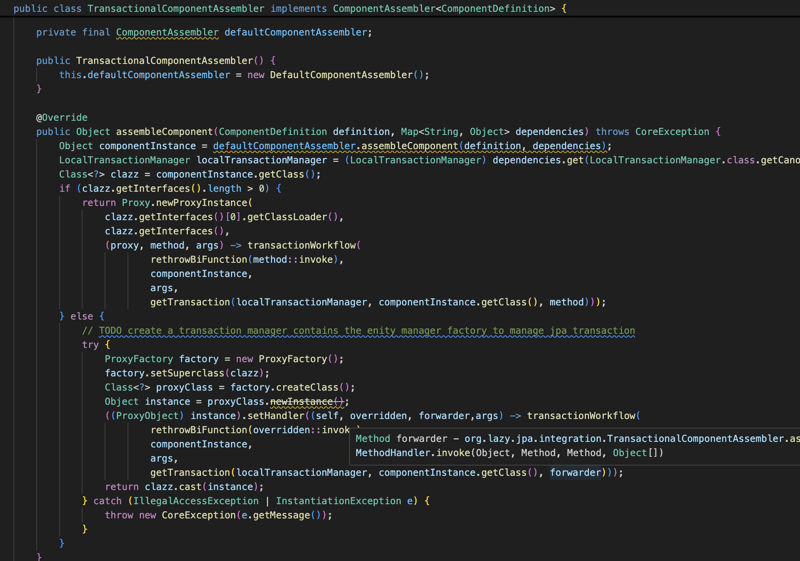
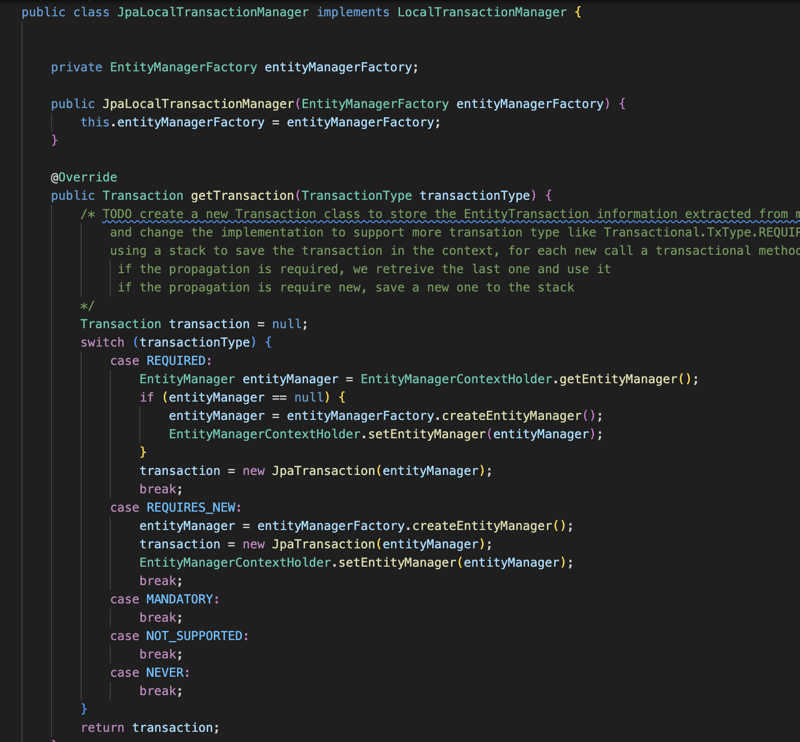
Module Web
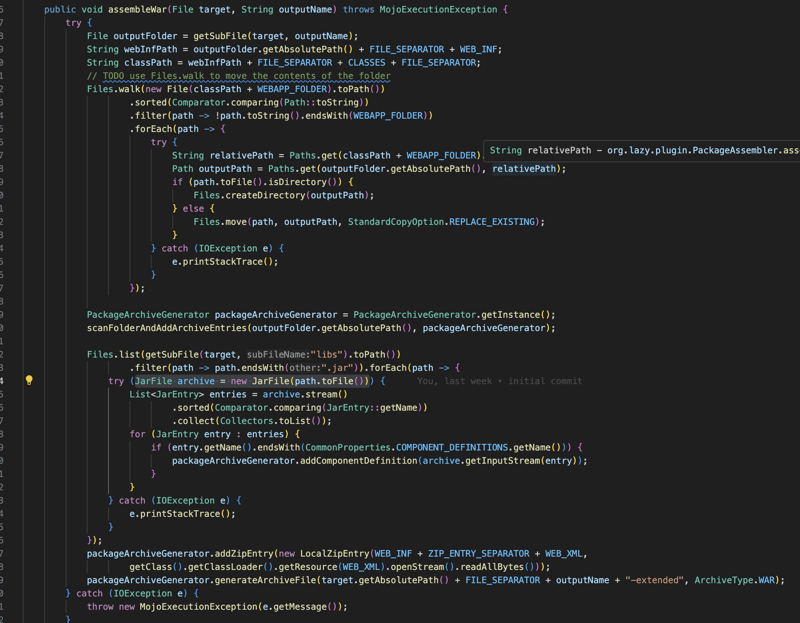
Le modèle Web est responsable de la gestion de toute la partie Web de l'application et, de par sa conception, il s'agit d'un module indépendant, ce qui signifie qu'il peut être utilisé indépendamment du reste des modules de la bibliothèque. Comme d'habitude, son utilisation est très similaire à celle de certains bibliothèque Java EE familière comme Spring Web ou Jax-rs.
