
Cómo realizar voz en tiempo real con Dify API
 Navegar:535
Navegar:535
Dify es una plataforma SaaS de código abierto para crear flujos de trabajo LLM en línea. Estoy usando la API para crear una experiencia de IA conversacional en mi aplicación. Tenía dificultades para obtener transmisiones TTS como respuesta API y reproducirlas. Aquí demuestro cómo procesar las transmisiones de audio y reproducirlas correctamente.
Estoy usando el punto final API https://api.dify.ai/v1/chat-messages para chat de texto. Devuelve datos de audio en la misma secuencia que la respuesta de texto si habilitamos la función Texto a voz en nuestras aplicaciones Dify.
Presione el botón AGREGAR FUNCIÓN y agregue la función Texto a voz.
Puedes comprobar la respuesta de la API con el siguiente comando curl.
curl -X POST 'https://api.dify.ai/v1/chat-messages' \
--header 'Authorization: Bearer YOUR_API_KEY' \
--header 'Content-Type: application/json' \
--data-raw '{
"inputs": {},
"query": "What are the specs of the iPhone 13 Pro Max?",
"response_mode": "streaming",
"conversation_id": "",
"user": "abc-123",
"files": []
}'
Lo demuestro en TypeScript/JavaScript, pero puedes aplicar la misma lógica a tu lenguaje de programación.
Anatomía de los datos transmitidos
Primero, comprendamos qué tipo de datos utiliza Dify para las transmisiones.
Formato de datos transmitidos
Dify utiliza el siguiente formato de datos de texto. Es como líneas JSON pero no es exactamente igual.
data: {"event": "workflow_started", "conversation_id": "065fb118-35d4-4524-a067-a70338ece575", "message_id": "3f0fe3cf-5aa1-4f7c-8abe-2505bf07ae8f", "created_at": 1724478014, "task_id": "dacb2d5c-a6f5-44b5-b5a6-de000f24aeba", "workflow_run_id": "50100b30-e458-4632-ad7d-8dd383823376", "data": {"id": "50100b30-e458-4632-ad7d-8dd383823376", "workflow_id": "debdb4fa-dcab-4233-9413-fd6d17b9e36a", "sequence_number": 334, "inputs": {"sys.query": "What are the specs of the iPhone 13 Pro Max?", "sys.files": [], "sys.conversation_id": "065fb118-35d4-4524-a067-a70338ece575", "sys.user_id": "abc-123"}, "created_at": 1724478014}}
data: {"event": "node_started", "conversation_id": "065fb118-35d4-4524-a067-a70338ece575", "message_id": "3f0fe3cf-5aa1-4f7c-8abe-2505bf07ae8f", "created_at": 1724478014, "task_id": "dacb2d5c-a6f5-44b5-b5a6-de000f24aeba", "workflow_run_id": "50100b30-e458-4632-ad7d-8dd383823376", "data": {"id": "bf912f43-29dd-4ee2-aefa-0fabdf379257", "node_id": "1721365917005", "node_type": "start", "title": "\u958b\u59cb", "index": 1, "predecessor_node_id": null, "inputs": null, "created_at": 1724478013, "extras": {}}}
data: {"event": "node_finished", "conversation_id": "065fb118-35d4-4524-a067-a70338ece575", "message_id": "3f0fe3cf-5aa1-4f7c-8abe-2505bf07ae8f", "created_at": 1724478014, "task_id": "dacb2d5c-a6f5-44b5-b5a6-de000f24aeba", "workflow_run_id": "50100b30-e458-4632-ad7d-8dd383823376", "data": {"id": "bf912f43-29dd-4ee2-aefa-0fabdf379257", "node_id": "1721365917005", "node_type": "start", "title": "\u958b\u59cb", "index": 1, "predecessor_node_id": null, "inputs": {"sys.query": "What are the specs of the iPhone 13 Pro Max?", "sys.files": [], "sys.conversation_id": "065fb118-35d4-4524-a067-a70338ece575", "sys.user_id": "abc-123", "sys.dialogue_count": 1}, "process_data": null, "outputs": {"sys.query": "What are the specs of the iPhone 13 Pro Max?", "sys.files": [], "sys.conversation_id": "065fb118-35d4-4524-a067-a70338ece575", "sys.user_id": "abc-123", "sys.dialogue_count": 1}, "status": "succeeded", "error": null, "elapsed_time": 0.001423838548362255, "execution_metadata": null, "created_at": 1724478013, "finished_at": 1724478013, "files": []}}
data: {"event": "node_started", "conversation_id": "065fb118-35d4-4524-a067-a70338ece575", "message_id": "3f0fe3cf-5aa1-4f7c-8abe-2505bf07ae8f", "created_at": 1724478014, "task_id": "dacb2d5c-a6f5-44b5-b5a6-de000f24aeba", "workflow_run_id": "50100b30-e458-4632-ad7d-8dd383823376", "data": {"id": "89ed58ab-6157-499b-81b2-92b1336969a5", "node_id": "llm", "node_type": "llm", "title": "LLM", "index": 2, "predecessor_node_id": "1721365917005", "inputs": null, "created_at": 1724478013, "extras": {}}}
...
