 Page de garde > La programmation > Champignons Magiques : explorer et traiter les données nulles avec Mage
Page de garde > La programmation > Champignons Magiques : explorer et traiter les données nulles avec Mage
Champignons Magiques : explorer et traiter les données nulles avec Mage
 Parcourir:932
Parcourir:932
Mage est un outil puissant pour les tâches ETL, avec des fonctionnalités qui permettent l'exploration et l'exploration de données, des visualisations rapides via des modèles de graphiques et plusieurs autres fonctionnalités qui transforment votre travail avec des données en quelque chose de magique.
Dans le traitement des données, au cours d'un processus ETL, il est courant de trouver des données manquantes qui peuvent générer des problèmes dans le futur, en fonction de l'activité que nous allons réaliser avec l'ensemble de données, les données nulles peuvent être assez perturbatrices.
Pour identifier l'absence de données dans notre ensemble de données, nous pouvons utiliser Python et la bibliothèque pandas pour vérifier les données qui présentent des valeurs nulles, en plus nous pouvons créer des graphiques qui montrent encore plus clairement l'impact de ces valeurs nulles dans notre ensemble de données.
Notre pipeline se compose de 4 étapes : commencer par le chargement des données, deux étapes de traitement et l'exportation des données.
Chargeur de données
Dans cet article nous utiliserons l'ensemble de données : Prédiction binaire des champignons vénéneux qui est disponible sur Kaggle dans le cadre d'un concours. Utilisons l'ensemble de données de formation disponible sur le site Web.
Créons une étape Data Loader en utilisant python pour pouvoir charger les données que nous allons utiliser. Avant cette étape, j'ai créé une table dans la base de données Postgres, que j'ai localement sur ma machine, pour pouvoir charger les données. Comme les données sont dans Postgres, nous utiliserons le modèle de chargement Postgres déjà défini dans Mage.
from mage_ai.settings.repo import get_repo_path from mage_ai.io.config import ConfigFileLoader from mage_ai.io.postgres import Postgres from os import path if 'data_loader' not in globals(): from mage_ai.data_preparation.decorators import data_loader if 'test' not in globals(): from mage_ai.data_preparation.decorators import test @data_loader def load_data_from_postgres(*args, **kwargs): """ Template for loading data from a PostgreSQL database. Specify your configuration settings in 'io_config.yaml'. Docs: https://docs.mage.ai/design/data-loading#postgresql """ query = 'SELECT * FROM mushroom' # Specify your SQL query here config_path = path.join(get_repo_path(), 'io_config.yaml') config_profile = 'default' with Postgres.with_config(ConfigFileLoader(config_path, config_profile)) as loader: return loader.load(query) @test def test_output(output, *args) -> None: """ Template code for testing the output of the block. """ assert output is not None, 'The output is undefined'
Au sein de la fonction load_data_from_postgres() nous définirons la requête que nous utiliserons pour charger la table dans la base de données. Dans mon cas, j'ai configuré les informations bancaires dans le fichier io_config.yaml où elles sont définies comme configuration par défaut, il suffit donc de transmettre le nom par défaut à la variable config_profile.
Après avoir exécuté le bloc, nous utiliserons la fonction Ajouter un graphique, qui fournira des informations sur nos données via des modèles déjà définis. Cliquez simplement sur l'icône à côté du bouton de lecture, marquée dans l'image par une ligne jaune.

Nous sélectionnerons deux options pour explorer davantage notre ensemble de données, les options summay_overview et feature_profiles. Grâce à summary_overview, nous obtenons des informations sur le nombre de colonnes et de lignes dans l'ensemble de données. Nous pouvons également afficher le nombre total de colonnes par type, par exemple le nombre total de colonnes catégorielles, numériques et booléennes. Feature_profiles, quant à lui, présente des informations plus descriptives sur les données, telles que : type, valeur minimale, valeur maximale, entre autres informations, nous pouvons même visualiser les valeurs manquantes, qui font l'objet de notre traitement.
Pour pouvoir nous concentrer davantage sur les données manquantes, utilisons le modèle : % de valeurs manquantes, un graphique à barres avec le pourcentage de données manquantes, dans chacune des colonnes.
