
El principio de construir CNN equivalentes regulares
 Navegar:326
Navegar:326
The one principle is simply stated as 'Let the kernel rotate' and we will focus in this article on how you can apply it in your architectures.
Equivariant architectures allow us to train models which are indifferent to certain group actions.
To understand what this exactly means, let us train this simple CNN model on the MNIST dataset (a dataset of handwritten digits from 0-9).
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.cl1 = nn.Conv2d(in_channels=1, out_channels=8, kernel_size=3, padding=1)
self.max_1 = nn.MaxPool2d(kernel_size=2)
self.cl2 = nn.Conv2d(in_channels=8, out_channels=16, kernel_size=3, padding=1)
self.max_2 = nn.MaxPool2d(kernel_size=2)
self.cl3 = nn.Conv2d(in_channels=16, out_channels=16, kernel_size=7)
self.dense = nn.Linear(in_features=16, out_features=10)
def forward(self, x: torch.Tensor):
x = nn.functional.silu(self.cl1(x))
x = self.max_1(x)
x = nn.functional.silu(self.cl2(x))
x = self.max_2(x)
x = nn.functional.silu(self.cl3(x))
x = x.view(len(x), -1)
logits = self.dense(x)
return logits
| Accuracy on test | Accuracy on 90-degree rotated test |
|---|---|
| 97.3% | 15.1% |
Table 1: Test accuracy of the SimpleCNN model
As expected, we get over 95% accuracy on the testing dataset, but what if we rotate the image by 90 degrees? Without any countermeasures applied, the results drop to just slightly better than guessing. This model would be useless for general applications.
In contrast, let us train a similar equivariant architecture with the same number of parameters, where the group actions are exactly the 90-degree rotations.
| Accuracy on test | Accuracy on 90-degree rotated test |
|---|---|
| 96.5% | 96.5% |
Table 2: Test accuracy of the EqCNN model with the same amount of parameters as the SimpleCNN model
The accuracy remains the same, and we did not even opt for data augmentation.
These models become even more impressive with 3D data, but we will stick with this example to explore the core idea.
In case you want to test it out for yourself, you can access all code written in both PyTorch and JAX for free under Github-Repo, and training with Docker or Podman is possible with just two commands.
Have fun!
So What is Equivariance?
Equivariant architectures guarantee stability of features under certain group actions. Groups are simple structures where group elements can be combined, reversed, or do nothing.
You can look up the formal definition on Wikipedia if you are interested.
For our purposes, you can think of a group of 90-degree rotations acting on square images. We can rotate an image by 90, 180, 270, or 360 degrees. To reverse the action, we apply a 270, 180, 90, or 0-degree rotation respectively. It is straightforward to see that we can combine, reverse, or do nothing with the group denoted as C4 . The image visualizes all actions on an image.
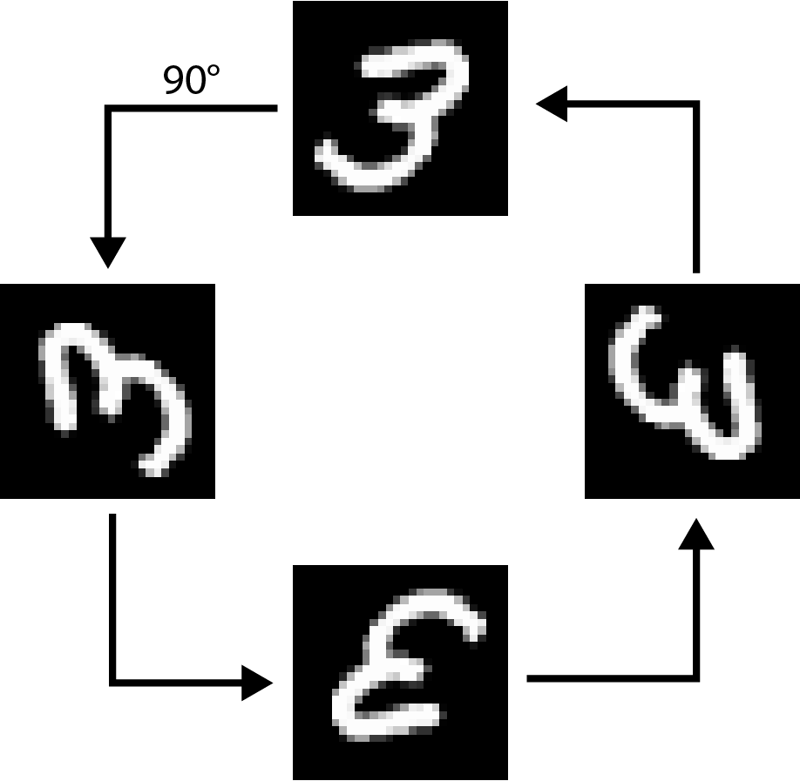
Figure 1: Rotated MNIST image by 90°, 180°, 270°, 360°, respectively
Now, given an input image
x
, our CNN model classifier
fθ
, and an arbitrary 90-degree rotation
g
, the equivariant property can be expressed as
fθ(rotate x by g)=fθ(x)
Generally speaking, we want our image-based model to have the same outputs when rotated.
