 Página delantera > Programación > La mejor solución para AEC al trasladar el algoritmo matlab/octave a C
Página delantera > Programación > La mejor solución para AEC al trasladar el algoritmo matlab/octave a C
La mejor solución para AEC al trasladar el algoritmo matlab/octave a C
 Navegar:495
Navegar:495
¡Hecho! Un poco impresionado conmigo mismo.
Nuestro producto necesita la función de cancelación de eco, se identificaron tres posibles soluciones técnicas,
1) use MCU para detectar señales de audio de salida y entrada de audio, escriba un algoritmo para calcular la intensidad de los dos lados de la señal de sonido, de acuerdo con la intensidad de la salida de audio y el audio intermedio entre los dos cambios de canales opcionales, para lograr el efecto de llamada semidúplex, pero ahora en el mercado hay efecto de llamada full-duplex, el efecto semidúplex hará que el producto sea menos competitivo
(2) Utilice el algoritmo de cancelación de eco del proveedor de CPU, la eliminación de eco de prueba real no es lo suficientemente limpia debido al ajuste de todos los parámetros ajustables y muchas discusiones redondas con el proveedor, lejos del efecto esperado. La respuesta del proveedor es mejorar la carcasa para aislar el micrófono lo más posible del altavoz, pero no hay espacio para cambiar la carcasa debido al diseño de identificación, la calidad del sonido y los requisitos de volumen.
(3) Descargue los algoritmos de cancelación de eco de código abierto, como webrtc y speex, de Internet y transpórtelos al producto después de la compilación cruzada.
4) Comprar los algoritmos de una empresa que se especializa en algoritmos de audio, pero cada producto requeriría costos adicionales, lo que reduciría en gran medida la competitividad del producto.
Después de sopesar las opciones, decidí hacer una investigación en profundidad sobre la solución de utilizar algoritmos de código abierto;
Entonces, descargué una serie de códigos de cancelación de eco de github, gitee y otros sitios, tanto en C como en matlab.
Sintetiza las dos voces con una octava para generar una sección de una escena de doble conversación con la voz de captura del micrófono cercano y la voz de referencia del extremo lejano.
Luego ejecute el código descargado en línea para la cancelación del eco, analice el audio de salida y elija el algoritmo que funcione mejor entre ellos.
Según los resultados, el algoritmo AEC del procesamiento de audio webrtc no es bueno, la cancelación del eco no es limpia y es evidente que se tragan palabras en la escena de doble discurso. El algoritmo AEC3 del procesamiento de audio webrtc es limpio, pero suprime en gran medida el sonido del otro extremo del doble discurso, y el sonido es intermitente y poco natural;
El speex tiene un ligero eco, lo mejor es encontrar una implementación en lenguaje matlab del algoritmo aec, la eliminación del eco es muy limpia, el doble discurso solo produce un ligero fenómeno de deglución de palabras.
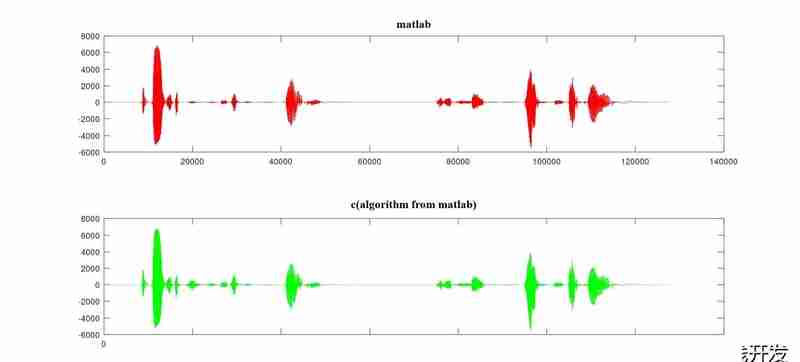
Luego, uso Visual Studio para compilar y depurar el código fuente abierto de webrtc audioprocessing aec, consulte el algoritmo aec de matlab anterior para modificar el código, uso la depuración en línea para establecer puntos de interrupción, ejecución de un solo paso y otros análisis de el valor de la declaración cambia paso a paso y, finalmente, los datos y los resultados del algoritmo aec del lenguaje matlab son idénticos. Los datos finales obtenidos son exactamente los mismos que el resultado del algoritmo aec en matlab;
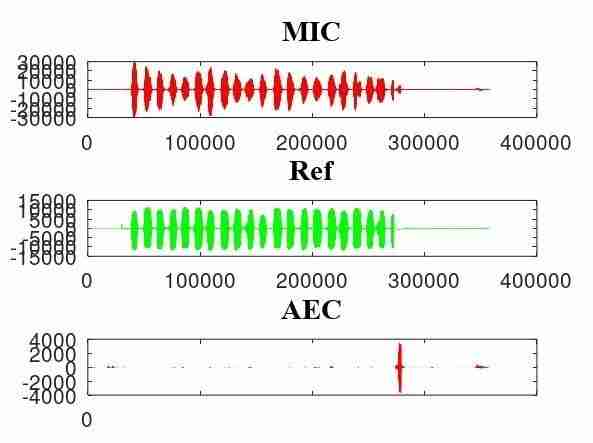
Hoy en la compilación del producto, la ganancia del MIC y del ALTAVOZ se ajustó a un valor razonable, y luego la llamada real para probar el efecto de la cancelación de eco, los resultados son sorprendentemente buenos.
Por lo tanto, existe la esperanza de diseñar un producto que pueda alcanzar ventas por encima del objetivo pequeño.