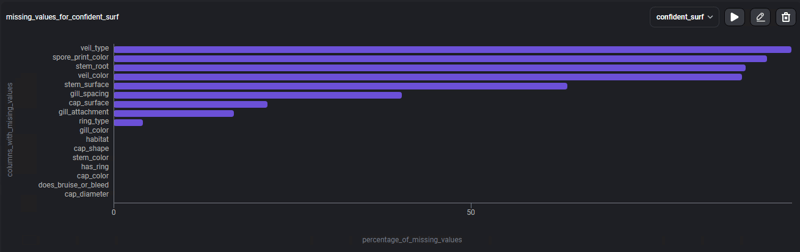
Le graphique présente 4 colonnes où les valeurs manquantes correspondent à plus de 80% de son contenu, et d'autres colonnes qui présentent des valeurs manquantes mais en plus petites quantités, ces informations nous permettent désormais de rechercher différentes stratégies pour y faire face données nulles
Colonnes de dépôt de transformateur
Pour les colonnes qui contiennent plus de 80 % de valeurs nulles, la stratégie que nous suivrons sera d'effectuer une suppression des colonnes dans le dataframe, en sélectionnant les colonnes que nous allons exclure du dataframe. En utilisant le bloc TRANSFORMER dans le langage Python, nous sélectionnerons l'option Colum Removal .
from mage_ai.data_cleaner.transformer_actions.base import BaseAction from mage_ai.data_cleaner.transformer_actions.constants import ActionType, Axis from mage_ai.data_cleaner.transformer_actions.utils import build_transformer_action from pandas import DataFrame if 'transformer' not in globals(): from mage_ai.data_preparation.decorators import transformer if 'test' not in globals(): from mage_ai.data_preparation.decorators import test @transformer def execute_transformer_action(df: DataFrame, *args, **kwargs) -> DataFrame: """ Execute Transformer Action: ActionType.REMOVE Docs: https://docs.mage.ai/guides/transformer-blocks#remove-columns """ action = build_transformer_action( df, action_type=ActionType.REMOVE, arguments=['veil_type', 'spore_print_color', 'stem_root', 'veil_color'], axis=Axis.COLUMN, ) return BaseAction(action).execute(df) @test def test_output(output, *args) -> None: """ Template code for testing the output of the block. """ assert output is not None, 'The output is undefined'
Dans la fonction execute_transformer_action() nous insérerons une liste avec le nom des colonnes que nous voulons exclure de l'ensemble de données, dans la variable arguments, après cette étape, exécutez simplement le bloc.
Le transformateur remplit les valeurs manquantes
Maintenant, pour les colonnes qui contiennent moins de 80 % de valeurs nulles, nous utiliserons la stratégie Remplir les valeurs manquantes, comme dans certains cas malgré des données manquantes, en les remplaçant par des valeurs telles que En moyenne, ou à la mode, il peut être en mesure de répondre au besoin de données sans provoquer de nombreux changements dans l'ensemble de données, en fonction de votre objectif final.
Il existe certaines tâches, telles que la classification, où le remplacement des données manquantes par une valeur pertinente (mode, moyenne, médiane) pour l'ensemble de données peut contribuer à l'algorithme de classification, qui pourrait parvenir à d'autres conclusions si les données étaient supprimées. comme dans l’autre stratégie que nous avons utilisée.
Pour décider quelle mesure nous utiliserons, nous utiliserons à nouveau la fonctionnalité Ajouter un graphique de Mage. En utilisant le modèle Valeurs les plus fréquentes nous pouvons visualiser le mode et la fréquence de cette valeur dans chacune des colonnes.
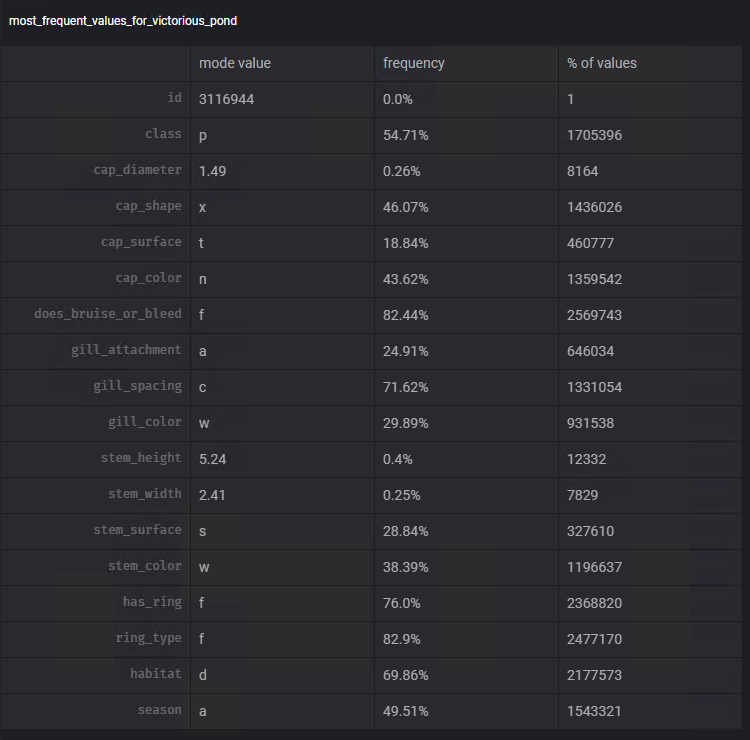
En suivant des étapes similaires aux précédentes, nous utiliserons le transformateur Remplir les valeurs manquantes, pour effectuer la tâche de soustraction des données manquantes en utilisant le mode de chacune des colonnes : steam_surface, gill_spacing, cap_surface , gill_attachment, ring_type.
