 Page de garde > La programmation > Création d'une application RAG avec LlamaIndex.ts et Azure OpenAI : mise en route !
Page de garde > La programmation > Création d'une application RAG avec LlamaIndex.ts et Azure OpenAI : mise en route !
Création d'une application RAG avec LlamaIndex.ts et Azure OpenAI : mise en route !
 Parcourir:632
Parcourir:632
Alors que l'IA continue de façonner notre façon de travailler et d'interagir avec la technologie, de nombreuses entreprises recherchent des moyens d'exploiter leurs propres données au sein d'applications intelligentes. Si vous avez utilisé des outils comme ChatGPT ou Azure OpenAI, vous savez déjà comment l'IA générative peut améliorer les processus et améliorer l'expérience utilisateur. Cependant, pour des réponses réellement personnalisées et pertinentes, vos applications doivent intégrer vos données propriétaires.
C'est là qu'intervient la génération de récupération augmentée (RAG), fournissant une approche structurée pour intégrer la récupération de données avec des réponses basées sur l'IA. Avec des frameworks comme LlamaIndex, vous pouvez facilement intégrer cette fonctionnalité dans vos solutions, libérant ainsi tout le potentiel de vos données d'entreprise.
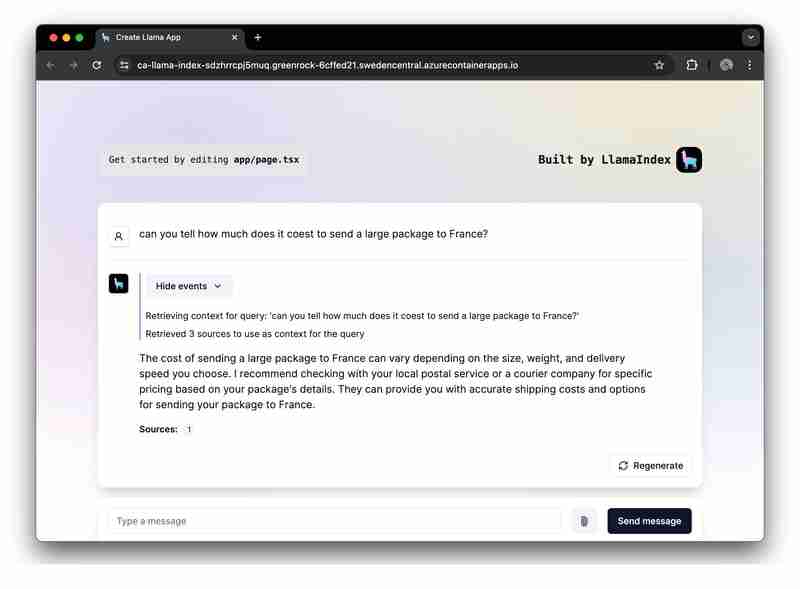
Vous souhaitez exécuter et explorer rapidement l'application ? Cliquez ici.
Qu'est-ce que RAG - Génération augmentée par récupération ?
Retrieval-Augmented Generation (RAG) est un cadre de réseau neuronal qui améliore la génération de texte d'IA en incluant un composant de récupération pour accéder aux informations pertinentes et intégrer vos propres données. Il se compose de deux parties principales :
- Retriever : un modèle de récupération dense (par exemple, basé sur BERT) qui recherche un vaste corpus de documents pour trouver des passages pertinents ou des informations liées à une requête donnée.
- Générateur : un modèle séquence à séquence (par exemple, basé sur BART ou T5) qui prend la requête et le texte récupéré en entrée et génère une réponse cohérente et enrichie contextuellement.
Le récupérateur trouve les documents pertinents et le générateur les utilise pour créer des réponses plus précises et informatives. Cette combinaison permet au modèle RAG d'exploiter efficacement les connaissances externes, améliorant ainsi la qualité et la pertinence du texte généré.
Comment LlamaIndex implémente-t-il RAG ?