L'implémentation est basée sur l'annotation, vous avez des classes annotées avec l'annotation Controller et à l'intérieur de ce contrôleur, vous trouverez une méthode annotée avec PathMapping et ces méthodes géreront un chemin spécifique ou spécifique demande basée sur certains critères comme le type de demande, le type de contenu...
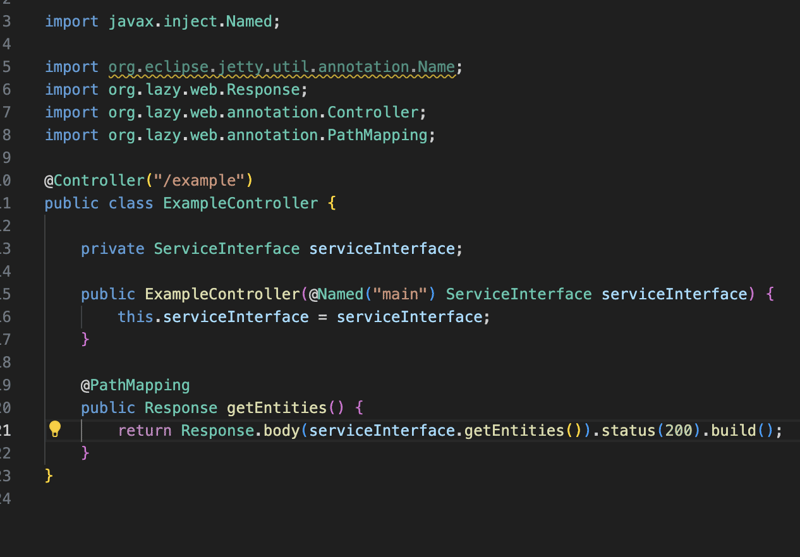
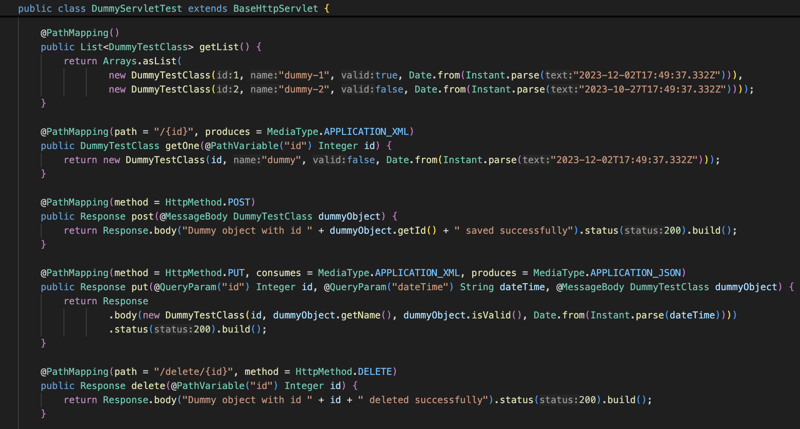
De l'extérieur, cela ressemblera beaucoup à l'autre bibliothèque, mais de l'intérieur, c'est différent car la bibliothèque modifiera ces classes Controller au moment de l'exécution pour qu'elles étendent toutes le BaseHttpServlet , qui étend également le HttpServlet et fonctionnera comme un servlet standard.