from mage_ai.data_cleaner.transformer_actions.constants import ImputationStrategy
from mage_ai.data_cleaner.transformer_actions.base import BaseAction
from mage_ai.data_cleaner.transformer_actions.constants import ActionType, Axis
from mage_ai.data_cleaner.transformer_actions.utils import build_transformer_action
from pandas import DataFrame
if 'transformer' not in globals():
from mage_ai.data_preparation.decorators import transformer
if 'test' not in globals():
from mage_ai.data_preparation.decorators import test
@transformer
def execute_transformer_action(df: DataFrame, *args, **kwargs) -> DataFrame:
"""
Execute Transformer Action: ActionType.IMPUTE
Docs: https://docs.mage.ai/guides/transformer-blocks#fill-in-missing-values
"""
action = build_transformer_action(
df,
action_type=ActionType.IMPUTE,
arguments=df.columns, # Specify columns to impute
axis=Axis.COLUMN,
options={'strategy': ImputationStrategy.MODE}, # Specify imputation strategy
)
return BaseAction(action).execute(df)
@test
def test_output(output, *args) -> None:
"""
Template code for testing the output of the block.
"""
assert output is not None, 'The output is undefined'
Dans la fonction execute_transformer_action() , nous définissons la stratégie de remplacement des données dans un dictionnaire Python. Pour plus d'options de remplacement, accédez simplement à la documentation du transformateur : https://docs.mage.ai/guides/transformer-blocks#fill-in-missing-values.
Exportateur de données
Lorsque nous effectuerons toutes les transformations, nous sauvegarderons notre ensemble de données désormais traité, dans la même base de données Postgres mais maintenant avec un nom différent afin de pouvoir le différencier. En utilisant le bloc Data Exporter et en sélectionnant Postgres, nous définirons le shema et la table où nous voulons enregistrer, en rappelant que les configurations de la base de données sont préalablement enregistrées dans le fichier io_config.yaml.
from mage_ai.settings.repo import get_repo_path from mage_ai.io.config import ConfigFileLoader from mage_ai.io.postgres import Postgres from pandas import DataFrame from os import path if 'data_exporter' not in globals(): from mage_ai.data_preparation.decorators import data_exporter @data_exporter def export_data_to_postgres(df: DataFrame, **kwargs) -> None: """ Template for exporting data to a PostgreSQL database. Specify your configuration settings in 'io_config.yaml'. Docs: https://docs.mage.ai/design/data-loading#postgresql """ schema_name = 'public' # Specify the name of the schema to export data to table_name = 'mushroom_clean' # Specify the name of the table to export data to config_path = path.join(get_repo_path(), 'io_config.yaml') config_profile = 'default' with Postgres.with_config(ConfigFileLoader(config_path, config_profile)) as loader: loader.export( df, schema_name, table_name, index=False, # Specifies whether to include index in exported table if_exists='replace', #Specify resolution policy if table name already exists )
Merci et à la prochaine fois ?