As such, equivariant models promise us architectures with baked-in symmetries. In the following section, we will see how our principle can be applied to achieve this property.
How to Make Our CNN Equivariant
The problem is the following: When the image rotates, the features rotate too. But as already hinted, we could also compute the features for each rotation upfront by rotating the kernel.
We could actually rotate the kernel, but it is much easier to rotate the feature map itself, thus avoiding interference with PyTorch's autodifferentiation algorithm altogether.
So, in code, our CNN kernel
x = nn.functional.silu(self.cl1(x))
now acts on all four rotated images:
x_0 = x x_90 = torch.rot90(x, k=1, dims=(2, 3)) x_180 = torch.rot90(x, k=2, dims=(2, 3)) x_270 = torch.rot90(x, k=3, dims=(2, 3)) x_0 = nn.functional.silu(self.cl1(x_0)) x_90 = nn.functional.silu(self.cl1(x_90)) x_180 = nn.functional.silu(self.cl1(x_180)) x_270 = nn.functional.silu(self.cl1(x_270))
Or more compactly written as a 3D convolution:
self.cl1 = nn.Conv3d(in_channels=1, out_channels=8, kernel_size=(1, 3, 3)) ... x = torch.stack([x_0, x_90, x_180, x_270], dim=-3) x = nn.functional.silu(self.cl1(x))
The resulting equivariant model has just a few lines more compared to the version above:
class EqCNN(nn.Module):
def __init__(self):
super(EqCNN, self).__init__()
self.cl1 = nn.Conv3d(in_channels=1, out_channels=8, kernel_size=(1, 3, 3))
self.max_1 = nn.MaxPool3d(kernel_size=(1, 2, 2))
self.cl2 = nn.Conv3d(in_channels=8, out_channels=16, kernel_size=(1, 3, 3))
self.max_2 = nn.MaxPool3d(kernel_size=(1, 2, 2))
self.cl3 = nn.Conv3d(in_channels=16, out_channels=16, kernel_size=(1, 5, 5))
self.dense = nn.Linear(in_features=16, out_features=10)
def forward(self, x: torch.Tensor):
x_0 = x
x_90 = torch.rot90(x, k=1, dims=(2, 3))
x_180 = torch.rot90(x, k=2, dims=(2, 3))
x_270 = torch.rot90(x, k=3, dims=(2, 3))
x = torch.stack([x_0, x_90, x_180, x_270], dim=-3)
x = nn.functional.silu(self.cl1(x))
x = self.max_1(x)
x = nn.functional.silu(self.cl2(x))
x = self.max_2(x)
x = nn.functional.silu(self.cl3(x))
x = x.squeeze()
x = torch.max(x, dim=-1).values
logits = self.dense(x)
return logits
But why is this equivariant to rotations?
First, observe that we get four copies of each feature map at each stage. At the end of the pipeline, we combine all of them with a max operation.
This is key, the max operation is indifferent to which place the rotated version of the feature ends up in.
To understand what is happening, let us plot the feature maps after the first convolution stage.
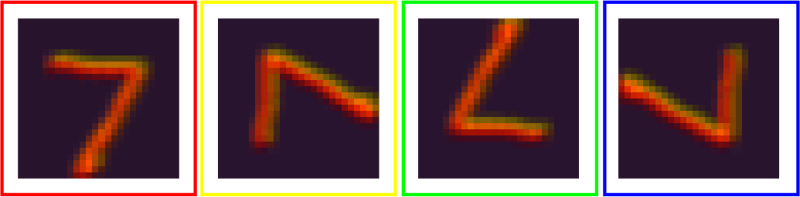
Figure 2: Feature maps for all four rotations
And now the same features after we rotate the input by 90 degrees.