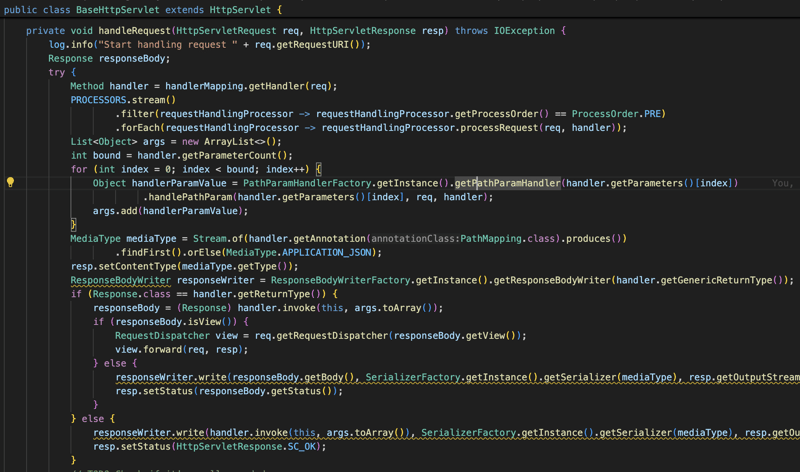
Comme vous pouvez le voir dans la capture d'écran ci-dessus, nous initialisons d'abord le composant dans la méthode init pour injecter toutes les dépendances à l'aide du WebApplicationContext, puis nous traiterons toutes les requêtes. venant sur ce contrôleur en utilisant la méthode handleRequest, avec cette approche, nous utiliserons l'API de servlet existante pour gérer les contrôleurs, cela aidera à maintenir l'empreinte mémoire faible et également à réduire la surcharge puisque la bibliothèque agit comme un plugin pour compléter le travail de l'API du servlet.
Tout d'abord, nous essayons de mapper la requête à la bonne méthode et après cela, nous essayons d'injecter toutes les informations demandées à l'intérieur de la méthode en obtenant les informations soit à partir du contexte, soit du HttpServletRequest comme la requête paramètre ou en-têtes ou variable de chemin ou le corps de la requête...
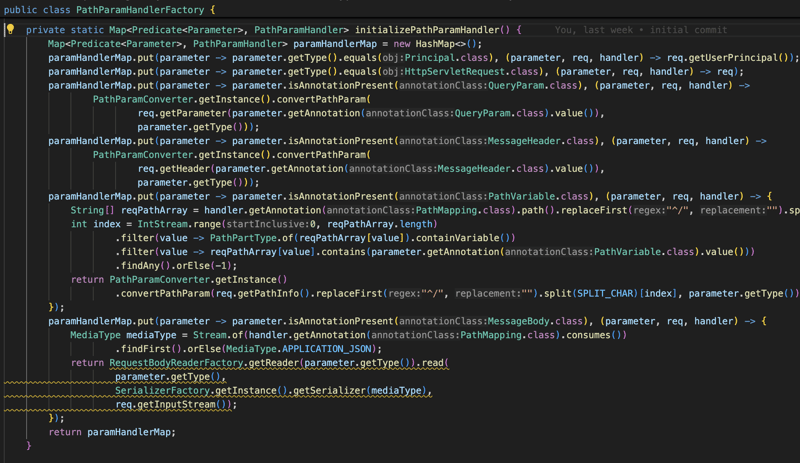
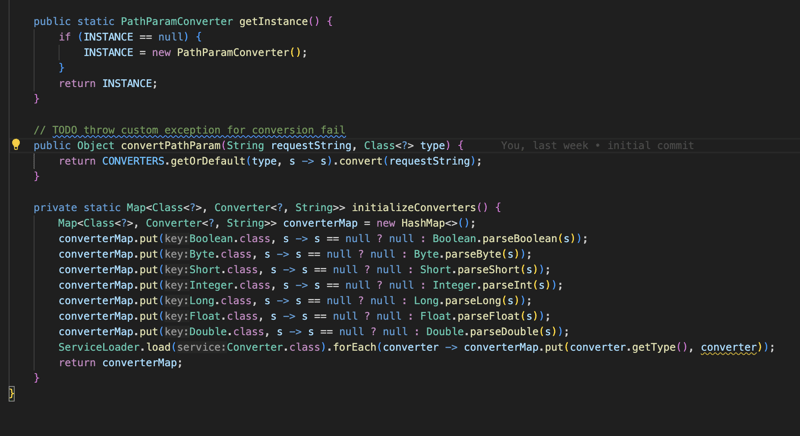
Nous convertissons toutes ces informations puis les injectons en tant que paramètre dans la méthode lorsqu'elle est demandée, puis nous exécutons la méthode et convertissons le résultat ou le résultat en fonction du PathMapping produit ou du type de contenu (par par défaut, c'est application/Json), puis nous écrivons le contenu dans HttpServletResponse.
