
ResNet frente a EfficientNet frente a VGG frente a NN
 Navegar:792
Navegar:792
Como estudiante, he sido testigo de primera mano de la frustración causada por el ineficiente sistema de objetos perdidos de nuestra universidad. El proceso actual, que depende de correos electrónicos individuales para cada artículo encontrado, a menudo genera retrasos y pérdida de conexiones entre las pertenencias perdidas y sus propietarios.
Impulsado por el deseo de mejorar esta experiencia para mí y para mis compañeros de estudios, me embarqué en un proyecto para explorar el potencial del aprendizaje profundo para revolucionar nuestro sistema de objetos perdidos y encontrados. En esta publicación de blog, compartiré mi viaje de evaluación de modelos previamente entrenados (ResNet, EfficientNet, VGG y NasNet) para automatizar la identificación y categorización de elementos perdidos.
A través de un análisis comparativo, mi objetivo es identificar el modelo más adecuado para integrarlo en nuestro sistema y, en última instancia, crear una experiencia de objetos perdidos más rápida, precisa y fácil de usar para todos en el campus.
Resnet
Inception-ResNet V2 es una poderosa arquitectura de red neuronal convolucional disponible en Keras, que combina las fortalezas de la arquitectura Inception con conexiones residuales de ResNet. Este modelo híbrido tiene como objetivo lograr una alta precisión en las tareas de clasificación de imágenes manteniendo la eficiencia computacional.
Conjunto de datos de entrenamiento: ImageNet
Formato de imagen: 299 x 299
Función de preprocesamiento
def readyForResNet(fileName):
pic = load_img(fileName, target_size=(299, 299))
pic_array = img_to_array(pic)
expanded = np.expand_dims(pic_array, axis=0)
return preprocess_input_resnet(expanded)
Predecir
data1 = readyForResNet(test_file) prediction = inception_model_resnet.predict(data1) res1 = decode_predictions_resnet(prediction, top=2)
VGG (Grupo de Geometría Visual)
VGG (Visual Geometry Group) es una familia de arquitecturas de redes neuronales convolucionales profundas conocidas por su simplicidad y eficacia en tareas de clasificación de imágenes. Estos modelos, en particular VGG16 y VGG19, ganaron popularidad debido a su sólido desempeño en el ImageNet Large Scale Visual Recognition Challenge (ILSVRC) en 2014.
Conjunto de datos de entrenamiento: ImageNet
Formato de imagen: 224 x 224
Función de preprocesamiento
def readyForVGG(fileName):
pic = load_img(fileName, target_size=(224, 224))
pic_array = img_to_array(pic)
expanded = np.expand_dims(pic_array, axis=0)
return preprocess_input_vgg19(expanded)
Predecir
data2 = readyForVGG(test_file) prediction = inception_model_vgg19.predict(data2) res2 = decode_predictions_vgg19(prediction, top=2)
Red eficiente
EfficientNet es una familia de arquitecturas de redes neuronales convolucionales que logran una precisión de vanguardia en tareas de clasificación de imágenes y, al mismo tiempo, son significativamente más pequeñas y más rápidas que los modelos anteriores. Esta eficiencia se logra a través de un novedoso método de escalado compuesto que equilibra la profundidad, el ancho y la resolución de la red.
Conjunto de datos de entrenamiento: ImageNet
Formato de imagen: 480 x 480
Función de preprocesamiento
def readyForEF(fileName):
pic = load_img(fileName, target_size=(480, 480))
pic_array = img_to_array(pic)
expanded = np.expand_dims(pic_array, axis=0)
return preprocess_input_EF(expanded)
Predecir
data3 = readyForEF(test_file) prediction = inception_model_EF.predict(data3) res3 = decode_predictions_EF(prediction, top=2)
Nasnet
NasNet (Red de búsqueda de arquitectura neuronal) representa un enfoque innovador en el aprendizaje profundo donde la arquitectura de la propia red neuronal se descubre a través de un proceso de búsqueda automatizado. Este proceso de búsqueda tiene como objetivo encontrar la combinación óptima de capas y conexiones para lograr un alto rendimiento en una tarea determinada.