En la respuesta, Dify envía respuesta de texto y datos de audio.
Ejemplo de respuesta de línea de texto
data: {"event": "message", "conversation_id": "aa13eb24-e90a-4c5d-a36b-756f0e3be8f8", "message_id": "5be739a9-09ba-4444-9905-a2f37f8c7a21", "created_at": 1724301648, "task_id": "0643f770-e9d3-408f-b771-bb2e9430b4f9", "id": "5be739a9-09ba-4444-9905-a2f37f8c7a21", "answer": "MP"}
Línea de ejemplo de datos de audio
data: {"event": "tts_message", "conversation_id": "aa13eb24-e90a-4c5d-a36b-756f0e3be8f8", "message_id": "5be739a9-09ba-4444-9905-a2f37f8c7a21", "created_at": 1724301648, "task_id": "0643f770-e9d3-408f-b771-bb2e9430b4f9", "audio": "//PkxABhvDm0DVp4ACUUfvWc1CFlh0tR9Oh7LxzHRsGBuGx155x3JqTJiwKKZf8wIcxpMzJU0h4zhgyQwwwIsgWQMAALQMkanBTjfCPgZwFsDOGGIYJoJoJoJoPQPQLYEgAOwM4SMXMW8TcNWGrEPEME0HoIQTg0DQNA0C5k7IOLeJuDnDVi5nWyJwgghAagQwTQQgJAGrDVibiFhqw1YR8HOEjBUA5AcgagQwTQTQQgJAAtgLYKsQ8hZc0PV7OrE4SgQgFIAsAQAwA6H0Uv4t4m4m49Yt4uYOQHIBkAyAqAkAuB0Mm6UeKxDGRrIODkByBqBNBCA1ARwHIEgBVg5wkY41W2GgdEVDFBNe HicQw0ydk7HrHrIWXM62d48ePNfCkNATcTcNWGrCRhqxDxcwMYBwBkByCGC4EILgoJTQUDeW8W8TcTchZ1qBWIYchOBbBCA1AhgSMJGGrFzLmh6fL LeBkAyAZAcgSAXAhB0Kxnj4YDkJwXA6FAzwj8IIJoJoPQXA6EPOcg4R8FOBnCRljRAwlwoh4EUwLhFTCVA MR0R8wyxOhgAwwDgJjBUABMM0hMxBgnTPtMrMBEEcwJQCzIXIdMZMG821DmjDKHJAwLDKHRMQsJkwbwVRoFs//PkxEx5dDnwAZ7wANHgEUFJHGCUCQp3LWCQQYGAATI5QzwHBJF4UFktpfATT2l0goAGNADLOU64HAMCQCK50szABAIkDS2/j8gl6l6Di7QgBEiAfMEADBnyZBgeAWCMK4xvBbhoRZj1M ktsNMTrMNcHEwHQEzAjAHMGQAQwRQZTBHALMGMDkzhh2jGhLtMgsMMwfhOzCnGLMMcKgwOw8pqHMoGtvdDzos0AIAiXIsBAmGsRFtYcBABmB0AUYjQfhhDAfjoCrETAGArMOAJ4iAAMCMFkwXwh5fffuhpYMhyP2bl3MVAJQrSYQDsna7G2 fx/GvyAwUQbTAdAFCAHVKyIAduTXHZZXDjNS57/VeVJ5 JBJ 0kATkCSells8/NBt/2/5Dj1s chDBYSINutNS9FQwDwBWHjgASKRgAAJOyYC4Ao0CMNAKBgB6KK1hYBkAAHROM9mLsknb8avTcB0MerV6jl7llE70egOerRh9WcP/FoHqtVsO/In2f