Enfin, si quelque chose ne va pas dans le processus et qu'une erreur est générée, nous captons cette erreur ou l'exception et nous essayons de la gérer en fonction du type de l'exception, nous avons un gestionnaire d'exception pour gérer différents types d'exception et le l'utilisateur peut également fournir davantage de gestionnaires pour gérer toute exception comme il le souhaite.
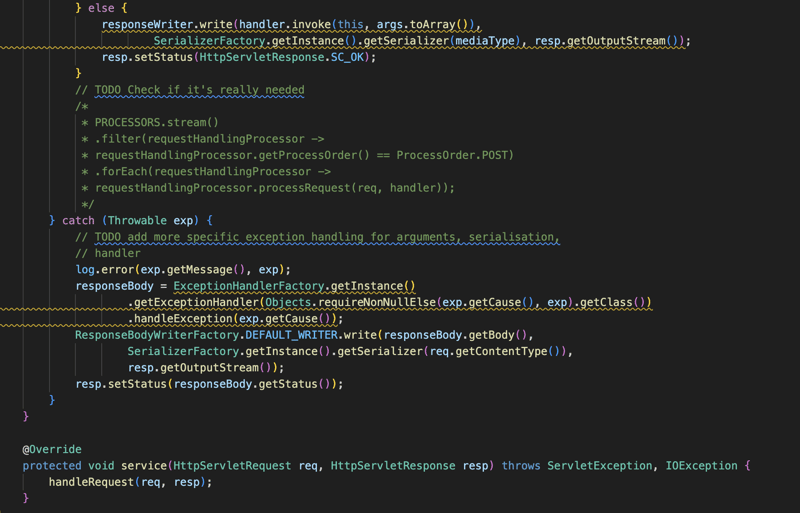
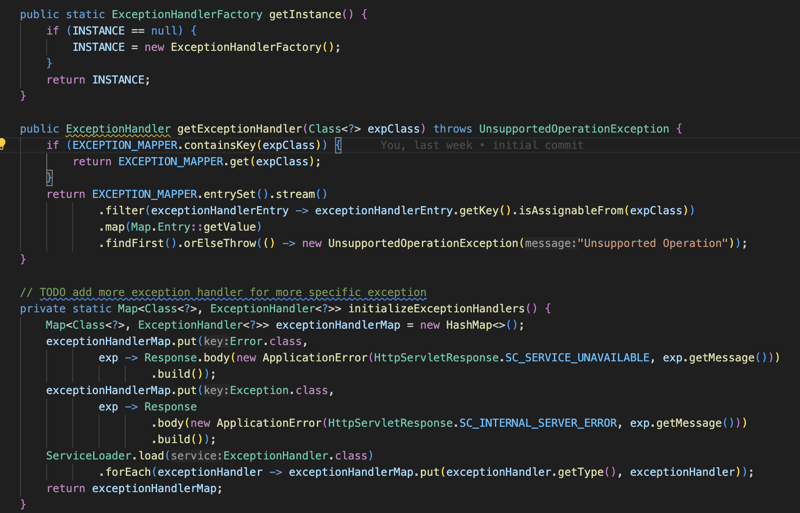
Plugin Maven
La dernière et importante partie est le plugin maven qui créera tous les fichiers nécessaires au bon fonctionnement de l'application et également à la construction du package jar ou war.
Tout d'abord, le plugin analysera le chemin de classe et les dépendances pour rechercher les fichiers component-definitions-json, à partir de ces fichiers, il générera :
lazy-application.json : contient tous les composants et leurs dépendances pour l'application
lazy-application.properties : contient la liste des contrôleurs et des entités afin que nous n'ayons pas besoin d'analyser le chemin de classe au moment de l'exécution.
et enfin, si l'emballage est en pot, nous obtiendrons la classe principale.