Pour implémenter un système RAG à l'aide de LlamaIndex, suivez ces étapes générales :
Ingestion de données :
- Chargez vos documents dans LlamaIndex.ts à l'aide d'un chargeur de documents tel que SimpleDirectoryReader, qui permet d'importer des données à partir de diverses sources telles que des PDF, des API ou des bases de données SQL.
- Décomposez les documents volumineux en morceaux plus petits et gérables à l'aide de SentenceSplitter.
Création d'index :
- Créez un index vectoriel de ces morceaux de document à l'aide de VectorStoreIndex, permettant des recherches de similarité efficaces basées sur des intégrations.
- Facultativement, pour les ensembles de données complexes, utilisez des techniques de récupération récursive pour gérer les données structurées hiérarchiquement et récupérer les sections pertinentes en fonction des requêtes des utilisateurs.
Configuration du moteur de requête :
- Convertissez l'index vectoriel en un moteur de requête à l'aide de asQueryEngine avec des paramètres tels que similarityTopK pour définir le nombre de documents principaux à récupérer.
- Pour des configurations plus avancées, créez un système multi-agents dans lequel chaque agent est responsable de documents spécifiques et un agent de niveau supérieur coordonne le processus global de récupération.
Récupération et génération :
- Implémentez le pipeline RAG en définissant une fonction objective qui récupère les morceaux de documents pertinents en fonction des requêtes des utilisateurs.
- Utilisez RetrieverQueryEngine pour effectuer la récupération et le traitement des requêtes, avec des étapes de post-traitement facultatives telles que le reclassement des documents récupérés à l'aide d'outils tels que CohereRerank.
Pour un exemple pratique, nous avons fourni un exemple d'application pour démontrer une implémentation complète de RAG à l'aide d'Azure OpenAI.
Exemple d’application pratique RAG
Nous allons maintenant nous concentrer sur la création d'une application RAG à l'aide de LlamaIndex.ts (l'implémentation TypeScipt de LlamaIndex) et Azure OpenAI, et la déployer en tant qu'applications Web sans serveur sur Azure Container Apps.
Conditions requises pour exécuter l'exemple
- Azure Developer CLI (azd) : un outil de ligne de commande pour déployer facilement l'intégralité de votre application, y compris le backend, le frontend et les bases de données.
- Compte Azure : vous aurez besoin d'un compte Azure pour déployer l'application. Obtenez un compte Azure gratuit avec quelques crédits pour commencer.
Vous trouverez le projet de démarrage sur GitHub. Nous vous recommandons de créer ce modèle afin de pouvoir le modifier librement en cas de besoin :

Architecture de haut niveau
L'application de projet de démarrage est construite sur la base de l'architecture suivante :
- Azure OpenAI : fournisseur d'IA qui traite les requêtes de l'utilisateur.
- LlamaIndex.ts : le framework qui permet d'ingérer, de transformer et de vectoriser le contenu (PDF) et de créer un index de recherche.
- Azure Container Apps : environnement de conteneur dans lequel l'application sans serveur est hébergée.
- Azure Managed Identity : garantit une sécurité de premier ordre et élimine le besoin de gérer les informations d'identification et les clés API.
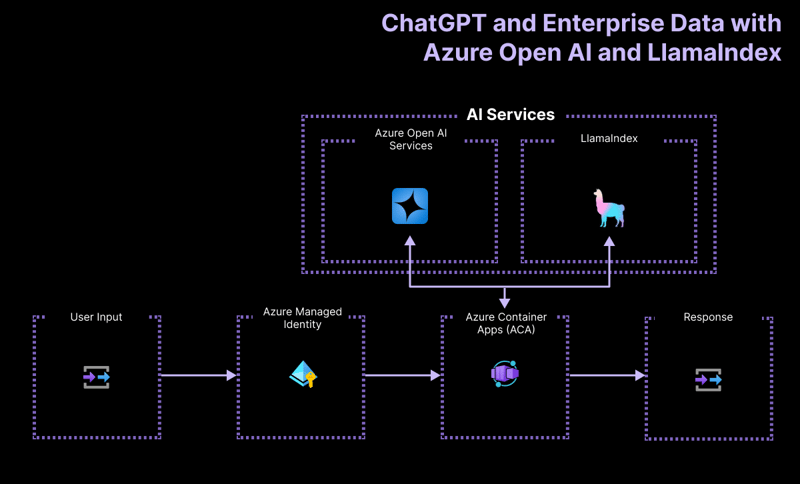
Pour plus de détails sur les ressources déployées, consultez le dossier infra disponible dans tous nos exemples.