G2tsdnH L/KSSvBQB4OATam27Yi4jiBgBFOpq15bTQU6k1G4LoWo1mMAwDQwlBEzEnKsMkA7c5JYuTOzK2MvAbEysSPTM dOOn1XEzGgIzXzmPODVvs1cyNTJxQ9MsAWwy//PkxDlz7DIMAd7gAek5EwnjcjX9QVN1N0czFyijQKOmMi4IYw8RvzFvCHMHYBQwdQlTRxVNvm8ycGjLYlMTAQ=="}
Podemos distinguir líneas JSON de datos de audio verificando la propiedad del evento. Audio JSON tiene tts_message como valor. El binario de audio mp3 se almacena en la propiedad de audio de los JSON en formato base64.
Problemas en el manejo de datos.
El primer problema que tenemos cuando reproducimos audio TTS en tiempo real es que las líneas JSON se dividen en paquetes y cada paquete no son datos JSON válidos tal como están.
Ejemplo de paquete cortado por la mitad
euimRrhsPMZiMAl BqSZMDmIkQEcDb/8 TEtHm8MhwA3p/p8dA0CCpAxwMMPABoYMIWwUDG6BRmiYZg2G6gRidGanOm5i5iaIYmfkH8Z/FmEopqJGZKXihYEIRxCKYKtlQuMvPjPQIwUVFFECDRnRCYEimGmA6cji41yQMImMEmhaHrVKpCxo2OYx6Q5RcJKAKkah4X6MckHEqdwKgHGHltDUjCy46HMgTCpwodAM8KijREwSSEk5hB4gRGFfC0ouYoeDiYtNREDgKQsTT6EI4egmMMBxpQZmoUJmAAg6YPDmQISgSECAZQOLfAUEQAG/dgxAVkxfFHGorEHB4CS Yugwk2gq8akIwMsZIuIzUSrCAGm1iBnoYA8lcoYSlaIJ5RjCblwbsh8sB3skA7Gcx3zmSOKnXNJO6ObKklhuYjlVL1dSMhgwVJtFzMeWFufNKy3ODmCExBTUUzLjEwMKqqqqqqqqqqqqqqqqqqCIEWFIAA4DAWKkMDDIBA4lBqGDdmZwzAkGJFoYiwEV0IQOQHg1AATJiUM6F0z2fDE6PMvlc6DhTMJ MNH4xWwzBwKMMCgHAwwUFQwjGEgMgovgIBMIMECYxYSDKAwSoMOBC4Ez682pEZIB8kBuiawZEaSnFAjIEwSFRxGUJIXMGRMmfNCPApcKL/8 TEiVdEKlJm5pM9gz0MyScwo04BgqjEFh489MGKVw=="}
El paquete comienza desde el medio de una línea JSON. Tenemos que combinar varios paquetes para obtener líneas JSON válidas.
El segundo problema es que el fragmento de datos de audio en un JSON no es un dato de audio válido. Los datos se cortan en medio de fotogramas de mp3.
