
Reliez l’IA/ML avec votre solution Adaptive Analytics
 Parcourir:822
Parcourir:822
Dans le paysage des données actuel, les entreprises sont confrontées à un certain nombre de défis différents. L’une d’elles consiste à effectuer des analyses au-dessus d’une couche de données unifiée et harmonisée disponible pour tous les consommateurs. Une couche capable de fournir les mêmes réponses aux mêmes questions, quel que soit le dialecte ou l'outil utilisé.
InterSystems IRIS Data Platform répond à cela avec un module complémentaire d'Adaptive Analytics qui peut fournir cette couche sémantique unifiée. Il existe de nombreux articles dans DevCommunity sur son utilisation via les outils BI. Cet article expliquera comment le consommer avec l'IA et également comment remettre quelques informations en retour.
Allons-y étape par étape...
Qu'est-ce que l'analyse adaptative ?
Vous pouvez facilement trouver une définition sur le site Web de la communauté des développeurs
En quelques mots, il peut fournir des données sous une forme structurée et harmonisée à divers outils de votre choix pour une consommation et une analyse ultérieures. Il fournit les mêmes structures de données à divers outils de BI. Mais... il peut également fournir les mêmes structures de données à vos outils d'IA/ML !
Adaptive Analytics possède un composant supplémentaire appelé AI-Link qui établit ce pont entre l'IA et la BI.
Qu'est-ce qu'AI-Link exactement ?
Il s'agit d'un composant Python conçu pour permettre une interaction programmatique avec la couche sémantique dans le but de rationaliser les étapes clés du flux de travail d'apprentissage automatique (ML) (par exemple, l'ingénierie des fonctionnalités).
Avec AI-Link, vous pouvez :
- accéder par programmation aux fonctionnalités de votre modèle de données analytiques ;
- effectuer des requêtes, explorer des dimensions et des mesures ;
- alimenter les pipelines ML ; ... et renvoyez les résultats à votre couche sémantique pour qu'ils soient à nouveau consommés par d'autres (par exemple via Tableau ou Excel).
Comme il s'agit d'une bibliothèque Python, elle peut être utilisée dans n'importe quel environnement Python. Y compris les cahiers.
Et dans cet article, je vais donner un exemple simple d'accès à la solution Adaptive Analytics de Jupyter Notebook à l'aide d'AI-Link.
Voici le référentiel git qui aura le Notebook complet comme exemple : https://github.com/v23ent/aa-hands-on
Pré-requis
Les autres étapes supposent que vous ayez rempli les conditions préalables suivantes :
- Solution d'analyse adaptative opérationnelle (avec IRIS Data Platform comme entrepôt de données)
- Jupyter Notebook opérationnel
- Une connexion entre 1. et 2. peut être établie
Étape 1 : Configuration
Tout d'abord, installons les composants nécessaires dans notre environnement. Cela téléchargera quelques packages nécessaires au fonctionnement des étapes suivantes.
'atscale' - c'est notre package principal pour se connecter
'prophet' - package dont nous aurons besoin pour faire des prédictions
pip install atscale prophet
Ensuite, nous devrons importer des classes clés représentant certains concepts clés de notre couche sémantique.
Client - classe que nous utiliserons pour établir une connexion à Adaptive Analytics ;
Projet - classe pour représenter les projets dans Adaptive Analytics ;
DataModel - classe qui représentera notre cube virtuel ;
from atscale.client import Client from atscale.data_model import DataModel from atscale.project import Project from prophet import Prophet import pandas as pd
Étape 2 : Connexion
Nous devrions maintenant être prêts à établir une connexion à notre source de données.
client = Client(server='http://adaptive.analytics.server', username='sample') client.connect()
Allez-y et spécifiez les détails de connexion de votre instance Adaptive Analytics. Une fois que l'organisation vous a demandé de répondre dans la boîte de dialogue, veuillez saisir votre mot de passe de l'instance AtScale.
Une fois la connexion établie, vous devrez ensuite sélectionner votre projet dans la liste des projets publiés sur le serveur. Vous obtiendrez la liste des projets sous forme d'invite interactive et la réponse doit être l'ID entier du projet. Et puis le modèle de données est sélectionné automatiquement s'il est le seul.
project = client.select_project() data_model = project.select_data_model()
Étape 3 : Explorez votre ensemble de données
Il existe un certain nombre de méthodes préparées par AtScale dans la bibliothèque de composants AI-Link. Ils permettent d'explorer le catalogue de données dont vous disposez, d'interroger des données et même d'ingérer certaines données. La documentation AtScale contient une référence API détaillée décrivant tout ce qui est disponible.