Conjunto de datos de entrenamiento: ImageNet
Formato de imagen: 224 x 224
Función de preprocesamiento
def readyForNN(fileName):
pic = load_img(fileName, target_size=(224, 224))
pic_array = img_to_array(pic)
expanded = np.expand_dims(pic_array, axis=0)
return preprocess_input_NN(expanded)
Predecir
data4 = readyForNN(test_file) prediction = inception_model_NN.predict(data4) res4 = decode_predictions_NN(prediction, top=2)
Confrontación
Exactitud
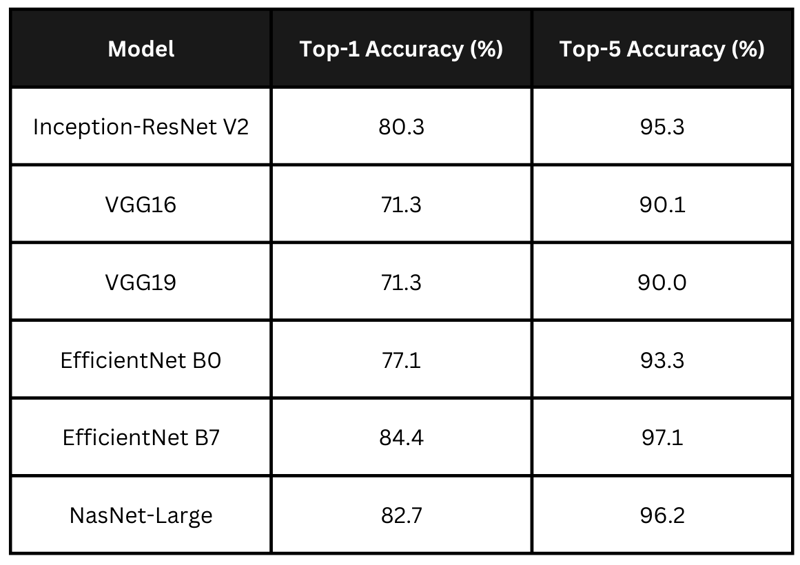
La tabla resume las puntuaciones de precisión declaradas de los modelos anteriores. EfficientNet B7 lidera con la mayor precisión, seguido de cerca por NasNet-Large e Inception-ResNet V2. Los modelos VGG presentan precisiones más bajas. Para mi aplicación quiero elegir un modelo que tenga un equilibrio entre tiempo de procesamiento y precisión.
Tiempo
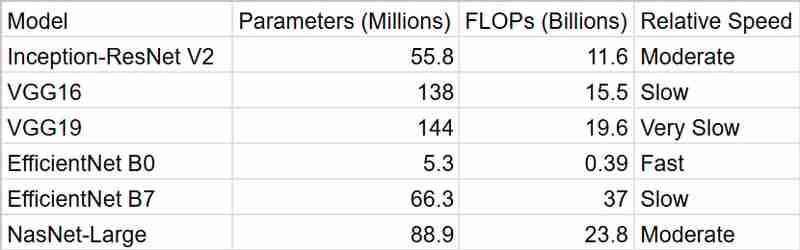
Como podemos ver, EfficientNetB0 nos proporciona los resultados más rápidos, pero InceptionResNetV2 es un mejor paquete si se tiene en cuenta la precisión
Resumen
Para mi sistema inteligente de objetos perdidos, decidí utilizar InceptionResNetV2. Si bien EfficientNet B7 parecía tentador por su precisión de primer nivel, me preocupaban sus demandas computacionales. En un entorno universitario, donde los recursos pueden ser limitados y el rendimiento en tiempo real suele ser deseable, sentí que era importante lograr un equilibrio entre precisión y eficiencia. InceptionResNetV2 parecía la opción perfecta: ofrece un rendimiento sólido sin ser demasiado intensivo desde el punto de vista computacional.
Además, el hecho de que esté previamente entrenado en ImageNet me da la confianza de que puede manejar la diversa gama de objetos que las personas podrían perder. ¡Y no olvidemos lo fácil que es trabajar con Keras! Eso definitivamente hizo que mi decisión fuera más fácil.
En general, creo que InceptionResNetV2 proporciona la combinación adecuada de precisión, eficiencia y practicidad para mi proyecto. ¡Estoy emocionado de ver cómo funciona para ayudar a reunir los objetos perdidos con sus dueños!