Implementación
Para manejar los datos divididos de JSON y mp3, tenemos que hacerlo de alguna manera inteligente. El flujo del proceso es el siguiente:
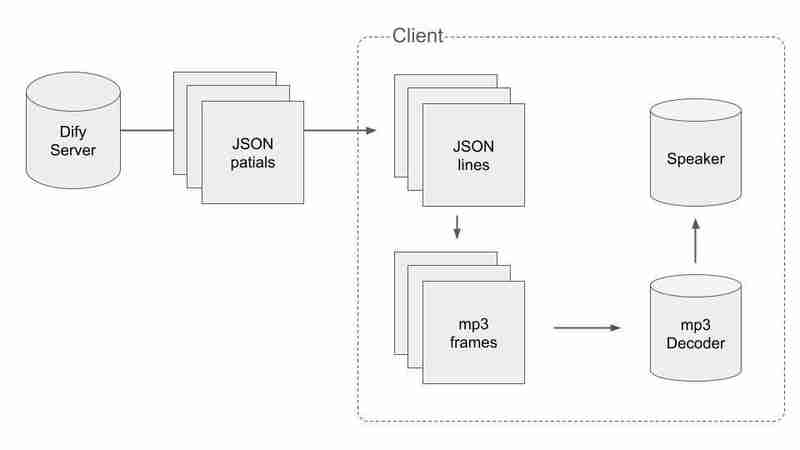
Primero, tenemos que obtener datos JSON válidos y dividirlos en JSON mientras recibimos paquetes. Cuando recibimos un paquete con \n al final, podemos decir que la concatenación de los paquetes recibidos hasta el momento no se corta por la mitad. El pseudocódigo es así.
let packets = []
stream.on('data', (bytes) => {
const text = bytes.toString()
packets.push(text)
if (text.endsWith('\n')) {
// Extract audio data from the packets.
const audioChunks = extractAudioChunks(packets.join(''))
// Clear the packet array
packets = []
}
})
En segundo lugar, tenemos que dividir los fragmentos de audio en fotogramas mp3. Concatenamos los fragmentos de audio en un binario y encontramos cada cuadro de mp3 en él.
const mp3Frames = [] const binaryToProcess = Buffer.concat([...audioChunks]) let frameStartIndex = 0 for (let i = 0; iEsta no es la implementación completa de la división en fotogramas mp3. En el proceso real, debemos considerar los casos en los que tenemos bytes restantes cuando extrajimos fotogramas mp3 del binario de audio y usamos el resto como el comienzo de los bytes de audio en la siguiente iteración. Consulte mi repositorio de Github para conocer la implementación completa.
-
 ¿Por qué Microsoft Visual C ++ no implementa correctamente la instanciación de la plantilla de dos fases?El misterio de la plantilla de dos fases "roto" instanciación en Microsoft Visual c declaración de problemas: usuarios comúnmente ...Programación Publicado el 2025-03-12
¿Por qué Microsoft Visual C ++ no implementa correctamente la instanciación de la plantilla de dos fases?El misterio de la plantilla de dos fases "roto" instanciación en Microsoft Visual c declaración de problemas: usuarios comúnmente ...Programación Publicado el 2025-03-12 -
UTF-8 vs. Latin-1: ¡la codificación del secreto del carácter!Distinguing UTF-8 y LATIN1 Cuando se trata de codificar, emergen dos opciones prominentes: UTF-8 y LATIN1. En medio de sus aplicaciones, surge...Programación Publicado el 2025-03-12
-
FormaciónLos métodos son fns que se pueden llamar a los objetos Las matrices son objetos, por lo tanto, también tienen métodos en js. Slice (Begi...Programación Publicado el 2025-03-12
-
Parte Serie de inyección SQL: explicación detallada de las técnicas avanzadas de inyección SQLautor: trix cyrus WayMap Pentesting Tool: Haga clic aquí Trixsec Github: haga clic aquí TrixSec Telegram: haga clic aquí Explotos ...Programación Publicado el 2025-03-12
-
¿Cómo podemos asegurar las cargas de archivos contra contenido malicioso?Las preocupaciones de seguridad con las cargas de archivo Los archivos de carga a un servidor pueden introducir riesgos de seguridad significa...Programación Publicado el 2025-03-12
-
¿Cómo eliminar los descansos de línea de las cadenas usando expresiones regulares en JavaScript?Eliminación de rupturas de línea de las cadenas En este escenario de código, el objetivo es eliminar las rupturas de línea de una cadena de text...Programación Publicado el 2025-03-12
-