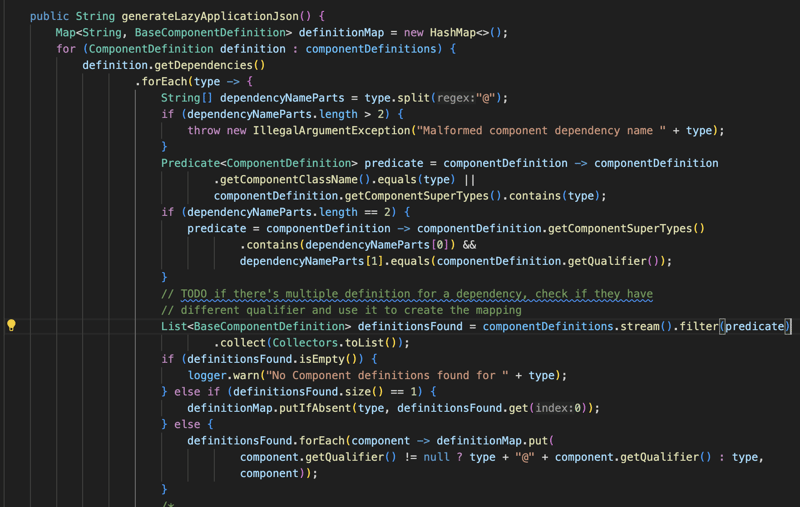
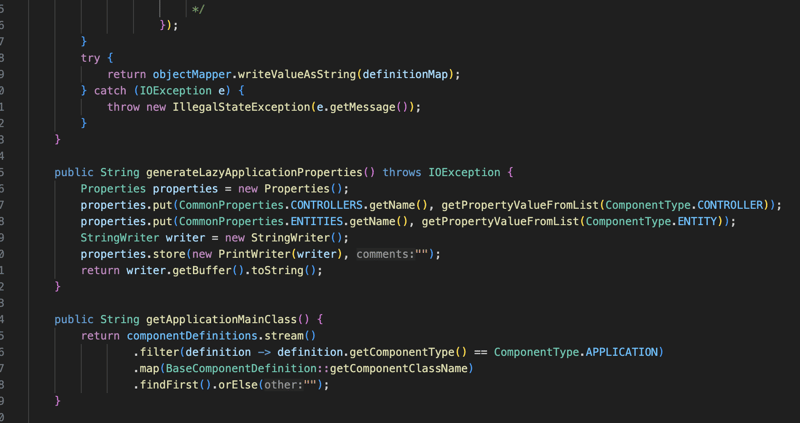
et enfin, nous construisons le fichier d'archive du package qui contiendra le code de l'application avec ses dépendances et les fichiers que nous avons générés à l'étape précédente.
J'ai essayé de ne pas entrer dans les détails pour garder les articles courts et pas si compliqués à comprendre, bien sûr, le code est disponible sur GitHub afin que vous puissiez également jouer avec. Si vous avez des questions, déposez-les ci-dessous et j'essaierai pour y répondre.
-
 Pouvez-vous utiliser CSS pour colorer la sortie de la console dans Chrome et Firefox?Affichage des couleurs dans la console javascrip Messages? Réponse Oui, il est possible d'utiliser CSS pour ajouter des couleurs aux me...La programmation Publié le 2025-04-08
Pouvez-vous utiliser CSS pour colorer la sortie de la console dans Chrome et Firefox?Affichage des couleurs dans la console javascrip Messages? Réponse Oui, il est possible d'utiliser CSS pour ajouter des couleurs aux me...La programmation Publié le 2025-04-08 -
Comment puis-je configurer Pytesseract pour une reconnaissance à un chiffre avec une sortie numéro uniquement?Pytesseract OCR avec une reconnaissance à un chiffre unique et des contraintes de numéro uniquement dans le contexte de Pytesseract, la config...La programmation Publié le 2025-04-08
-
Pourquoi le corps {marge: 0; } `Supprimez toujours la marge supérieure dans CSS?Addressant la suppression de la marge du corps dans CSS pour les développeurs Web novices, la suppression de la marge de l'élément corpore...La programmation Publié le 2025-04-08
-
Pourquoi mon code GO renvoie-t-il "Exit Status 1" lorsque vous utilisez exec.command?Débogage "Exit Status 1" Erreur dans Go's exec.command Lors de la rencontre de l'erreur "Exit Status 1" tout en ex...La programmation Publié le 2025-04-08
-
Comment capturer et diffuser Stdout en temps réel pour l'exécution de la commande chatbot?Capturant stdout en temps réel à partir de l'exécution de commandes dans le domaine de l'élaboration de chatbots capables d'exécut...La programmation Publié le 2025-04-08
-
Comment insérer correctement les blobs (images) dans MySQL à l'aide de PHP?Insérez des blobs dans les bases de données MySQL avec PHP Lorsque vous essayez de stocker une image dans une base de données MySQL, vous pou...La programmation Publié le 2025-04-08
-
Comment puis-je associer par programme une extension de fichier avec mon application sous Windows sans utiliser un installateur?Associer les extensions de fichiers à l'application ] Lors du développement d'applications qui modifient un type de fichier spécifique,...La programmation Publié le 2025-04-08
-
Comment créer une animation CSS à gauche à gauche en douceur pour une div dans son conteneur?Animation CSS générique pour le mouvement gauche-droit Dans cet article, nous explorerons la création d'une animation CSS générique pour d...La programmation Publié le 2025-04-08