-
 ¿Por qué Microsoft Visual C ++ no implementa correctamente la instanciación de la plantilla de dos fases?El misterio de la plantilla de dos fases "roto" instanciación en Microsoft Visual c declaración de problemas: usuarios comúnmente ...Programación Publicado el 2025-03-12
¿Por qué Microsoft Visual C ++ no implementa correctamente la instanciación de la plantilla de dos fases?El misterio de la plantilla de dos fases "roto" instanciación en Microsoft Visual c declaración de problemas: usuarios comúnmente ...Programación Publicado el 2025-03-12 -
UTF-8 vs. Latin-1: ¡la codificación del secreto del carácter!Distinguing UTF-8 y LATIN1 Cuando se trata de codificar, emergen dos opciones prominentes: UTF-8 y LATIN1. En medio de sus aplicaciones, surge...Programación Publicado el 2025-03-12
-
FormaciónLos métodos son fns que se pueden llamar a los objetos Las matrices son objetos, por lo tanto, también tienen métodos en js. Slice (Begi...Programación Publicado el 2025-03-12
-
Parte Serie de inyección SQL: explicación detallada de las técnicas avanzadas de inyección SQLautor: trix cyrus WayMap Pentesting Tool: Haga clic aquí Trixsec Github: haga clic aquí TrixSec Telegram: haga clic aquí Explotos ...Programación Publicado el 2025-03-12
-
¿Cómo podemos asegurar las cargas de archivos contra contenido malicioso?Las preocupaciones de seguridad con las cargas de archivo Los archivos de carga a un servidor pueden introducir riesgos de seguridad significa...Programación Publicado el 2025-03-12
-
¿Cómo eliminar los descansos de línea de las cadenas usando expresiones regulares en JavaScript?Eliminación de rupturas de línea de las cadenas En este escenario de código, el objetivo es eliminar las rupturas de línea de una cadena de text...Programación Publicado el 2025-03-12
-
¿Por qué cesan la ejecución de JavaScript cuando se usa el botón de retroceso de Firefox?Problema de historial de navegación: JavaScript deja de ejecutar después de usar el botón de retroceso de Firefox Los usuarios de Firefox pued...Programación Publicado el 2025-03-12
-
¿Cómo insertar correctamente las blobs (imágenes) en MySQL usando PHP?Inserte blobs en bases de datos MySQL con php Al intentar almacenar una imagen en una base de datos MySQL, puede encontrar un asunto. Esta gu...Programación Publicado el 2025-03-12
-
¿Puedo migrar mi cifrado de MCRYPT a OpenSSL y descifrar datos cifrados de MCRYPT usando OpenSSL?actualizando mi biblioteca de cifrado de MCRYP En OpenSSL, ¿es posible descifrar datos encriptados con MCRYPT? Dos publicaciones diferentes propo...Programación Publicado el 2025-03-12
-
¿Existe una diferencia de rendimiento entre usar un bucle for-ENTRES y un iterador para la transmisión de recorrido en Java?para cada bucle vs. iterator: eficiencia en la colección traversal introduction cuando la colección en java, la opción, la opción iba entr...Programación Publicado el 2025-03-12
-
¿Cómo verificar si un objeto tiene un atributo específico en Python?para determinar el atributo de objeto existencia Esta consulta busca un método para verificar la presencia de un atributo específico dentro de...Programación Publicado el 2025-03-12
-
Explicación detallada del método de adquisición de elementos aleatorios de Java Hashset/Linkedhashsetpara encontrar un elemento aleatorio en un set en programación, puede ser útil seleccionar un elemento aleatorio de una colección, como un conju...Programación Publicado el 2025-03-12
-
¿Cuándo los atributos CSS se vuelven a caer a los píxeles (PX) sin unidades?fallback para atributos CSS sin unidades: un estudio de caso atributos CSS a menudo requiere unidades (por ejemplo, PX, EM, %) para especifica...Programación Publicado el 2025-03-12
-
¿Cómo recuperar la última biblioteca jQuery de Google API?recuperando la última biblioteca jQuery de Google APIS La URL de jQuery proporcionada en la pregunta es para la versión 1.2.6. Para recuperar ...Programación Publicado el 2025-03-12
-
¿Cuáles fueron las restricciones al usar Current_Timestamp con columnas de marca de tiempo en MySQL antes de la versión 5.6.5?en las columnas de la marca de tiempo con cursion_timestamp en predeterminado o en las cláusulas de actualización en las versiones mySql antes de ...Programación Publicado el 2025-03-12















Estudiar chino
- 1 ¿Cómo se dice "caminar" en chino? 走路 pronunciación china, 走路 aprendizaje chino
- 2 ¿Cómo se dice "tomar un avión" en chino? 坐飞机 pronunciación china, 坐飞机 aprendizaje chino
- 3 ¿Cómo se dice "tomar un tren" en chino? 坐火车 pronunciación china, 坐火车 aprendizaje chino
- 4 ¿Cómo se dice "tomar un autobús" en chino? 坐车 pronunciación china, 坐车 aprendizaje chino
- 5 ¿Cómo se dice conducir en chino? 开车 pronunciación china, 开车 aprendizaje chino
- 6 ¿Cómo se dice nadar en chino? 游泳 pronunciación china, 游泳 aprendizaje chino
- 7 ¿Cómo se dice andar en bicicleta en chino? 骑自行车 pronunciación china, 骑自行车 aprendizaje chino
- 8 ¿Cómo se dice hola en chino? 你好Pronunciación china, 你好Aprendizaje chino
- 9 ¿Cómo se dice gracias en chino? 谢谢Pronunciación china, 谢谢Aprendizaje chino
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