Exemples de flux de travail utilisateur
L'exemple d'application contient une logique pour deux flux de travail :
-
Ingestion de données : les données sont récupérées, vectorisées et des index de recherche sont créés. Si vous souhaitez ajouter d'autres fichiers tels que des fichiers PDF ou Word, c'est ici que vous devez les ajouter.
npm run generate
Traitement des demandes d'invite : l'application reçoit les invites des utilisateurs, les envoie à Azure OpenAI et augmente ces invites en utilisant l'index vectoriel comme outil de récupération.
Exécution de l'exemple
Avant d'exécuter l'exemple, assurez-vous d'avoir provisionné les ressources Azure nécessaires.
Pour exécuter le modèle GitHub dans GitHub Codespace, cliquez simplement sur
Dans votre instance Codespaces, connectez-vous à votre compte Azure, depuis votre terminal :
azd auth login
Provisionner, empaqueter et déployer l'exemple d'application sur Azure à l'aide d'une seule commande :
azd up
Pour exécuter et essayer l'application localement, installez les dépendances npm et exécutez l'application :
npm install npm run dev
L'application s'exécutera sur le port 3000 de votre instance Codespaces ou sur http://localhost:3000 dans votre navigateur.
Conclusion
Ce guide a montré comment créer une application RAG (Retrieval-Augmented Generation) sans serveur à l'aide de LlamaIndex.ts et Azure OpenAI, déployée sur Microsoft Azure. En suivant ce guide, vous pouvez tirer parti de l'infrastructure d'Azure et des capacités de LlamaIndex pour créer de puissantes applications d'IA qui fournissent des réponses enrichies contextuellement en fonction de vos données.
Nous sommes ravis de voir ce que vous créez avec cette application de démarrage. N'hésitez pas à le créer et à aimer le référentiel GitHub pour recevoir les dernières mises à jour et fonctionnalités.
-
 Pourquoi est-ce que je reçois MySQL Error # 1089: clé de préfixe incorrect?MySql Error # 1089: Key de préfixe incorrect Les utilisateurs de MySQL peuvent rencontrer du code d'erreur # 1089, indiquant une utilisati...La programmation Publié le 2025-07-13
Pourquoi est-ce que je reçois MySQL Error # 1089: clé de préfixe incorrect?MySql Error # 1089: Key de préfixe incorrect Les utilisateurs de MySQL peuvent rencontrer du code d'erreur # 1089, indiquant une utilisati...La programmation Publié le 2025-07-13 -
Pourquoi est-ce que je reçois une erreur \ "class \ 'ziparchive \' non trouvée \" après avoir installé archive_zip sur mon serveur Linux?classe 'ziparchive' introuvable erreur lors de l'installation d'archive_zip sur le serveur Linux symptôme: Lorsque vous tent...La programmation Publié le 2025-07-13
-
Comment corriger \ "MySQL_Config INSTRUST \" Erreur lors de l'installation de MySQL-Python sur Ubuntu / Linux?Erreur d'installation de mysql-python: "mysql_config non fondée" tentant d'installer mysql-python sur ubuntu / linux box peu...La programmation Publié le 2025-07-13
-
Comment surmonter les restrictions de redéfinition de la fonction de PHP?surmonter les limitations de redéfinition de la fonction de Php dans php, définir une fonction avec le même nom plusieurs fois est un non. Ten...La programmation Publié le 2025-07-13
-
Comment créer des variables dynamiques dans Python?Création de variables dynamiques dans python La capacité de créer des variables dynamiquement peut être un outil puissant, en particulier lors...La programmation Publié le 2025-07-13
-