¿Por qué cesan la ejecución de JavaScript cuando se usa el botón de retroceso de Firefox?Problema de historial de navegación: JavaScript deja de ejecutar después de usar el botón de retroceso de Firefox Los usuarios de Firefox pued...Programación Publicado el 2025-03-12
-
¿Cómo insertar correctamente las blobs (imágenes) en MySQL usando PHP?Inserte blobs en bases de datos MySQL con php Al intentar almacenar una imagen en una base de datos MySQL, puede encontrar un asunto. Esta gu...Programación Publicado el 2025-03-12
-
¿Puedo migrar mi cifrado de MCRYPT a OpenSSL y descifrar datos cifrados de MCRYPT usando OpenSSL?actualizando mi biblioteca de cifrado de MCRYP En OpenSSL, ¿es posible descifrar datos encriptados con MCRYPT? Dos publicaciones diferentes propo...Programación Publicado el 2025-03-12
-
¿Existe una diferencia de rendimiento entre usar un bucle for-ENTRES y un iterador para la transmisión de recorrido en Java?para cada bucle vs. iterator: eficiencia en la colección traversal introduction cuando la colección en java, la opción, la opción iba entr...Programación Publicado el 2025-03-12
-
¿Cómo verificar si un objeto tiene un atributo específico en Python?para determinar el atributo de objeto existencia Esta consulta busca un método para verificar la presencia de un atributo específico dentro de...Programación Publicado el 2025-03-12
-
Explicación detallada del método de adquisición de elementos aleatorios de Java Hashset/Linkedhashsetpara encontrar un elemento aleatorio en un set en programación, puede ser útil seleccionar un elemento aleatorio de una colección, como un conju...Programación Publicado el 2025-03-12
-
¿Cuándo los atributos CSS se vuelven a caer a los píxeles (PX) sin unidades?fallback para atributos CSS sin unidades: un estudio de caso atributos CSS a menudo requiere unidades (por ejemplo, PX, EM, %) para especifica...Programación Publicado el 2025-03-12
-
¿Cómo recuperar la última biblioteca jQuery de Google API?recuperando la última biblioteca jQuery de Google APIS La URL de jQuery proporcionada en la pregunta es para la versión 1.2.6. Para recuperar ...Programación Publicado el 2025-03-12
-
¿Cuáles fueron las restricciones al usar Current_Timestamp con columnas de marca de tiempo en MySQL antes de la versión 5.6.5?en las columnas de la marca de tiempo con cursion_timestamp en predeterminado o en las cláusulas de actualización en las versiones mySql antes de ...Programación Publicado el 2025-03-12















Estudiar chino
- 1 ¿Cómo se dice "caminar" en chino? 走路 pronunciación china, 走路 aprendizaje chino
- 2 ¿Cómo se dice "tomar un avión" en chino? 坐飞机 pronunciación china, 坐飞机 aprendizaje chino
- 3 ¿Cómo se dice "tomar un tren" en chino? 坐火车 pronunciación china, 坐火车 aprendizaje chino
- 4 ¿Cómo se dice "tomar un autobús" en chino? 坐车 pronunciación china, 坐车 aprendizaje chino
- 5 ¿Cómo se dice conducir en chino? 开车 pronunciación china, 开车 aprendizaje chino
- 6 ¿Cómo se dice nadar en chino? 游泳 pronunciación china, 游泳 aprendizaje chino
- 7 ¿Cómo se dice andar en bicicleta en chino? 骑自行车 pronunciación china, 骑自行车 aprendizaje chino
- 8 ¿Cómo se dice hola en chino? 你好Pronunciación china, 你好Aprendizaje chino
- 9 ¿Cómo se dice gracias en chino? 谢谢Pronunciación china, 谢谢Aprendizaje chino
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