Voyons d'abord quel est notre ensemble de données en appelant quelques méthodes de data_model :
data_model.get_features() data_model.get_all_categorical_feature_names() data_model.get_all_numeric_feature_names()
Le résultat devrait ressembler à ceci
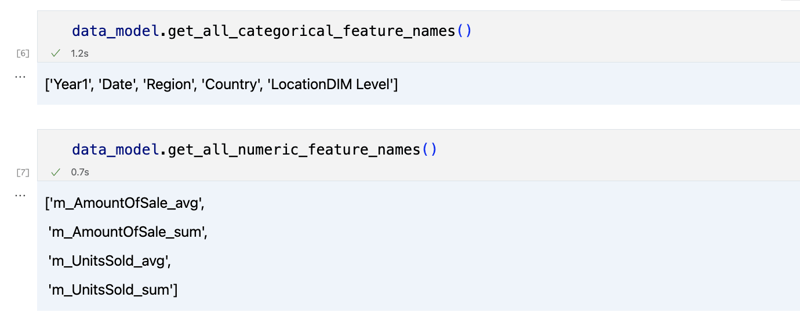
Une fois que nous avons regardé un peu, nous pouvons interroger les données réelles qui nous intéressent en utilisant la méthode 'get_data'. Il renverra un DataFrame pandas contenant les résultats de la requête.
df = data_model.get_data(feature_list = ['Country','Region','m_AmountOfSale_sum']) df = df.sort_values(by='m_AmountOfSale_sum') df.head()
Qui affichera votre datadrame :
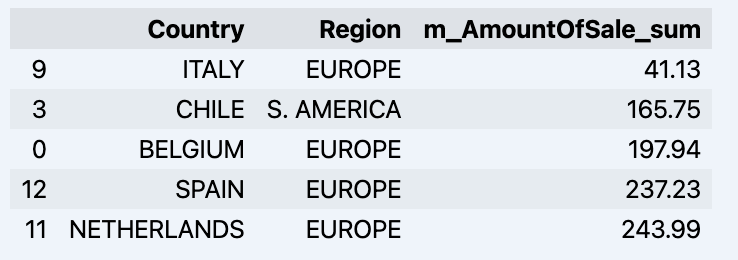
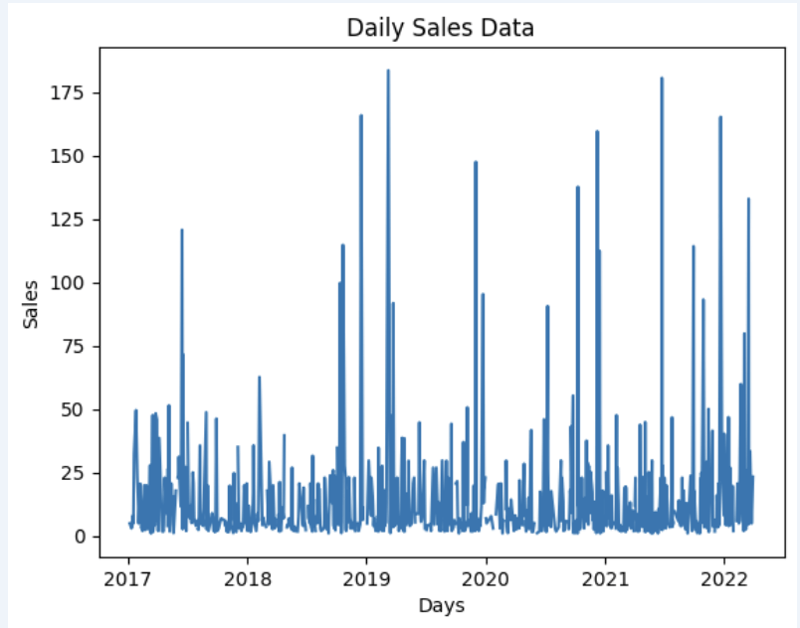
Préparons un ensemble de données et montrons-le rapidement sur le graphique
import matplotlib.pyplot as plt
# We're taking sales for each date
dataframe = data_model.get_data(feature_list = ['Date','m_AmountOfSale_sum'])
# Create a line chart
plt.plot(dataframe['Date'], dataframe['m_AmountOfSale_sum'])
# Add labels and a title
plt.xlabel('Days')
plt.ylabel('Sales')
plt.title('Daily Sales Data')
# Display the chart
plt.show()
Sortir:
Étape 4 : Prédiction
La prochaine étape serait de réellement tirer une certaine valeur du pont AI-Link - faisons une prédiction simple !