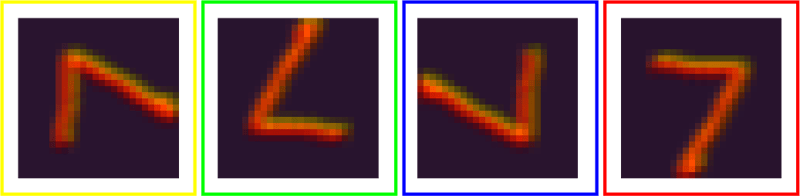
Figure 3: Feature maps for all four rotations after the input image was rotated
I color-coded the corresponding maps. Each feature map is shifted by one. As the final max operator computes the same result for these shifted feature maps, we obtain the same results.
In my code, I did not rotate back after the final convolution, since my kernels condense the image to a one-dimensional array. If you want to expand on this example, you would need to account for this fact.
Accounting for group actions or "kernel rotations" plays a vital role in the design of more sophisticated architectures.
Is it a Free Lunch?
No, we pay in computational speed, inductive bias, and a more complex implementation.
The latter point is somewhat solved with libraries such as E3NN, where most of the heavy math is abstracted away. Nevertheless, one needs to account for a lot during architecture design.
One superficial weakness is the 4x computational cost for computing all rotated feature layers. However, modern hardware with mass parallelization can easily counteract this load. In contrast, training a simple CNN with data augmentation would easily exceed 10x in training time. This gets even worse for 3D rotations where data augmentation would require about 500x the training amount to compensate for all possible rotations.
Overall, equivariance model design is more often than not a price worth paying if one wants stable features.
What is Next?
Equivariant model designs have exploded in recent years, and in this article, we barely scratched the surface. In fact, we did not even exploit the full C4 group yet. We could have used full 3D kernels. However, our model already achieves over 95% accuracy, so there is little reason to go further with this example.
Besides CNNs, researchers have successfully translated these principles to continuous groups, including SO(2) (the group of all rotations in the plane) and SE(3) (the group of all translations and rotations in 3D space).
In my experience, these models are absolutely mind-blowing and achieve performance, when trained from scratch, comparable to the performance of foundation models trained on multiple times larger datasets.
Let me know if you want me to write more on this topic.
Further References
In case you want a formal introduction to this topic, here is an excellent compilation of papers, covering the complete history of equivariance in Machine Learning.
AEN
I actually plan to create a deep-dive, hands-on tutorial on this topic. You can already sign up for my mailing list, and I will provide you with free versions over time, along with a direct channel for feedback and Q&A.
See you around :)
-
 ¿Cómo puedo convertir de forma segura un puntero en un número entero en máquinas de 64 bits?Conversión de un puntero en un número entero: revisada para máquinas de 64 bitsEn C/C, un error potencial al tratar con 64 bits máquinas de bits surge...Programación Publicado el 2024-12-23
¿Cómo puedo convertir de forma segura un puntero en un número entero en máquinas de 64 bits?Conversión de un puntero en un número entero: revisada para máquinas de 64 bitsEn C/C, un error potencial al tratar con 64 bits máquinas de bits surge...Programación Publicado el 2024-12-23 -
¿Cómo abrir de forma segura archivos HTML locales en Chrome?¿Cómo iniciar HTML usando Chrome en el modo "--allow-file-access-from-files"?Navegando por este problema requiere iniciar el archivo HTML a ...Programación Publicado el 2024-12-23
-
¿Cómo generar dinámicamente opciones para elementos seleccionados en JavaScript?Generación de opciones dinámicas para elementos seleccionados con JavaScriptEn el desarrollo web, a menudo nos encontramos con la necesidad de crear o...Programación Publicado el 2024-12-23
-
¿Por qué no funciona Word-Wrap en tablas HTML y cómo puedo solucionarlo?Word-wrap en una tabla HTML: corrección de texto sin envolverWord-wrap es una propiedad CSS utilizada para permitir que el texto se ajuste dentro de e...Programación Publicado el 2024-12-23