repo -> https://github.com/DeadPunnk/Mushrooms/tree/main
-
 Comment définir dynamiquement les touches dans les objets JavaScript?Comment créer une clé dynamique pour une variable d'objet JavaScript lorsque vous essayez de créer une clé dynamique pour un objet JavaScrip...La programmation Publié le 2025-07-04
Comment définir dynamiquement les touches dans les objets JavaScript?Comment créer une clé dynamique pour une variable d'objet JavaScript lorsque vous essayez de créer une clé dynamique pour un objet JavaScrip...La programmation Publié le 2025-07-04 -
Comment éviter les fuites de mémoire lors de la tranchage du langage GO?la fuite de la mémoire dans les tranches go Comprendre les fuites de mémoire dans les tranches de go peut être un défi. Cet article vise à app...La programmation Publié le 2025-07-04
-
Pourquoi est-ce que je reçois MySQL Error # 1089: clé de préfixe incorrect?MySql Error # 1089: Key de préfixe incorrect Les utilisateurs de MySQL peuvent rencontrer du code d'erreur # 1089, indiquant une utilisati...La programmation Publié le 2025-07-04
-
Comment analyser les tableaux JSON en Go en utilisant le package «JSON»?analyser les tableaux json dans Go avec le package json Problème: Comment pouvez-vous analyser une chaîne JSON représentant un Array dans Go...La programmation Publié le 2025-07-04
-
Comment puis-je personnaliser les optimisations de compilation dans le compilateur Go?Personnaliser les optimisations de compilation dans go compiller Le processus de compilation par défaut dans Go suit une stratégie d'optim...La programmation Publié le 2025-07-04
-
Python Metaclass Principe de travail et création et personnalisation de classeQue sont les métaclasses dans python? Les métaclasses sont responsables de la création d'objets de classe dans python. Tout comme les classe...La programmation Publié le 2025-07-04
-
Guide pour résoudre les problèmes CORS dans Spring Security 4.1 et plusSpring Security Cors Filter: dépannage des problèmes communs Lors de l'intégration de Spring Security dans un projet existant, vous pouvez...La programmation Publié le 2025-07-04
-
Comment rediriger plusieurs types d'utilisateurs (étudiants, enseignants et administrateurs) vers leurs activités respectives dans une application Firebase?Red: comment rediriger plusieurs types d'utilisateurs vers des activités respectives Comprendre le problème dans une application de vo...La programmation Publié le 2025-07-04
-
Causes et solutions pour la défaillance de la détection du visage: erreur -215Gestion des erreurs: résolution "Erreur: (-215)! Vide () Dans la fonction détectMultiSCALE" dans OpenCv lorsque vous pouvez utiliser...La programmation Publié le 2025-07-04
-
Comment résoudre l'erreur "Impossible de deviner le type de fichier, utiliser l'application / l'octet-stream ..." dans Applexinement?Appangement static File mime type override Dans Appengine, les gestionnaires de fichiers statiques peuvent parfois remplacer le type de mime c...La programmation Publié le 2025-07-04
-
Comment extraire un élément aléatoire d'un tableau en PHP?sélection aléatoire à partir d'un tableau en php, l'obtention d'un élément aléatoire à partir d'un tableau peut être accompli av...La programmation Publié le 2025-07-04
-
Méthode pour convertir correctement les caractères Latin1 en UTF8 dans UTF8 MySQL TableConvertir les caractères latins1 dans une table utf8 en utf8 Vous avez rencontré un problème où les caractères avec diacritique (par exemple, ...La programmation Publié le 2025-07-04
-
TableauLes méthodes sont des fns qui peuvent être appelés sur des objets Les tableaux sont des objets, donc ils ont également des méthodes en js. ...La programmation Publié le 2025-07-04
-
PHP Future: adaptation et innovationL'avenir de PHP sera réalisé en s'adaptant aux nouvelles tendances technologiques et en introduisant des fonctionnalités innovantes: 1) s'...La programmation Publié le 2025-07-04
-
Comment implémenter une fonction de hachage générique pour les tuples dans les collections non ordonnées?Fonction de hachage générique pour les tuples dans les collections non ordonnées Le std :: non ordonné_map et std :: non ordonné les conteneur...La programmation Publié le 2025-07-04















Étudier le chinois
- 1 Comment dit-on « marcher » en chinois ? 走路 Prononciation chinoise, 走路 Apprentissage du chinois
- 2 Comment dit-on « prendre l’avion » en chinois ? 坐飞机 Prononciation chinoise, 坐飞机 Apprentissage du chinois
- 3 Comment dit-on « prendre un train » en chinois ? 坐火车 Prononciation chinoise, 坐火车 Apprentissage du chinois
- 4 Comment dit-on « prendre un bus » en chinois ? 坐车 Prononciation chinoise, 坐车 Apprentissage du chinois
- 5 Comment dire conduire en chinois? 开车 Prononciation chinoise, 开车 Apprentissage du chinois
- 6 Comment dit-on nager en chinois ? 游泳 Prononciation chinoise, 游泳 Apprentissage du chinois
- 7 Comment dit-on faire du vélo en chinois ? 骑自行车 Prononciation chinoise, 骑自行车 Apprentissage du chinois
- 8 Comment dit-on bonjour en chinois ? 你好Prononciation chinoise, 你好Apprentissage du chinois
- 9 Comment dit-on merci en chinois ? 谢谢Prononciation chinoise, 谢谢Apprentissage du chinois
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