-
 Polyfills: ¿un relleno o un agujero enorme? (Parte 1)Hace unos días, recibimos un mensaje de prioridad en el chat de Teams de nuestra organización, que decía: Vulnerabilidad de seguridad encontrada: Poly...Programación Publicado el 2024-11-05
Polyfills: ¿un relleno o un agujero enorme? (Parte 1)Hace unos días, recibimos un mensaje de prioridad en el chat de Teams de nuestra organización, que decía: Vulnerabilidad de seguridad encontrada: Poly...Programación Publicado el 2024-11-05 -
Operadores de desplazamiento y asignaciones taquigráficas bit a bit1. Operadores de desplazamiento de bits : Desplazamiento a la derecha. >>>: Desplazamiento a la derecha sin signo (relleno con ceros). 2. Sintaxis gen...Programación Publicado el 2024-11-05
-
¿Cómo establecer una conexión a una base de datos MySQL desde Excel usando VBA?¿Cómo se puede conectar VBA a la base de datos MySQL en Excel?Conectarse a una base de datos MySQL usando VBAIntentando conectarse a una base de datos...Programación Publicado el 2024-11-05
-
Automatización de pruebas: Guía de Selenium con Java y TestNGLa automatización de pruebas se ha convertido en una parte integral del proceso de desarrollo de software, lo que permite a los equipos aumentar la ef...Programación Publicado el 2024-11-05
-
Mi opinión sobre una página de destino para DuckDuckGo“¿Por qué no lo buscas en Google?” es una respuesta común que recibo durante las conversaciones. La ubicuidad de Google incluso ha llevado al nuevo ve...Programación Publicado el 2024-11-05
-
¿Por qué \"cin\" de Turbo C++ solo lee la primera palabra?Limitación "cin" de Turbo C: leer solo la primera palabraEn Turbo C, el operador de entrada "cin" tiene una limitación cuando se t...Programación Publicado el 2024-11-05
-
Creación de una imagen Docker de la aplicación Spring Boot usando BuildpacksIntroducción Ha creado una aplicación Spring Boot. Está funcionando muy bien en su máquina local y ahora necesita implementar la aplicación e...Programación Publicado el 2024-11-05
-
¿Cómo proteger el código PHP del acceso no autorizado?Proteger el código PHP del acceso no autorizadoProteger la propiedad intelectual detrás de su software PHP es crucial para evitar su mal uso o robo. P...Programación Publicado el 2024-11-05
-
React: comprensión del sistema de eventos de ReactOverview of React's Event System What is a Synthetic Event? Synthetic events are an event-handling mechanism designed by React to ach...Programación Publicado el 2024-11-05
-
¿Por qué recibo un error 301 movido permanentemente cuando utilizo solicitudes POST de datos de formulario/multiparte?POST de datos de formulario/multipartesAl intentar publicar datos utilizando datos de formulario/multipartes, se pueden mostrar mensajes de error como...Programación Publicado el 2024-11-05
-
¿Cómo determinar límites temporales en PHP utilizando objetos de fecha y hora?Determinación de límites temporales en PHPEn este escenario de programación, tenemos la tarea de determinar si un tiempo determinado se encuentra dent...Programación Publicado el 2024-11-05
-
¿Cómo solucionar problemas de arrastre/cambio de tamaño de jQuery con CSS Transform Scale?Arrastrar/cambiar tamaño de jQuery con escala de transformación CSSProblema: Al aplicar una transformación CSS, específicamente transformar: matriz (0...Programación Publicado el 2024-11-05
-
¿Cómo solucionar el error \"ValueError: No se pudo convertir la matriz NumPy en tensor (tipo de objeto flotante no admitido)\" en TensorFlow?TensorFlow: resolviendo "ValueError: no se pudo convertir la matriz NumPy en tensor (tipo de objeto flotante no admitido)"Se encontró un err...Programación Publicado el 2024-11-05
-
¿Cómo determinar de manera eficiente la existencia de un artículo de almacenamiento local?Determinación de la existencia de un elemento de almacenamiento localCuando se trabaja con almacenamiento web, es fundamental verificar la existencia ...Programación Publicado el 2024-11-05
-
¿Qué es un atómico en Java? Comprensión de la atomicidad y la seguridad de subprocesos en Java1. Introducción a Atomic en Java 1.1 ¿Qué es un atómico en Java? En Java, el paquete java.util.concurrent.atomic ofrece un conjunto d...Programación Publicado el 2024-11-05















Estudiar chino
- 1 ¿Cómo se dice "caminar" en chino? 走路 pronunciación china, 走路 aprendizaje chino
- 2 ¿Cómo se dice "tomar un avión" en chino? 坐飞机 pronunciación china, 坐飞机 aprendizaje chino
- 3 ¿Cómo se dice "tomar un tren" en chino? 坐火车 pronunciación china, 坐火车 aprendizaje chino
- 4 ¿Cómo se dice "tomar un autobús" en chino? 坐车 pronunciación china, 坐车 aprendizaje chino
- 5 ¿Cómo se dice conducir en chino? 开车 pronunciación china, 开车 aprendizaje chino
- 6 ¿Cómo se dice nadar en chino? 游泳 pronunciación china, 游泳 aprendizaje chino
- 7 ¿Cómo se dice andar en bicicleta en chino? 骑自行车 pronunciación china, 骑自行车 aprendizaje chino
- 8 ¿Cómo se dice hola en chino? 你好Pronunciación china, 你好Aprendizaje chino
- 9 ¿Cómo se dice gracias en chino? 谢谢Pronunciación china, 谢谢Aprendizaje chino
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