-
¿Cuándo debería utilizar `std::size_t` para contadores de bucles en C++?Cuándo utilizar std::size_t en su código CPregunta:Cuándo Al trabajar con bucles dentro de C, particularmente en escenarios donde se compara el tamaño...Programación Publicado el 2024-12-23
-
¿Debo utilizar codificación Base64 para imágenes en mi sitio web?Comprender el impacto de codificar imágenes en Base64La conversión de imágenes a codificación Base64 es una práctica común en el desarrollo web. Sin e...Programación Publicado el 2024-12-23
-
¿Cómo combino dos matrices asociativas en PHP manteniendo ID únicas y manejando nombres duplicados?Combinando matrices asociativas en PHPEn PHP, combinar dos matrices asociativas en una sola matriz es una tarea común. Considere la siguiente solicitu...Programación Publicado el 2024-12-23
-
¿Cómo convierto correctamente matrices Java en listas, teniendo en cuenta los comportamientos específicos de la versión?Conversión de matrices en listas en Java: un viaje a través de las transformaciones de matrices y listasEn el ámbito de la manipulación de datos, la c...Programación Publicado el 2024-12-23
-
¿Por qué Python arroja un UnboundLocalError?Cómo ocurre UnboundLocalError: nombres independientes y enlace de variables en PythonEn Python, el enlace de variables determina el alcance y la vida ...Programación Publicado el 2024-12-23
-
Libere sus habilidades de desarrollo web con el curso "Inicio rápido con jQuery"¿Estás listo para mejorar tu experiencia en desarrollo web y desbloquear el poder de la biblioteca JavaScript más popular, jQuery? No busque más, el c...Programación Publicado el 2024-12-23
-
¿Cómo manejar registros con múltiples valores en una cláusula MySQL WHERE IN()?Operador MySQL IN ()Al consultar una base de datos MySQL, el operador WHERE IN () se utiliza a menudo para recuperar filas en función de datos específ...Programación Publicado el 2024-12-23
-
¿Cómo filtrar filas de matriz según el valor de la columna que coincida con valores específicos?Subconjunto de filas basado en la inclusión del valor de la columnaConsidere una matriz, $arr1, con varias columnas y una segunda matriz plana, $arr2,...Programación Publicado el 2024-12-23
-
¿Cómo puedo combinar varias imágenes de Docker en una sola imagen usando DockerMake?Combinación de varias imágenes de DockerLa combinación de varias imágenes de Docker en una única imagen unificada no es compatible directamente con Do...Programación Publicado el 2024-12-23
-
FormaciónLos métodos son fns que se pueden invocar en objetos Los arreglos son objetos, por lo tanto también tienen métodos en JS. segmento (comienzo):...Programación Publicado el 2024-12-23
-
¿Cómo gestiona la función `cvWaitKey()` de OpenCV la interacción del usuario y los eventos de ventana?Explorando la funcionalidad de 'cvWaitKey()' de OpenCVLa función 'cvWaitKey()' de OpenCV juega un papel crucial en la gestión de la in...Programación Publicado el 2024-12-23















Estudiar chino
- 1 ¿Cómo se dice "caminar" en chino? 走路 pronunciación china, 走路 aprendizaje chino
- 2 ¿Cómo se dice "tomar un avión" en chino? 坐飞机 pronunciación china, 坐飞机 aprendizaje chino
- 3 ¿Cómo se dice "tomar un tren" en chino? 坐火车 pronunciación china, 坐火车 aprendizaje chino
- 4 ¿Cómo se dice "tomar un autobús" en chino? 坐车 pronunciación china, 坐车 aprendizaje chino
- 5 ¿Cómo se dice conducir en chino? 开车 pronunciación china, 开车 aprendizaje chino
- 6 ¿Cómo se dice nadar en chino? 游泳 pronunciación china, 游泳 aprendizaje chino
- 7 ¿Cómo se dice andar en bicicleta en chino? 骑自行车 pronunciación china, 骑自行车 aprendizaje chino
- 8 ¿Cómo se dice hola en chino? 你好Pronunciación china, 你好Aprendizaje chino
- 9 ¿Cómo se dice gracias en chino? 谢谢Pronunciación china, 谢谢Aprendizaje chino
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