-
Comment télécharger des fichiers avec des paramètres supplémentaires à l'aide de java.net.urlconnection et de codage multipart / formulaire de formulaire?Téléchargement des fichiers avec des demandes http pour télécharger des fichiers sur un serveur http tout en soumettant des paramètres supplém...La programmation Publié le 2025-04-08
-
Comment supprimer proprement les gestionnaires d'événements JavaScript anonymes?supprimer les auditeurs d'événements anonymes Ajouter des auditeurs d'événements anonymes aux éléments offre une flexibilité et une simp...La programmation Publié le 2025-04-08
-
Comment extraire un élément aléatoire d'un tableau en PHP?sélection aléatoire à partir d'un tableau en php, l'obtention d'un élément aléatoire à partir d'un tableau peut être accompli av...La programmation Publié le 2025-04-08
-
Comment puis-je générer efficacement des limaces adaptées à l'URL des chaînes Unicode en PHP?Créant une fonction pour la génération efficace des limaces Création de limaces, des représentations simplifiées des chaînes Unicode utilisées...La programmation Publié le 2025-04-08
-
Comment gérer la saisie des utilisateurs dans le mode exclusif complet de Java?Gestion de la saisie de l'utilisateur en mode exclusif en plein écran en java introduction Lors de l'exécution d'une application...La programmation Publié le 2025-04-08
-
Comment corriger \ "MySQL_Config INSTRUST \" Erreur lors de l'installation de MySQL-Python sur Ubuntu / Linux?Erreur d'installation de mysql-python: "mysql_config non fondée" tentant d'installer mysql-python sur ubuntu / linux box peu...La programmation Publié le 2025-04-08
-
Y a-t-il une différence de performance entre l'utilisation d'une boucle for-out et un itérateur pour la traversée de collecte en Java?pour chaque boucle vs iterator: efficacité dans la collection Traversal introduction Lorsque vous traversez une collection dans Java, le c...La programmation Publié le 2025-04-08















Étudier le chinois
- 1 Comment dit-on « marcher » en chinois ? 走路 Prononciation chinoise, 走路 Apprentissage du chinois
- 2 Comment dit-on « prendre l’avion » en chinois ? 坐飞机 Prononciation chinoise, 坐飞机 Apprentissage du chinois
- 3 Comment dit-on « prendre un train » en chinois ? 坐火车 Prononciation chinoise, 坐火车 Apprentissage du chinois
- 4 Comment dit-on « prendre un bus » en chinois ? 坐车 Prononciation chinoise, 坐车 Apprentissage du chinois
- 5 Comment dire conduire en chinois? 开车 Prononciation chinoise, 开车 Apprentissage du chinois
- 6 Comment dit-on nager en chinois ? 游泳 Prononciation chinoise, 游泳 Apprentissage du chinois
- 7 Comment dit-on faire du vélo en chinois ? 骑自行车 Prononciation chinoise, 骑自行车 Apprentissage du chinois
- 8 Comment dit-on bonjour en chinois ? 你好Prononciation chinoise, 你好Apprentissage du chinois
- 9 Comment dit-on merci en chinois ? 谢谢Prononciation chinoise, 谢谢Apprentissage du chinois
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