# Load the historical data to train the model
data_train = data_model.get_data(
feature_list = ['Date','m_AmountOfSale_sum'],
filter_less = {'Date':'2021-01-01'}
)
data_test = data_model.get_data(
feature_list = ['Date','m_AmountOfSale_sum'],
filter_greater = {'Date':'2021-01-01'}
)
Nous obtenons ici 2 ensembles de données différents : pour entraîner notre modèle et le tester.
# For the tool we've chosen to do the prediction 'Prophet', we'll need to specify 2 columns: 'ds' and 'y'
data_train['ds'] = pd.to_datetime(data_train['Date'])
data_train.rename(columns={'m_AmountOfSale_sum': 'y'}, inplace=True)
data_test['ds'] = pd.to_datetime(data_test['Date'])
data_test.rename(columns={'m_AmountOfSale_sum': 'y'}, inplace=True)
# Initialize and fit the Prophet model
model = Prophet()
model.fit(data_train)
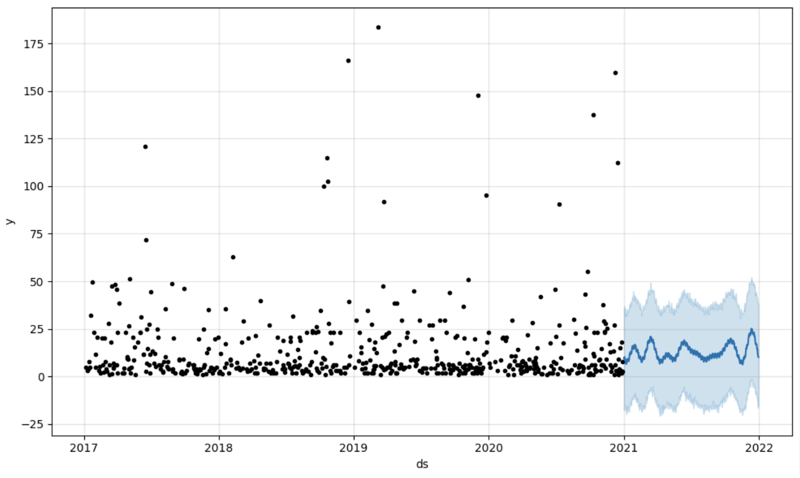
Et puis nous créons un autre dataframe pour accueillir notre prédiction et l'affichons sur le graphique
# Create a future dataframe for forecasting future = pd.DataFrame() future['ds'] = pd.date_range(start='2021-01-01', end='2021-12-31', freq='D') # Make predictions forecast = model.predict(future) fig = model.plot(forecast) fig.show()
Sortir:
Étape 5 : Réécriture
Une fois notre prédiction en place, nous pouvons la remettre dans l'entrepôt de données et ajouter un agrégat à notre modèle sémantique pour la refléter pour les autres consommateurs. La prédiction serait disponible via n'importe quel autre outil BI pour les analystes BI et les utilisateurs professionnels.
La prédiction elle-même sera placée dans notre entrepôt de données et y sera stockée.
from atscale.db.connections import Iris
db = Iris(
username,
host,
namespace,
driver,
schema,
port=1972,
password=None,
warehouse_id=None
)data_model.writeback(dbconn=db,
table_name= 'SalesPrediction',
DataFrame = forecast)data_model.create_aggregate_feature(dataset_name='SalesPrediction',
column_name='SalesForecasted',
name='sum_sales_forecasted',
aggregation_type='SUM')
Ailette
C'est ça !
Bonne chance avec vos prédictions !