Comment puis-je récupérer efficacement les valeurs d'attribut à partir de fichiers XML à l'aide de PHP?Récupération des valeurs d'attribut à partir de fichiers xml dans php Chaque développeur rencontre la nécessité de analyser les fichiers X...La programmation Publié le 2025-07-13
-
CSS peut-il localiser les éléments HTML basés sur une valeur d'attribut?ciblant les éléments HTML avec n'importe quelle valeur d'attribut dans CSS Dans CSS, il est possible de cibler les éléments basés sur ...La programmation Publié le 2025-07-13
-
Plusieurs éléments collants peuvent-ils être empilés les uns sur les autres en CSS pur?Est-il possible d'avoir plusieurs éléments collants empilés les uns sur les autres en pur css? Le comportement souhaité peut être vu Ici:...La programmation Publié le 2025-07-13
-
Spark DataFrame Conseils pour ajouter des colonnes constantesCréation d'une colonne constante dans une étincelle DataFrame L'ajout d'une colonne constante à une étincelle DataFrame avec une v...La programmation Publié le 2025-07-13
-
Pourquoi y a-t-il des rayures dans mon fond de dégradé linéaire, et comment puis-je les réparer?bannissant les bandes d'arrière-plan à partir du gradient linéaire Lorsque vous utilisez la propriété linéaire-gradient pour un arrière-pl...La programmation Publié le 2025-07-13
-
Comment pouvez-vous utiliser des données de groupe par pour pivoter dans MySQL?Pivoting des résultats de la requête en utilisant le groupe mysql par Dans une base de données relationnelle, les données pivotant se réfèrent...La programmation Publié le 2025-07-13
-
Comment ajouter la base de données MySQL à la boîte de dialogue DataSource dans Visual Studio 2012?Ajout de la base de données MySQL à la boîte de dialogue DataSource dans Visual Studio 2012 En travaillant avec Entity Framework et MySQL, l&#...La programmation Publié le 2025-07-13
-
La méthode de la base de données MySQL n'est pas nécessaire pour vider la même instanceCopie d'une base de données mysql sur la même instance sans vider copie une base de données sur la même instance mysql peut être faite san...La programmation Publié le 2025-07-13
-
Comment extraire du texte entre parenthèses efficacement en PHP en utilisant Regexphp: extraire du texte dans les parenthèses de manière optimale lors de l'extraction de texte enfermé entre parenthèses, il est essentiel ...La programmation Publié le 2025-07-13
-
Causes et solutions pour la défaillance de la détection du visage: erreur -215Gestion des erreurs: résolution "Erreur: (-215)! Vide () Dans la fonction détectMultiSCALE" dans OpenCv lorsque vous pouvez utiliser...La programmation Publié le 2025-07-13















Étudier le chinois
- 1 Comment dit-on « marcher » en chinois ? 走路 Prononciation chinoise, 走路 Apprentissage du chinois
- 2 Comment dit-on « prendre l’avion » en chinois ? 坐飞机 Prononciation chinoise, 坐飞机 Apprentissage du chinois
- 3 Comment dit-on « prendre un train » en chinois ? 坐火车 Prononciation chinoise, 坐火车 Apprentissage du chinois
- 4 Comment dit-on « prendre un bus » en chinois ? 坐车 Prononciation chinoise, 坐车 Apprentissage du chinois
- 5 Comment dire conduire en chinois? 开车 Prononciation chinoise, 开车 Apprentissage du chinois
- 6 Comment dit-on nager en chinois ? 游泳 Prononciation chinoise, 游泳 Apprentissage du chinois
- 7 Comment dit-on faire du vélo en chinois ? 骑自行车 Prononciation chinoise, 骑自行车 Apprentissage du chinois
- 8 Comment dit-on bonjour en chinois ? 你好Prononciation chinoise, 你好Apprentissage du chinois
- 9 Comment dit-on merci en chinois ? 谢谢Prononciation chinoise, 谢谢Apprentissage du chinois
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