-
 Comment puis-je itérer et imprimer des valeurs de manière synchrone à partir de deux tableaux de taille égale en PHP?itération et imprimant de manière synchrone à partir de deux tableaux de même taille lors de la création d'une SelectBox en utilisant deux t...La programmation Publié le 2025-04-27
Comment puis-je itérer et imprimer des valeurs de manière synchrone à partir de deux tableaux de taille égale en PHP?itération et imprimant de manière synchrone à partir de deux tableaux de même taille lors de la création d'une SelectBox en utilisant deux t...La programmation Publié le 2025-04-27 -
Résoudre l'erreur MySQL 1153: le paquet dépasse la limite 'max_allowed_packet'MySql Error 1153: le dépannage a obtenu un paquet plus grand que 'max_allowed_packet' octets face à l'erreur MySQL énigmatique 115...La programmation Publié le 2025-04-27
-
Quelle est la différence entre les fonctions imbriquées et les fermetures en pythonfonctions imbriquées par rapport aux fermetures en python Bien que les fonctions imbriquées dans Python ressemblent superficiellement Non-Clos...La programmation Publié le 2025-04-27
-
Comment éviter les fuites de mémoire lors de la tranchage du langage GO?la fuite de la mémoire dans les tranches go Comprendre les fuites de mémoire dans les tranches de go peut être un défi. Cet article vise à app...La programmation Publié le 2025-04-27
-
Comment définir dynamiquement les touches dans les objets JavaScript?Comment créer une clé dynamique pour une variable d'objet JavaScript lorsque vous essayez de créer une clé dynamique pour un objet JavaScrip...La programmation Publié le 2025-04-27
-
Java autorise-t-il plusieurs types de retour: un regard plus approfondi sur les méthodes génériques?Plusieurs types de retour en java: une idée fausse dévoilée dans le domaine de la programmation java, une signature de méthode particulière pe...La programmation Publié le 2025-04-27
-
Comment puis-je générer efficacement des limaces adaptées à l'URL des chaînes Unicode en PHP?Créant une fonction pour la génération efficace des limaces Création de limaces, des représentations simplifiées des chaînes Unicode utilisées...La programmation Publié le 2025-04-27
-
Causes et solutions pour la défaillance de la détection du visage: erreur -215Gestion des erreurs: résolution "Erreur: (-215)! Vide () Dans la fonction détectMultiSCALE" dans OpenCv lorsque vous pouvez utiliser...La programmation Publié le 2025-04-27
-
Comment convertir efficacement les fuseaux horaires en PHP?Conversion efficace du fuseau horaire en php Dans PHP, la gestion des fuseaux horaires peut être une tâche simple. Ce guide fournira une méthode...La programmation Publié le 2025-04-27
-
Comment télécharger des fichiers avec des paramètres supplémentaires à l'aide de java.net.urlconnection et de codage multipart / formulaire de formulaire?Téléchargement des fichiers avec les demandes http pour télécharger des fichiers sur un serveur http tout en soumettant des paramètres supplém...La programmation Publié le 2025-04-27
-
Comment détecter efficacement les tableaux vides en PHP?Vérification du vide du tableau en php Un tableau vide peut être déterminé en php via diverses approches. Si le besoin est de vérifier la prés...La programmation Publié le 2025-04-27
-
Comment corriger \ "MySQL_Config INSTRUST \" Erreur lors de l'installation de MySQL-Python sur Ubuntu / Linux?Erreur d'installation de mysql-python: "mysql_config non fondée" tentant d'installer mysql-python sur ubuntu / linux box peu...La programmation Publié le 2025-04-27
-
Comment répéter efficacement les caractères de chaîne pour l'indentation en C #?Répétant une chaîne pour l'indentation Lorsque vous intelliez une chaîne basée sur la profondeur d'un élément, il est pratique d'a...La programmation Publié le 2025-04-27
-
Guide de création de pages Fastapi Custom 404 PagePage personnalisée 404 non trouvé avec fastapi Pour créer une page 404 personnalisée, Fastapi propose plusieurs approches. La méthode appropri...La programmation Publié le 2025-04-27
-
Comment résoudre \ "Refusé de charger le script ... \" Erreurs dues à la stratégie de sécurité du contenu d'Android?dévoiler le mystère: contenu des erreurs de directive de stratégie de sécurité rencontrant l'erreur énigmatique "refusé de charger le...La programmation Publié le 2025-04-27















Étudier le chinois
- 1 Comment dit-on « marcher » en chinois ? 走路 Prononciation chinoise, 走路 Apprentissage du chinois
- 2 Comment dit-on « prendre l’avion » en chinois ? 坐飞机 Prononciation chinoise, 坐飞机 Apprentissage du chinois
- 3 Comment dit-on « prendre un train » en chinois ? 坐火车 Prononciation chinoise, 坐火车 Apprentissage du chinois
- 4 Comment dit-on « prendre un bus » en chinois ? 坐车 Prononciation chinoise, 坐车 Apprentissage du chinois
- 5 Comment dire conduire en chinois? 开车 Prononciation chinoise, 开车 Apprentissage du chinois
- 6 Comment dit-on nager en chinois ? 游泳 Prononciation chinoise, 游泳 Apprentissage du chinois
- 7 Comment dit-on faire du vélo en chinois ? 骑自行车 Prononciation chinoise, 骑自行车 Apprentissage du chinois
- 8 Comment dit-on bonjour en chinois ? 你好Prononciation chinoise, 你好Apprentissage du chinois
- 9 Comment dit-on merci en chinois ? 谢谢Prononciation chinoise, 谢谢Apprentissage du chinois
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









